-
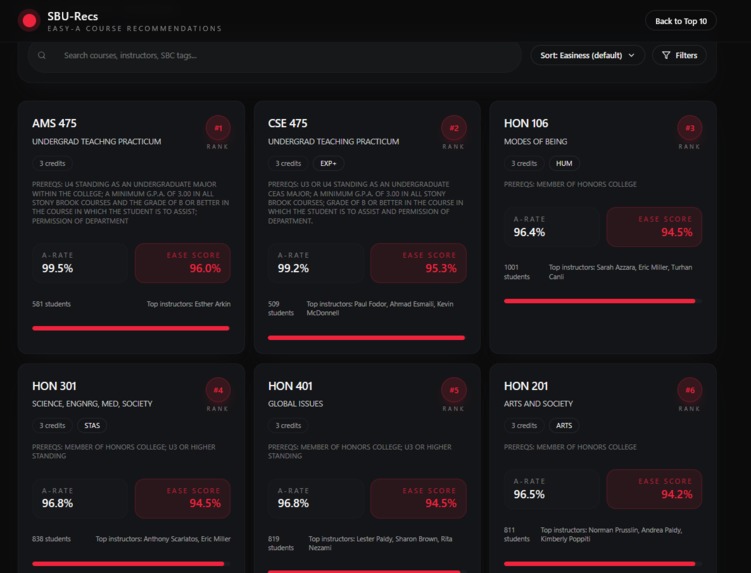
Main Screen
-
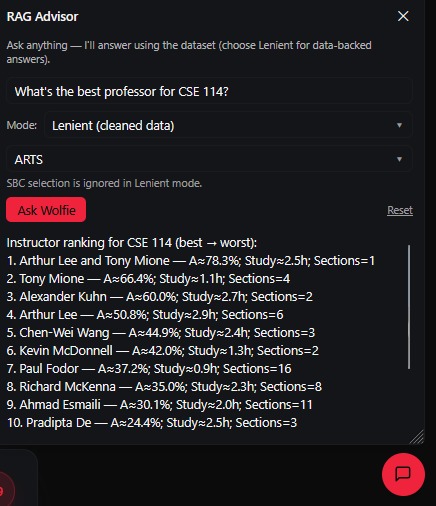
ChatBox
-
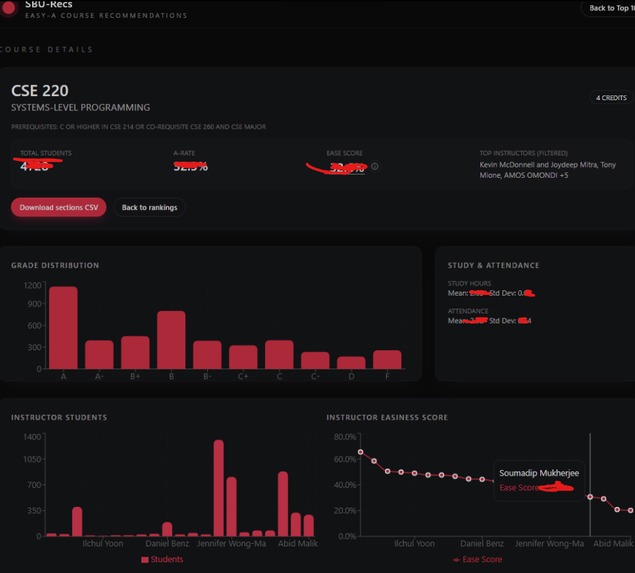
Class View (blurred data for privacy)
-
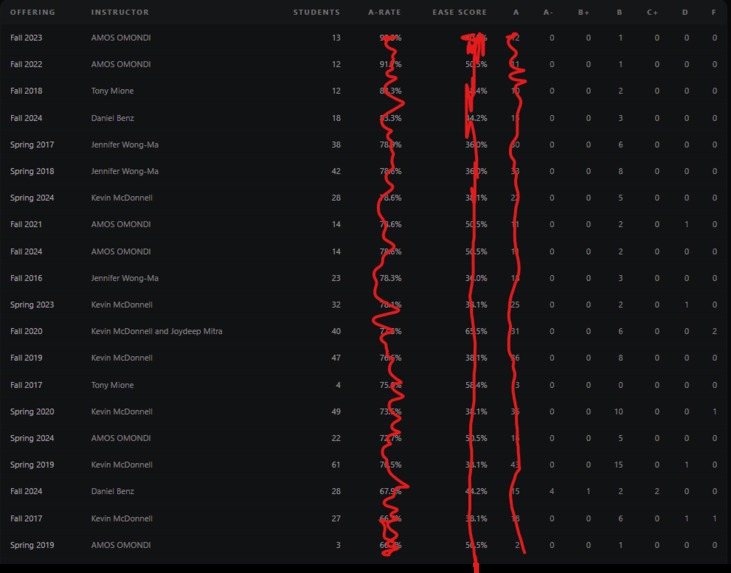
Stats For A Class
-
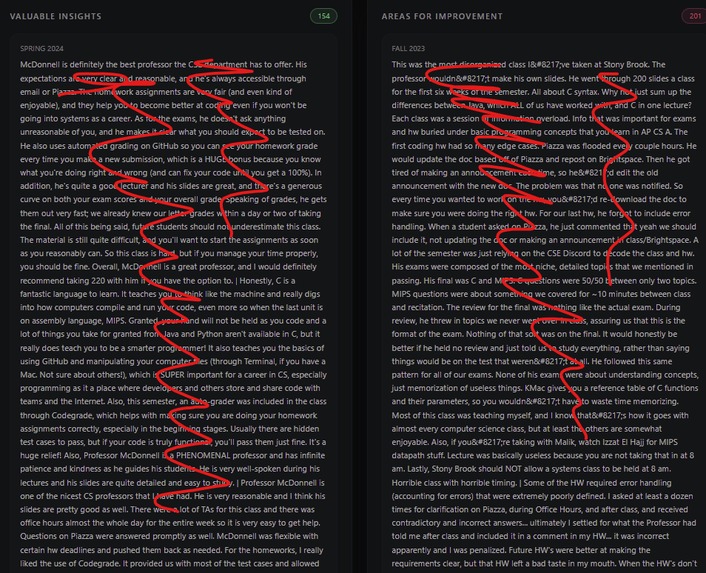
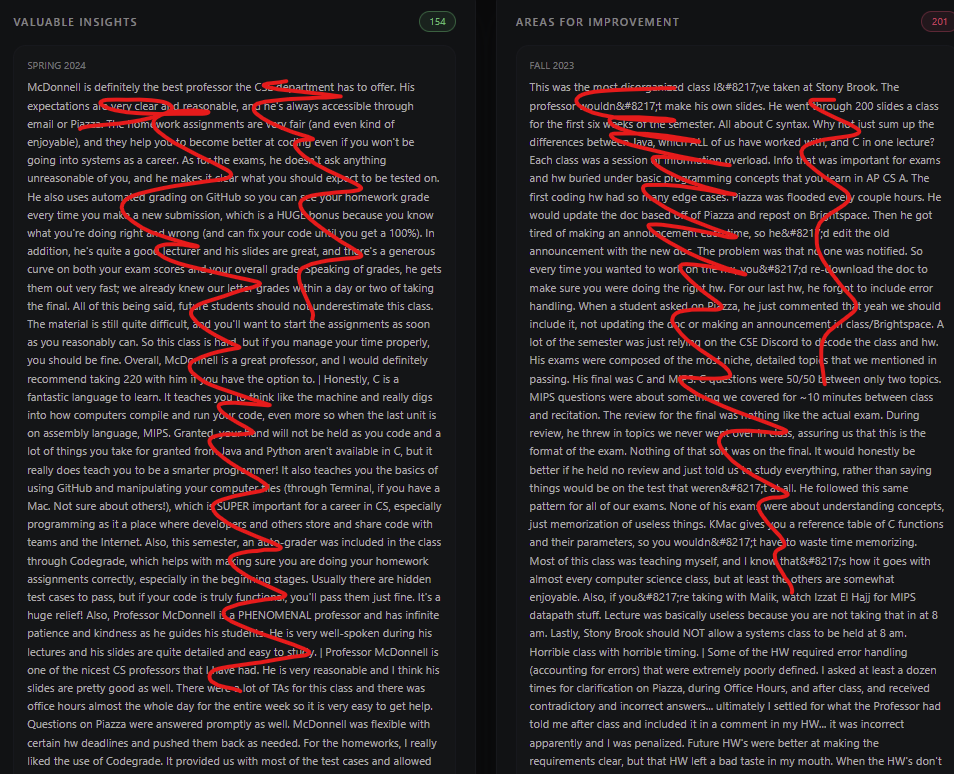
Student comments for each class

Inspiration
People are building their class schedules now for the next semester, and many wish they had a reliable place to see which classes are most GPA-friendly. There used to be a site that listed easy-A classes, but it’s gone and lacked key features like professor-level rankings, full comment visibility, and AI-assisted summaries. SBU-Recs fills that gap by combining complete grade-distribution data with cleaned student comments and an AI-backed assistant so students can make smarter scheduling decisions.
What it does
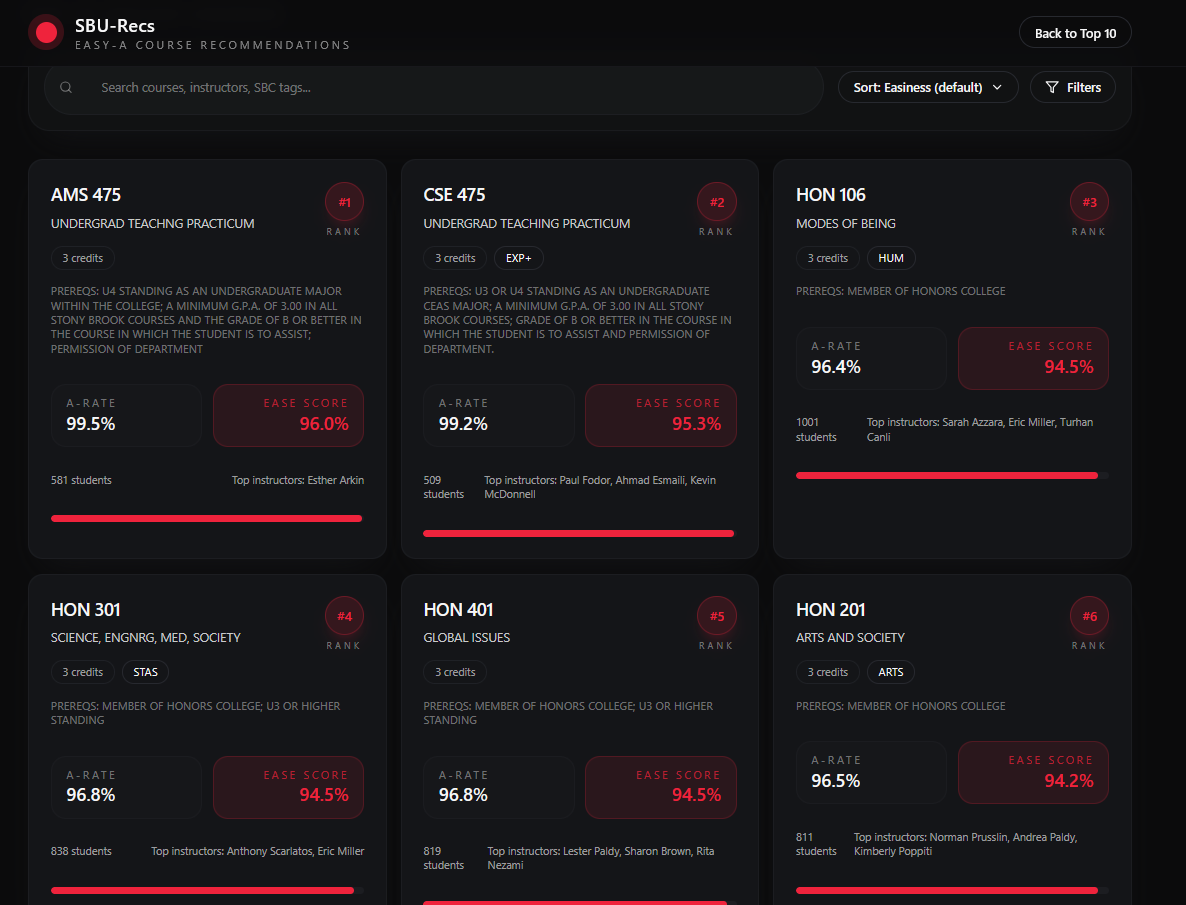
- Ranks courses and instructors by a robust "ease" score derived from real grade-distribution data (not just raw A-counts).
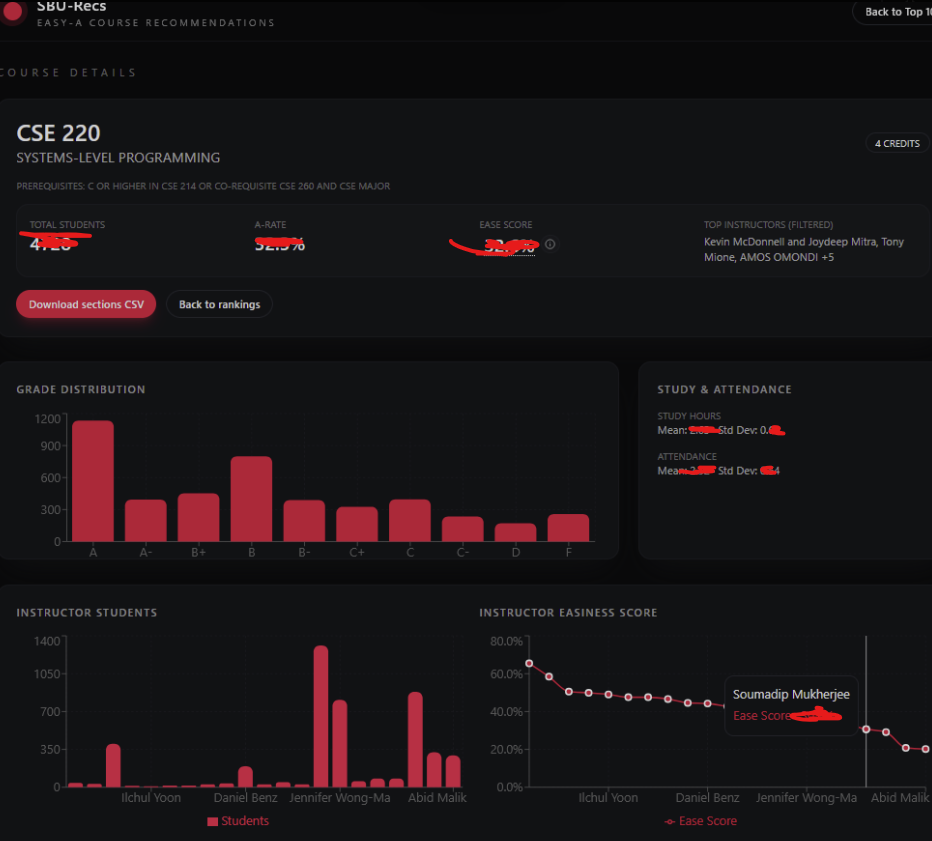
- Shows full grade-distribution details per section and per instructor so you can judge not only how many As are given but how many students were in the class.
- Displays every cleaned student comment ("valuable" vs "improvement") for each course/section, with search and filtering.
- Provides professor/instructor leaderboards (rankings) for departments and courses.
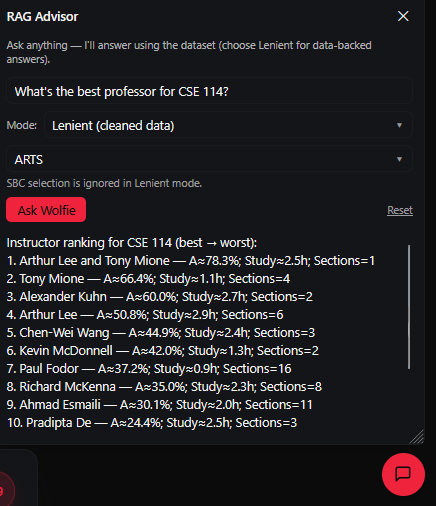
- Includes a floating RAG chat assistant that answers free-text questions about courses, instructors, and trends:
- SBC/vector mode: semantic retrieval + LLM synthesis (when an API key is available).
- Lenient/offline mode: a fast, heuristic retriever that uses the cleaned CSVs so answers work without an API key.
- Client-side CSV ingestion and a server/CLI toolchain to clean, split, and prepare large datasets for efficient retrieval.
- Prefers pre-cleaned datasets stored in
cleaned/if present, making nightly or batch cleaning straightforward.
How we built it
- Frontend: React + TypeScript (Vite) for a fast SPA experience, Tailwind-like utilities for styling, and Zustand for local app state.
- CSV parsing & client logic: PapaParse + custom normalization in
csv.ts. - Data cleaning & pipeline scripts: Python (pandas) scripts in
scripts/to clean comments, remove footers/signatures, sanitize SBC tags, and split large RAG datasets into <50 MB parts. - RAG & CLI tooling:
rag.pysupports both vector-backed retrieval (OpenAI embeddings + Chroma) and a lenient offline mode. - Developer helpers: split/recombine scripts and a manifest system (
index.json) to let the frontend prefer cleaned assets. - Assisted development: used Cursor and GitHub Copilot to accelerate prototyping and refactoring.
Challenges we ran into
- Data acquisition: getting the full Classie Evals exports and aligning headers/encodings was nontrivial.
- Data cleaning: comments contain repeated footers, signatures, and noisy tokens (SBC tags with digits or long tokens). Building robust cleaning heuristics required iterating on real data.
- Serving large datasets: single CSVs can exceed hosting limits; we wrote strict splitting/recombination tools to keep parts under size limits for vector ingestion and hosting.
- Ranking math: raw A-counts aren’t meaningful — a single-student section shouldn’t outrank a 200-student section. We used Bayesian smoothing toward the global A-rate and weighted volume to avoid small-sample bias.
- AI & infra: making RAG reliable was tricky — vector stores, embeddings, and prompt design needed tuning. The LLM sometimes ignored evidence; the offline retriever gives stability.
Accomplishments that we're proud of
- A full-stack pipeline that goes from raw Classie CSVs to cleaned, split, and consumable datasets.
- A responsive UI showing grade distributions, instructor rankings, and all original comments.
- A flexible RAG assistant with a graceful offline fallback for users without API keys.
- Robust heuristics for cleaning comments and normalizing SBC tags.
- Tools to split large RAG datasets into <50 MB parts for hosting and ingestion.
What we learned
- Data quality takes the most time — cleaning messy comments required far more effort than expected.
- Small-sample bias is real — naive metrics are misleading without smoothing.
- Offline fallback support dramatically improves reliability.
- Iterating in small steps (clean → split → ingest → UI) reduces risk and speeds development.
What's next for SBU-Recs
- Deeper AI integration: better prompt engineering, reranking, and domain-specific tuning.
- Schedule generator: propose GPA-optimized semester plans with prerequisites and offering patterns.
- More data enrichment: instructor office hours, workload estimates, cross-listing cleanup.
- UX polish: better mobile UI for the assistant, more visualizations, per-department dashboards.
- Deployment & privacy: admin tools for dataset refresh and improved privacy controls for comments.
Built With
- chroma
- papaparse
- python
- react
- tailwind
- typescript
- vite



Log in or sign up for Devpost to join the conversation.