-
-
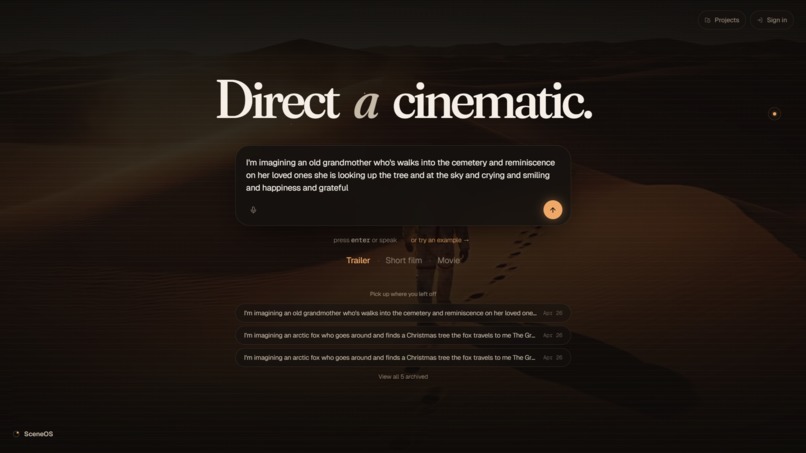
(1) Entry page
-
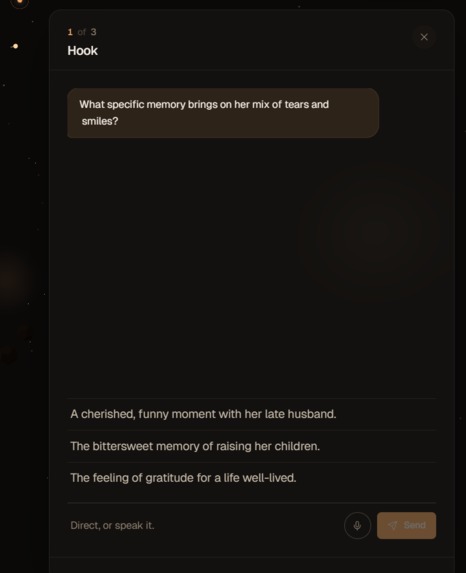
(2) Agentic pipeline (discuss your film) at every step
-
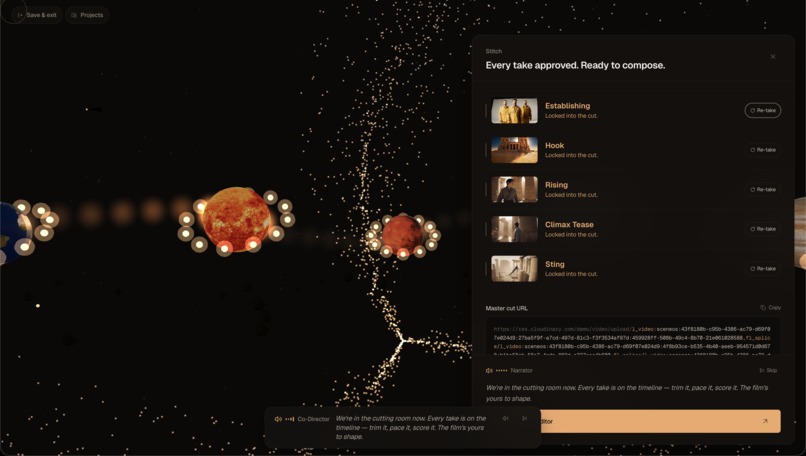
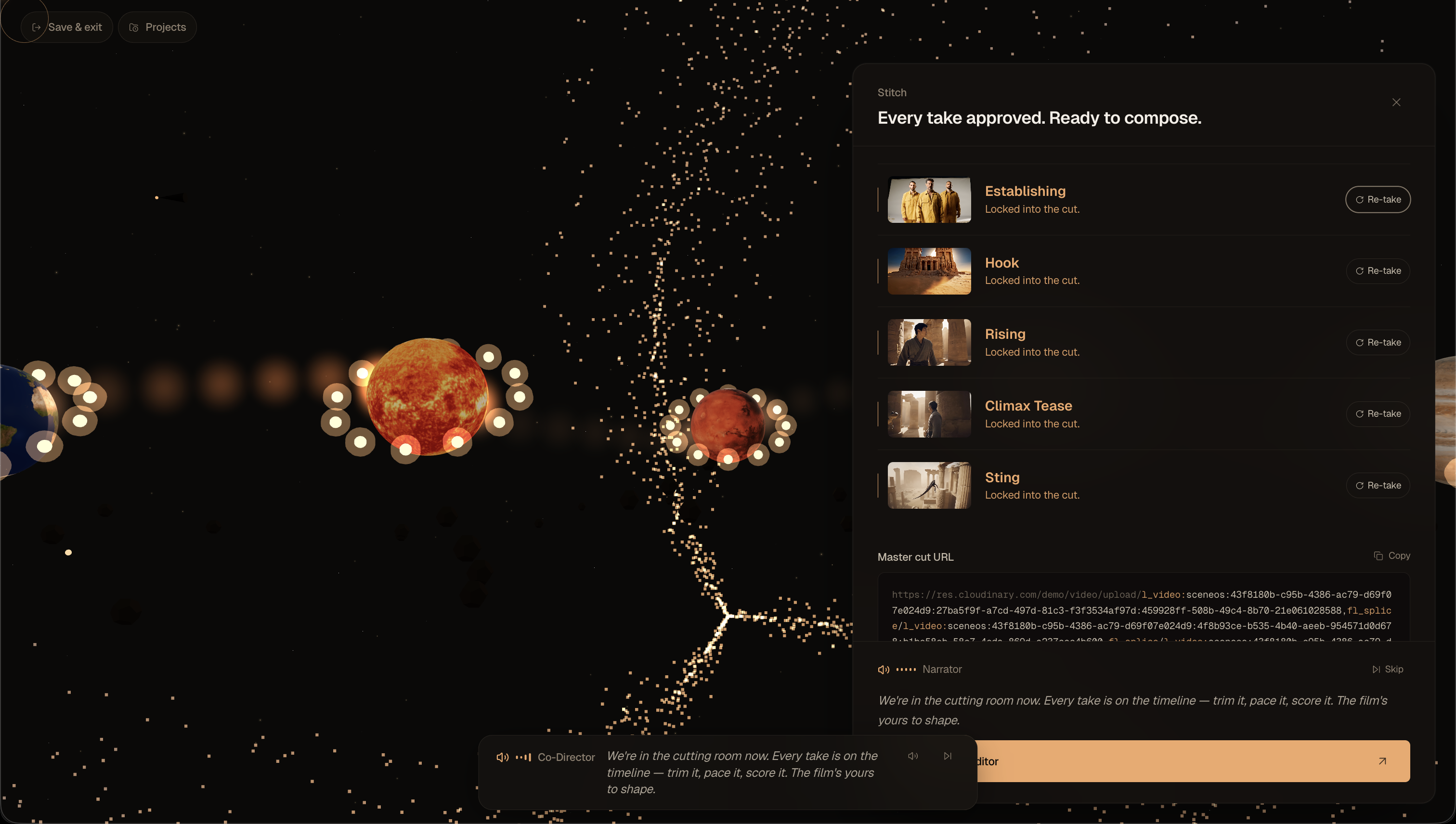
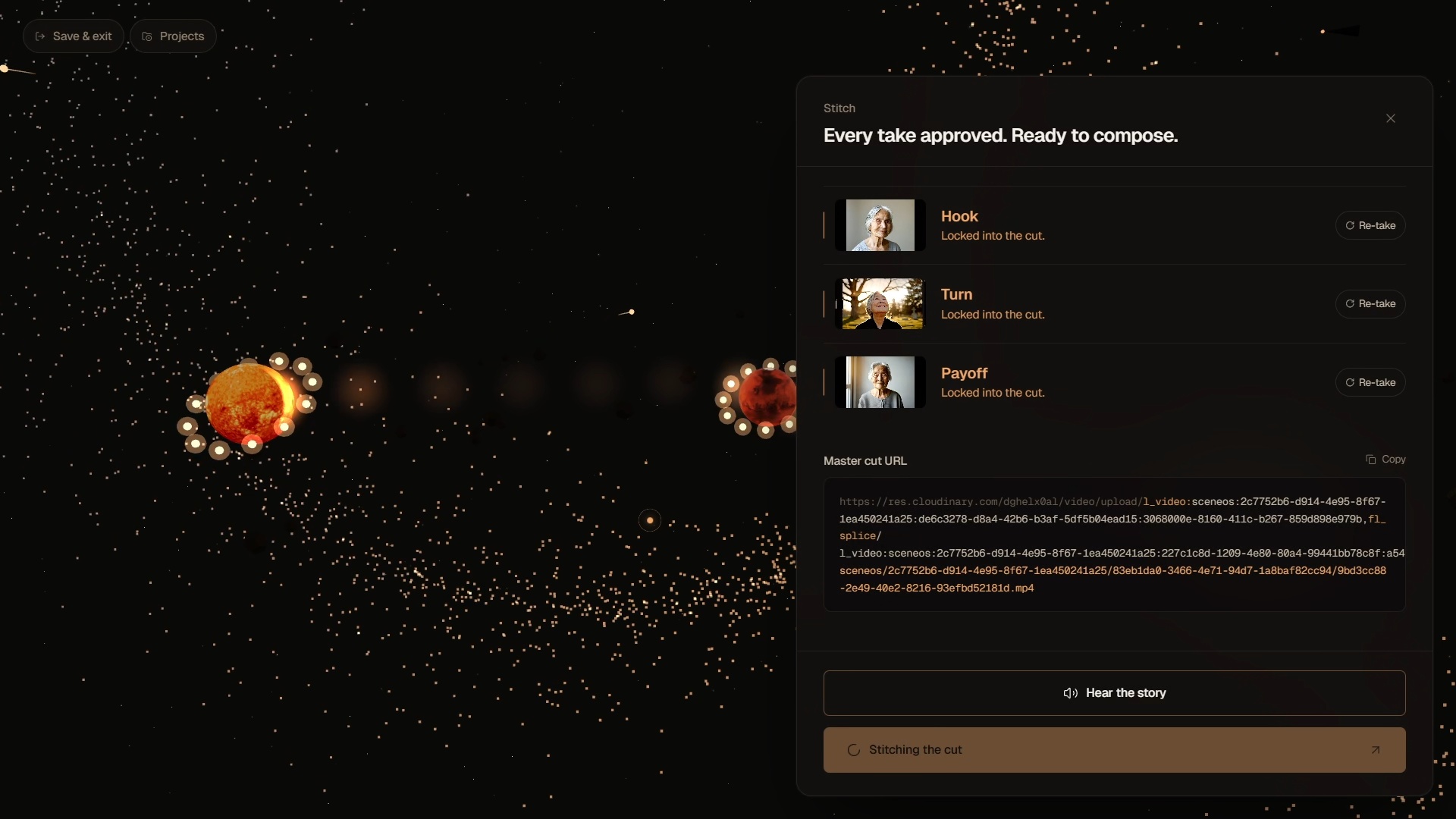
(3) Approve the final scenes
-
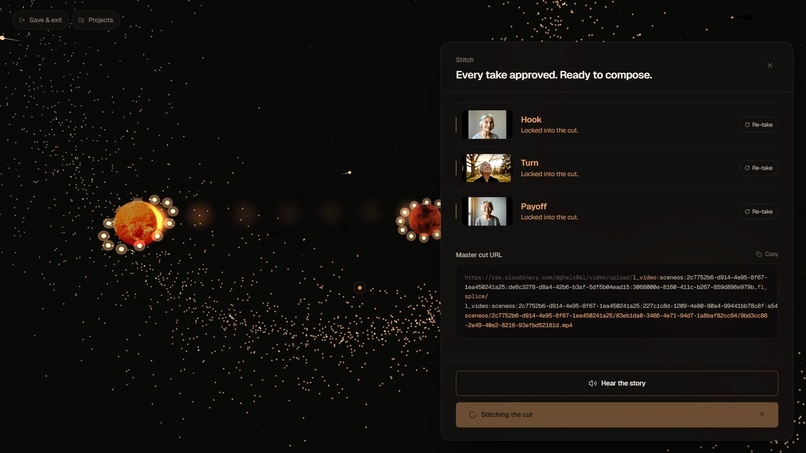
-
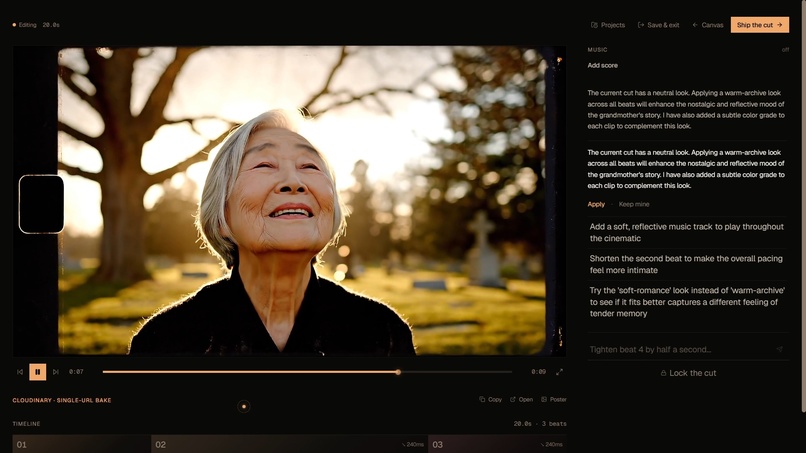
(4) Final video editor

Inspiration (look at slides too)
While travelling on a bus, Alex recalled a video from Cluely's CEO discussing the rapidly rising demand for AI video generation. The CEO was openly hiring for that specific skill set, asserting that even companies with 100x Cluely's budget would be hopping on the trend tenfold over the next year.
Previously, for Alex's own startup, he had used Higgsfield AI to generate the scenes for a movie trailer promoting a food nutritional app, and the trailer leaned on a time-travel "come back to life" sequence that worked but required meticulous planning, scripting, and Alex reliving the inner cinematographer he had only pretentiously studied back in 8th grade. Even after the AI handed him the clips, the final 2-minute trailer still cost 24 hours of editing in post-production software.
Alex and Vishnu spent close to 2 solid hours on their flight from Toronto, Canada to Los Angeles, plus the commute up to UCLA, working through the idea, and by the end of the commute the question had shifted: it was no longer "is this technically feasible," because Google Vertex, Veo, and Higgsfield AI already solve the compute layer, the technical feasibility, and the cinematic output quality. The bottleneck was everything around them.
Then Ethan brought up the production math. According to industry estimates, a 30-second TV commercial typically runs anywhere from \$50,000 to \$500,000 or more in production cost, with the high end exceeding \$1M, and a music video usually lands between \$20,000 and \$1,000,000. An indie short film crew runs anywhere from 8 to 20 people (cinematographer, gaffer, editor, colorist, sound designer, foley artist, scriptwriter, and so on), industry rule of thumb pegs editing time at 1 to 3 hours per minute of finished narrative content, and pre-production planning takes weeks. Even with AI video models like Veo and Higgsfield in the mix, a creator still needs at least an ounce of filmmaking literacy to direct the output, which means there is a real roadblock to access.
The question that fell out of that conversation was the one we built around: what if any individual with a single spark of creativity could reimagine or build a whole movie trailer, short film, or even an entire movie alone, without bringing clips into a video editor for 24 hours, and without hard-focusing the storyline through professional consultations or back-and-forth with a strong LLM, because the whole pipeline lives inside one app where the spark of an idea becomes a finished cinematic without the creator ever having to leave the tab?
That is what SceneOS provides.
What it does
SceneOS turns a single director's prompt into a finished cinematic short. The user lands on one line of input, the mic auto-starts so they can simply speak their idea (three seconds of silence auto-submits — no button press required), the page auto-picks a length tier from prompt verbosity (Trailer / 3 beats, Short film / 5 beats, Movie / 8 beats) which the user can override, and a 1.6-second page-curl bridge transitions them into a 3D star-map canvas where every beat is a planet on a Catmull-Rom spline. Veo 3.1 Fast starts rendering every beat in parallel the moment decompose resolves, so the user's wait collapses from sum(N × ~150s) to max(longest conversation, longest render).
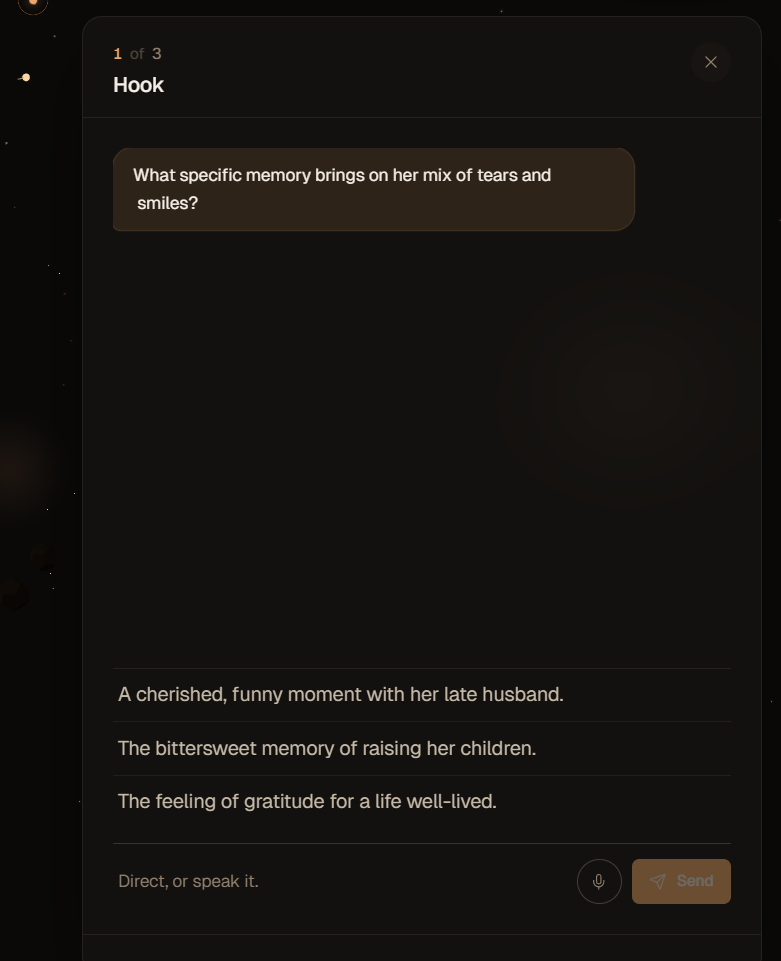
On the canvas the camera auto-arcs into the first pending beat after a 2-second breath, opening a director's drawer where a Vertex Gemini 2.5 agent runs a tier-aware questionnaire (Trailer caps at 2 questions, Movie at 5) in the same director-toned register as a real cinematographer ("frame, lens, light, blocking, pace") and produces a structured handoff (subject, action, setting, framing, mood, voiceLine, captionLine) that the user's voice actually shapes. When the agent commits via markSufficient we invalidate the speculative pre-bake and re-fire Veo with the conversation-shaped prompt — the user's idea reaches the model, every time. Approve a beat and the drawer auto-closes, the camera arcs to the next pending planet, and the cycle repeats hands-free; if the user manually escapes back to the overview the auto-arc respects that and stays out of their way until the next approval.
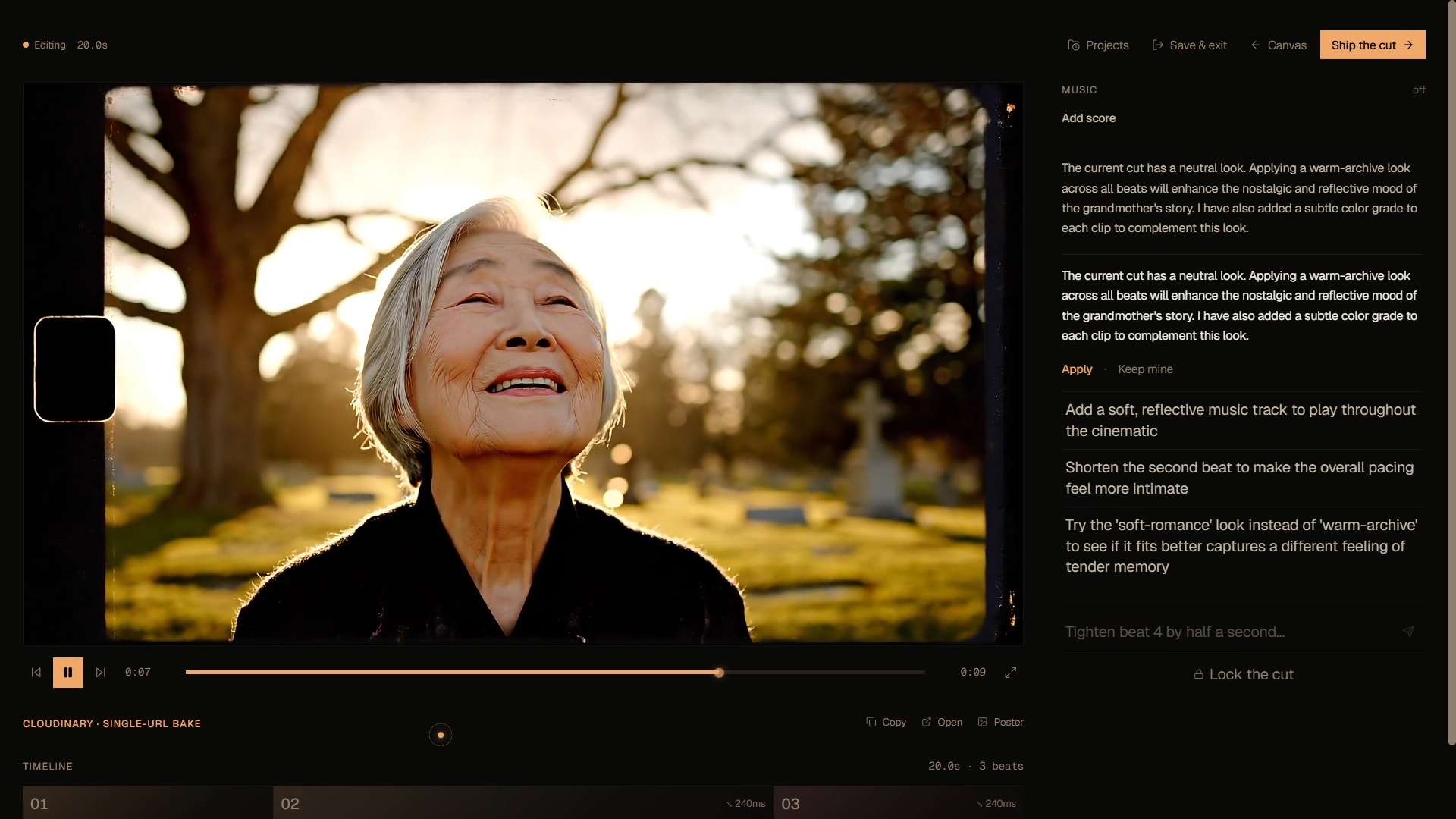
After the final approval the user opens the stitch tray, reviews each clip in line, and the live fl_splice URL composes itself into a chrome strip as approvals land. Then a fully agentic editor (Stage 7) takes over: a second director-agent proposes specific edits ("tighten beat 4 by half a second", "warm-archive LUT", "captions south", "duck the music under dialogue") and every change deterministically re-bakes the Cloudinary delivery URL. There is no FFmpeg, no render server, no second encode — the URL itself is the cut. Lock the cut and the page transitions to /final, where the cinematic plays back letterboxed with Download MP4 + Copy URL beneath it.
The value lives in what collapses: a typical commercial crew of 12 becomes a single creator at a desk, 24 hours of editing becomes the length of a coffee, and a cinematographer's vocabulary becomes something the user never has to learn because the canvas, the agent, and the editor agent absorb it on their behalf. SceneOS is not coming for the theatrical film industry, which produces work that genuinely needs irreplaceable craft and human taste, but it is coming for the volume layer beneath it (social-media content, brand variants, influencer ads, scrappy trailers, music-video drafts, pitch reels), because any creator who has scaled organically on TikTok or YouTube Shorts already knows that volume wins, and SceneOS hands a single creator a production studio inside a browser tab.
This submission applies to the Flicker to Flow track (a flickering creative impulse becomes finished output without context-switching through a video editor, a script doctor, and a cinematographer's vocabulary) and to the Cloudinary track (the entire stitching layer is pure URL composition through fl_splice with no server-side rendering, the URL composes itself live as the user approves beats, AND the post-stitch editor's every decision re-bakes that URL deterministically — the most direct demonstration we could think of for what fl_splice actually unlocks).
How we built it
The frontend is React 19 + Vite 7 + Tailwind v4 with Motion 12 driving state-based animation and GSAP 3.12 carrying the showpiece bridge transition. The 3D canvas runs on React Three Fiber 9 + drei 10 with a custom CameraRig replacing OrbitControls so the camera reads as a film camera rather than a 3D viewport. State lives in a Zustand v5 store with a merge() clamp on rehydrate that defends against localStorage drift, plus a partialize boundary that keeps transient UI state ephemeral. Voice input is auto-started Web Speech API with a 3-second silence onSettle that auto-submits both the landing prompt and per-beat user turns; voice output is Web Speech Synthesis triggered only when the last user turn was voice (so typed flows stay silent). The audio language is five cues synthesized directly from the Web Audio API rather than sample files. The chrome stack pairs Lenis-driven smooth scroll with a lazy-loaded cmdk command palette, a custom cinematic cursor that lerps slightly behind the mouse, and a persistent fl_splice URL strip. Typography is a deliberate three-font system of Fraunces (display), Manrope (body), and Geist Mono (technical strings) with one uppercase tracking value of 0.18em and italics reserved for connectives.
The build is aggressively code-split. manualChunks peels three.js, drei + postprocessing, Motion, Lenis/GSAP, Radix/cmdk/sonner, Zustand/TanStack, and React itself into separate vendor chunks; the landing first paint is ~210KB gzipped while the 1.6MB three.js + drei bundle only loads when canvas mounts and is cached across routes. Tests are vitest in a Node environment with a localStorage shim, covering pure beat-layout math, store selectors, archive→resume cycles, and a 60-second stream-timeout abort contract that mocks fetch with fake timers — 23 frontend tests total, all green. The backend has 111 pytest suites covering session start, decompose, agent eval, audio + stitch, the cached-demo provider, the Stage 7 editor, keyframes + movie plan, reliability, resilience, and contract — 134 total tests across the stack, all green.
The backend is FastAPI on Python 3.11 with a custom agent submodule rather than a generic framework. We split it into messages.py (Gemini message + config builder), normalizer.py (tool-call → AgentResponse shape), prompt.py (system prompt composition), repair.py (defense-in-depth for redundant questions), stub.py (deterministic fallback when no Vertex client is configured for tests + dev), tools.py (askQuestion + markSufficient + proposeEdit + commitEdit tool schemas), and gemini.py (Vertex Gemini dispatch with both non-streaming and SSE streaming paths). Vertex Gemini 2.5 Flash is the only LLM SceneOS uses (Anthropic was used early in development but removed entirely once Vertex's tool-use story matured). Decompose, the per-beat questionnaire, the editor agent, and the cross-beat continuity bible all run through the same Vertex Gemini surface.
The agent is mode-aware and tier-aware. A demo-mode flag uses a smaller thinking-budget (512) versus a normal-mode budget (2048). Question caps scale with the user's tier choice (Trailer=2, Short film=3, Movie=5). When the user runs out of texture before the cap, the agent autonomously fills cinematographer's choices from the beat archetype's directorNotes (lens, movement, light, blocking, pace) instead of stalling — that single behaviour is the difference between a vague-prompt demo collapsing into "asking for a name eight times" and a vague-prompt demo producing a real cinematic on the first try.
Generation is deterministic provider dispatch with Higgsfield as the prominent lane and Vertex Veo as the sibling fallback. When HIGGSFIELD_API_KEY is set, the autodetector promotes Higgsfield to primary; the cascade dispatch_with_fallback then tries Higgsfield first, falls through to Vertex Veo on any 5xx/quota/safety failure, and finally to a baked cached lane so a single-provider outage never dead-ends a live demo. The frontend always gets originalProvider + fallbackReason on the response so it can label the result honestly ("Demo lane in use" badge). Stitching is pure URL composition through Cloudinary's fl_splice — no server-side rendering, no FFmpeg, no waiting on a final encode. The Stage 7 editor extends the same primitive: a second director-agent emits structured EditDecisions (clips, audio, look LUT, captions, watermark, ducking, fade-in/out) and a deterministic Python baker turns those decisions into a Cloudinary delivery URL with e_brightness, e_volume, fl_layer_apply, and l_text transformations — the cut is the URL.
The Higgsfield integration journey, in detail. The killer primitive Higgsfield gives us is Soul mode — pass 1-to-5 reference images as identity anchors, get back a video that uses them as cross-frame consistency seeds. That's exactly the cross-beat character-stability problem we'd been chasing with chained last-frames. We wired it as a parallel provider behind a clean GenerationProvider = "higgsfield" | "vertex" | ... enum and made it the default whenever the API key is present. The auth surface turned out to be dual: the public higgsfieldapi.com/api/v1 endpoint uses bearer tokens, while the legacy platform.higgsfield.ai (the API surface that ships with cloud.higgsfield.ai dashboard accounts) uses HMAC-style Authorization: Key {api_key_id}:{api_key_secret}. We auto-detect which based on whether HIGGSFIELD_API_SECRET is set and route accordingly — single integration, two surfaces. We extended the orchestrator so when Higgsfield is the active provider, character + location reference images flow through Higgsfield's Soul T2I model (soul/standard) instead of Vertex Imagen, get cached on session.projectRefs as soul::{project}::{kind}::{request_id} IDs, and are passed forward as references on every per-beat I2V call. The legacy platform.higgsfield.ai/dop/standard I2V endpoint has its own payload contract — model: "dop-lite", single image_url, motions_id (a UUID for the camera-motion preset, default Arc Left at c5881721-05b1-47d9-94d6-0203863114e1), motions_strength, enhance_prompt, seed — distinct from the public API's auto-detect shape, so the payload builder branches on _is_legacy(). Verified end-to-end: a real 403 not_enough_credits JSON response on a fresh-account smoke (clean billing failure mode, much nicer than opaque 500s) → top up → ~20s for Soul T2I returning real CDN URLs in {"images": [{"url": "..."}]} → ~80s for I2V returning {"video": {"url": "..."}} → automatic Cloudinary re-upload to keep the editor's fl_splice URL inside one CDN. The dop-lite tier prices at roughly 5–7 platform credits per 5-second clip, which means a Trailer (3 beats, 2 souls) lands around 30–45 credits and a full Movie (8 beats) around 55–80. A $10 top-up funds 10+ Trailer iterations, comfortable for a 60-second demo without burning the budget.
Deploy is Vercel for the frontend + Cloud Run for the backend, both wired up: frontend/vercel.json encodes Vite build settings + asset caching + security headers, backend_py/Dockerfile is a python:3.11-slim image with --proxy-headers for Cloud Run's load balancer, and docs/DEPLOY.md walks through the gcloud deploy + custom-domain mapping + CORS gotcha + smoke tests + rollback steps.
Challenges we ran into
The frontend started generic, with the default shadcn skin, Inter for body, Playfair-flavored serifs for display, and Sparkles icons next to AI features, and it read like every other AI product in 2026, so we threw the whole thing out and rebuilt typography, palette, motion language, and microcopy from a single thesis ("Tesla designing a Christopher Nolan trailer"), running three full audit-and-rebuild cycles before the system actually held up at every size. The 3D canvas hit four production crashes worth naming: a hardcoded CameraRig position that silently overrode our ResponsiveCamera computation on portrait viewports (resolved by passing the camera distance as a prop), a first-commit null crash inside @react-three/postprocessing 3.0.4 under React 19 + R3F 9 (resolved by removing the entire EffectComposer and letting atmosphere shells and the holographic active overlay carry the visual weight), a per-character text animation that broke words mid-character (resolved by grouping characters into non-breaking inline-block word containers), and a Zustand v5 + StrictMode max-update-depth crash on fresh-array selectors (resolved with useShallow from zustand/react/shallow).
The backend's most interesting architectural reversal was the speculative pre-bake. We fan out one /api/generate per beat the moment decompose returns, so by the time the user reaches a planet the clip is often already done — but that meant the user's per-beat conversation had ZERO effect on what Veo rendered, because the drawer would short-circuit to the speculative result. The fix was making markSufficient and "lock it in" both invalidate the speculative job + clip URL, which forces a fresh Veo dispatch using the agent's richer refinedPrompt (which now carries the structured subject, action, setting, framing, mood, voiceLine, captionLine handoff). The user's voice actually reaches the model. The pre-bake still serves the "user clicks through 8 beats without talking" flow as a draft, but the conversation is canonical the moment it engages.
Veo's content-policy filter is the second non-obvious challenge. Some prompts (real-violence, named persons, explicit) come back as Vertex AI's usage guidelines rejections and the user can't be expected to know the safety surface up front. Instead of a dead-end "render failed" overlay we built isContentPolicyError() detection that bounces the beat back into questioning, wipes the offending refinedPrompt + speculative state, and seeds an agent turn ("Veo refused that frame for a content-policy reason — tell me different words…") so the user keeps refining until Veo accepts. They never see a wall.
The Anthropic removal was its own architectural reversal. We started with Claude wired through a thin LangGraph wrapper because the tool-use ergonomics were familiar, but Vertex Gemini 2.5's structured tool-use, streaming thoughts, and continuity-bible synthesis matured faster than expected and the case for one model became overwhelming. We pulled Anthropic and the LangGraph layer entirely, split the agent into a proper Python submodule (messages / normalizer / prompt / repair / stub / tools / gemini), wired the editor agent into the same primitives, and now run every LLM call through one cleanly-typed Vertex Gemini surface.
We also had to think hard about what is actually feasible for a 2-to-5-minute live demo, because while Higgsfield produces the highest-quality cinematic output for filmmaking right now its latency is too long for live demo, Veo 3.1 Fast is the right sweet spot, and fal.ai is the fastest with acceptable quality, so we built a provider toggle exposed via the command palette with a "best model" path for serious cinematic generation and a "speedrun model" path for live demo and fast iteration. The cached fallback lane (a pre-baked lighthouse-keeper short) is the on-stage safety net that fires automatically when Vertex rejects a request mid-demo.
Accomplishments that we're proud of
We got the entire pipeline stitched together end to end (prompt to decompose to 3D canvas to per-beat conversation to clip generation to live URL stitching to fully agentic post-stitch editor to final cinematic delivery, with mock and live modes, reduced-motion fallbacks, error boundaries protecting every stage, content-policy auto-rechat, an automated archive→resume flow that survives a hard refresh mid-edit, and a smart auto-arc that respects manual escapes), and we did it on the back of close to 6 hours of pre-build investigation on the flight and commute. We held the design bar as non-negotiable across the whole build, holding every screen to the screenshot test, every microcopy string to the director's voice, and every animation to the four-reasons rule, while ruthlessly protecting the four demo-winning moments (the landing-to-canvas portal, the 3D star-map first reveal, the live Cloudinary URL strip composing itself in real time as approvals land, and the editor's URL re-baking the moment the user changes a single trim handle).
We're particularly proud of three things that are non-obvious from the outside. First: the Stage 7 editor is genuinely agentic, not a trim-tool veneer. The director-agent proposes specific edits ("tighten beat 4 by half a second, drop the LUT on beat 6, captions south, duck the music under the dialogue") and every change re-bakes the Cloudinary URL deterministically — the entire post-production layer is one pure function from EditDecisions to URL. Second: voice-first is genuine. The mic auto-starts on landing, three seconds of silence auto-submits the prompt, the per-beat agent's mic auto-starts on drawer open, and three seconds of silence auto-submits a user turn — the user can drive the entire pipeline without ever touching a mouse. Third: the speculative pre-bake architecture cuts perceived latency by half a magnitude on multi-beat cinematics while still letting the conversation shape the canonical clip.
We have 134 tests passing across the stack (23 frontend vitest unit tests covering pure math, store selectors, resume cycles, and the 60-second stream-timeout abort contract; 111 backend pytest suites covering session start, decompose, agent eval, audio + stitch, cached demo, editor, keyframes + movie plan, reliability, and resilience), a clean tsc + clean Vite production build with the landing first-paint at 173KB and the canvas-only WebGL bundle peeled into a cached vendor chunk, and a live-deployable scaffolding (vercel.json, Dockerfile, docs/DEPLOY.md) so the same code that runs on a laptop ships to sceneos.us + api.sceneos.us without manual config.
What we learned
We learned that SceneOS must offer value to its users by both stripping away the time needed to perform high-skill craft (because that craft is automated) and removing the prerequisite skill bar (video editing, cinematography, filmwriting) that gates high-volume cinematic content today. We did not want SceneOS to be a simple wrapper that calls AI video creation, because the wrapper has been tried and the wrapper is the bottom of the market; we wanted a whole guided, intuitive, clean, satisfying suite that goes from idea to completed video with every step in between automated or guided by the user's voice, with the option to type when the mic is unavailable. The director conversation, the 3D canvas, the persistent URL strip, and the agentic editor are the real differentiators, while the wrappers underneath are a commodity.
We learned that "let the agent decide" is a real product feature. When the user runs out of texture before the question cap, the agent autonomously picks specific cinematographer's choices from the beat archetype's directorNotes — lens, movement, light, blocking, pace — and that single behaviour is the difference between a vague-prompt demo collapsing into "asking for a name eight times" and a vague-prompt demo producing a real cinematic on the first try.
We also learned that the cinematic register is built by deletion rather than addition (we removed image-upload, the speculative-result short-circuit on conversation, the trailing-summary microcopy, the EffectComposer, the lint script that pointed at an uninstalled binary, even an entire LLM provider once one model was clearly enough), that demo-day calculus is its own product discipline (the 800ms perception threshold, the four protected moments, the cached-fallback safety net, the reduced-motion kill switch, the 60-second stream timeout, the auto-rechat on content-policy, the two-step delete confirmation that prevents one-click work loss), and that two co-founders sketching a startup on a flight then shipping in 36 hours is a rare and worth-protecting thing, because the 6 hours of philosophy work we did up front paid off in every single design decision afterward.
What's next for SceneOS
SceneOS intends to expand into a full suite that uses video generation APIs as the engine driving what modern post-production software does, focused entirely on AI, with stronger models, pricing tiers, and deliberate B2B and B2C positioning. Three concrete next steps:
1. Provider tiering and pricing. A free tier on the speedrun model (fal.ai), a pro tier on the cinematic model (Veo, Higgsfield), and a studio tier with batch generation, brand-kit imports, voiceover synthesis, and export pipelines for editorial software (Premiere XML, Final Cut Pro XML), with pricing experiments informing which tier creators stay in and what the right price is for the volume use case versus the cinematic one.
2. A B2B agency workflow. Brands and agencies routinely need 50 to 200 social-media variants for a single campaign, and SceneOS's pipeline (one prompt to many beats to many clips to one stitched cinematic, plus an agentic editor that can deterministically re-cut the same source) is already a variant engine, so the B2B layer adds brand-kit constraints, multi-variant prompt expansion, stakeholder approval workflows, and rights-managed export, while the per-account revenue dwarfs B2C.
3. A multimodal director's notebook. Today the conversation is voice-first with text as a fallback, but the next step is full multimodal direction: drop a reference reel and the agent learns the visual language from it, hum a melody and the agent picks a score direction, sketch a storyboard panel and the agent matches framing across beats, all with the same goal we started with, which is to lower the prerequisite-skill bar to zero while raising the ceiling of what one person can ship in a day.
The longer arc: the next decade of social-media content belongs to individuals with cinematic taste and zero crew, and the tooling layer between idea and finished cinematic decides who wins. We are building that layer.
Built With
- anthropic
- cloudinary
- cmdk
- drei
- fal.ai
- fastapi
- google-vertex-ai
- gsap
- higgsfield
- langchain
- langgraph
- lenis
- lucide
- motion
- openai
- python
- radix-ui
- react
- react-three-fiber
- sonner
- tailwindcss
- three.js
- typescript
- veo
- vite
- web-audio-api
- web-speech-api
- zustand




Log in or sign up for Devpost to join the conversation.