-
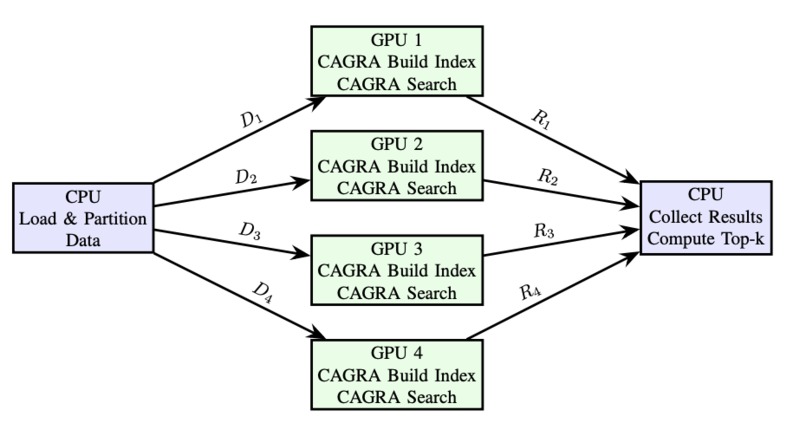
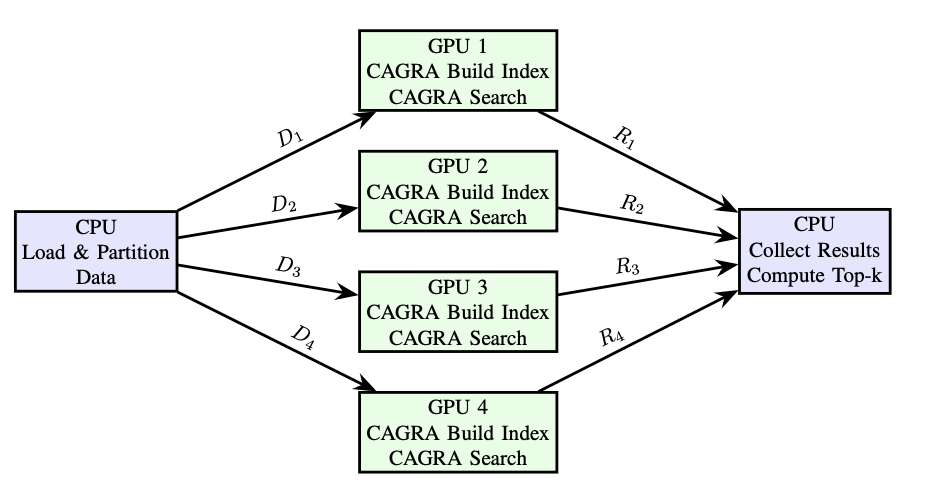
Fig. 1: Multi-GPU CAGRA with CPU coordinating multiple GPUs.
-
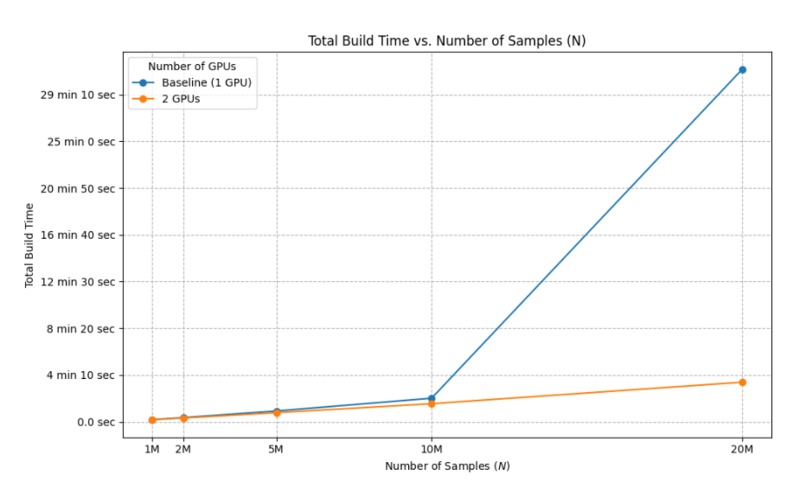
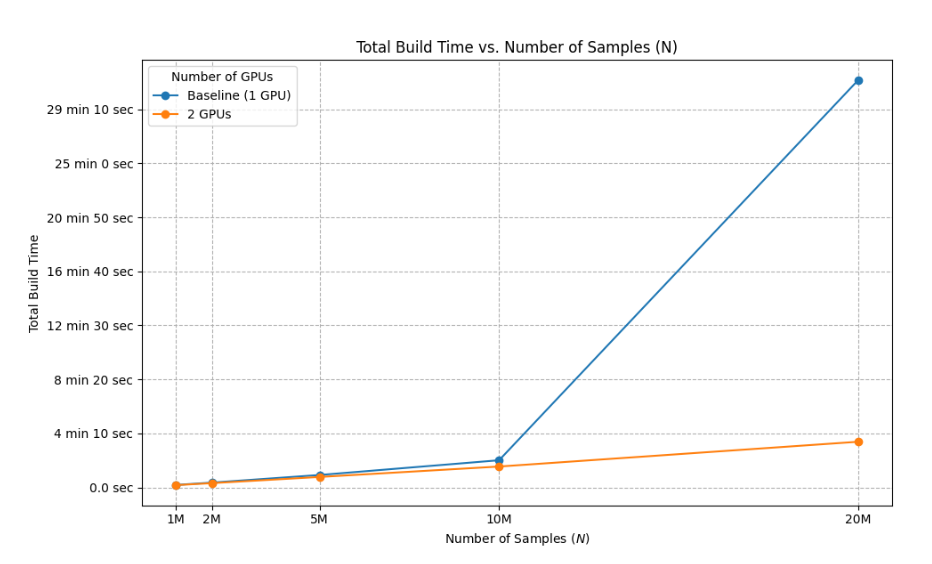
Fig. 2: Index build time comparison.
-
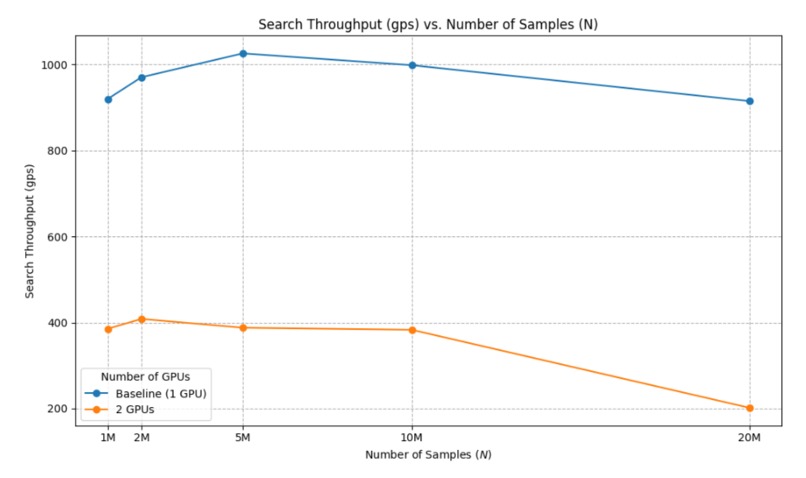
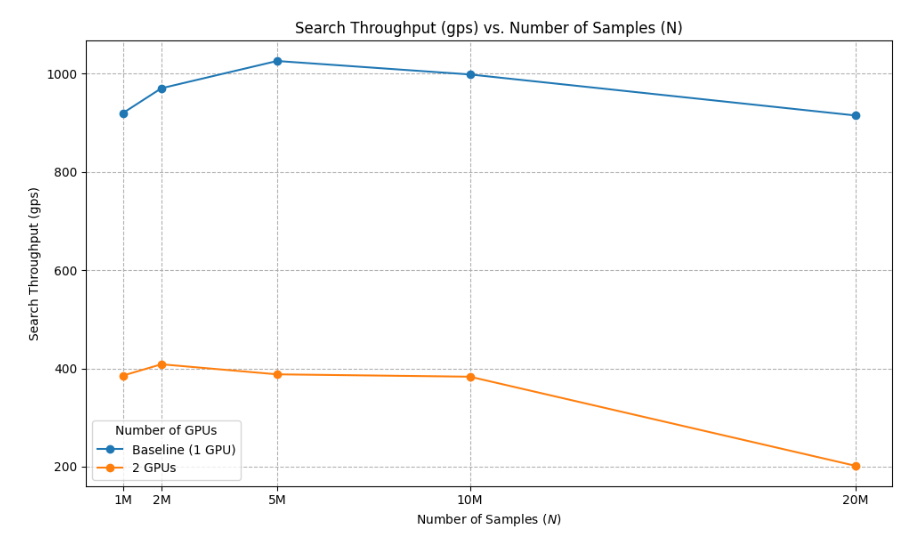
Fig. 3: Query throughput performance comparison.
-
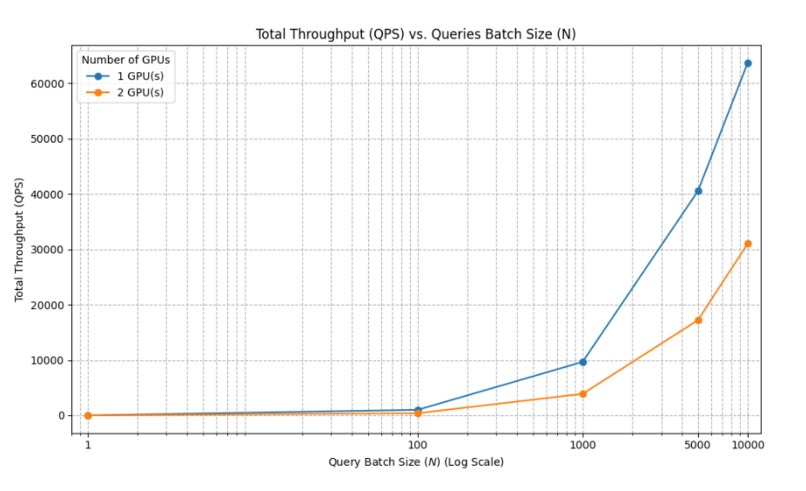
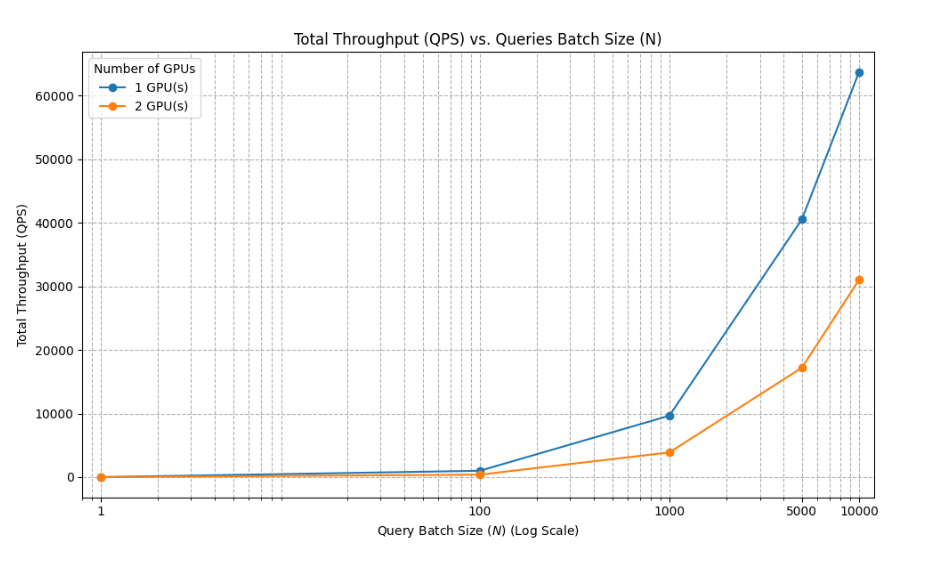
Fig. 4: Query throughput performance comparison.
-
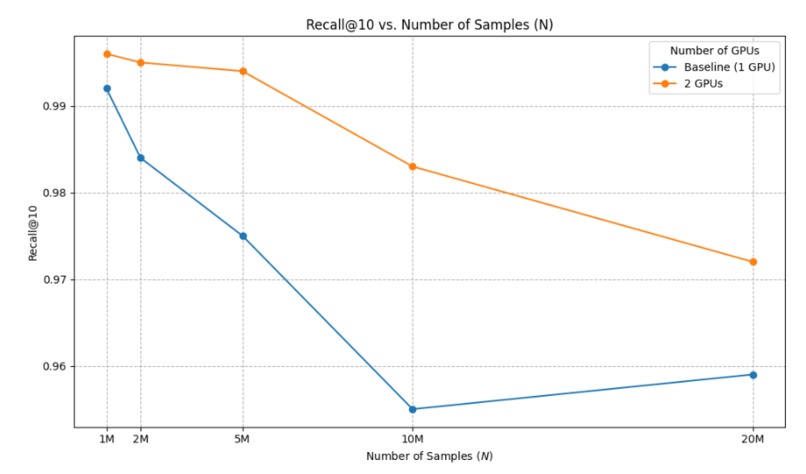
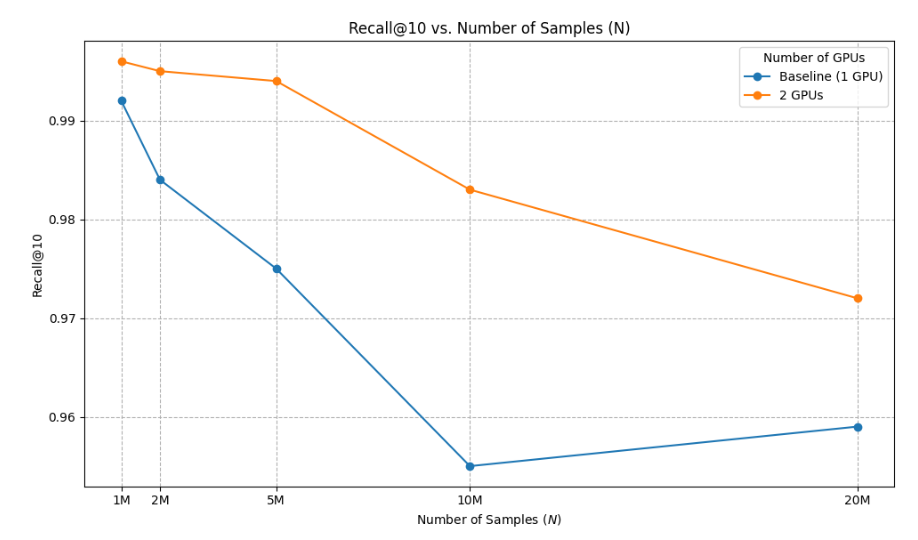
Fig. 5: Recall@10 comparison.
-
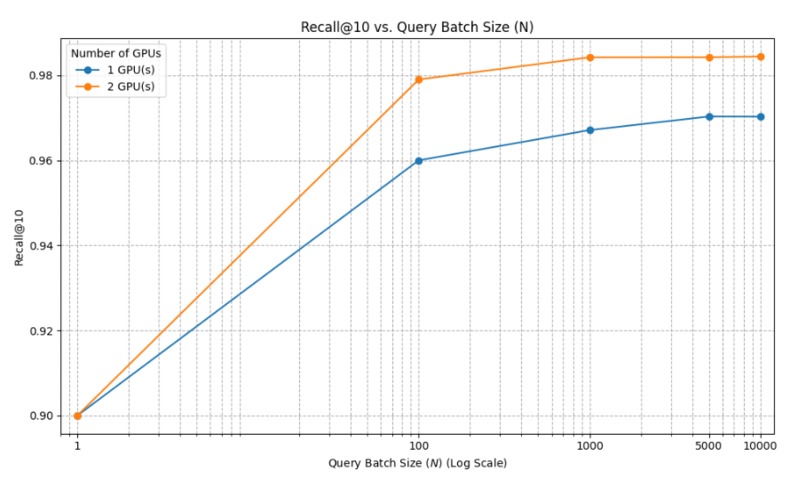
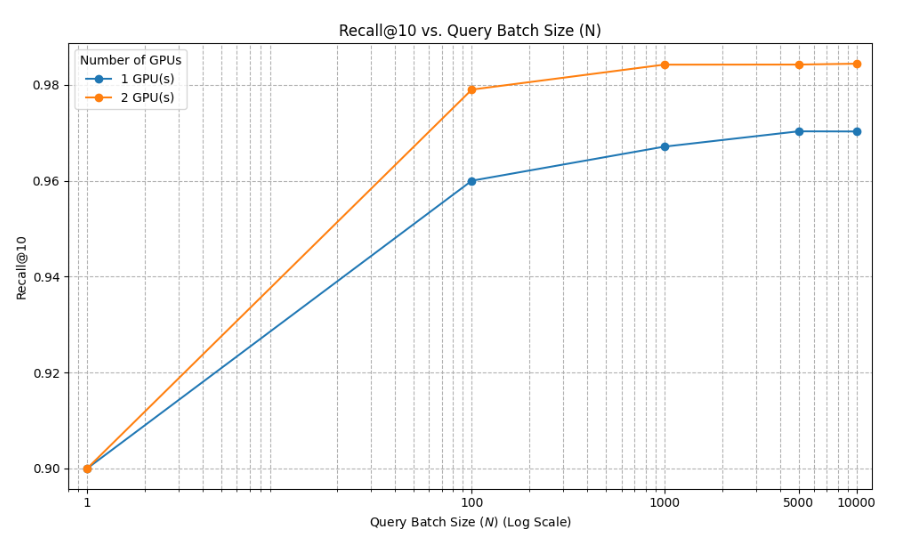
Fig. 6: Recall@10 comparison.
Inspiration
Modern AI systems — from retrieval-augmented generation (RAG) to recommendation engines — rely on Approximate Nearest Neighbor (ANN) search over massive vector databases. While CAGRA is one of the fastest GPU-based ANN engines available today, it has a major limitation: it only runs on a single GPU, which severely caps how large a dataset it can handle.
We were inspired by a simple but important question:
How can we keep GPU-level performance while scaling vector search beyond the memory of a single GPU?
This led us to design a multi-GPU, scalable extension of CAGRA that allows large-scale vector datasets to be indexed and searched efficiently without compression or loss of accuracy.
What it does
Our system extends CAGRA into a multi-GPU ANN engine that can index and search tens of millions of vectors by distributing the workload across multiple GPUs.
Instead of forcing all data into one device, we shard the dataset across GPUs. Each GPU builds and searches its own CAGRA index, and the CPU merges the results to produce the global top-(k) nearest neighbors. This allows us to:
- Scale beyond single-GPU memory limits
- Maintain high recall
- Achieve near-linear speedup in index construction
How I built it
We adopted a Sharded ”Scatter-Gather” Architecture (Figure 1). Instead of building one massive distributed graph (which incurs high communication overhead during traversal), we partition the dataset D into N shards. The CPU acts as a central coordinator that loads and partitions the dataset. It then feeds the partitions and the queries to GPUs, where each GPU builds indices and performs search independently. Finally, the CPU collects results from each GPU and computes a global k nearest neighbors.
To make this work in Python, we used:
- Multiprocessing instead of multithreading to bypass the Python GIL and enable true GPU parallelism
- Shared memory and memory-mapped files (mmap) so multiple processes could access massive datasets without duplicating memory
- Strided and shuffle partitioning to balance data and workload across GPUs
We built a full benchmarking pipeline to measure build time, throughput, and Recall@K on the SIFT1B dataset.
Challenges I ran into
One of the biggest challenges was discovering that Python multithreading does not provide real GPU parallelism because CAGRA holds the GIL during CUDA calls. This forced us to redesign the system around multiprocessing.
Another major challenge was memory management. A 50M-vector dataset is over 25GB — loading it into each process would immediately cause out-of-memory errors. We solved this by implementing zero-copy shared memory loading, which let every GPU process read from the same memory without duplication.
Finally, partitioning data across GPUs introduces a risk of recall loss. Ensuring high accuracy while splitting the graph was a key design challenge.
Accomplishments that I'm proud of
- Successfully scaling CAGRA from a 20M-vector single-GPU limit to over 50M vectors on two GPUs
- Achieving near-linear index build scaling as dataset size increases
- Maintaining 1–2% higher Recall@10 than the single-GPU baseline by merging results across partitions
- Building a fully reproducible benchmarking framework for multi-GPU ANN evaluation
What I learned
This project taught me how machine learning systems meet distributed systems engineering.
I learned how ANN graph search works at a deep level, but more importantly, I learned how GPU memory limits, inter-process communication, and concurrency models shape what is actually possible in practice. I also gained hands-on experience designing scalable architectures, debugging performance bottlenecks, and building data-intensive pipelines.
What's next for Scalable Approximate KNN Search based on CAGRA
There are several exciting directions to push this further:
- Locality-aware partitioning and query routing, so each query only touches the most relevant GPUs
- Pipeline parallelism, overlapping data loading with GPU computation
- Distributed multi-node support, allowing datasets larger than a single machine to be indexed
- Resource-aware scheduling for heterogeneous GPU clusters
These improvements could turn this into a truly production-ready large-scale vector search engine.

Log in or sign up for Devpost to join the conversation.