-
Project Architecture
-
Wireframing
Inspiration
We were inspired by the need to understand changes in visual scenes over time in a reliable and automated way. Whether it is tracking urban development, monitoring environmental changes, ensuring brand compliance, or inspecting industrial processes, detecting scene changes manually is slow, error prone, and often impossible at scale. We wanted to create a system that could provide accurate, detailed insights about what has changed, where, and why, in any environment.
What it does
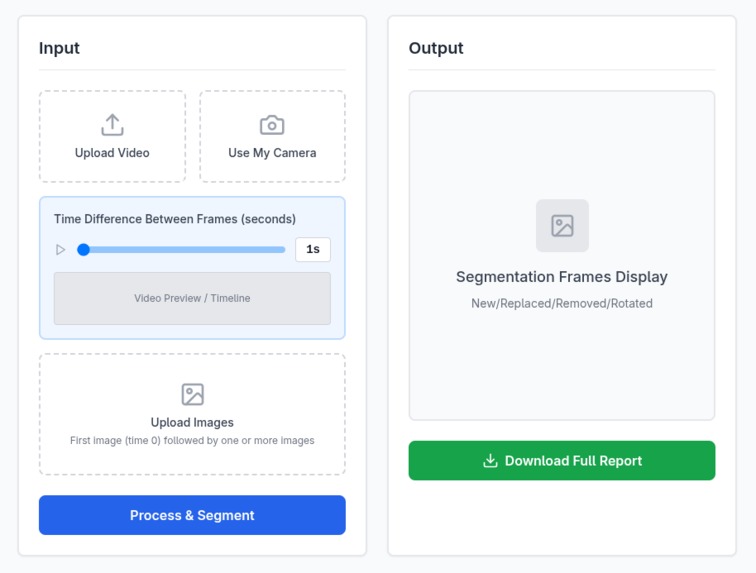
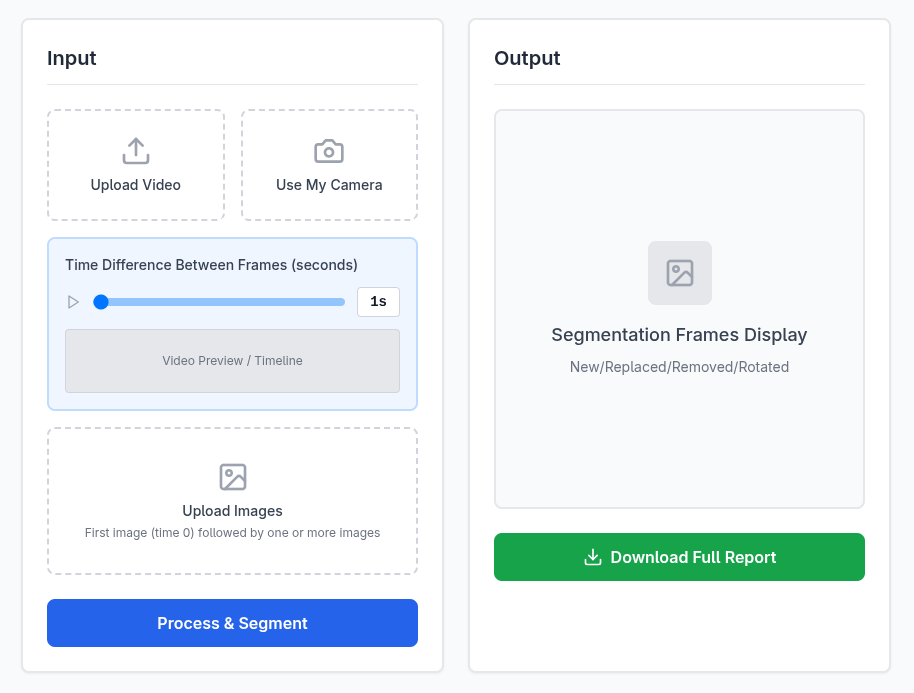
SceneSense automatically detects and analyzes changes in time series images or videos. It identifies added, removed, or modified objects and produces precise change masks. In addition, it generates detailed object level descriptions and contextual reports that summarize the evolution of a scene over time. Users can provide input through video upload, live camera capture, or image sequences, and the system generates actionable insights for urban planning, environmental monitoring, security, retail, and industrial inspection.
How we built it
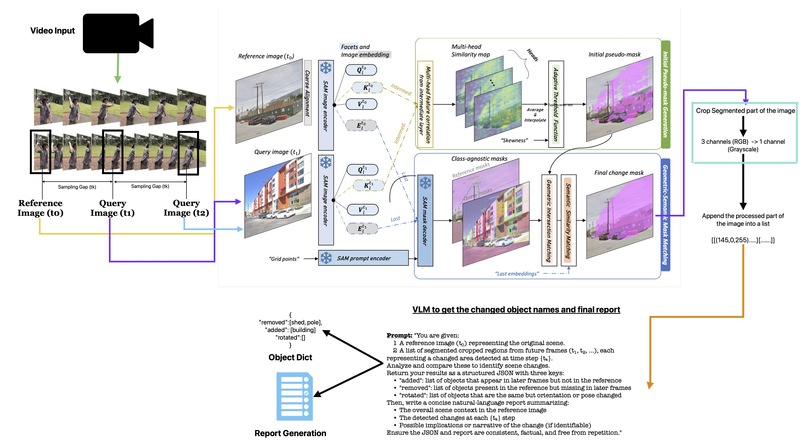
SceneSense uses a combination of visual foundation models and cross attention mechanisms:
- Input and Sampling: Frames are extracted from videos or sequences, with the first frame serving as a reference.
- Feature Extraction: SAM encoders generate multi-level visual embeddings for reference and query frames.
- Multi-Head Similarity Mapping: Attention modules compare embeddings to generate an initial change mask.
- Mask Refinement: Geometric and semantic alignment of masks isolates true changes from noise.
- Post-Processing: Changed regions are cropped and compressed for efficient analysis.
- Vision-Language Model Reasoning: Each change is classified as added, removed, or rotated, and a contextual report is generated.
Architecture and Engineering Pipeline:
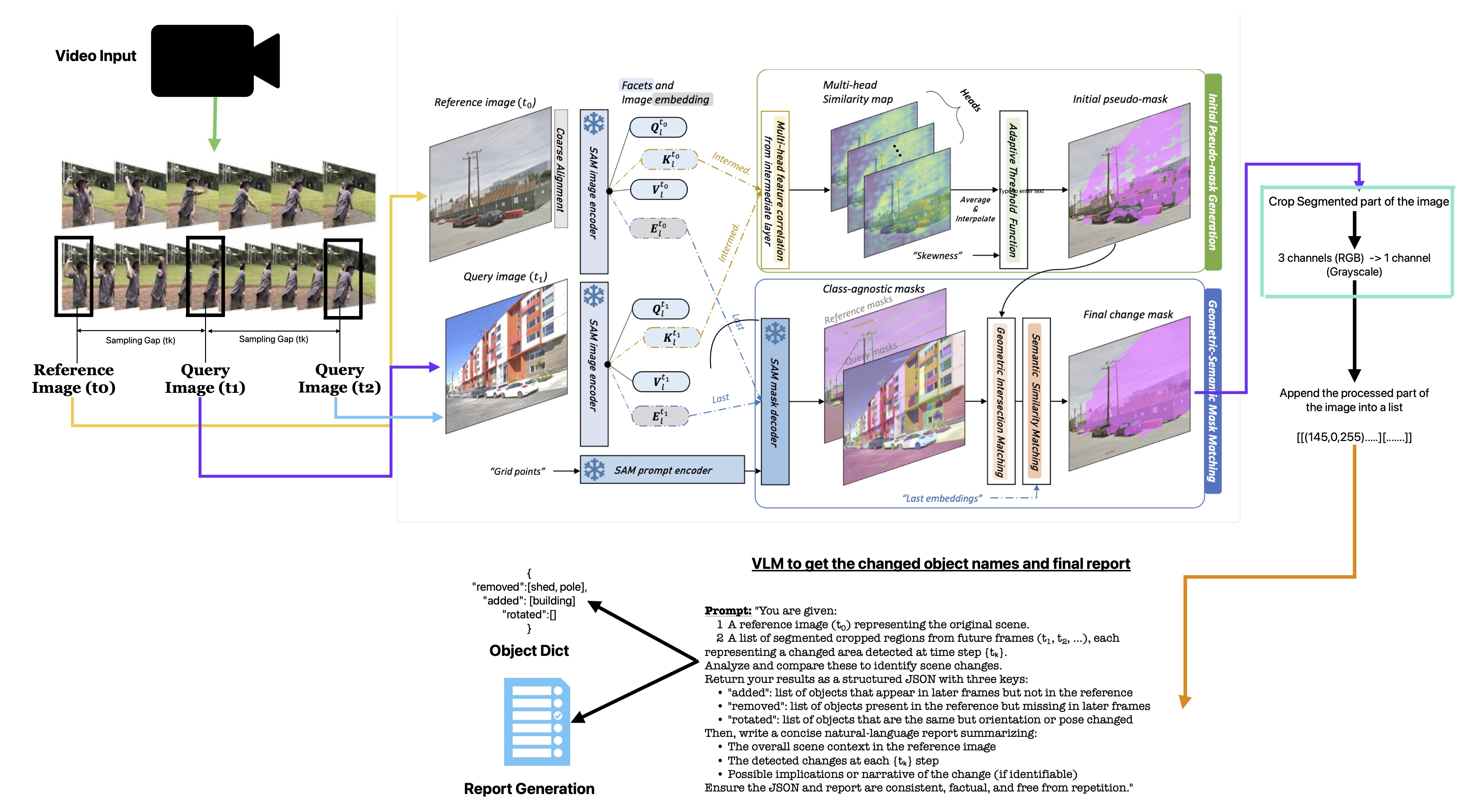
Input and Sampling The pipeline begins with a video input, from which frames are sampled at a configurable temporal gap hkhk. The first frame (t₀) serves as the reference image, representing the baseline scene. The subsequent frames t1,t2,…,tnt1,t2,…,tn are query images, each spaced hkhk apart, representing possible states of change. This controlled sampling ensures that the system captures both gradual and abrupt scene transformations without redundant computation.
Feature Extraction and Alignment Each reference–query pair is first coarsely aligned to handle camera motion and viewpoint differences. Then, both are processed by SAM-based encoders: The SAM image encoder generates multi-level visual embeddings (Qi,Ki,Vi,EiQi,Ki,Vi,Ei) for both reference and query frames. A SAM prompt encoder feeds grid-based prompts to guide the model toward localized attention on areas likely to differ across frames. These embeddings are later used for semantic and geometric comparison.
Multi-Head Similarity Mapping A multi-head attention module computes similarity maps between the reference and query embeddings. Each head captures different aspects of change — texture, geometry, and contextual variations. The maps are aggregated using an adaptive threshold function and a skewness-based metric, producing an initial pseudo-mask that highlights candidate change regions.
Mask Refinement via Intersection and Matching A mask decoder generates class-agnostic masks for both reference and query images. Through geometric intersection matching and semantic similarity weighting, the system aligns the masks to isolate true changes from noise (e.g., lighting or small motions). The result is a final change mask, which accurately delineates added, removed, or modified objects between t0t0 and each tntn.
Post-Processing and Compression Each change mask is used to crop the changed region from the query image: The region is converted from RGB (3 channels) to grayscale (1 channel). Each processed region is appended to a list representing all temporal change patches across the sequence: [[[145,0,255], ...], ...]
This compact format minimizes redundancy while preserving essential visual structure for the next stage.
- VLM-Based Change Reasoning After processing all frames, the reference image (t₀) and the list of cropped change regions are passed to a Vision-Language Model (VLM). The VLM receives a structured prompt instructing it to: Compare each query region with the reference context. Classify changes as “added,” “removed,” or “rotated.” Produce an object dictionary, e.g.: { "removed": ["shed", "pole"], "added": ["building"], "rotated": [] }
Generate a natural-language report summarizing contextual changes at each time step.
- Output Generation Finally, the object dictionary and textual report are exported, forming a complete scene-change analysis ready for human or downstream AI consumption.
What we learned
- Multi-head attention and cross-modal embeddings significantly improve change detection accuracy.
- Pre-trained foundation models like SAM can generalize well to unseen environments when combined with effective refinement.
- Post-processing and structured prompts are critical for translating visual differences into actionable information.
- Efficient sampling and processing of temporal data can balance performance and computational cost.
Possible Applications and Inspiration
Brand compliance, infrastructure degradation, compliance audits Urban planning: Detects construction or demolition changes over time. Environmental monitoring: Track deforestation, erosion, or flooding. Security & surveillance: Identify unauthorized activity or changes in sensitive areas. Retail & inventory: Monitor shelf changes or stock rearrangements. Industrial/manufacturing inspection: Detects anomalies in manufacturing lines or infrastructure.



Log in or sign up for Devpost to join the conversation.