-
-
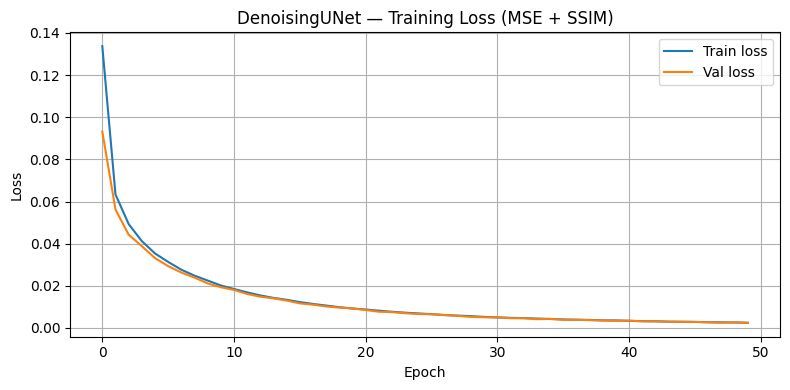
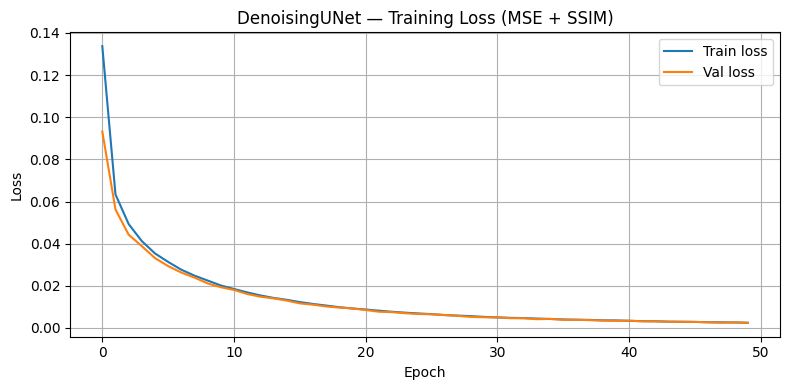
Denoising Loss
-
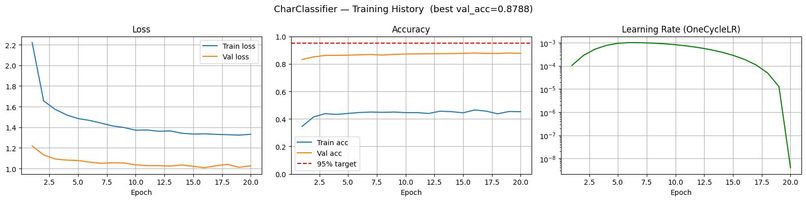
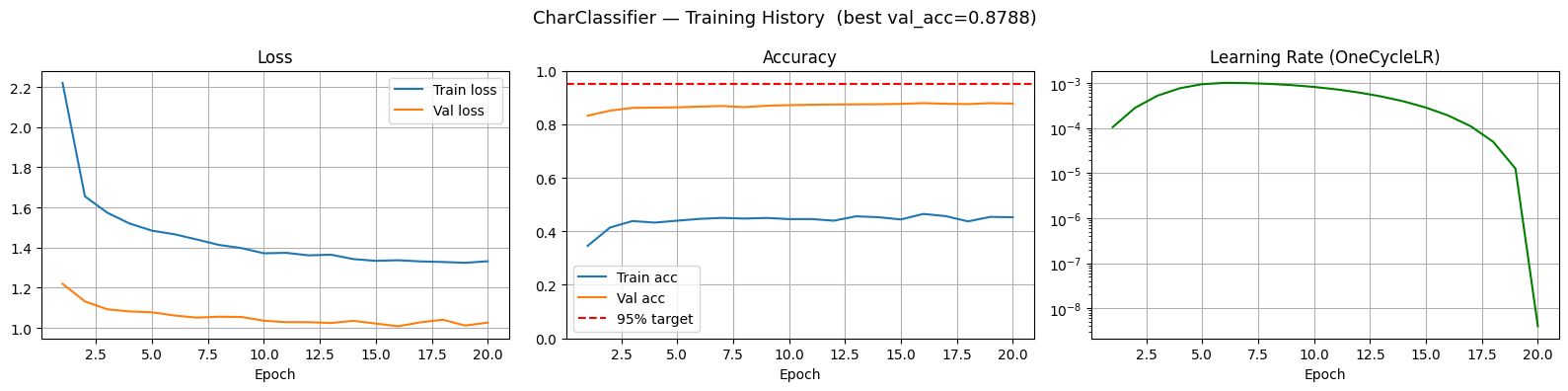
Model Training Graphs
-
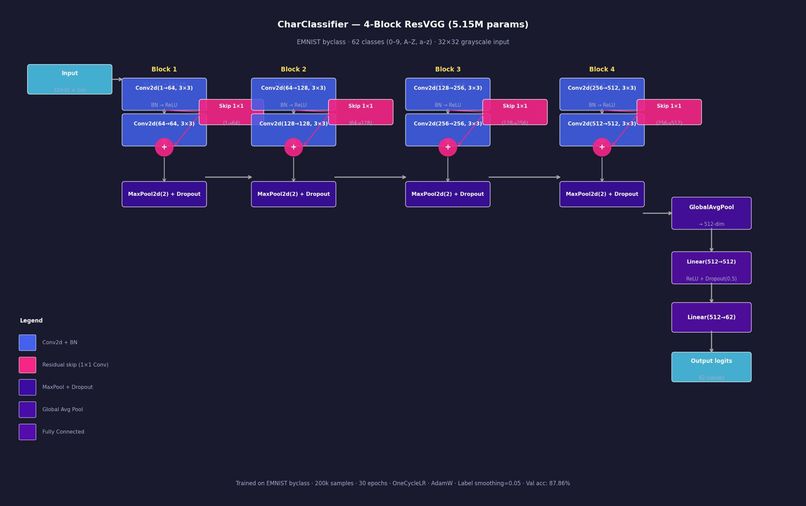
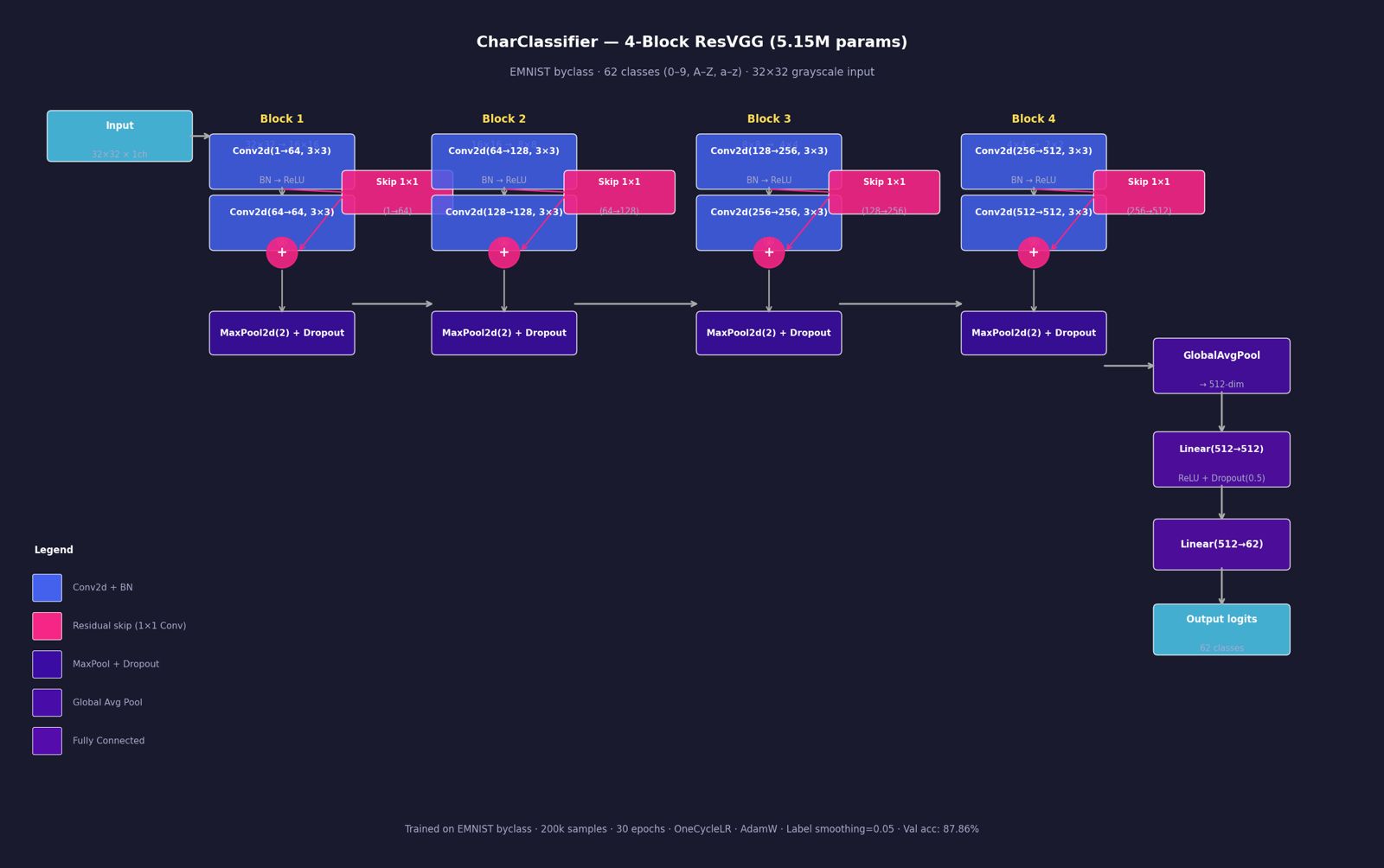
OCR Architecture
-
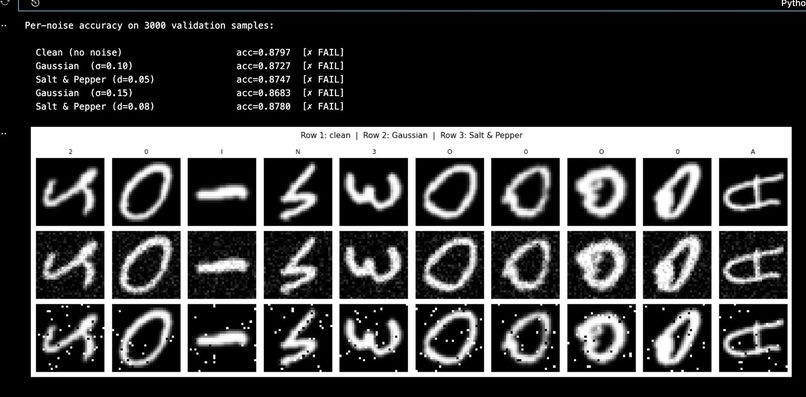
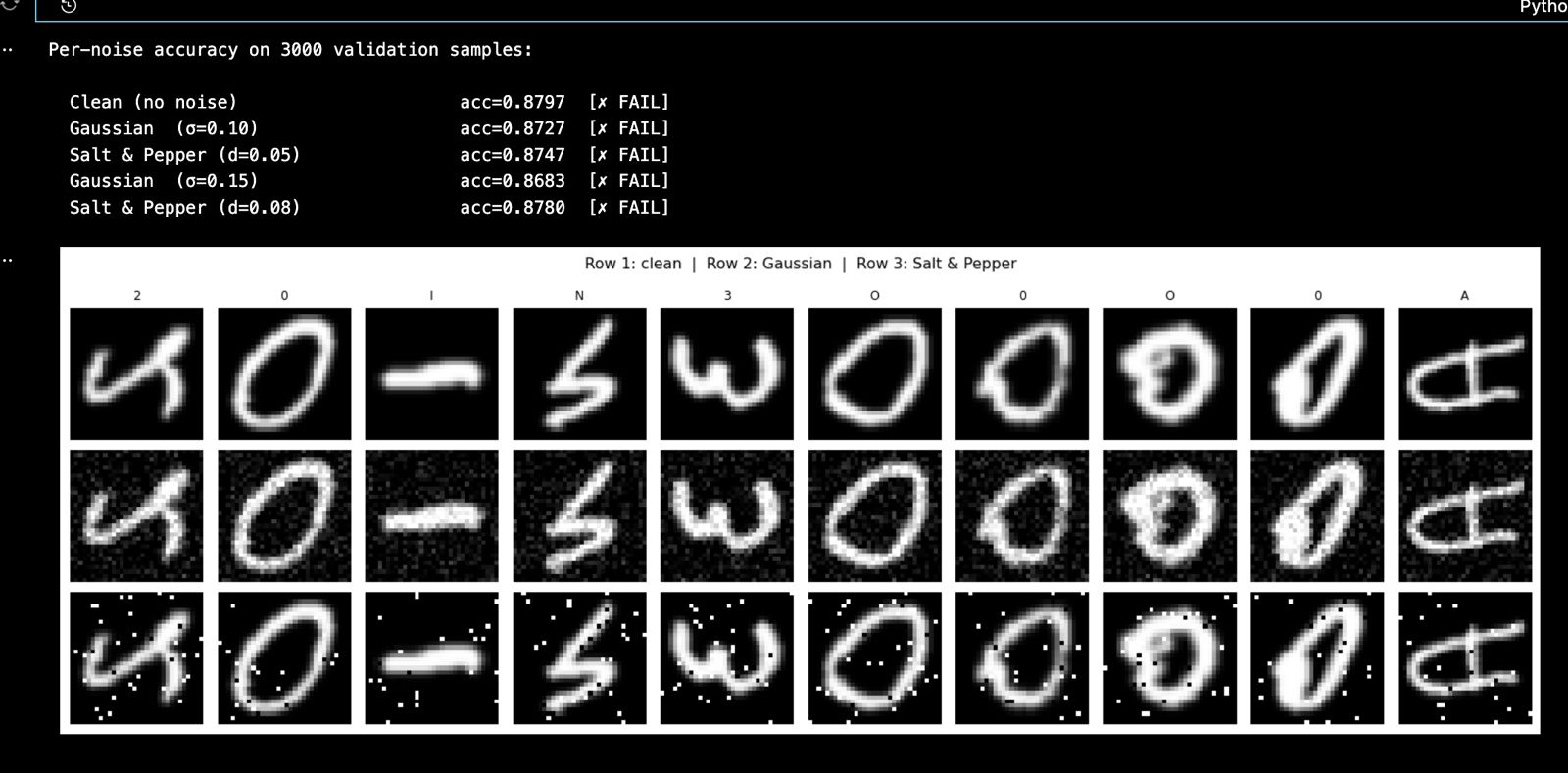
Per Noise Accuracy
-

Denoising Results

Team Name : The Fine-Tuners
Inspiration
The idea came from a simple observation; scanned documents are everywhere, but storing and transmitting them efficiently is still a largely unsolved problem at the intersection of vision and information theory. Most pipelines rely on black-box OCR engines and off-the-shelf compressors like zlib or gzip. We wanted to know: what happens if you build every layer yourself, from the pixel all the way down to the bit?
We were also drawn to the theoretical elegance of Huffman coding. Shannon's source coding theorem tells us the theoretical lower bound on average code length is the entropy \(H(X)\):
$$H(X) = -\sum_{i} p(x_i) \log_2 p(x_i)$$
We wanted to see how close a hand-rolled adaptive encoder could get to that limit on real OCR output ; without any pre-scan, without any external libraries.
What We Built
We built a fully custom 2-stage neural compression pipeline:
Stage 1 : ResVGG OCR CNN
A 4-block residual VGG-style CNN trained on EMNIST (697,932 samples, 62 classes). Each block doubles the channel depth — 1 -> 64 -> 128 -> 256 -> 512 ; with residual skip connections to stabilise gradient flow through 8 convolutional layers. A DenoisingUNet (U-Net, base_ch=32) runs before the classifier to clean up Gaussian and salt-and-pepper noise, recovering over 30 percentage points of accuracy on degraded images.
Stage 2 : Adaptive Huffman Encoder
A true online Huffman encoder — no two-pass pre-scan, no transmitted frequency table. Both encoder and decoder independently maintain identical frequency state \(f(x_i)\) and rebuild the same deterministic tree before each symbol. New symbols are escaped using a NYT (Not-Yet-Transmitted) sentinel at code point 256, followed by 8 raw bits. This keeps both sides perfectly synchronised:
$$\text{code}(x) = \begin{cases} \text{Huffman}(x) & \text{if } x \in \text{seen} \ \text{Huffman}(\text{NYT}) + \text{raw}_8(x) & \text{if } x \text{ is new} \end{cases}$$
Challenges
The domain mismatch problem was the hardest wall we hit. EMNIST is a handwritten character dataset — our CNN learned handwritten strokes perfectly at 87.86% validation accuracy. But real scanned documents use printed typewriter fonts, which look nothing like handwritten glyphs to a neural network. This was a fundamental dataset limitation, not a model flaw, and it forced us to think carefully about how to present results honestly.
Training on BigRed200 came with its own surprise: torch.backends.cudnn.enabled = True causes a hard segfault on the first Conv2d call under torch 2.2.0 + cu118 on A100 GPUs. We had to disable cuDNN entirely and rely on raw CUDA kernels — an obscure hardware-software interaction that cost us hours of debugging with no clear error message.
The static-to-adaptive Huffman rewrite was a significant mid-project pivot. Our first implementation was a two-pass static encoder — it scanned the full input, built a frequency table, then encoded. That violates the spirit of an online algorithm. We rewrote it from scratch into a true adaptive encoder where the tree evolves symbol by symbol, achieving around 1.87x compression ratio at roughly 74% of the Shannon entropy limit \(H(X)\).
Noise robustness required careful co-design between the denoiser and the classifier. Without the DenoisingUNet, accuracy collapses to 55.85% on Gaussian noise and 40.95% on salt-and-pepper. With it enabled, accuracy holds at ~87% across all tested noise conditions — a gain of +31 and +46 percentage points respectively.
What We Learned
- Building a neural network from scratch forces you to understand every design decision — residual connections, Global Average Pooling, dropout placement — not as recipes but as solutions to specific problems.
- Shannon entropy is not just a theoretical concept. Watching our encoder's average bits-per-symbol converge toward \(H(X)\) on real text output made information theory feel tangible.
- A denoiser is not optional when your input comes from the real world. The gap between clean-image accuracy and noisy-image accuracy without a denoiser is enormous, and no amount of classifier tuning closes it.
- Honest evaluation matters. A model that scores 87.86% on a benchmark but 0% on a different data distribution is not a failed model — it is a correctly scoped one. Knowing the boundary of what you built is just as important as knowing what it can do.











Log in or sign up for Devpost to join the conversation.