Organizations live inside mountains of PDFs: official bulletins, procurement notices, invoices, and court decisions. The information is public and valuable, but turning it into reliable, queryable data is still manual, slow, and hard to audit. We wanted a path from unstructured documents to governed, trustworthy JSON that a production system can depend on—without building a different parser for every template.
What it does
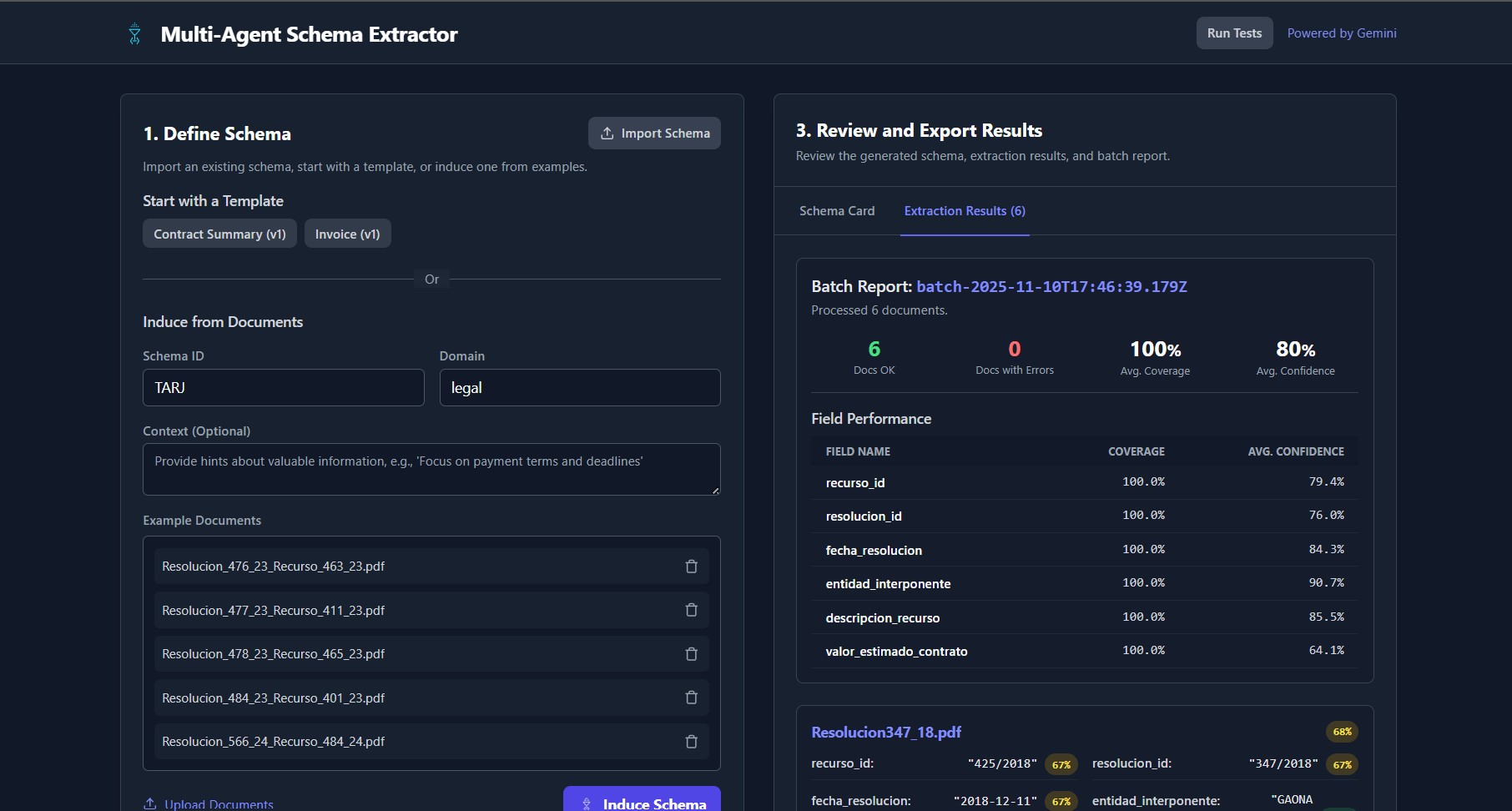
ClasificadorDocumentos induces a schema from a few examples, then extracts and validates fields against that schema. Each field carries a confidence score and the document gets an overall confidence, so review becomes targeted instead of exhaustive. Validation is explicit—types, ranges, regex, and cross-field checks such as ( \text{subtotal} + \text{tax} = \text{total} ). Results, versions, and logs are stored for full traceability.
How I built it
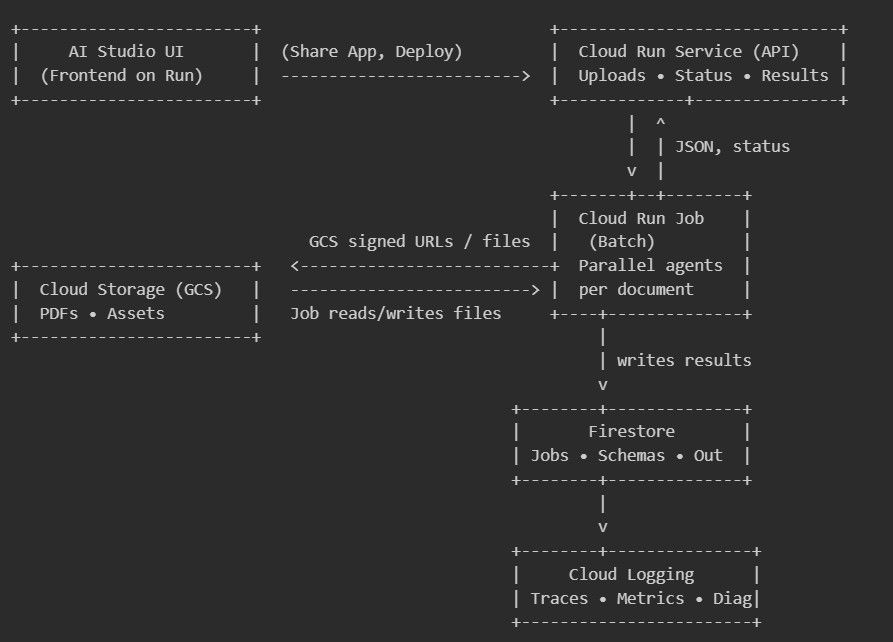
The frontend was prototyped in Google AI Studio and deployed directly to Cloud Run, which made it easy to iterate on prompts and UI. The backend is a FastAPI service coupled with a Cloud Run Job for batch processing. Files go to Cloud Storage; run state, schemas, and outputs live in Firestore; Cloud Logging stitches together the traces. Agents implemented with Pydantic-AI handle schema induction, extraction, and validation. The service issues signed URLs for uploads, tracks job progress, and returns validated JSON with per-field confidence.
Challenges I ran into
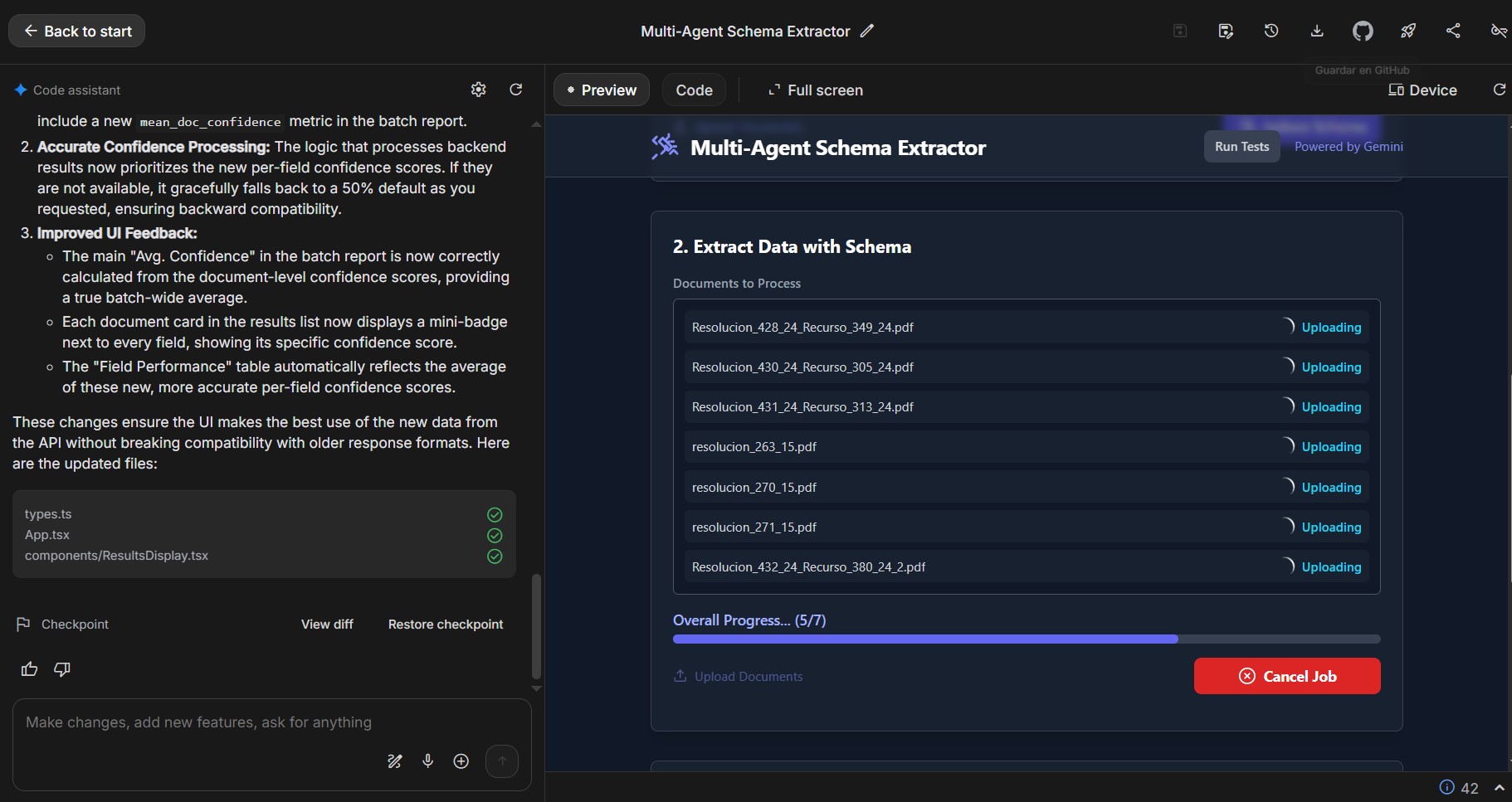
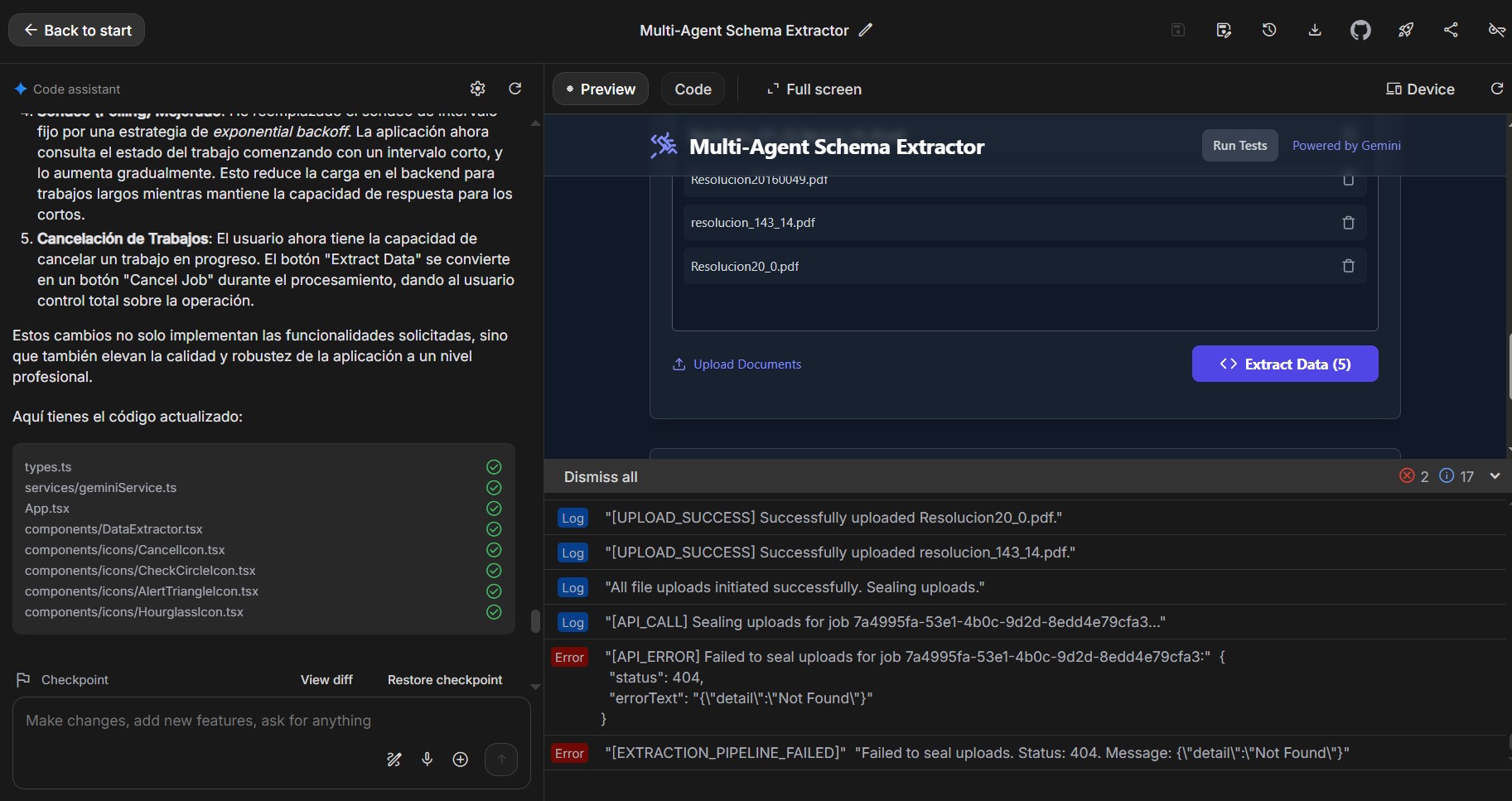
Real documents are messy. Some are scanned, some mix languages, and many drift from one layout to another. I separated schema induction from extraction so the system adapts quickly when formats change. Another challenge was offering meaningful progress feedback without complex event pipelines; a simple status endpoint and a lightweight polling loop in the AI Studio frontend proved reliable and easy to reason about.
What I learned
AI becomes production-ready when it is governed. Encoding domain rules in schemas, measuring confidence, and storing every run with its artifacts creates trust. Cloud Run’s split between Services and Jobs maps naturally to this workload and kept operations minimal. The AI Studio “Share App” model helped us document and reuse prompt logic instead of hiding it in code.
What’s next
We plan to expand the test corpus, add stronger OCR fallbacks for scans, ship a compact reviewer console focused on low-confidence items, and publish schema packs for common domains like procurement, invoices, and official bulletins. The current design also leaves room to swap or augment the extractor with GPU-backed open models where latency budgets allow.
Built With
- ai
- docker
- fastapi
- firestore
- google-cloud
- logging
- pydantic-ai
- python
- react
- typescript
- vite


Log in or sign up for Devpost to join the conversation.