



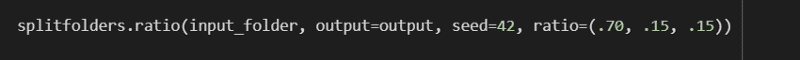

💡 Inspiration 🚀
Plastic pollution can alter habitats and natural processes, reducing ecosystems' ability to adapt to climate change, directly affecting millions of people's livelihoods, food production capabilities and social well-being. The benefits of reducing plastic consumption include: Preventing pollution by lessening the amount of new raw materials used. Saves energy. Reduces greenhouse gas emissions, which contribute towards climate change.

Due to prolonged exposure to the sun, water, and air, the plastic is eventually broken down into microplastic which is eaten by the fish, other sea mammals, and birds. Each year, 12,000 to 24,000 tons of plastic are consumed by fish in the North Pacific, causing intestinal injury and death, as well as passing plastic up the food chain to larger fish, marine mammals, and human seafood diners
👩💻 What it does 🚀
In this Project, we’ll look at how computer vision can be used to identify plastic bottles. This Deep Learning model help you to detect plastic bottles.
🛠 How we built it 🚀
Computer Vision and Deep Learning to the Rescue
Computer vision is a very large field of Artificial Intelligence both in terms of breadth and depth. The branch of Artificial Intelligence that solves problems using deep neural networks is called Deep Learning.
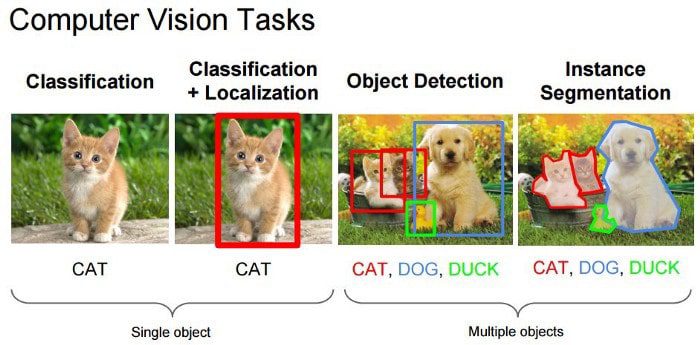
Object detection and image segmentation on the other hand also provide information on where is the person or the item that we are interested in. Object detection does that by returning a class label along with a bounding box for each detection. We can visualize the bounding box by drawing rectangles over the original image.
image classification provides no information about the location of the object. Object detection provides a rough localization of the object using a bounding box. Image Segmentation provides the localization information at pixel level which is an even finer level of granularity.
Data Collection for Plastic Waste Detection
Supervised Machine learning-based computer vision algorithms are usually trained with the same kind of information that it expects as output. For example, in object detection, the input is an image and the output is a set of class labels and bounding boxes. To train an object detector, we need a dataset of images, and for every image in the dataset, we need bounding boxes around objects and their corresponding class labels.
Data Collection by Google Image Scraping
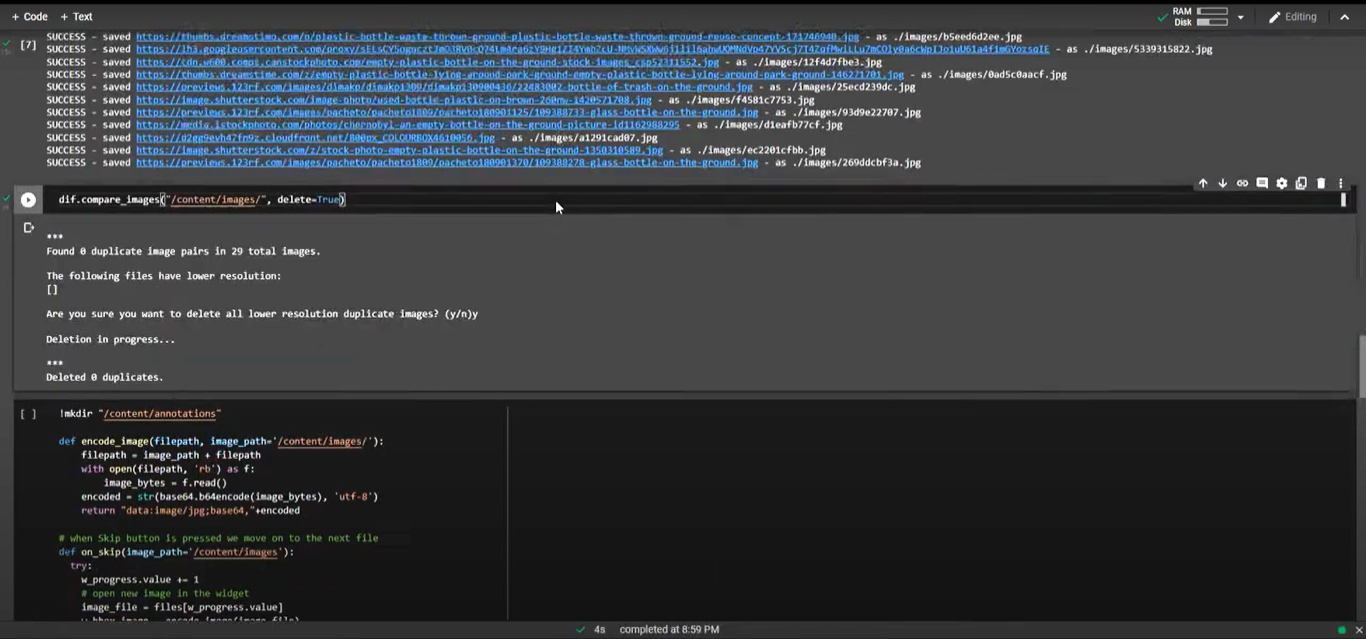
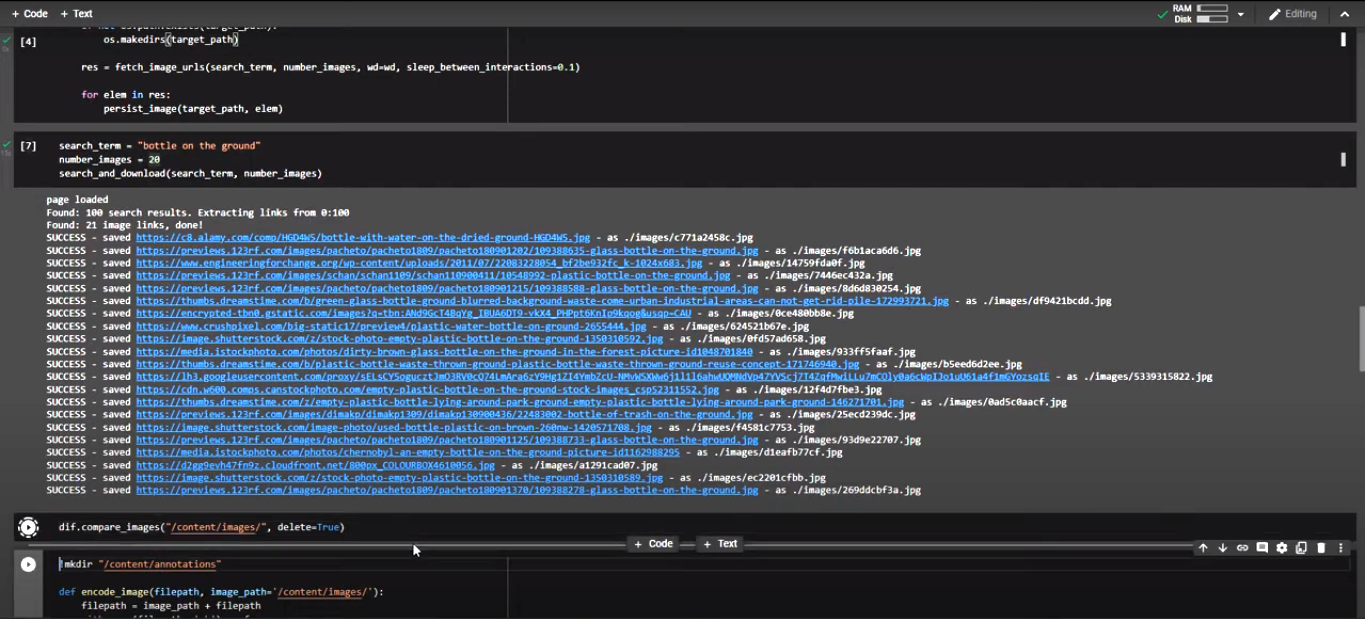
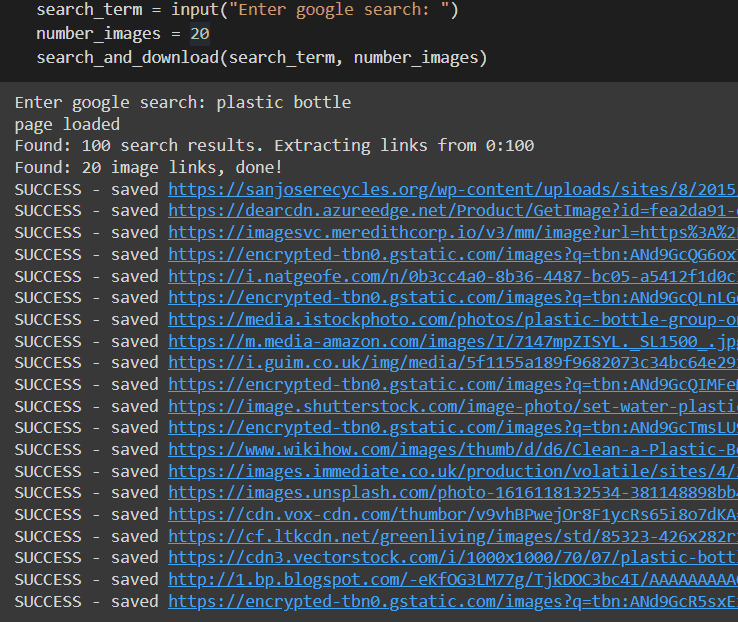
Web scraping in general is a technique used to extract all kinds of data from websites. In this project, we use web scraping as a means to collect images for our dataset. Before you use the scraper, I recommend doing a real Google search to see if the images it returns are relevant to your problem. The following code demonstrates how to extract photos from a Google search for “plastic bottle”.
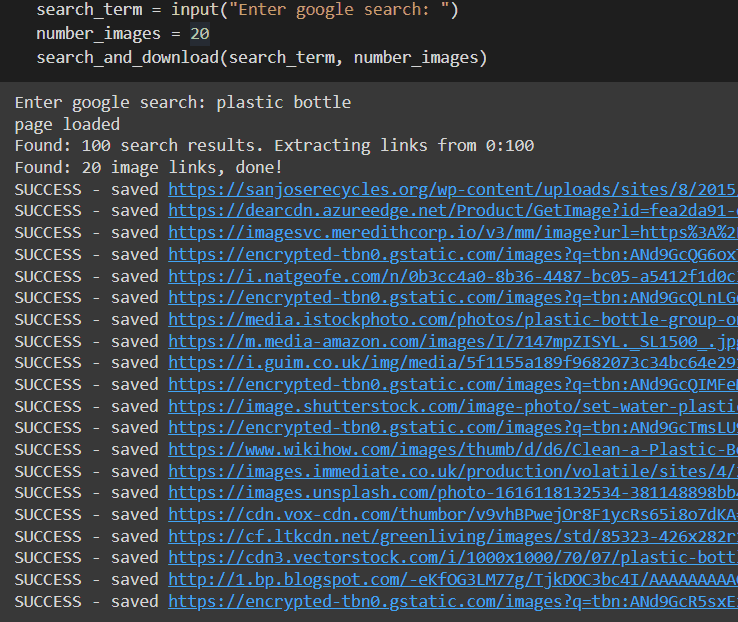
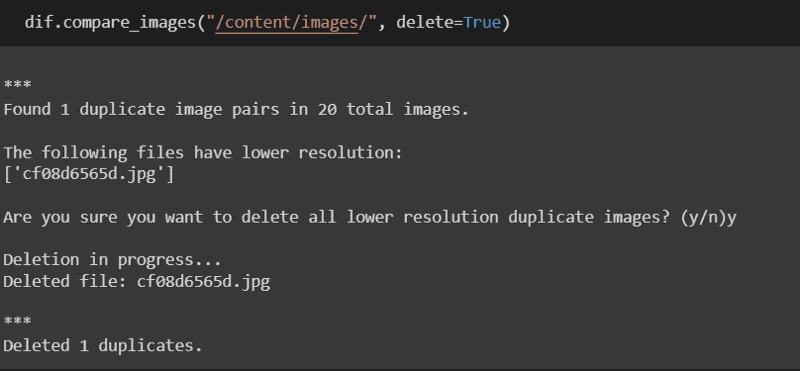
Once the scraper is done with the images, we then run a script to delete any duplicate images that may have appeared in our google search before proceeding with the annotation.
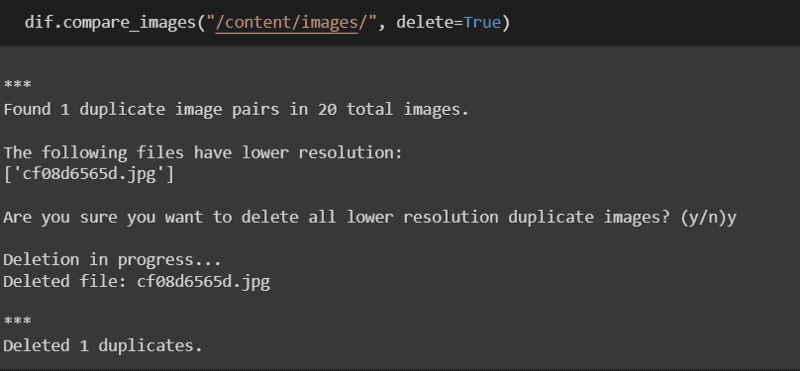
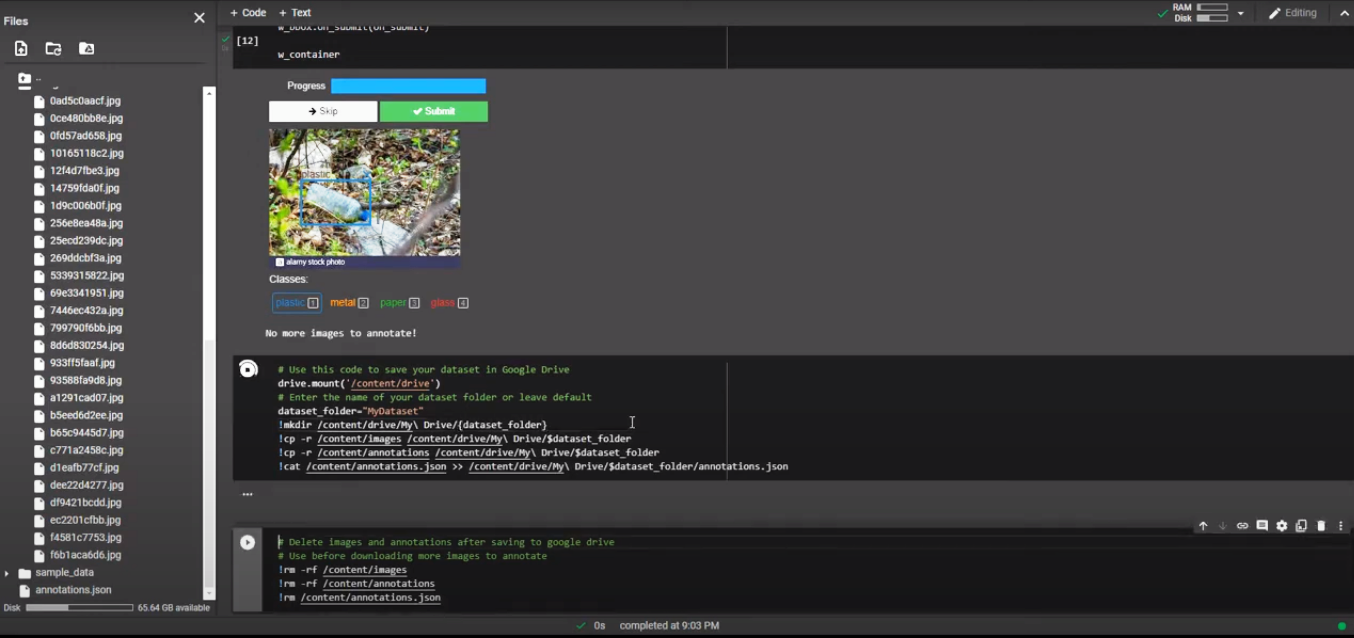
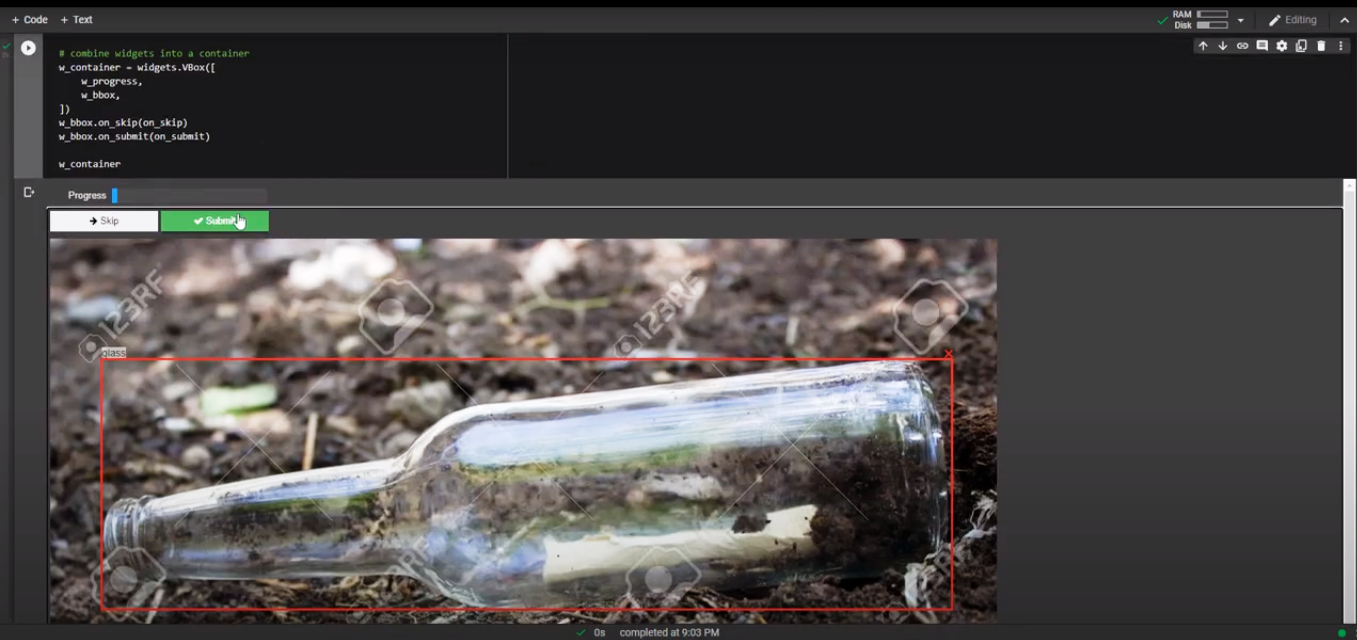
Image Annotating for Object Detection
For this project, I have annotated my images with the main 4 classes of litter, plastic, metal, paper, and glass. The following image presents the annotation tool which is used within Google Colab.

Data Preparation and Model Training
After we’re done building our dataset, we then split our data into train, validation, and test subsets. Usually, the splitting is done with a ratio of 70% training data and 15% validation and test data (70–15–15 for short). We could also split them with 60–20–20 or even 50–25–25, it depends on a variety of factors but the best ratio for a specific problem is generally found through trial and error.

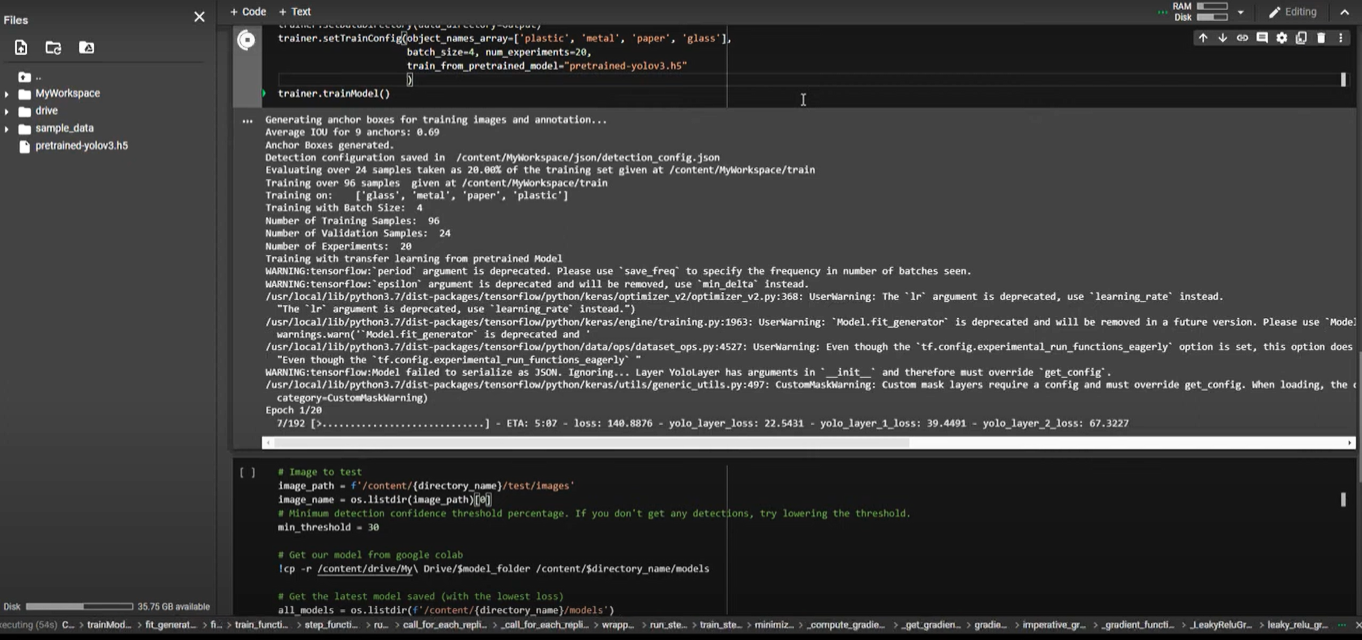
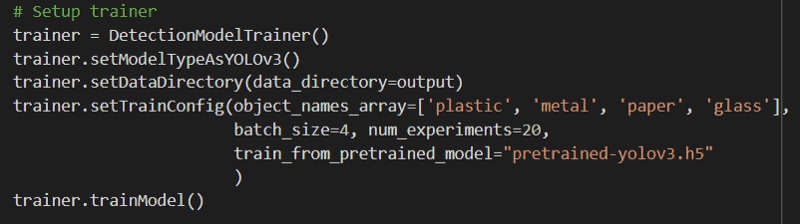
For an easy-to-understand and implement solution, we will use the imageAI library to train and test our model. This library contains the YoloV3 model, which is one of the most popular and well-rounded models for object detection. We will download and use a pre-trained model since it will require fewer data but also fewer iterations to train.
Training a pre-trained model is a technique commonly known as transfer learning and is considered a good practice among machine learning practitioners [8]. After preparing the data and downloading our model, the training takes just 5 lines of code.

Deep Learning Model Testing and Evaluation
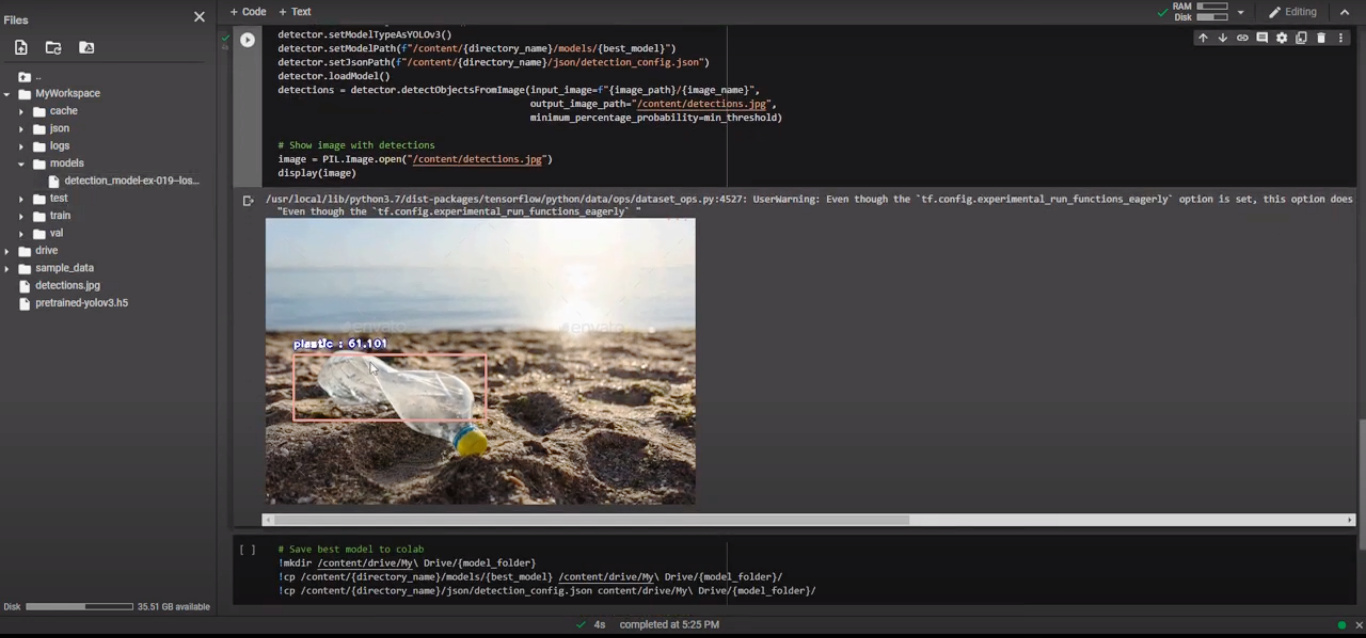
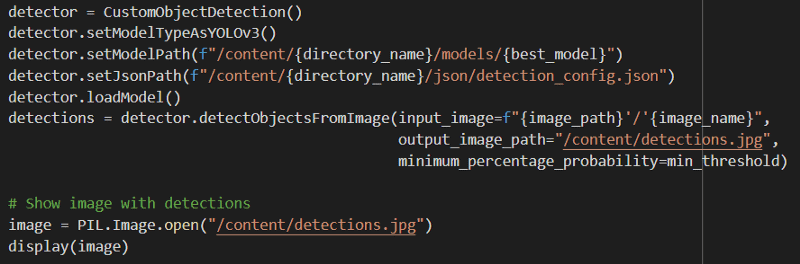
Finally, the most fun part of our process is testing. Once we are done training our model, we can test it using images from our test set or even run it on videos. Testing the model with imageAI takes 6 lines of code with 2 additional lines to display the image and its corresponding bounding boxes.
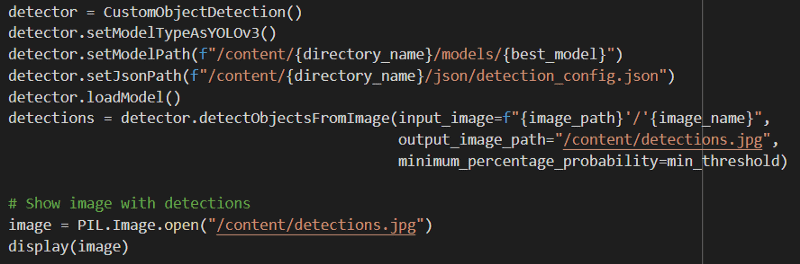
output:

We can observe that the plastic bounding box is on the bottle but it does not contain the whole item. Moreover, there are some false positives of paper that could be filtered by increasing the minimum threshold. The numbers indicate the confidence percentage of the model for each detection which is relatively low. It can be increased by training the model further but most importantly by collecting more data.
💪🏻 Challenges we ran into 🚀
Here, I faced lots of challenges like syntax errors, JavaScript integration issues, and all the other issues, but after a long time of debugging and fixing I run & execute my code sample successfully. Also here I could not properly implement the API to frontend because of time constrictions and I tried to make use of each and every tool in a creative and unique way possible. This project has still lot of potential and improvements to make.
📌 Accomplishments that we're proud of 🚀
Even after the challenges we faced , we finished it on time and this project will help preventing pollution by lessening the amount of new raw materials used. Saves energy. Reduces greenhouse gas emissions, which contribute towards climate change.
📚 What we learned 🚀
A practical introduction to the high-level fundamental concepts of machine learning and computer vision on Jupiter notebook.
⏭ What's next for Say no ❗ to (C2H4)n☣⚠ 🚀
The next version of this project is to add a interactive user interface and deploy our model.
For a faster and more smooth annotation process, I encourage you to look for a more sophisticated annotation tool and annotate your images locally.
When we are done collecting and annotating our data, it is considerably faster to pull them from GitHub instead of copying them from google drive. This can help reduce training times dramatically.
Even though ImageAI is an incredible tool that is extremely easy to use compared to other tools and frameworks, using a lower-level framework such as PyTorch and Tensorflow could provide more training speed and flexibility.
Built With
- deeplearning
- jupyternotebook
- python




Log in or sign up for Devpost to join the conversation.