-
-
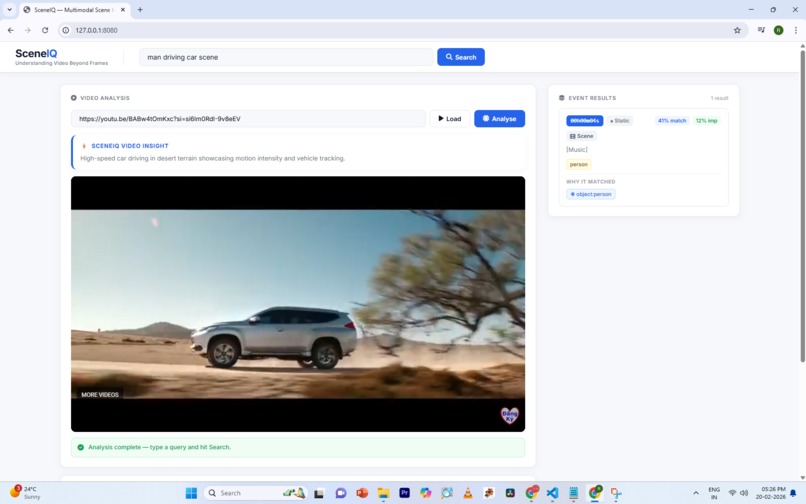
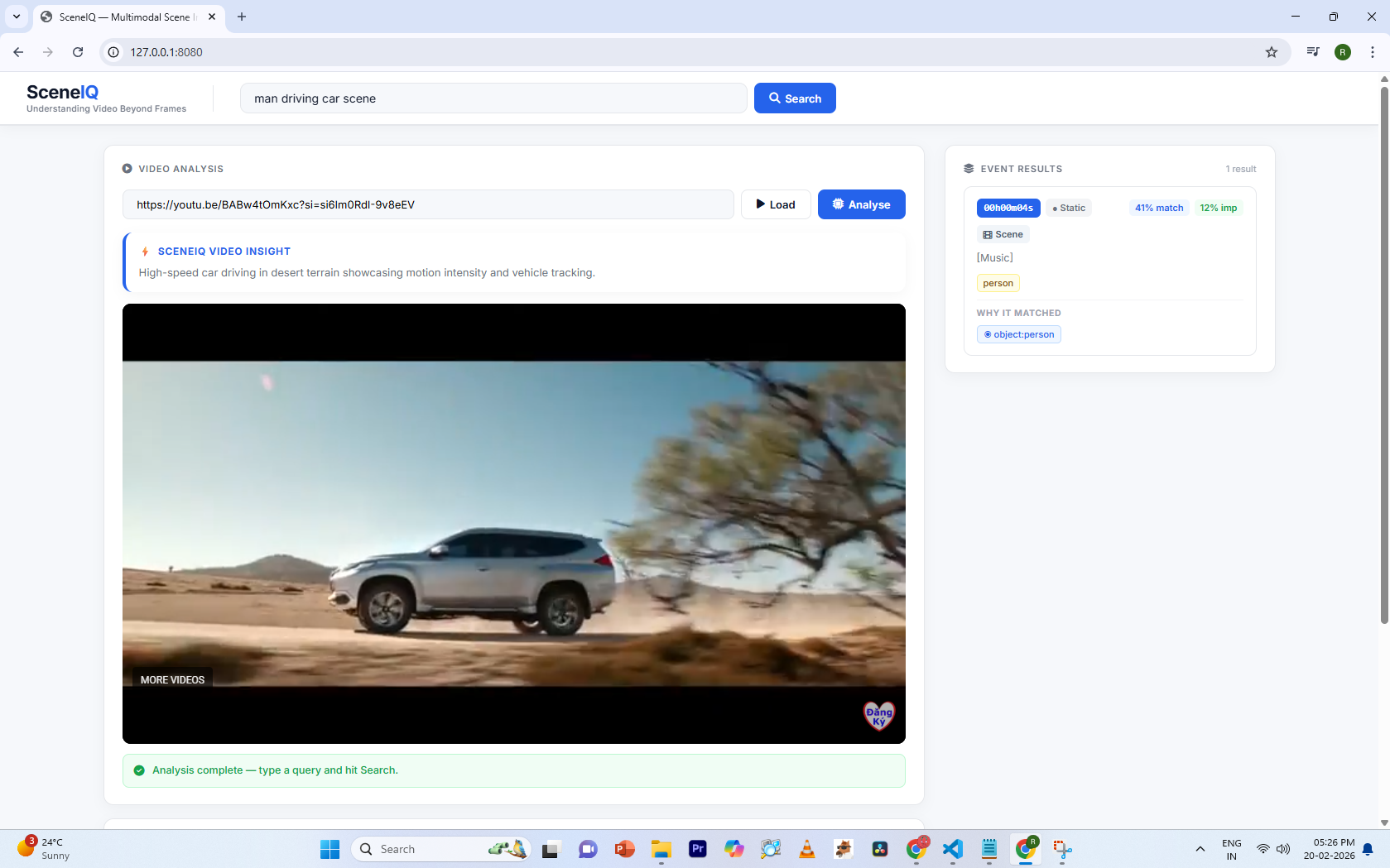
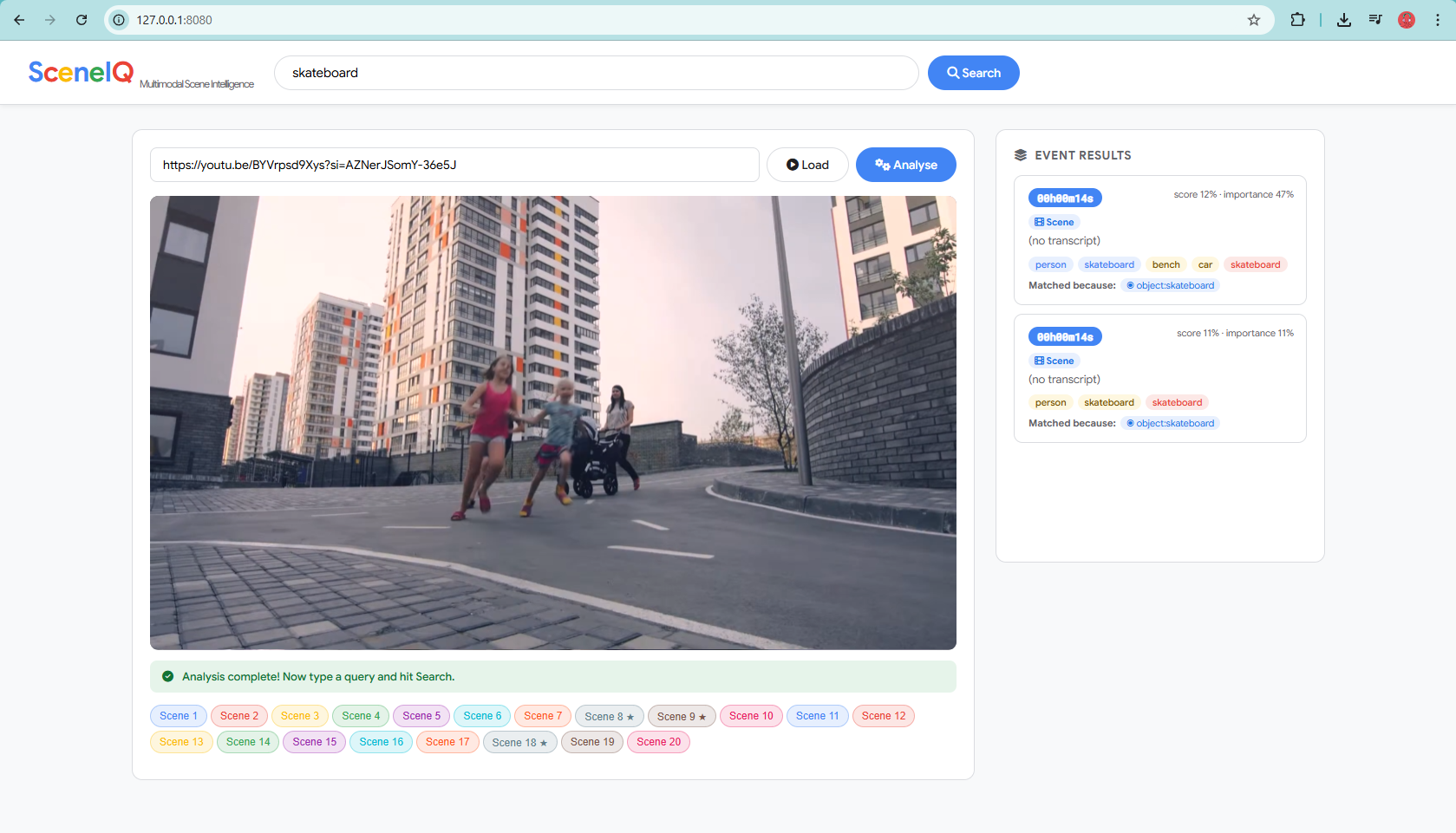
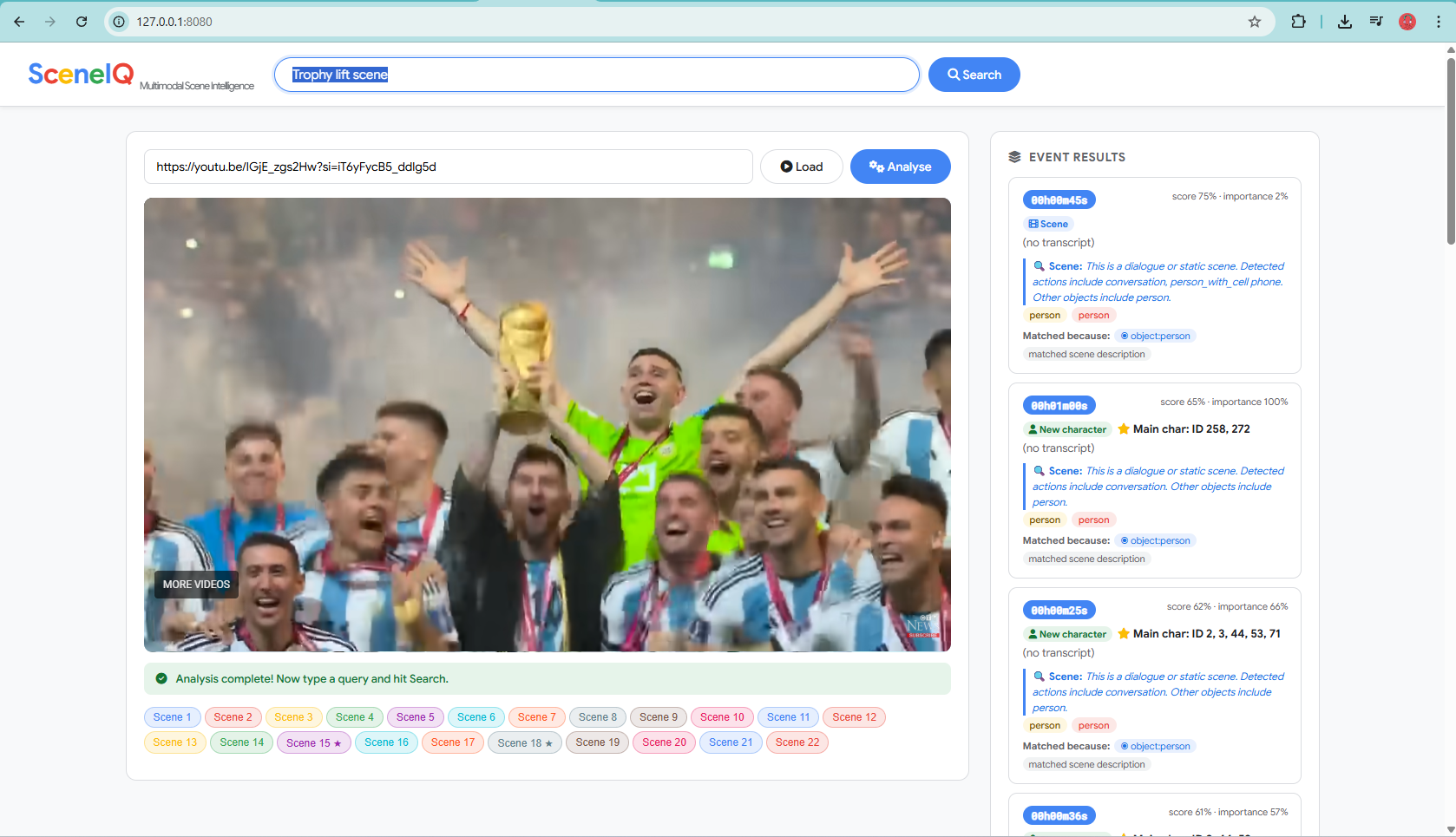
Query-driven retrieval showing motion-aware scene matching with importance scoring and exact timestamp output.
-
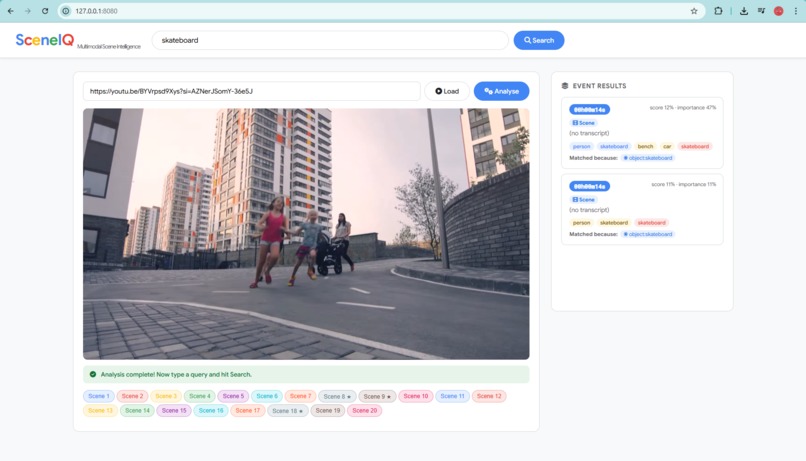
SceneIQ analyzes a YouTube video, segments scenes, and enables semantic timestamp-based retrieval.
-
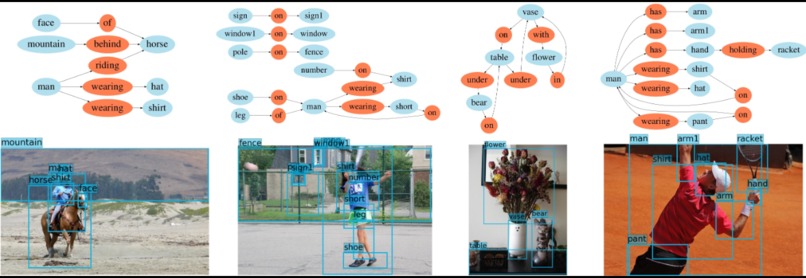
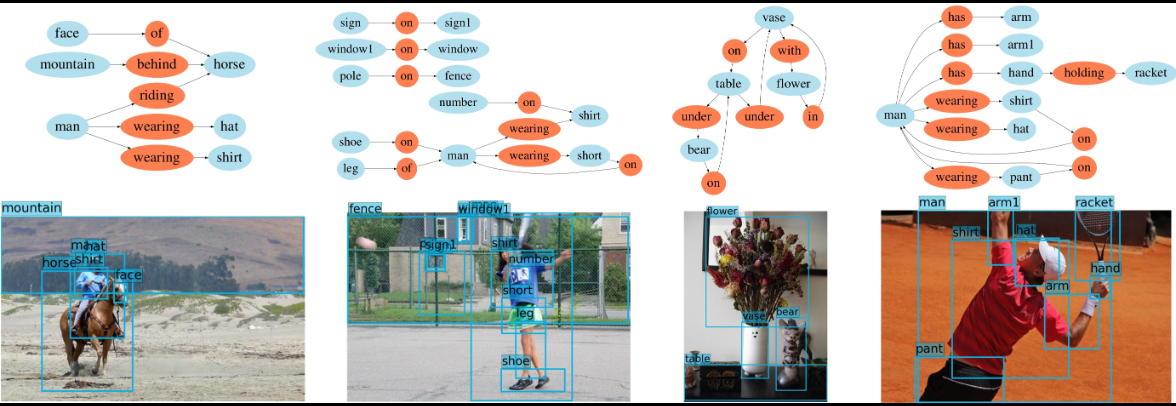
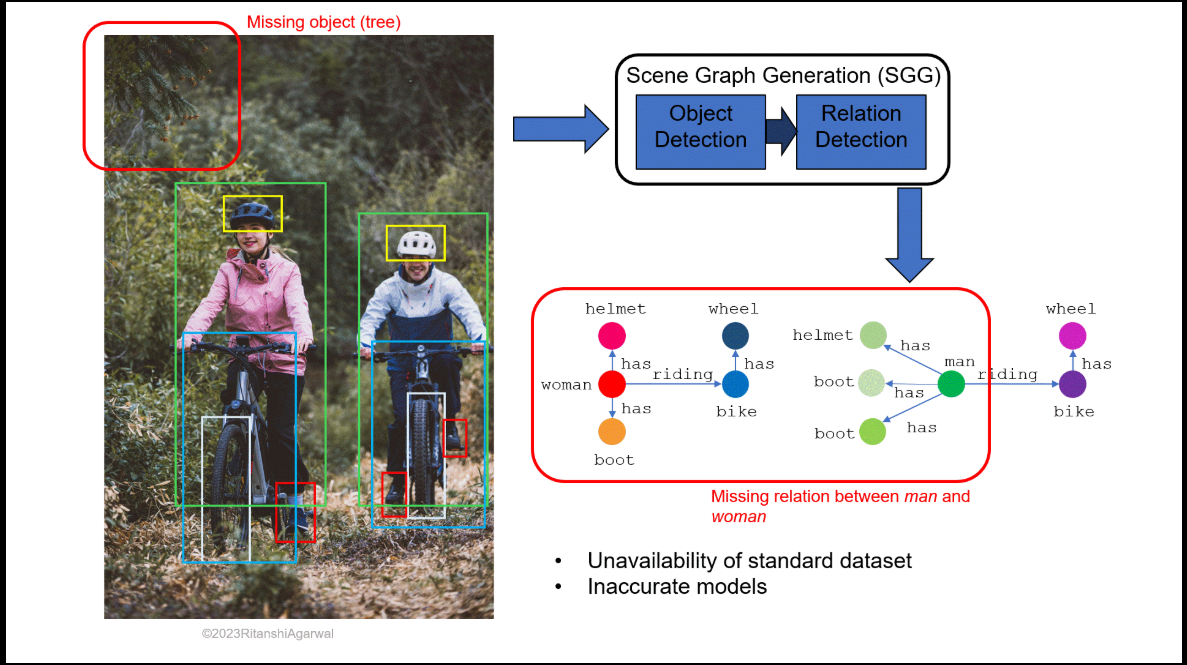
Examples of generated scene graphs showing entity relationships such as riding, wearing, holding, and spatial positioning.
-
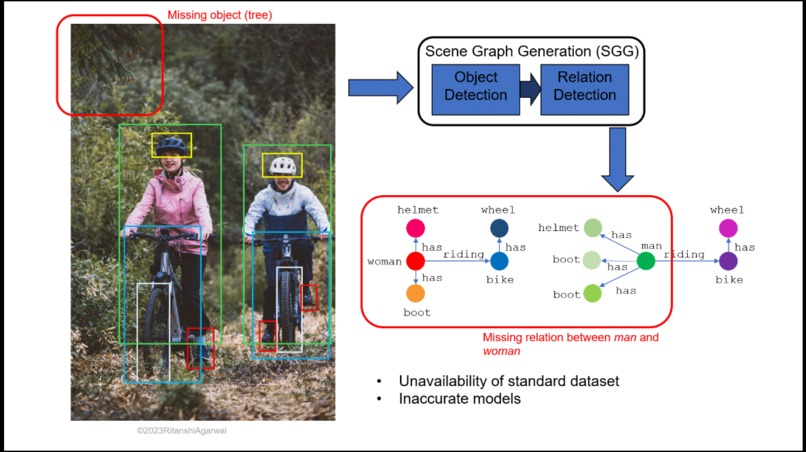
Demonstrates object detection and highlights limitations of traditional models in capturing missing relational context.
-
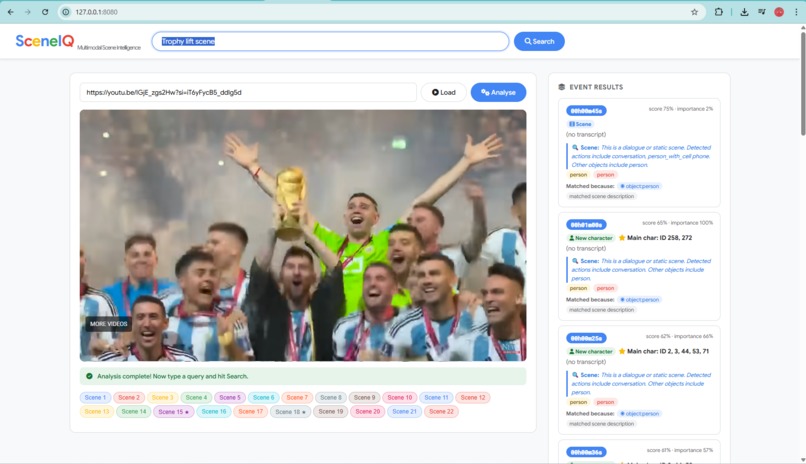
SceneIQ retrieves the trophy lift moment using persistent character IDs and motion-aware ranking for instant timestamp navigation.
Inspiration
Modern cities generate massive amounts of video from CCTV, drones, and public recordings. However, identifying important moments still requires manually reviewing hours of footage. During emergencies or investigations, this delay wastes critical time. We built SceneIQ to transform video from passive recordings into structured, searchable intelligence, allowing users to instantly locate meaningful moments inside long videos.
What it does
SceneIQ converts raw video into structured scene intelligence. Instead of analyzing isolated frames, SceneIQ models events over time. The system automatically segments video into scenes, detects and tracks entities across frames, analyzes motion patterns, models interactions between objects, and ranks scenes by importance.
Users can search videos using natural language queries such as: “person driving car” “crowd panic moment” “player holding trophy” SceneIQ instantly retrieves the exact timestamp of the relevant scene, eliminating the need to manually scrub through hours of footage.
How we built it
SceneIQ processes video through a multi-stage AI pipeline. First, videos are segmented into narrative scenes using structural scene segmentation techniques. Each frame is then analyzed using YOLOv8 object detection, combined with persistent multi-object tracking to maintain identity across time.
Next, motion intelligence models analyze velocity patterns to identify meaningful activity such as running, crowd movement, or vehicle motion. An interaction graph layer captures spatial and temporal relationships between entities.
Finally, scenes are ranked using an importance scoring function based on motion intensity, entity density, and interaction complexity. These structured scenes are indexed and made searchable through semantic natural-language queries.
Challenges we ran into
One major challenge was maintaining persistent identity tracking across long video sequences, especially when objects temporarily disappear, overlap, or reappear.
Another challenge was designing a scene importance scoring system that highlights meaningful events rather than random motion spikes. Balancing efficiency with accurate scene reasoning while keeping the entire system fully local and deterministic was also a key technical challenge.
Accomplishments that we're proud of
We successfully built a fully local and explainable video intelligence pipeline capable of understanding temporal events instead of isolated frames.
SceneIQ performs: scene segmentation persistent entity tracking motion reasoning interaction modeling semantic scene retrieval all within a modular architecture. Most importantly, we demonstrated that meaningful video understanding can be achieved without relying on heavy black-box transformer models.
What we learned
Building SceneIQ taught us that temporal continuity is essential for understanding video narratives. Motion dynamics and interaction density often reveal the importance of moments far better than simple frame-level object detection.
We also learned that well-designed computer vision pipelines can deliver strong semantic reasoning while remaining efficient, interpretable, and deployable locally.
What's next for SceneIQ: Temporal Scene Intelligence for Video Search
Next, we plan to enhance SceneIQ with:
Graph neural networks for deeper interaction reasoning Multimodal fusion with speech transcripts and audio signals Cross-video narrative linking for large media archives
Our long-term vision is to make video fully searchable by meaning, enabling powerful applications in public safety, disaster response analysis, education, sports analytics, and intelligent media indexing.

Log in or sign up for Devpost to join the conversation.