What problem your app solves and why I built it
Communication is the number one skill that determines career success, relationship quality, and personal confidence, yet it's the one skill we almost never get to practice safely. Think about it: before a job interview, you can rehearse answers in front of a mirror, but the mirror doesn't push back. Before firing an underperforming employee, there's no way to simulate their emotional reaction. Before confronting a difficult client, you're left guessing how they'll respond to your approach.
The consequences of walking into these moments unprepared are real: lost deals, damaged relationships, missed promotions, and the lasting regret of "I should have said..." Studies show that 70% of professionals avoid difficult conversations entirely due to anxiety, and those who do engage often perform poorly because they've never experienced the emotional pressure of the real interaction.
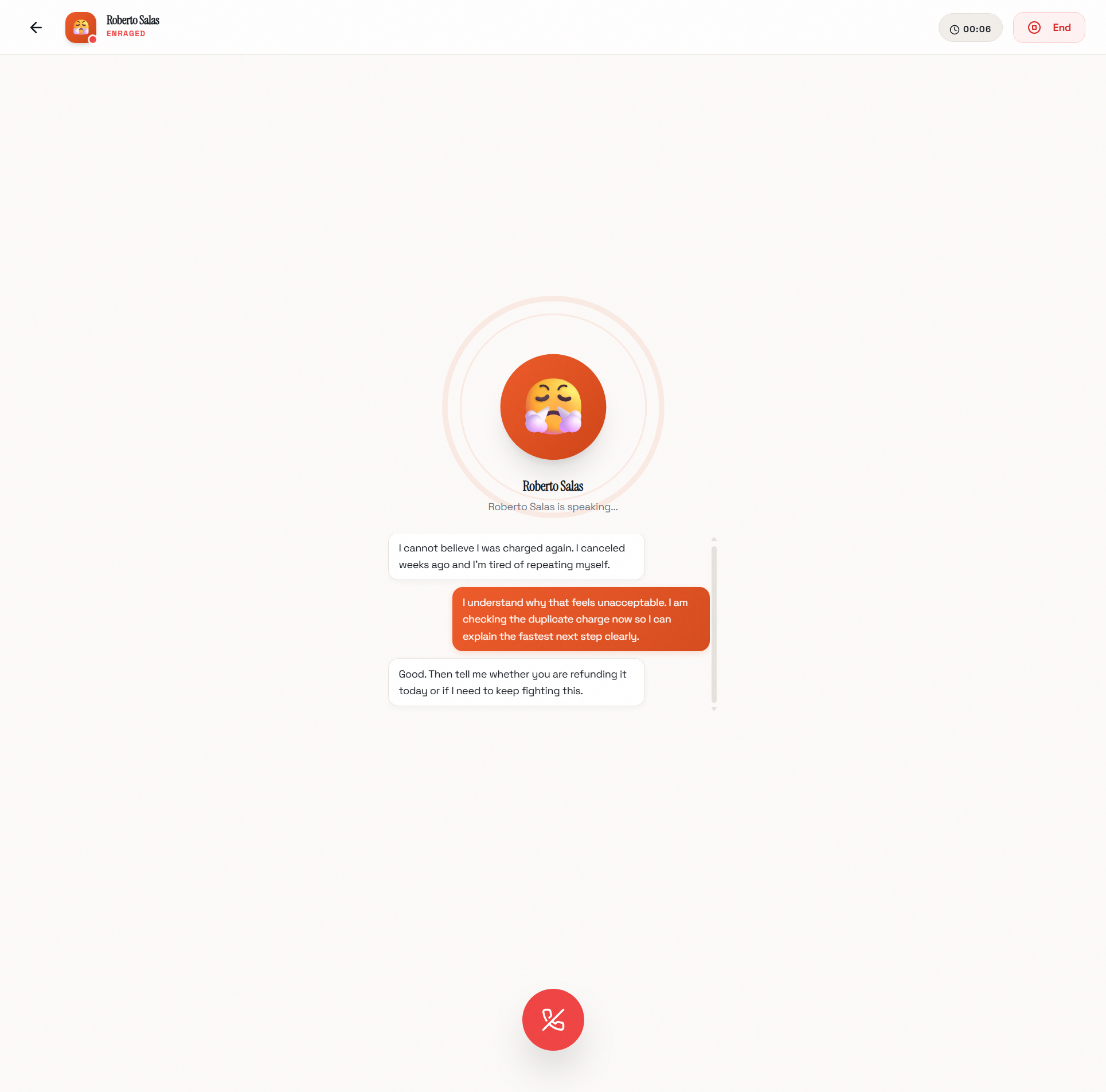
ScenarioCoach was built to solve this gap. It's a voice-first conversation simulator that puts you voice-to-voice with hyper-realistic AI opponents who argue back, get emotional, use manipulation tactics, and force you to think on your feet, just like a real difficult conversation. But unlike real life, there are no consequences for mistakes. You can practice the same conversation ten times, trying different approaches, until you find the one that works.
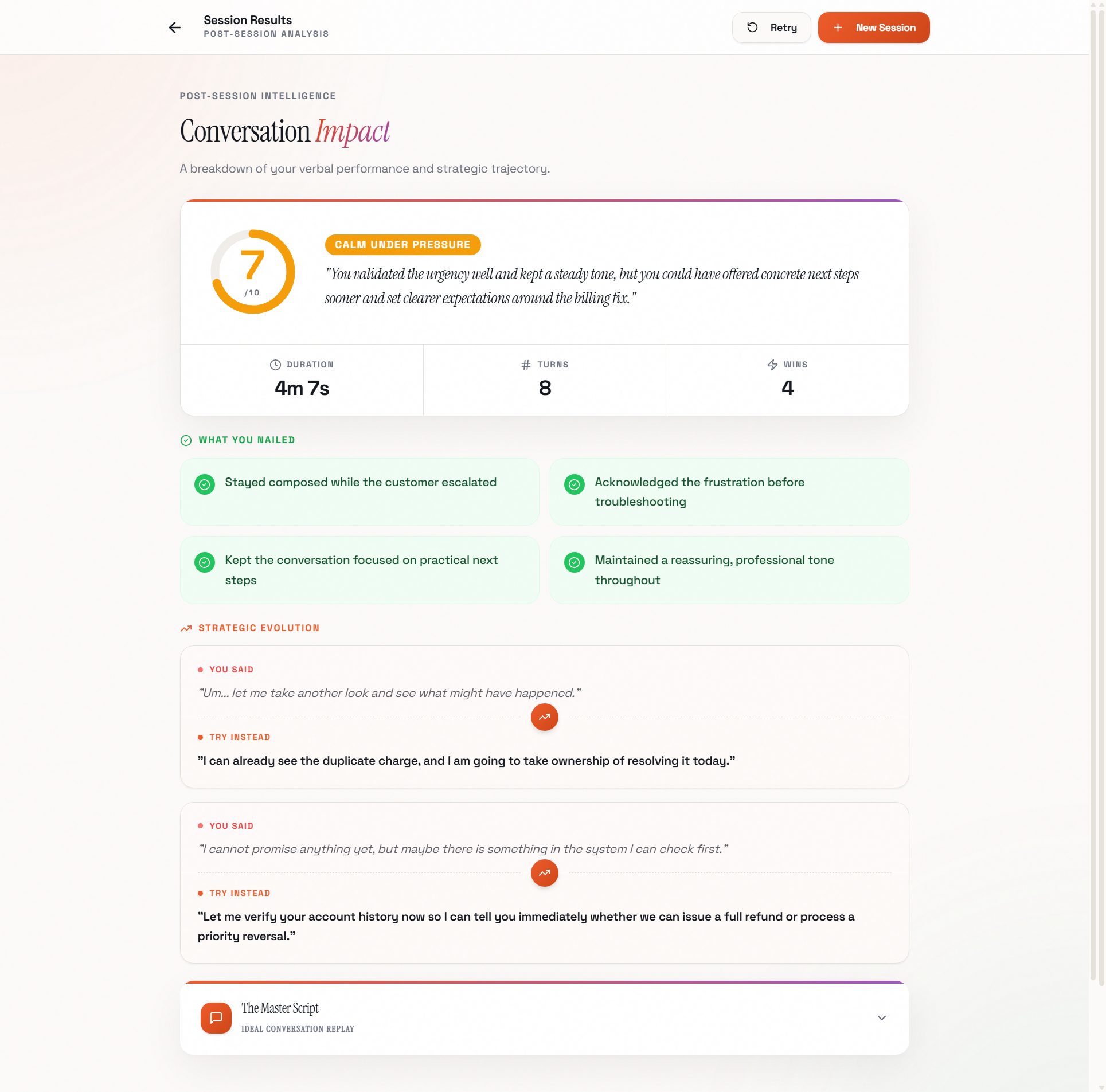
What makes ScenarioCoach truly unique is what happens after the conversation ends. The app doesn't just say "good job." It provides detailed coaching analysis with specific scores across multiple dimensions (empathy, assertiveness, problem resolution, emotional control), pulls exact quotes from your conversation to show what worked and what didn't, and then generates an ideal script showing exactly how a communication expert would have handled the same situation. The final touch: that ideal script is read back to you in your own cloned voice, so you can literally hear yourself delivering the perfect response. This creates a powerful mental rehearsal effect. When the real moment comes, you've already heard yourself succeed.
I built ScenarioCoach because I believe everyone deserves a safe space to practice being brave. Whether you're a customer service rep preparing for an escalated call, a manager about to deliver tough feedback, a job candidate facing an aggressive interviewer, or simply someone who needs to set boundaries with a difficult person in their life, you shouldn't have to face these moments for the first time when the stakes are highest.
How I structured conversations with MeDo to build the project
I built ScenarioCoach entirely through MeDo's conversational AI interface, leveraging its ability to generate full-stack applications from natural language descriptions. The process was iterative and spanned multiple focused conversation sessions, each targeting a specific layer of the application.
Session 1: Core Architecture & Foundation
I started by describing the high-level concept to MeDo: "A mobile-first web app where users practice difficult conversations with AI characters that have realistic personalities and emotional responses." MeDo scaffolded the entire project structure with React 18, TypeScript, Vite, Tailwind CSS with shadcn/ui components, React Router for navigation, and Supabase for the backend. The initial generation included the full authentication flow, database schema, and a clean component architecture with proper separation of concerns.
Session 2: Scenario System & AI Pipeline
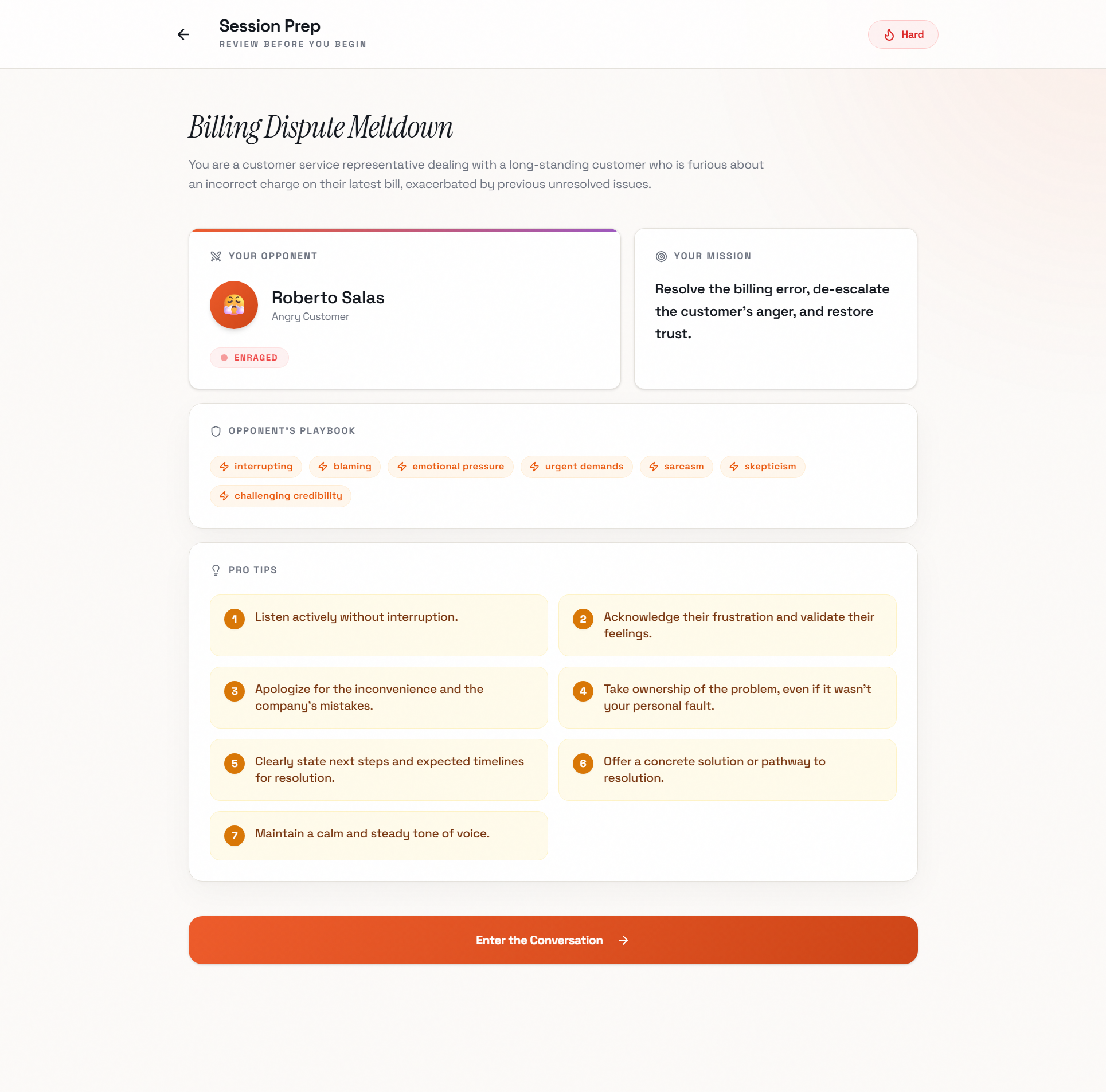
I described the scenario generation system I envisioned: "Before each practice session, the AI should analyze the chosen scenario and generate a complete character profile with their emotional state, personality traits, tactics they'll use, and coaching tips for the user." MeDo built the entire pipeline using Gemini 2.5 Flash through its gateway API, including structured JSON output schemas that ensure consistent scenario generation across all languages. It also created the preparation screen UI that displays strategy tips and emotional context before the user begins.
Session 3: Real-Time Voice Integration
This was the most complex conversation. I described the voice experience: "Users should be able to have a real-time voice conversation with the AI character, like a phone call. The AI should respond with appropriate emotions and the latency should be minimal." MeDo generated the complete integration with an external voice AI API, including WebSocket connection management, audio encoding and decoding, microphone capture with Web Audio API, audio playback queue management, and the dynamic agent creation system that injects the scenario's persona into the voice agent.
Session 4: Coaching & Analysis Engine
I asked MeDo to build the post-session analysis: "After the conversation ends, analyze the full transcript and provide detailed coaching with scores from 1 to 10, specific moments that were handled well with exact quotes, areas for improvement with alternative phrasings, and a complete ideal script." MeDo created the multi-dimensional scoring system, the quote extraction logic, and the results UI with animated score reveals and expandable coaching sections.
Session 5: Voice Cloning & Ideal Response Playback
This is the signature feature: "Let users record a voice sample, clone their voice, and then play back the ideal coaching script in their own cloned voice." MeDo implemented the voice cloning flow using an external voice cloning API, the audio recording interface, voice management capabilities, and the text-to-speech integration that reads the ideal script using the user's cloned voice.
Session 6: Polish, Multi-language & Mobile UX
Final iterations made the app feel professional: 10 language support with proper localization of all UI strings and AI prompts, mobile-first responsive design, smooth page transitions with Framer Motion, proper error handling and loading states, and accessibility improvements.
Throughout the process, I used MeDo's visual editor to fine-tune spacing, colors, and component layouts without needing to manually adjust CSS. The iterative conversation approach allowed me to build a complex, production-ready application in a fraction of the time it would have taken with traditional development.
The most impressive feature MeDo helped create
The standout feature is the real-time full-duplex voice conversation system combined with the post-session voice cloning playback. Together they create an experience that feels like talking to a real person and then hearing yourself become better.
The Voice Conversation Engine
MeDo generated a sophisticated real-time voice system that includes:
Dynamic Agent Creation: Before each voice session, the app programmatically creates a custom conversation agent with the scenario's specific persona, emotional profile, language, and behavioral instructions injected as the system prompt. This means every conversation feels unique. An angry customer sounds and behaves completely differently from an aggressive interviewer.
Full-Duplex WebSocket Audio Streaming: The implementation handles bidirectional audio, capturing microphone input via Web Audio API, encoding it, and streaming it to the voice service while simultaneously receiving, decoding, and playing back the agent's audio responses through a managed playback queue. The result is natural, interruption-capable conversation with minimal latency.
Emotion-Aware Responses: The AI opponent's system prompt includes emotion markers that guide both the content and delivery of responses, making the conversation feel emotionally authentic rather than flat and robotic.
Graceful Session Lifecycle: Connection management handles network interruptions, reconnection attempts, clean session termination, and proper transcript extraction from the voice session for subsequent coaching analysis.
The Voice Cloning Playback
After the coaching analysis generates the ideal script, users can hear it spoken in their own voice. MeDo built the complete flow: a guided recording interface that captures a voice sample, the voice cloning API integration, secure voice storage and management, and the text-to-speech generation that synthesizes the coaching script using the user's cloned voice with a multilingual model that supports all 10 languages.
This combination of practicing a conversation in real-time voice, getting scored, and then hearing yourself deliver the perfect version creates a uniquely powerful learning loop that simply doesn't exist in any other app.
How I used plugins or APIs to extend functionality
ScenarioCoach integrates multiple external services to create a seamless, production-quality experience.
MeDo's Gemini AI Gateway
The backbone of all intelligence in the app. I use Gemini 2.5 Flash through MeDo's authenticated gateway for three distinct AI tasks:
- Scenario Generation: Structured JSON output that creates complete character profiles, emotional states, tactics, and coaching preparation tips
- Live Chat (Text Mode): Server-Sent Events streaming for natural, low-latency text conversations where the AI stays in character
- Coaching Analysis: Deep transcript analysis producing multi-dimensional scores, quoted evidence, improvement suggestions, and complete ideal scripts
Each task uses carefully crafted prompts with JSON schema constraints to ensure consistent, parseable output across all 10 supported languages.
External Conversational Voice AI API
For real-time voice conversations, I integrated with an external conversational AI API that provides full-duplex voice communication:
- Dynamic agent creation that programmatically creates conversation agents with scenario-specific personas and voices
- Authenticated WebSocket connections for secure real-time audio streaming
- Bidirectional audio streaming with sub-second latency for natural voice conversations
- Automatic voice selection that picks the most appropriate voice for each character based on scenario context
Text-to-Speech & Speech-to-Text
In text chat mode, an external API vocalizes the AI opponent's responses, making even the text-based experience feel immersive. The multilingual model provides natural prosody across all supported languages. A transcription service converts user voice input, enabling a hands-free experience where users can speak their responses instead of typing. This is critical for mobile use and for simulating the pressure of real-time verbal responses.
Voice Cloning API
Users can upload a voice sample and create a synthetic clone of their own voice. This clone is then used to synthesize the coaching "ideal response" script, creating the powerful effect of hearing yourself deliver the perfect answer.
Supabase (Backend-as-a-Service)
Provides the complete backend infrastructure:
- Authentication: Email and password auth with secure session management
- PostgreSQL Database: Stores user profiles, practice sessions with full JSONB transcripts, coaching results, and voice preferences, all protected by Row Level Security policies
- Edge Functions (Deno): Three serverless functions (chat, coach, and voice) that handle API key management and proxy requests securely without exposing credentials to the client
- Storage: Audio bucket for caching generated audio files, reducing API calls and improving response times
Additional Libraries
Framer Motion provides smooth page transitions and micro-animations that make the coaching reveal feel rewarding. Recharts powers visual score displays in the results dashboard. Zod with React Hook Form enables type-safe form validation for the custom scenario creator. SSE stream parsing libraries enable real-time chat token display.
Built With
- medo


Log in or sign up for Devpost to join the conversation.