-
-
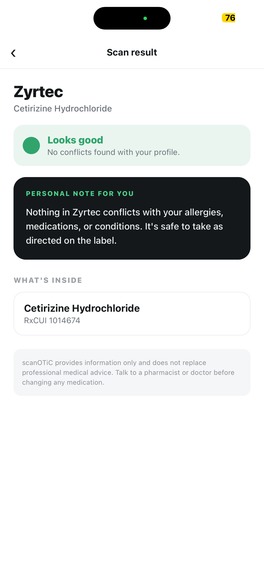
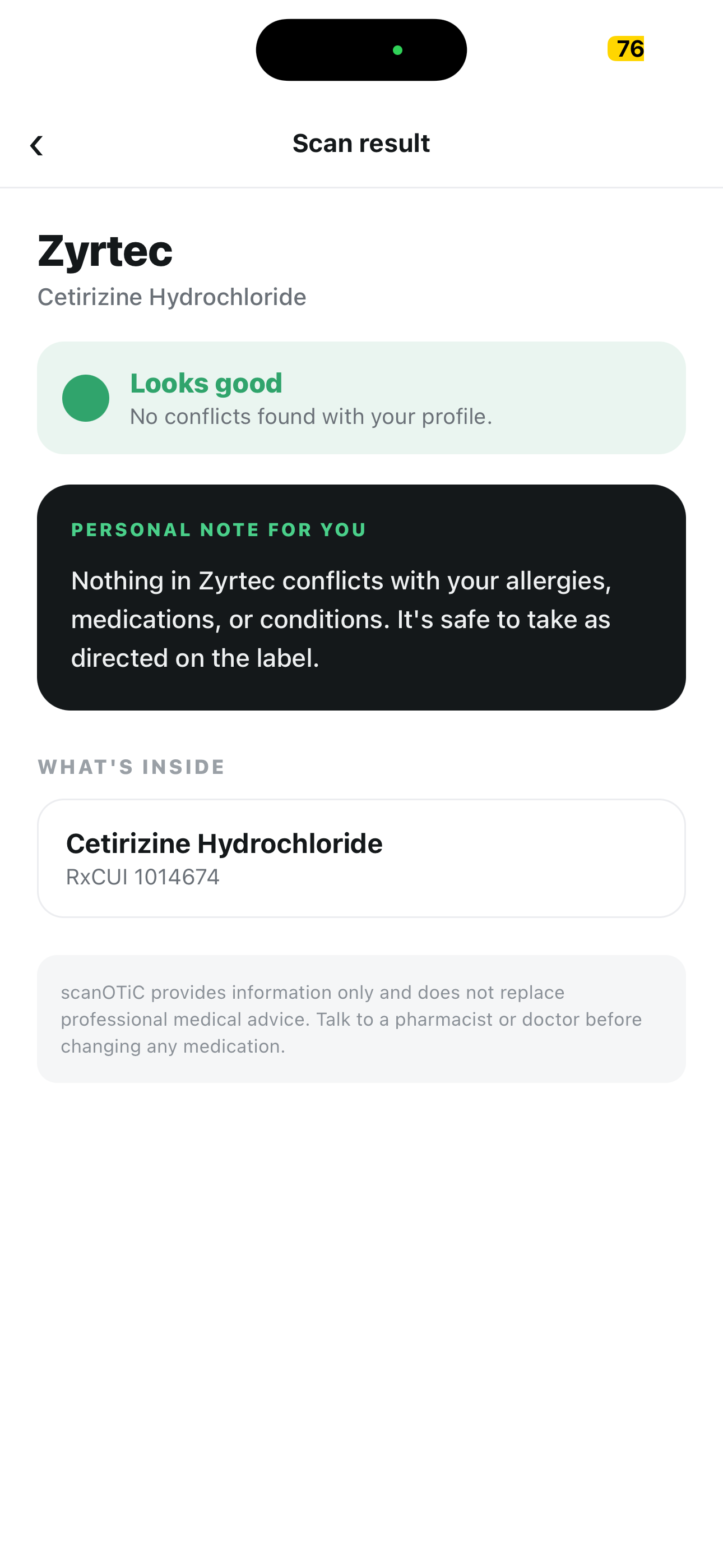
Our app gives the green light to products that have no visible conflict with the user profile
-
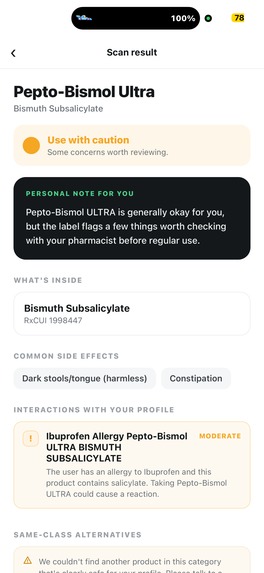
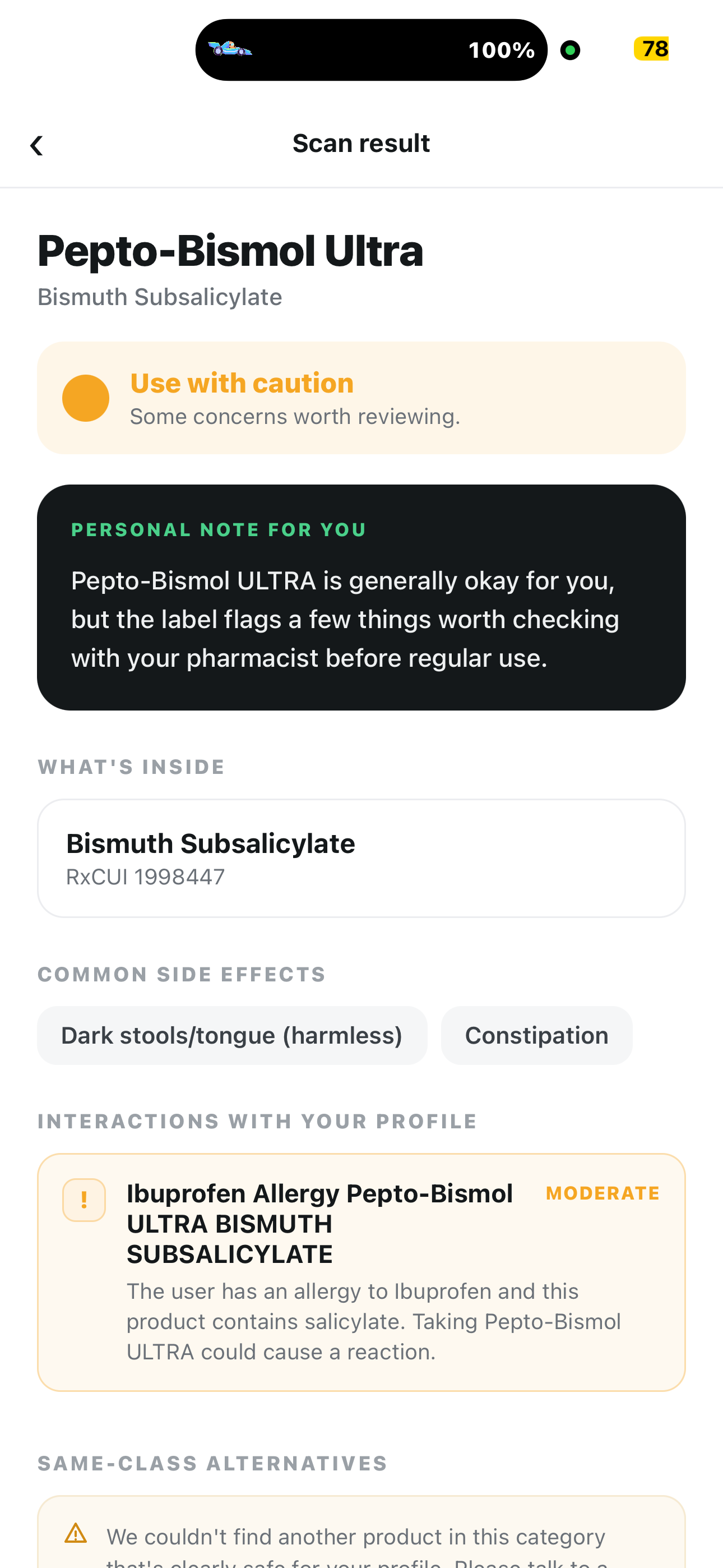
Our app can flag products to keep users aware of potential complications
-
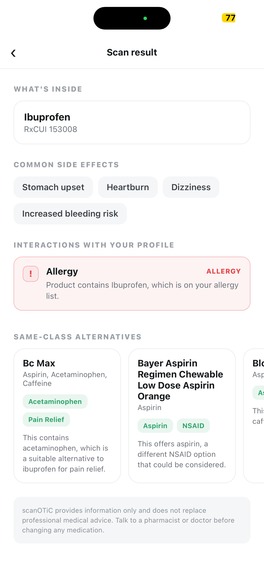
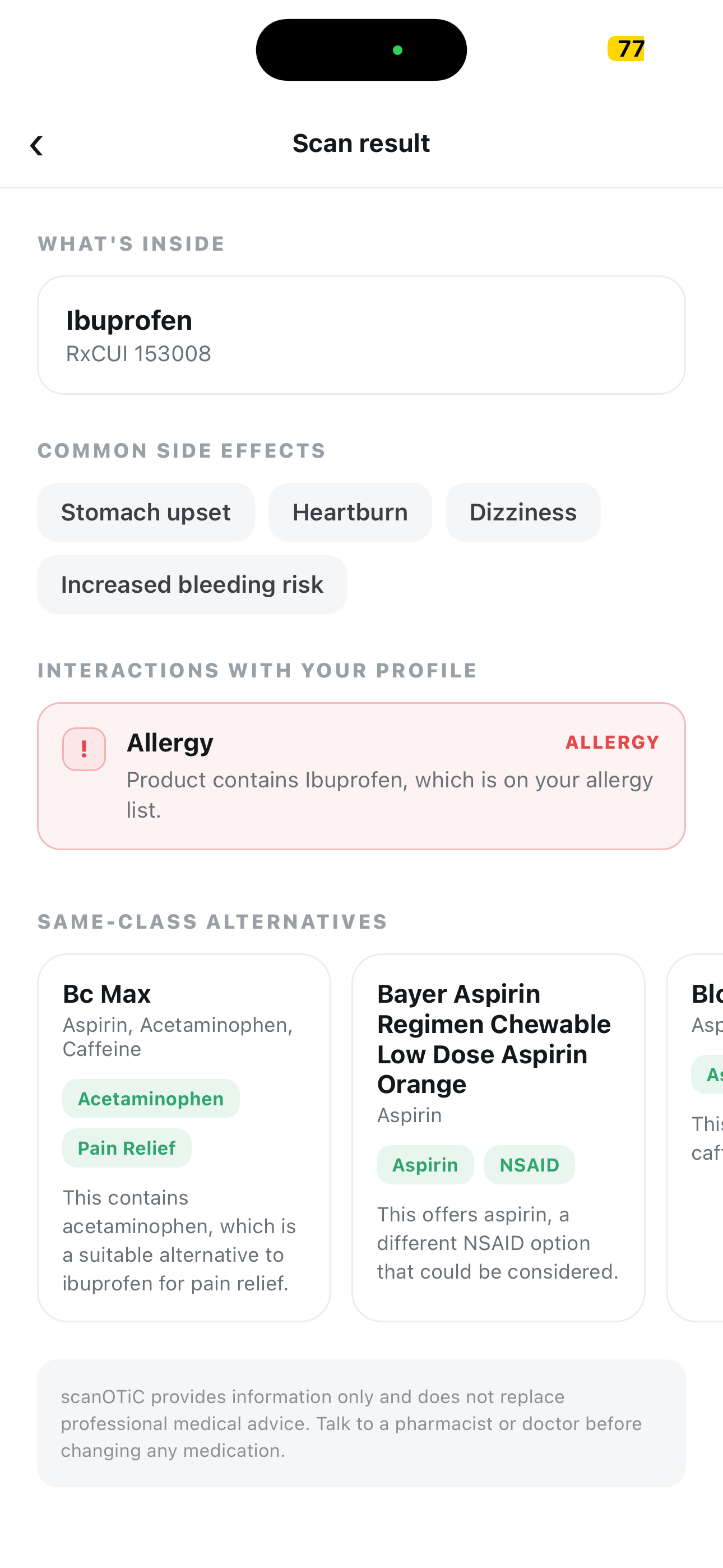
Our app recommends other products with similar purposes if a searched product is unsuitable due to allergies, other medications, etc.
The Problem
As a person stands in a pharmacy aisle trying to determine the safety of an OTC medication, the medical information required is available; however, it is obscured by:
- Microscopic typeface on FDA labeling, which is effectively useless for the aged and visually challenged
- Jargon-laden medical language written for liability, rather than comprehension by humans
- Confusing brand name labeling that obscures common active ingredients
- Danger of polypharmacy, where drug interactions increase with use of multiple medications
Why Does This Matter?
This is not a small problem. It is a systemic problem of health equity:
- ~1.3 million visits to emergency rooms each year in the US are due to adverse drug events, which often involve OTC products that the patients thought were safe.
- Unintentional overdose of acetaminophen is the most common cause of acute liver failure, often resulting from inadvertently using several brands of the same medication.
- Seniors suffer the most. 4+ medications per day, the weakest vision, the highest potential for interaction and the poorest readability of labels.
- Differences in health literacy correlate with demographics. Non-native speakers of English and poorer people pay the price of jargon-filled labels.
All the necessary information to avoid all these issues already exists in public databases. The problem is not the lack of data, but accessibility, translation, and customization. And so we developed a digital patient advocate.
What Does Our App Do?
Three taps:
- Onboard once: name, age, allergies, medications, conditions, lifestyle factors
- Point at any OTC barcode
- Get a Red / Yellow / Green verdict in seconds, plus a personal note in plain second-person English, active ingredients, common side effects, and same-class alternatives if you should pick something else
Every result is personalized. A scan of the same Advil box returns:
- GREEN for a healthy adult
- YELLOW for a warfarin patient, with bleeding risk explained by name
- RED for someone allergic to ibuprofen, and the LLM is not allowed to override it
How We Built It
| Layer | Stack |
|---|---|
| Mobile | Expo / React Native, on-device profile in AsyncStorage |
| Backend | Flask + openFDA drug catalog + Drug Facts labels |
| AI | Gemma 3 running locally via Ollama; no cloud, no API keys, no health data leaving the device |
| Cache | SQLite + ~80 pre-seeded UPC mappings → demo works on flaky Wi-Fi |
The analysis pipeline is layered:
- Deterministic allergy check runs first → produces a hard verdict ceiling the LLM cannot soften
- Gemma 3 then layers nuanced condition and interaction concerns from the label
Challenges We Ran Into
- Messiness in openFDA’s actual data: Arrays posing as strings, wandering parallel arrays, four overlapping pharmacological classes
- Format problem with Barcode: iPhones give 12 digits; openFDA keeps 13
- Maintaining a 4B-parameter local model’s honesty: It will conjure problems for itself, exhaust its context window with 5KB warnings, and wrap JSON in defensive language unless you reign it in completely
What We Learned
- Put a deterministic layer below the LLM. Using a Python
max()on two risk levels is better than a "be careful" instruction to the LLM. - Observe the context window limitations. Now each Drug Facts is limited to 1200 characters.
- APIs should be translated when they cross the boundary. Everything from openFDA is parsed to typed dataclasses.
- Healthcare reinterprets every default setting. Unknown verdict equals YELLOW and not GREEN because you optimize for being confidently wrong.
What's Next
- Supplements + prescriptions broaden the corpus beyond OTC
- RxNav drug-drug interactions as a second deterministic layer
- Full accessibility: VoiceOver / TalkBack, TTS read-aloud, dynamic type
- Multilingual: Spanish, Mandarin, Vietnamese
- Household profile sharing for caregivers managing elderly parents
- "Share this with my pharmacist" button that closes the loop honestly
Built With
- expo.io
- flaskapi
- llm
- openfda



Log in or sign up for Devpost to join the conversation.