-
-
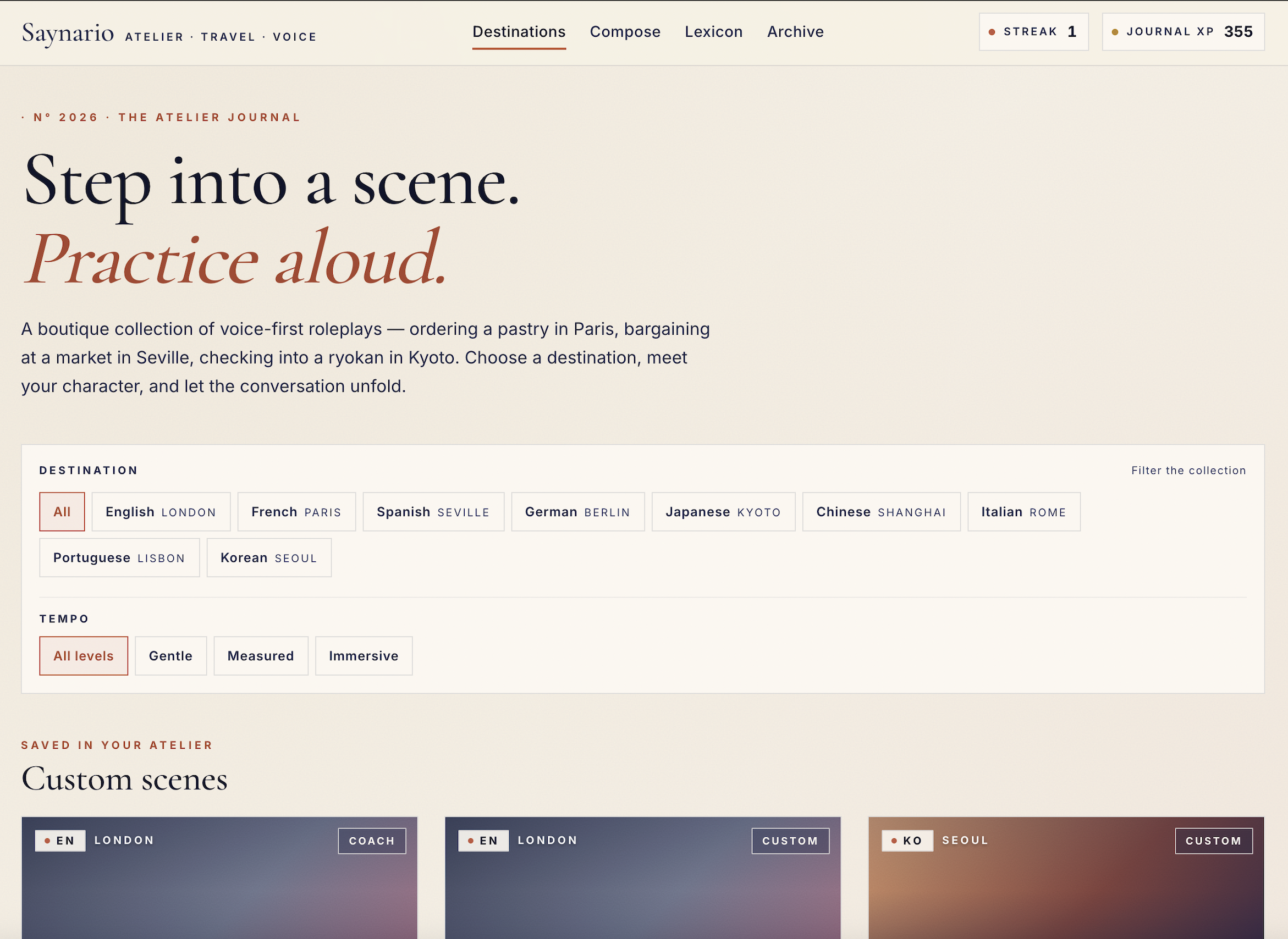
Frontend UI
-
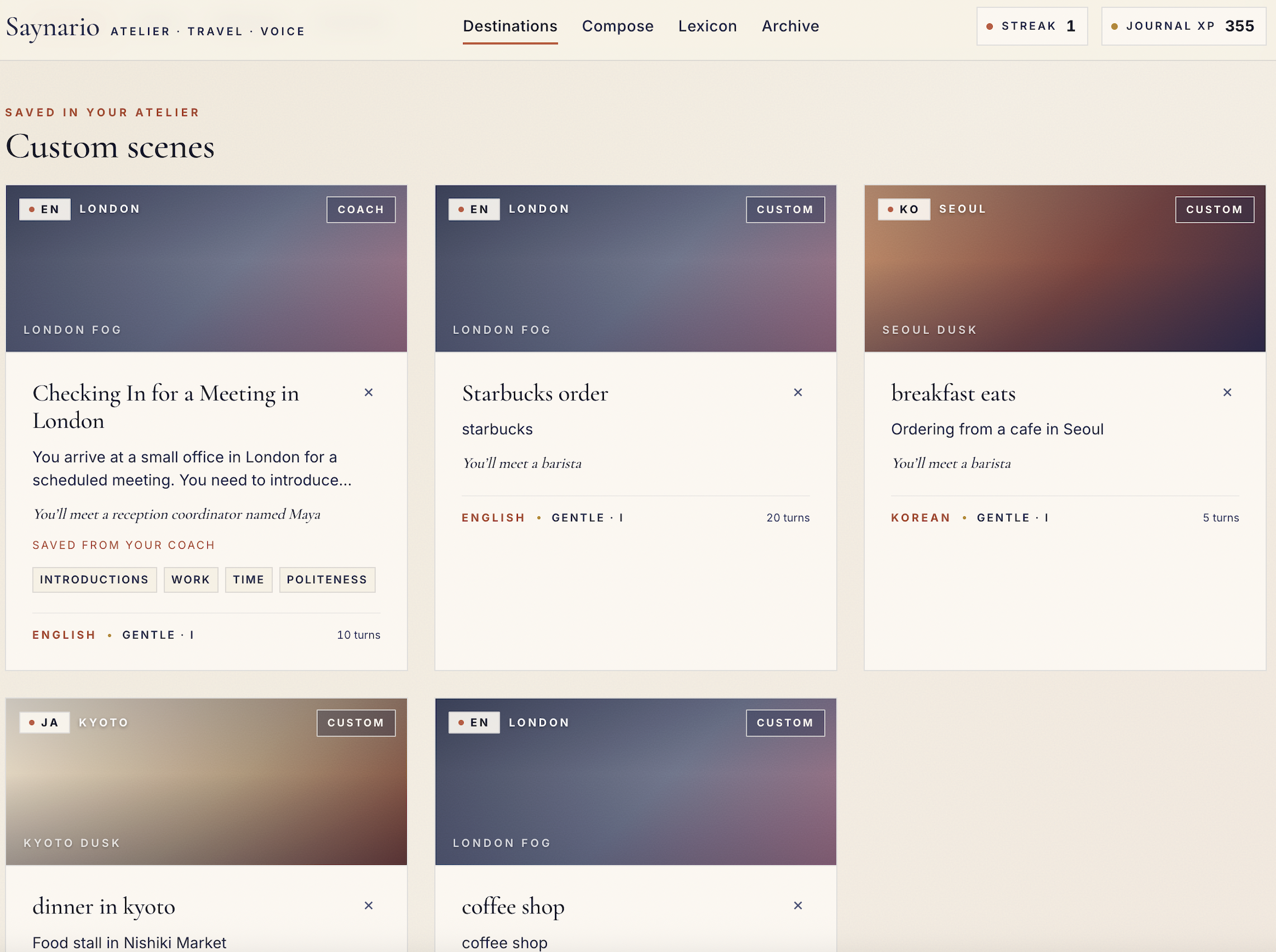
Custom scenes
-
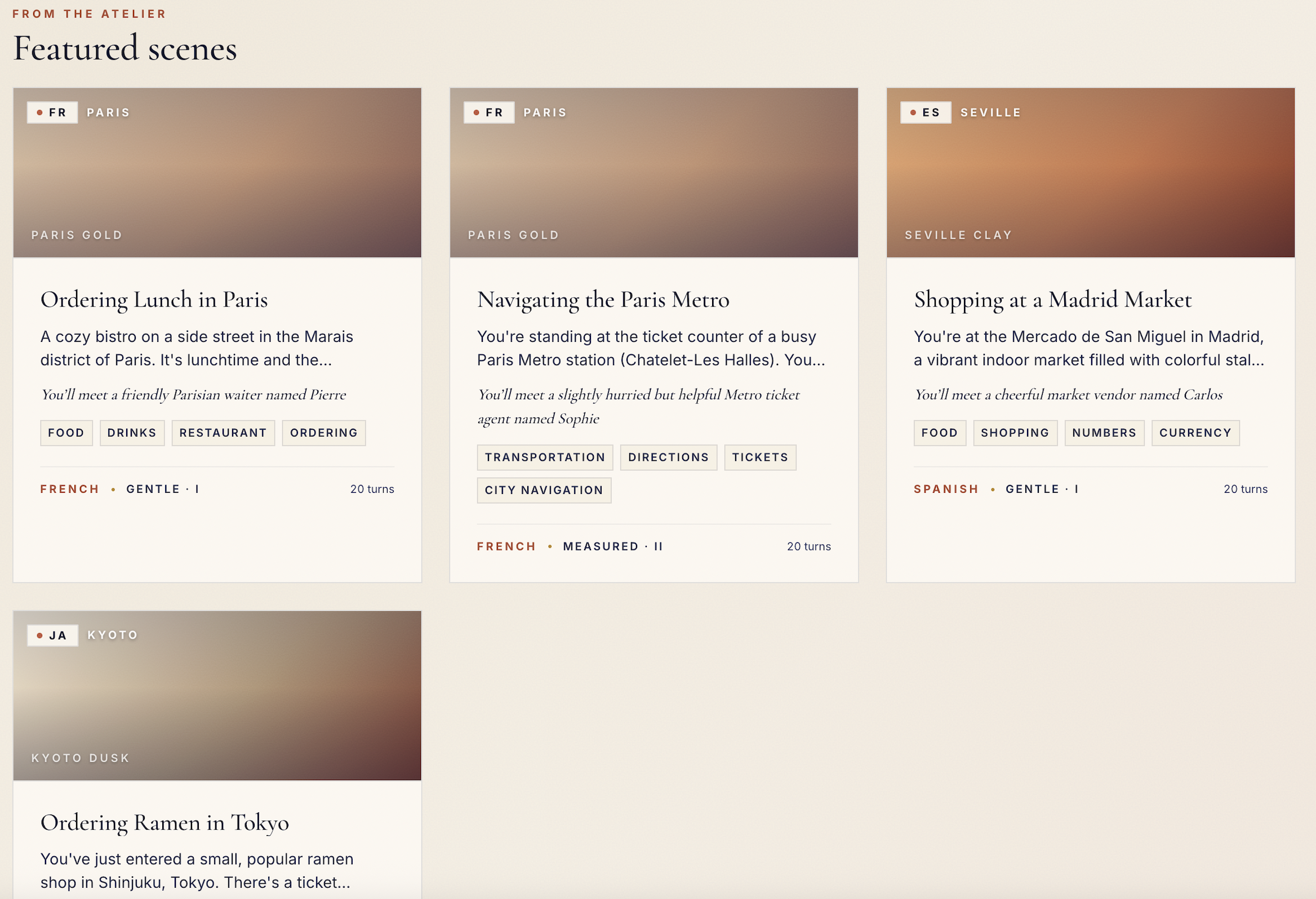
Default scenes
-
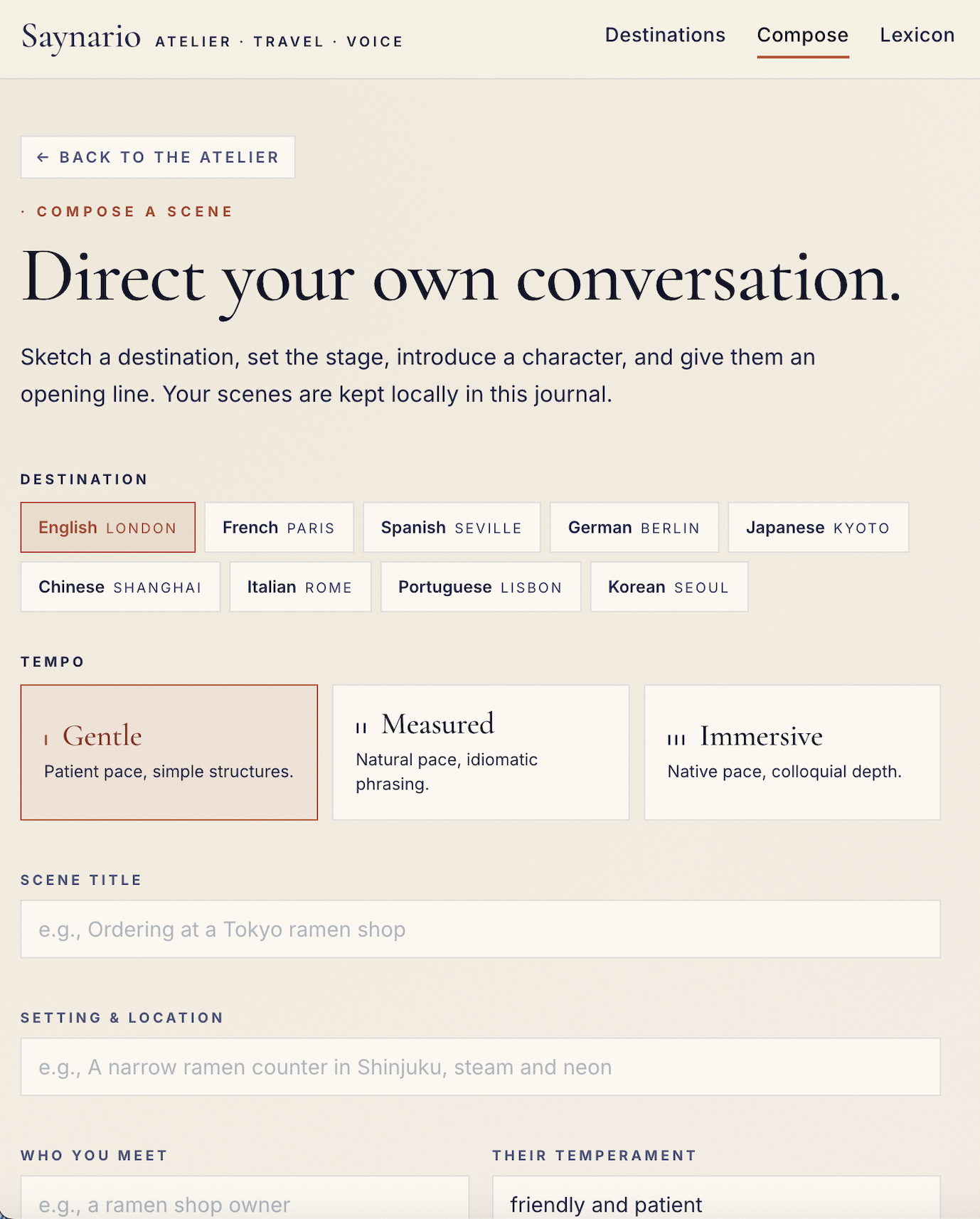
Scene customization
-
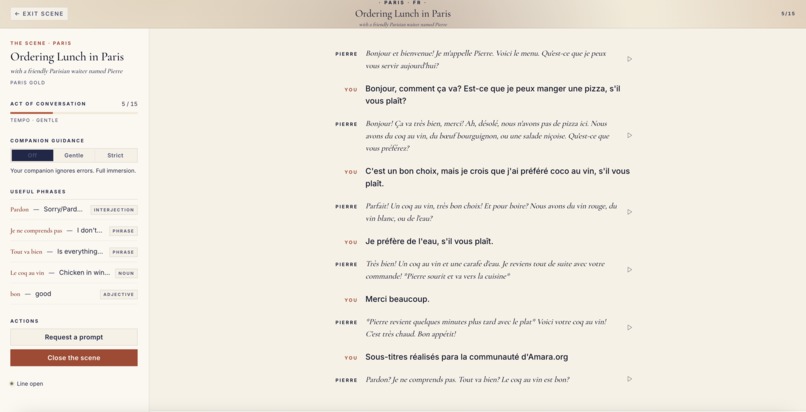
Sample conversation
-
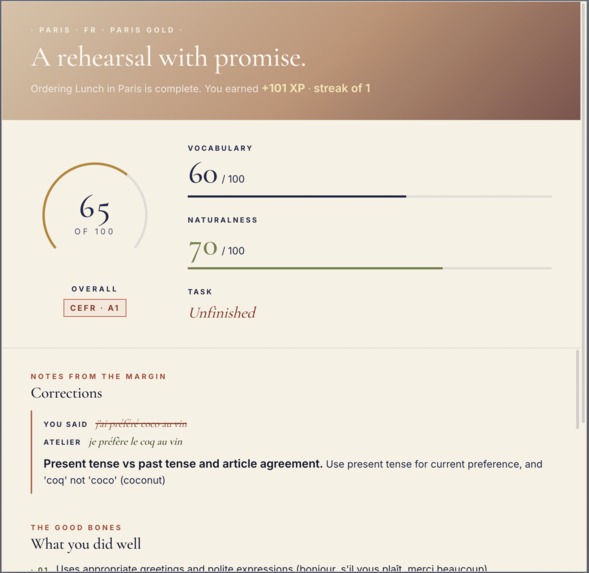
Gemini-powered report
-
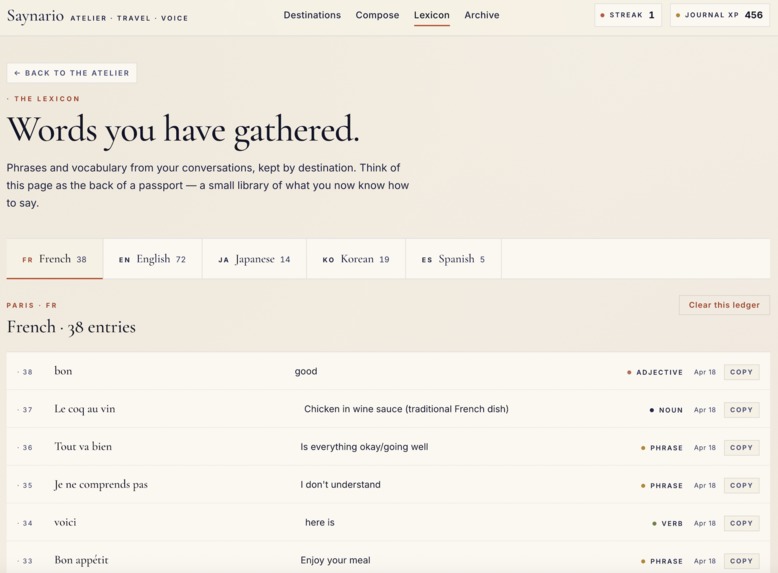
Vocab bank
-
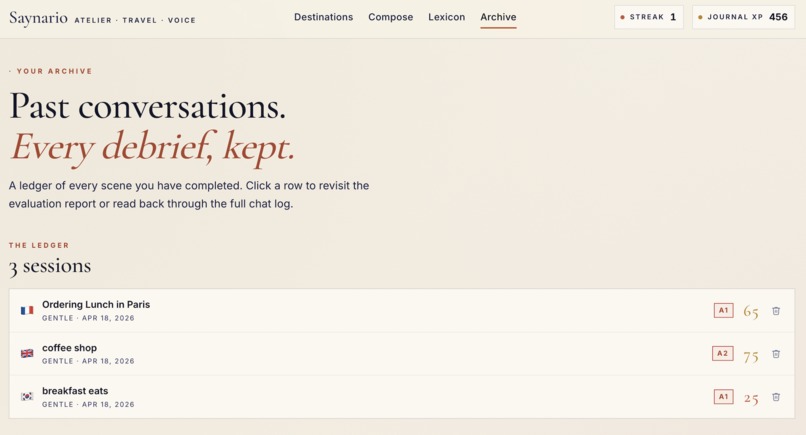
Past reports
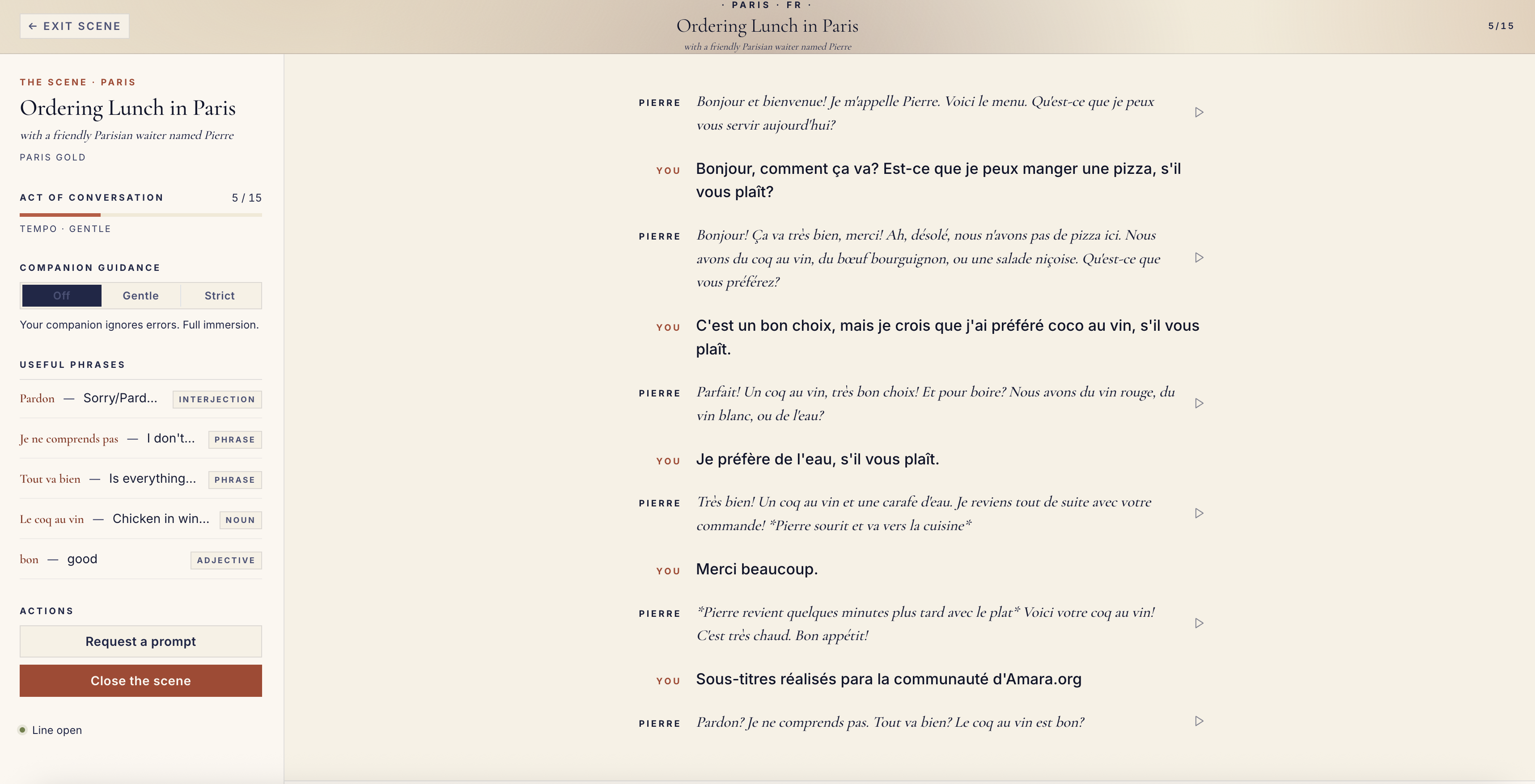

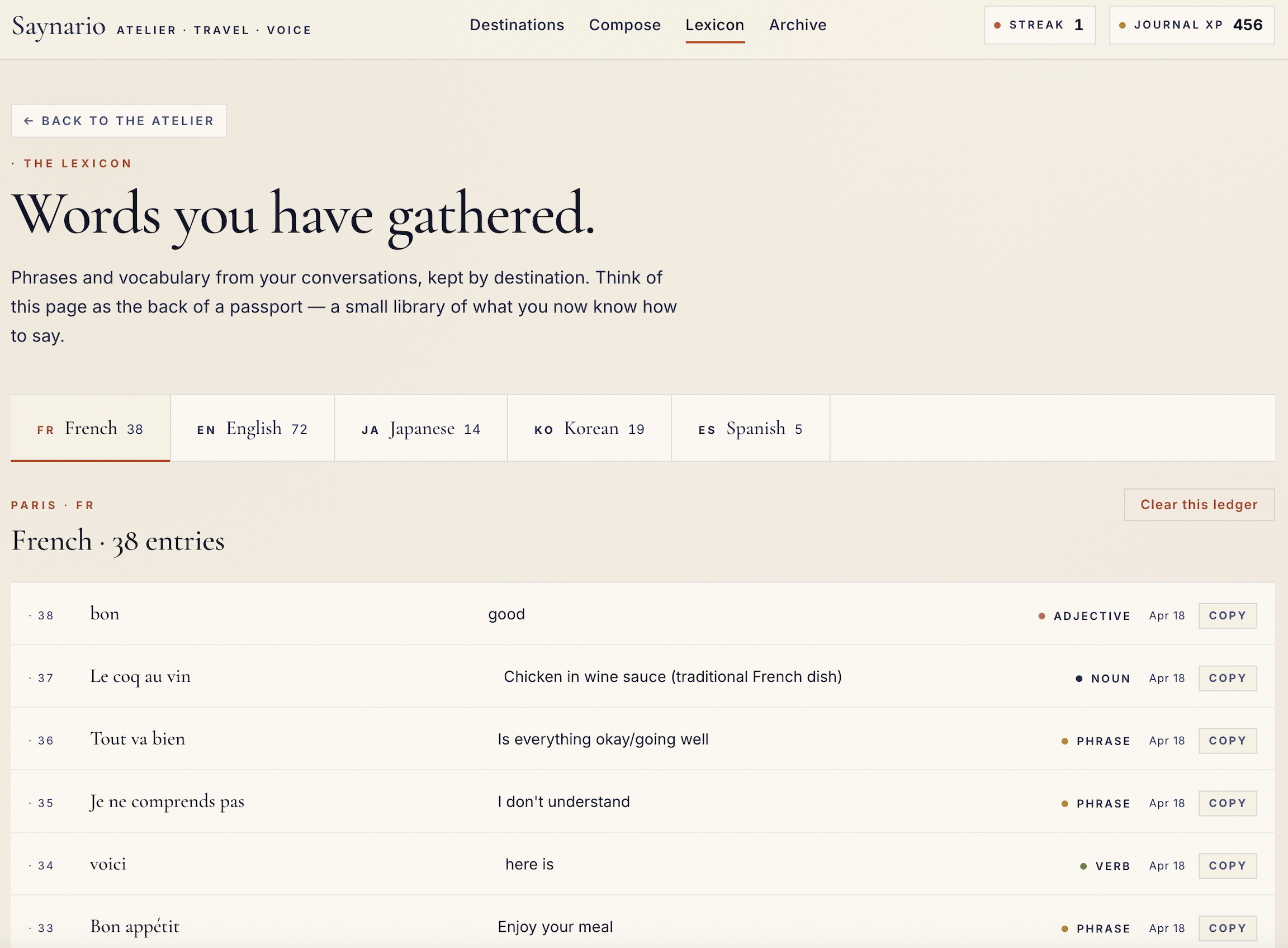
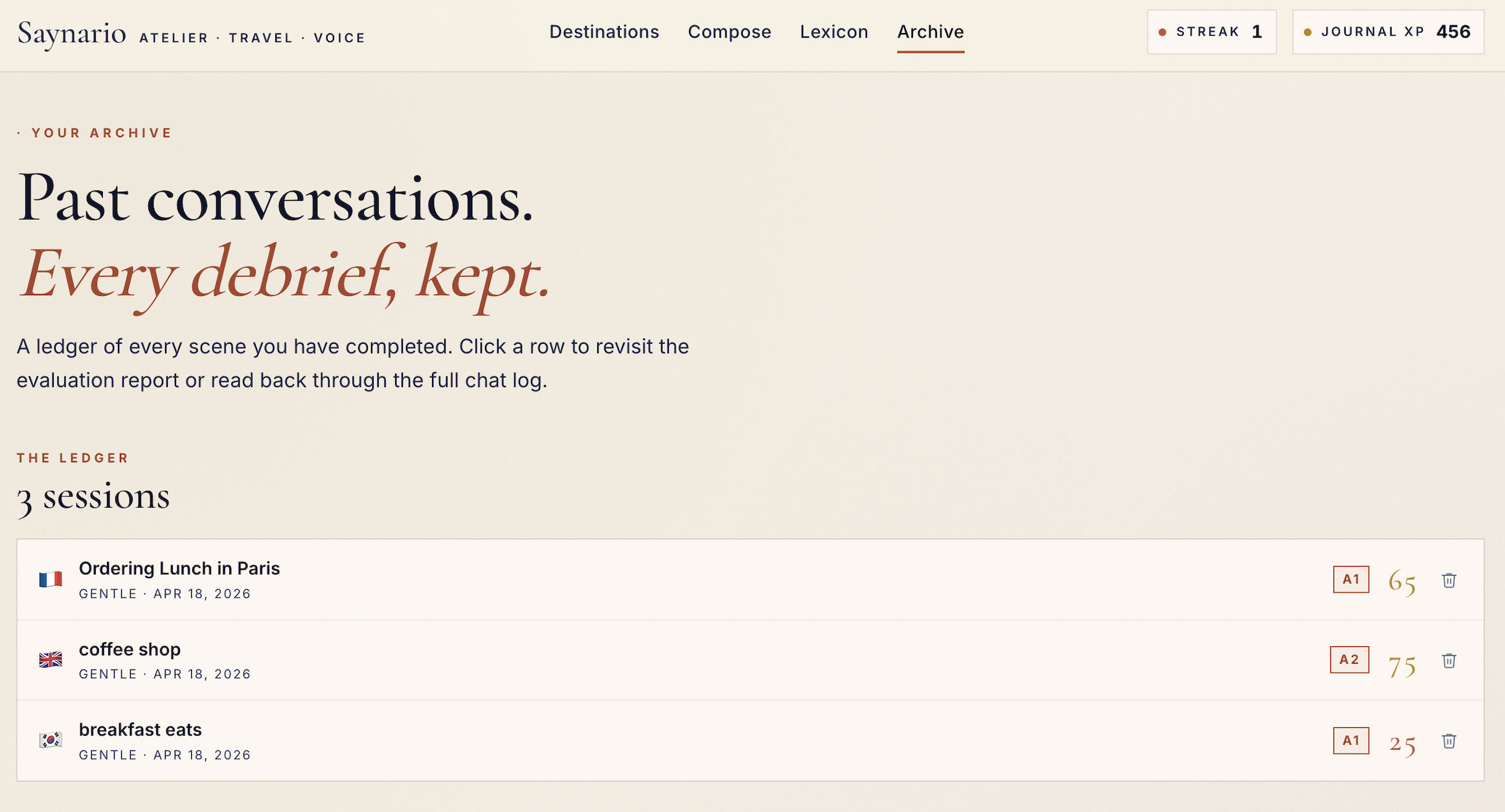
Inspiration
We were inspired by the gap between traditional language-learning apps and real conversation. Flashcards, quizzes, and grammar drills help with memorization, but they do not fully prepare someone for the moment they actually need to speak in another language. We wanted to build something that felt closer to a real interaction: ordering food, asking for directions, or navigating a social situation without switching back to English every few seconds.
That led us to Saynario, a voice-first AI roleplay experience that gives learners a safe place to practice realistic scenarios and get meaningful feedback afterward.
What it does
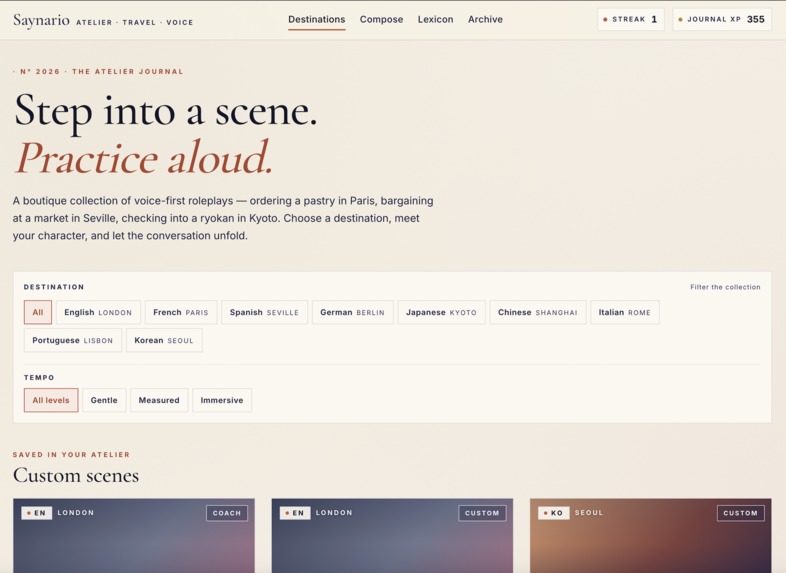
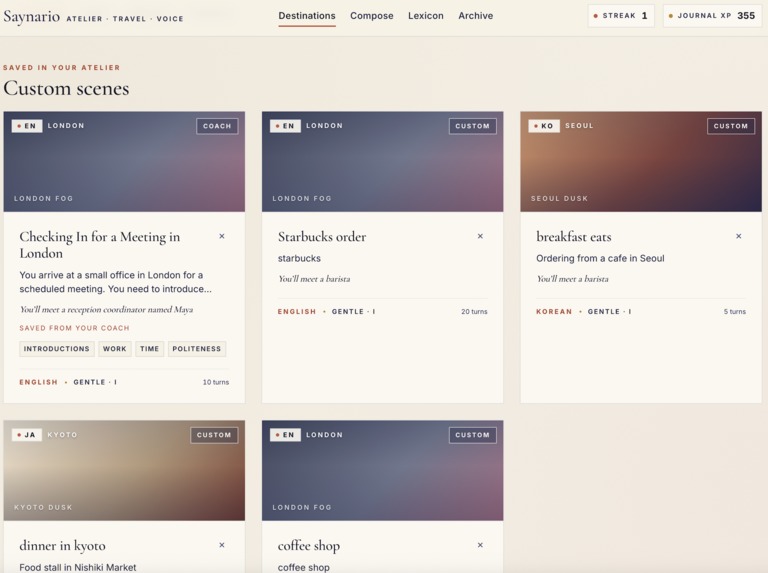
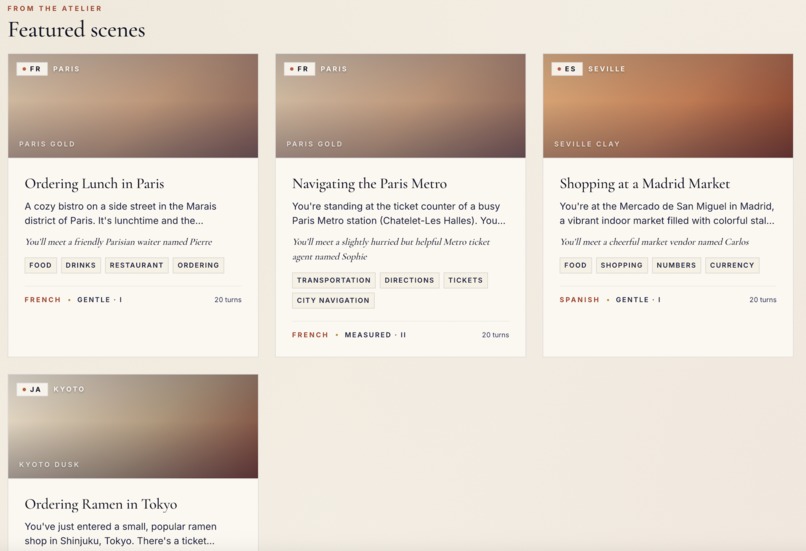
Saynario lets users practice spoken language through immersive roleplay scenarios. A learner picks a situation, such as a restaurant conversation or travel interaction, and then speaks with an AI character in the target language.
The app supports:
- Real-time voice-based conversation
- Scenario-based practice across multiple languages
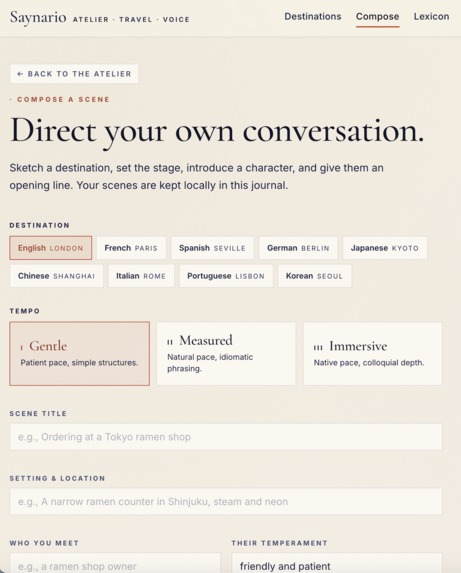
- Different difficulty levels
- Adaptive NPC speech modes that respond to learner performance
- In-conversation correction modes: off, gentle, or strict
- Vocabulary hints during the session
- End-of-session evaluation with fluency scoring, CEFR estimate, grammar corrections, strengths, and improvement areas
The goal is to make language practice feel less like a worksheet and more like a real-world conversation.
How we built it
We built the frontend with React + Vite and the backend with FastAPI. The browser communicates with the backend over WebSockets so we can stream conversation events in real time.
For the voice and AI pipeline, we combined:
- OpenAI Whisper for speech-to-text
- Anthropic Claude for the conversational roleplay and final evaluation
- ElevenLabs for text-to-speech
- Gemini to act as a persistent coach for the user
We also built custom logic for:
- Scenario loading from YAML files
- Real-time session management
- Streaming AI responses token by token
- Sentence-level TTS to reduce perceived latency
- Adaptive difficulty inspired by giving the learner slightly more advanced input over time
- Post-session evaluation that analyzes the learner’s turns and returns structured feedback
- On the deployment side, we containerized the app with Docker and deployed it to DigitalOcean App Platform, then connected it to a custom domain.
Challenges we ran into
One of the biggest challenges was latency. In a voice app, every part of the pipeline matters: recording, speech detection, transcription, generation, synthesis, and playback. If any step feels too slow, the conversation stops feeling natural.
Another challenge was balancing immersion with pedagogy. We wanted the AI to stay in character and keep the conversation flowing, but we also wanted the learner to actually improve. That meant designing different correction modes and deciding how much help to give without breaking the realism of the scenario.
We also ran into deployment and infrastructure challenges. Moving from local development to production involved Docker, DigitalOcean App Platform, DNS records, SSL, and custom domain setup. We also learned that real-time in-memory session handling works well for a single-instance deployment, but requires more planning for scaling.
Accomplishments that we're proud of
We are proud that we built a full end-to-end voice AI learning experience instead of just a chatbot demo. Saynario supports realistic spoken interaction, live feedback features, and a structured evaluation report that makes the practice session feel complete.
We are also proud that we:
- Built a real-time multilingual conversation system
- Added adaptive difficulty and correction controls for different learner preferences
- Designed a cleaner user experience around scenario-based practice
- Successfully deployed the app publicly with a custom domain
- Created something that feels practical, not just experimental
What we learned
We learned that building AI products is as much about orchestration and UX as it is about the model itself. The quality of the experience depends on how well all the parts work together, especially in a real-time setting.
We also learned a lot about:
- WebSocket-based real-time app design
- Reducing latency in voice interfaces
- Prompt design for consistent in-character responses
- Structuring evaluation output so it is useful to learners
- Deploying and debugging a full-stack AI app in production
A big takeaway for us was that the hardest part is not getting one model call to work. It is making the whole system feel seamless and trustworthy.
What's next for Saynario
Next, we want to make Saynario more robust and personalized. Some of the biggest areas we want to improve are persistent user progress, better long-term session storage, and a richer library of scenarios. Our long-term vision is to turn Saynario into a more complete language practice companion that helps learners build real speaking confidence through realistic, repeatable conversation.
Built With
- anthropic
- digitalocean
- docker
- elevenlabs
- fastapi
- javascript
- python
- vite
- websockets
- whisper



Log in or sign up for Devpost to join the conversation.