-
-
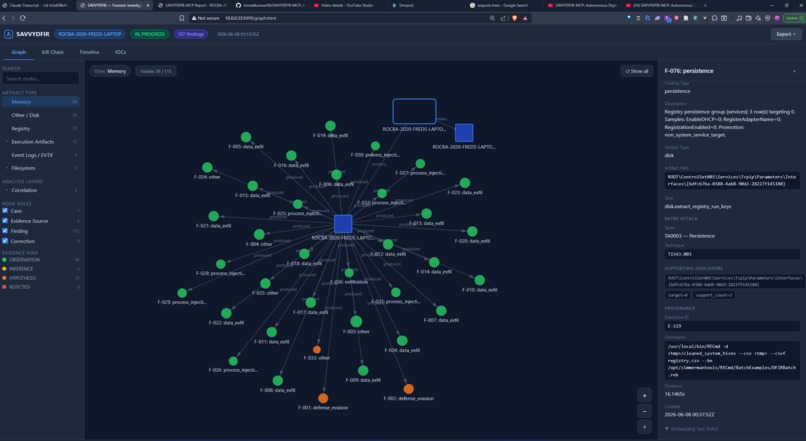
graph view
-
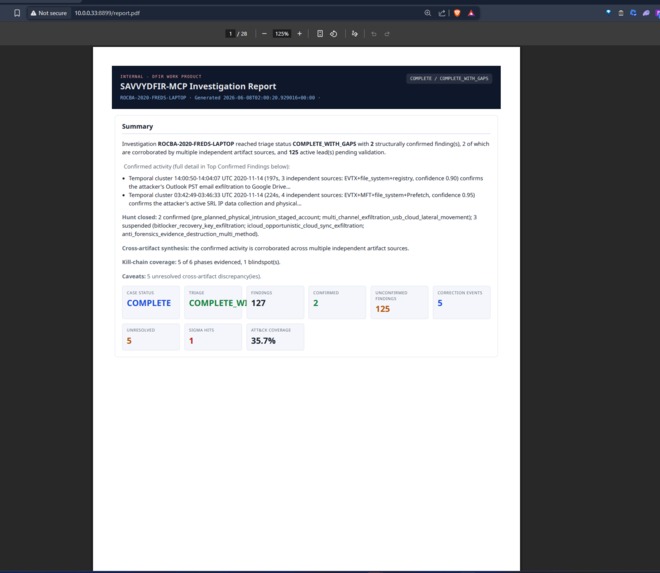
Report snippet
-
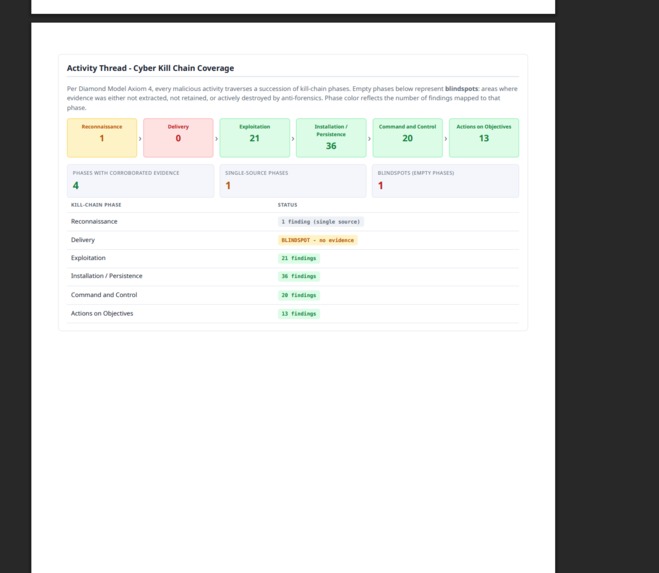
Reportsnippet
-
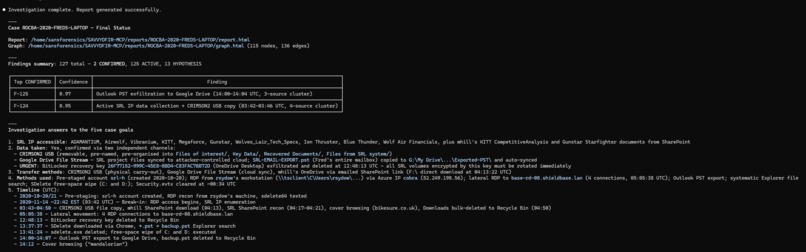
Claude Execution Completed
-
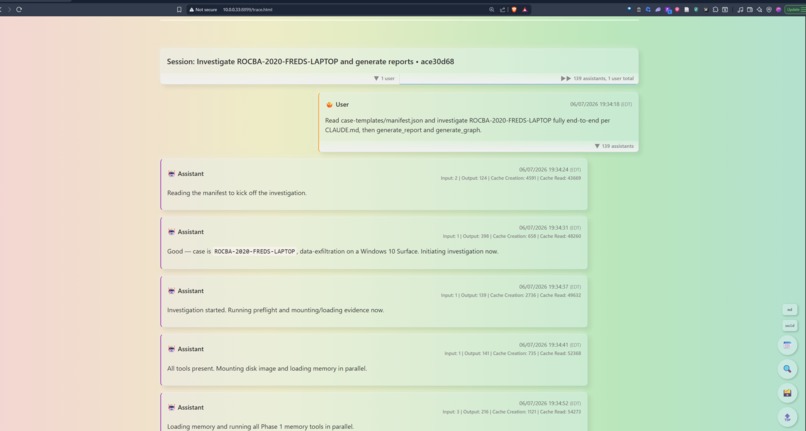
claude trace
-
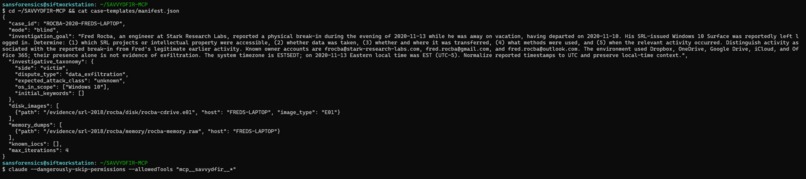
CASE-MANIFEST
-

Self correction and audit trial

Inspiration
DFIR analysts repeatedly run the same cycle on every case: evidence triage, artifact extraction, correlation, hypothesis testing, reporting. I wanted an AI agent to drive that workflow with minimal interaction on real Windows evidence, while preventing unsupported model conclusions from ever becoming confirmed forensic claims.
What it does
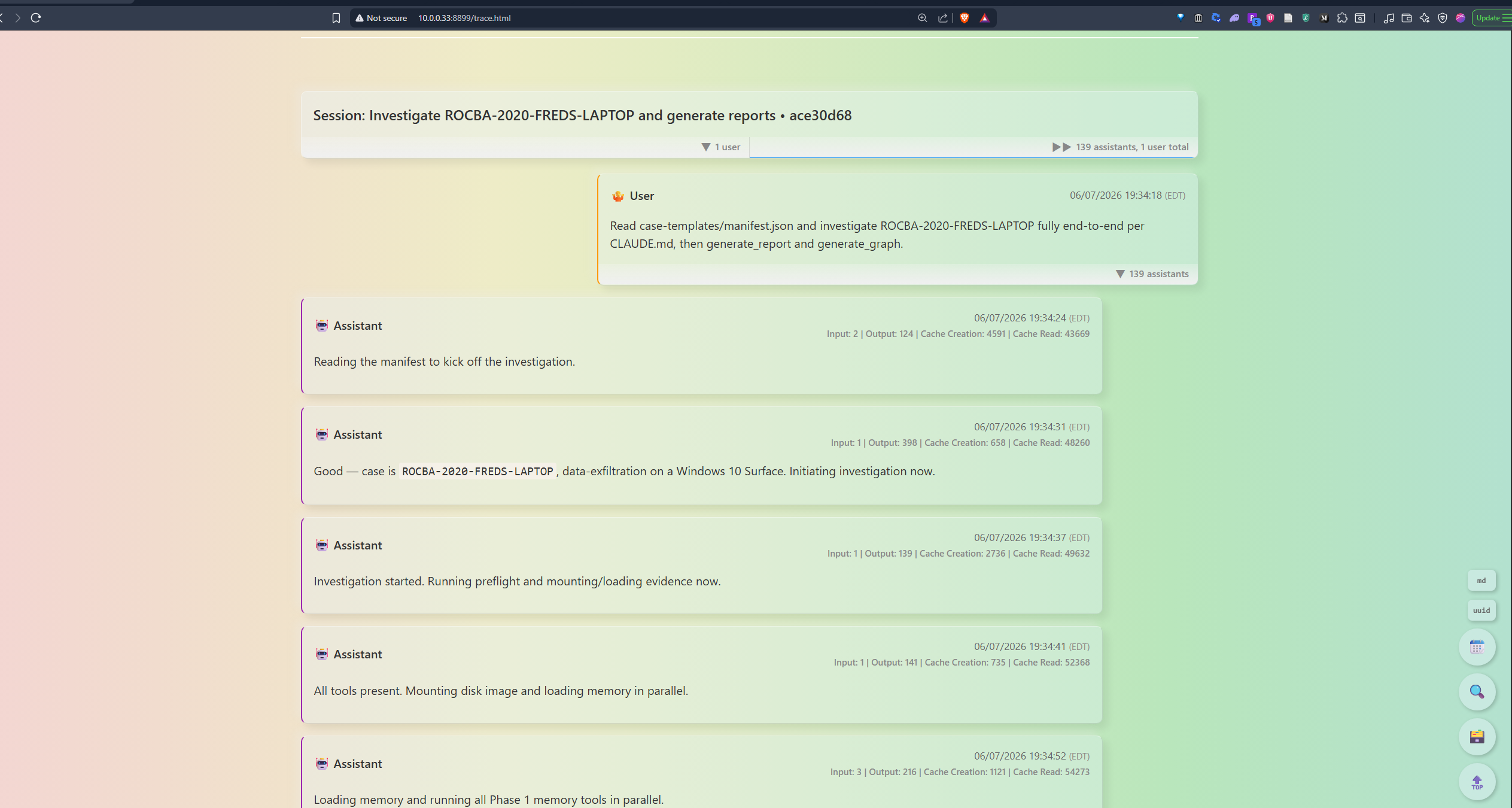
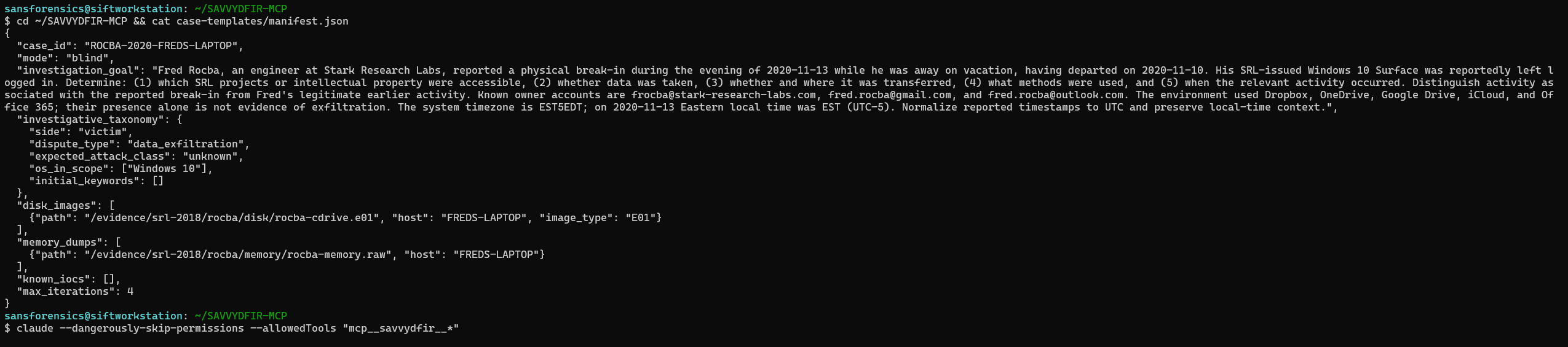
SAVVYDFIR-MCP is a digital-forensics-focused MCP server that turns Claude Code into a guardrailed DFIR investigation agent. Give it a manifest.json pointing to already-collected disk and memory evidence, and it:
- Exposes 65 catalogued MCP tools spanning Windows artifact extraction, memory analysis, targeted data queries, correlation, lifecycle control, and reporting. Artifacts include MFT/USN, EVTX, Prefetch, Amcache, registry, SRUM, processes, network, injection, and an eight-tool file-access bundle (ShellBags, LNK, Jump Lists, browser history, registry file-access, Recycle Bin, PowerShell history, scheduled tasks).
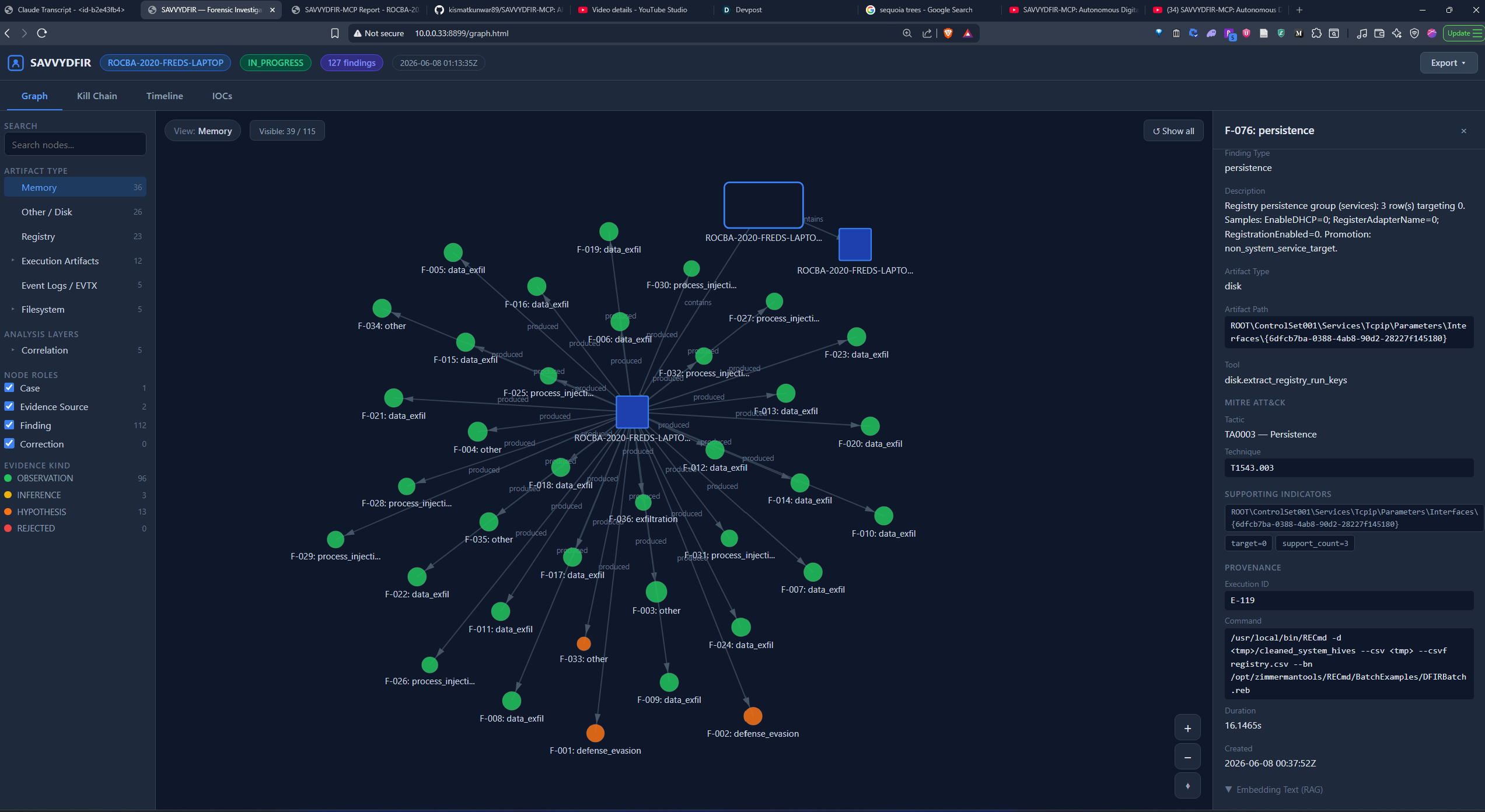
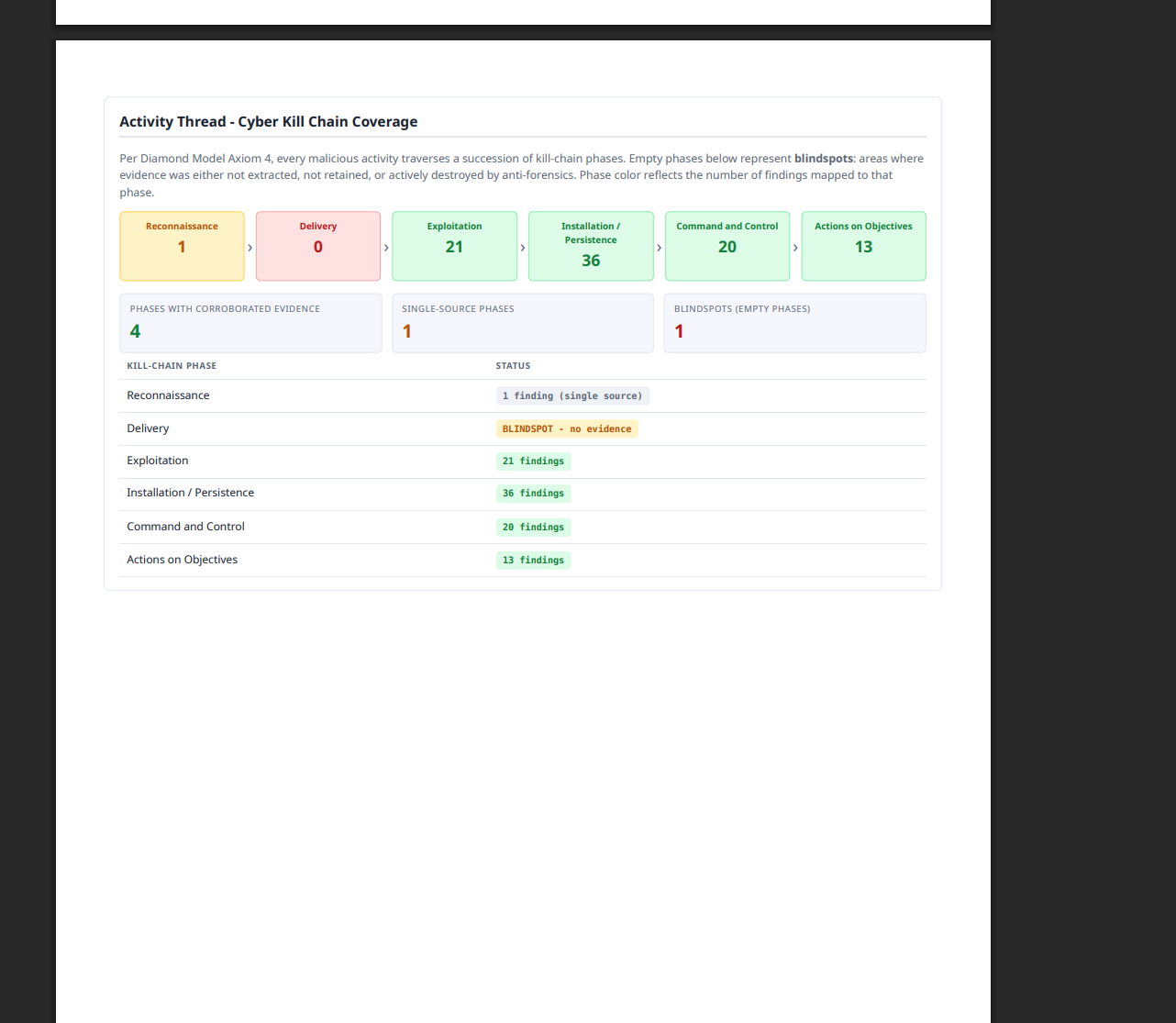
Runs 10 deterministic cross-artifact and anti-forensics checks. When evidence contradicts an earlier claim, the correlation engine writes a CorrectionEvent recording the contradiction and a confidence downgrade into the hash-chained audit.jsonl.
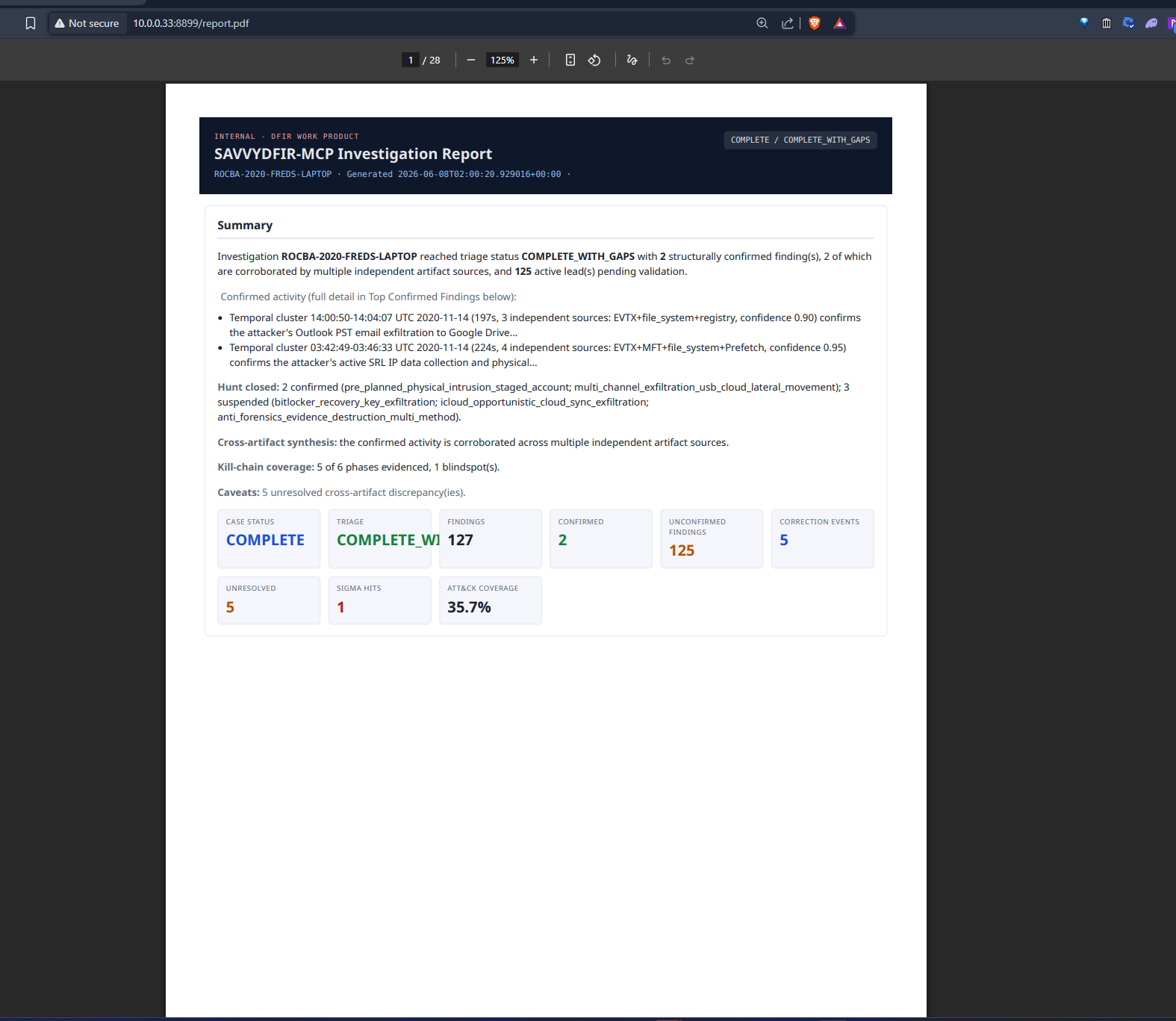
Separates report completeness from claim validation. Coverage gates require mandatory tools to run before reporting; provenance and semantic gates stop a finding from reaching
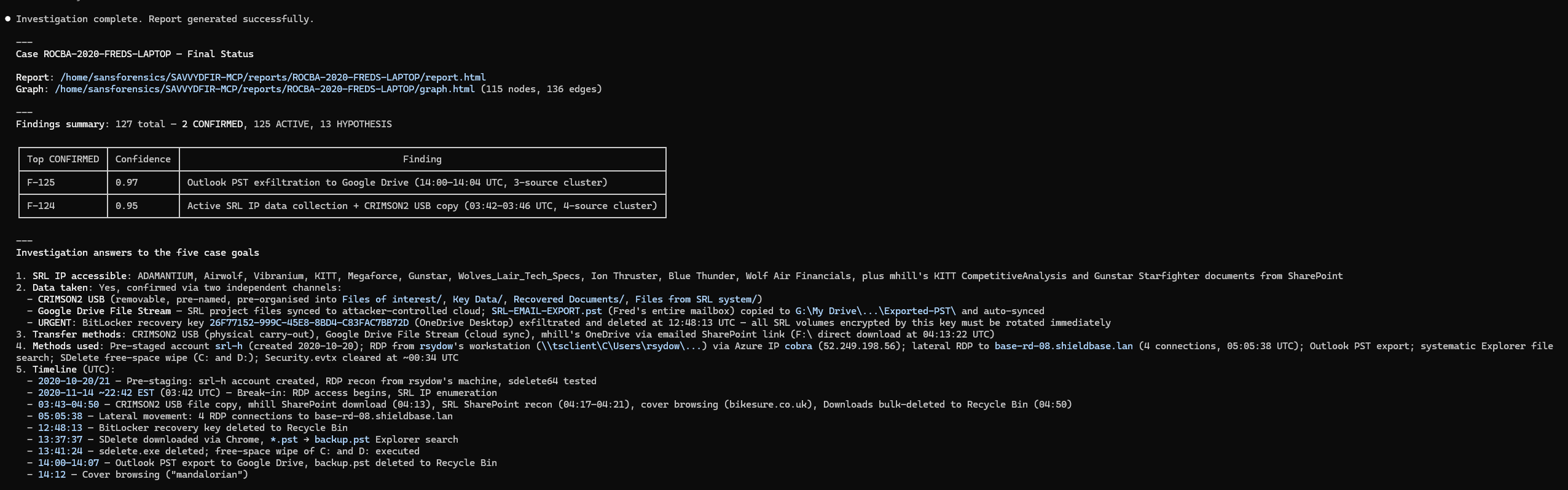
CONFIRMEDwithout a resolvable execution ID, 2+ corroborating sources, and a ruled-out alternative. Everything else stays an ACTIVE lead for human review.Produces an HTML/PDF report, an interactive investigation graph, persisted state, and a tamper-evident audit log (an optional session trace can be rendered too).
Blind evaluation (five independent Windows cases, on the judged v1.1.1 engine): ~84% mean ground-truth recall (60%-92.3% per case; ROCBA reached 90%), with zero scored hallucinations. A v1.2.0 showcase re-run of ROCBA held 90% with expanded artifact coverage; the full suite hasn't been re-scored on v1.2.0+ yet.
How I built it
Built on Claude Code (agent runtime, MCP client, hooks, skills, subagent plumbing), evaluated mainly with Claude Sonnet 4.6. On top I built the DFIR layer: a FastMCP server wrapping SIFT tooling (Volatility 3, Eric Zimmerman tools, The Sleuth Kit, Chainsaw/Sigma, Hayabusa, Plaso, YARA); per-artifact forensic-knowledge YAML; eight injected analyst heuristic knowledge bases; deterministic coverage and provenance gates enforced via Claude Code hooks; a 10-check correlation engine; durable artifact reuse; and report, graph, state, and audit generation. The forensic discipline is explicit: navigation isn't file access, file access isn't execution, and missing data is classified as absence, collection gap, incompatibility, or parser failure, not silently treated as proof.
Challenges I ran into
Forensic extraction was less uniform than the file formats suggest. Real images exposed case-sensitive Linux mounts, inconsistent Windows path casing, UTF-16 Task XML, and registry hives that need transaction-log replay before they can be trusted. I reused established tools where they were strongest Eric Zimmerman's parsers, Volatility 3, and Chainsaw/Sigma - and wrote narrowly scoped native parsers where those tools were the wrong fit: Recycle Bin $I records, PowerShell history, and scheduled tasks.
Context management was a persistent constraint. Artifact tables can run to millions of rows, so extraction tools write durable CSV/JSON handles to disk and the agent queries them selectively with targeted Pandas rather than loading raw output into its context. Task subagents also hit Claude Code's 32K output ceiling, and long runs trigger context compaction on the main agent - which pushed me toward an inline-analysis design with bounded, court-cited heuristic slices injected into each tool response.
Keeping a long-running agent aligned to the seven-phase workflow took more than prompting. Hooks reinforce the phase checkpoints, analysis-debt tracking flags artifacts that were extracted but never concluded on, and deterministic coverage and provenance gates block report completion - or CONFIRMED promotion - when required work or evidence is missing. The model still does the interpretation and skills still guide strategy; code constrains only what it's allowed to call complete or confirmed.
Artifact interpretation demanded the same discipline. ShellBags show navigation, not file access; Amcache and ShimCache alone don't prove execution; and a missing artifact can mean genuine absence, an incomplete collection, or a parser failure - three very different conclusions. So a finding stays an ACTIVE lead for human review unless it clears the CONFIRMED bar: resolvable provenance, at least two independent corroborating sources, and a documented benign alternative the evidence rules out. Most output stays ACTIVE by design.
Performance was the final tradeoff. One ROCBA disk-and-memory run took about 1h 42m (~100 minutes) on a small VM; the largest costs were memory-injection scanning, the Sigma sweep via Chainsaw, and EVTX parsing, followed by iterative artifact analysis. The heavy tools run sequentially for resource safety, and durable reuse avoids re-parsing on re-runs but controlled parallelism and broader caching are clear, unfinished optimization opportunities. A thorough run takes time, the way real forensic work does, and it scales with evidence size and hardware.
What I learned
The model is great for investigation strategy, targeted queries, synthesis, and narrative, but the trust comes from the deterministic layer around it: provenance, coverage policy, confidence semantics, correction events, and an auditable trail. Letting the model decide what's "good enough" is exactly where it goes wrong; keeping that in code is what makes the output defensible. And a human still reviews the leads.
What's next
Today it analyzes already-collected evidence. Next: validated ingestion of remote-endpoint triage packages, acquisition over MCP, and live network-capture integration, so it both acquires and investigates. And most importantly I want it to be crowdsourced community driven in future I know now where its strengths are and where community could enhance it drastically.



Log in or sign up for Devpost to join the conversation.