-
-
Hero
-
Upload Image
-
How it Works
-
Multilingual Mode
-
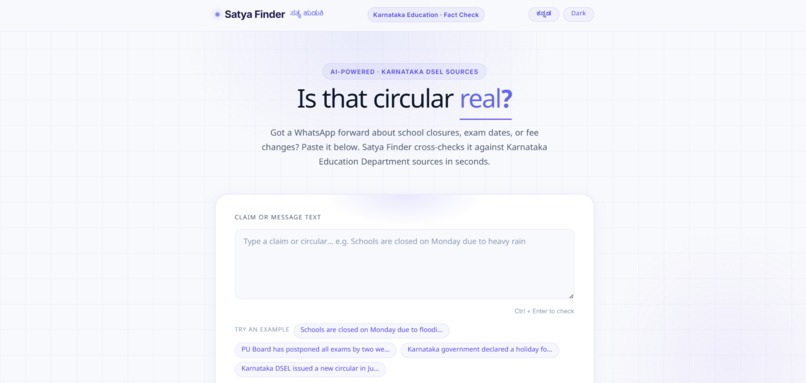
Light Mode
-
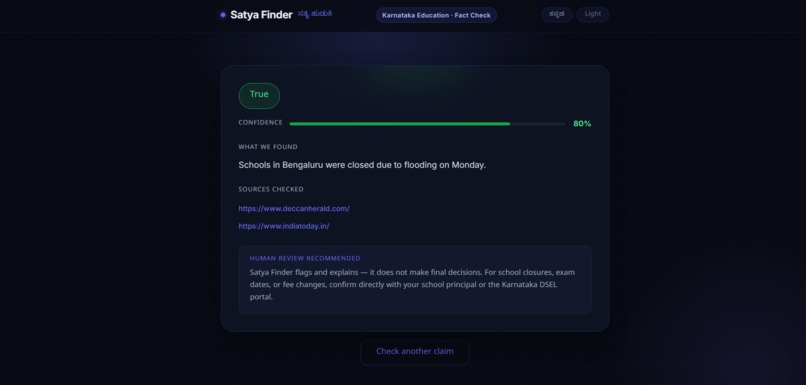
Results Card
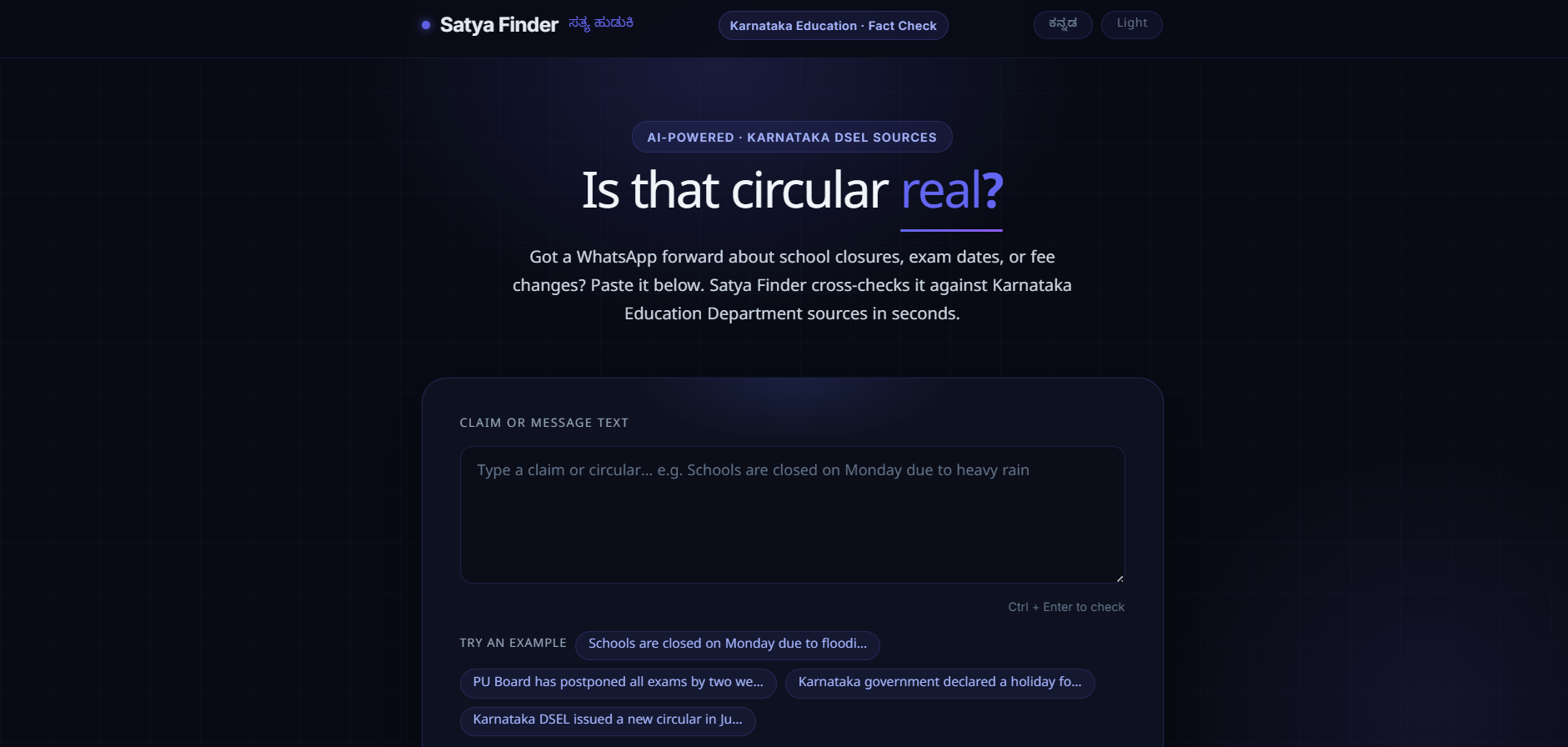
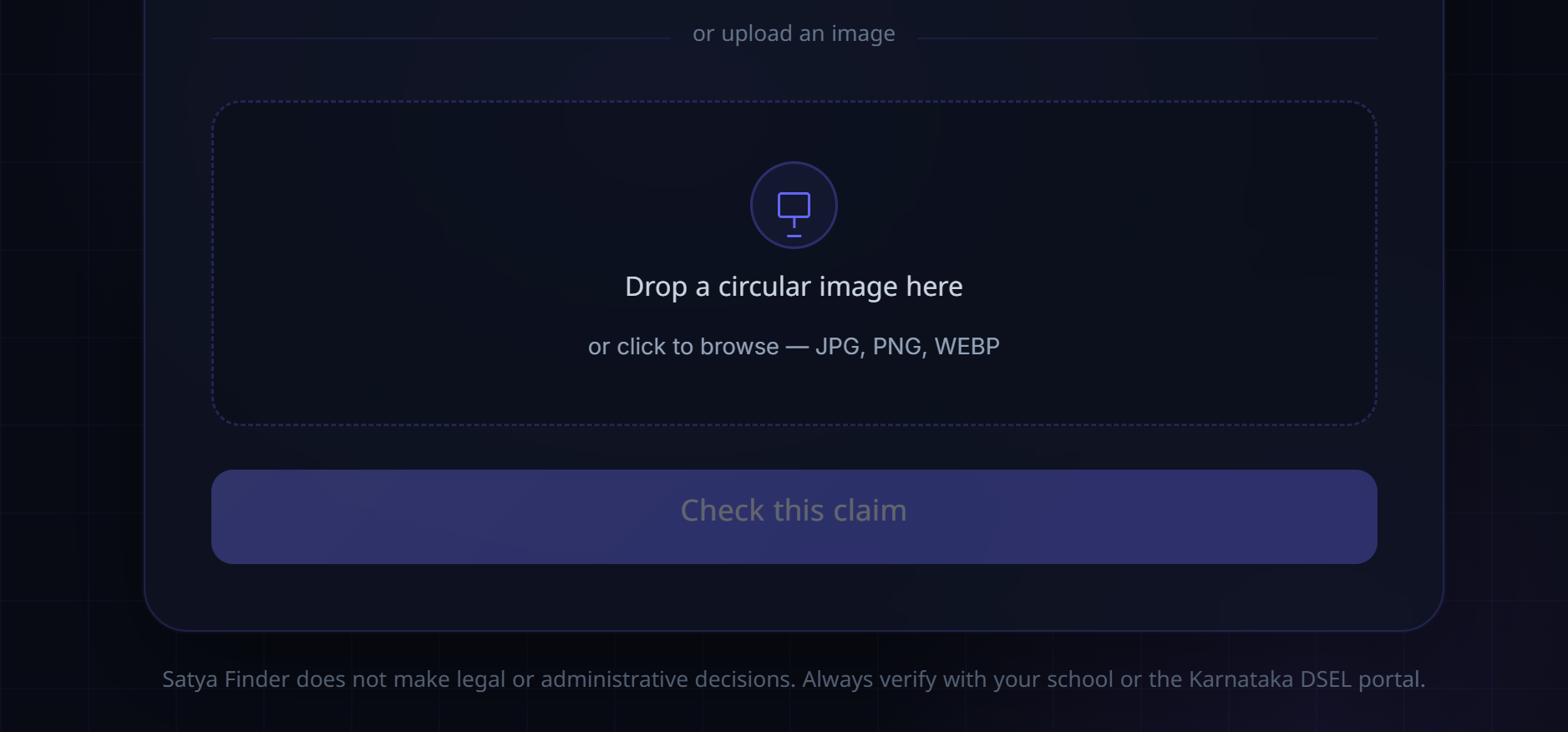

Inspiration
Scroll through Facebook, Instagram, or any parent WhatsApp group for more than a few minutes and you'll run into it: a post claiming schools have been shut down because of heavy flooding, a screenshot saying fees have suddenly been hiked, a forwarded message about some new rule that nobody can trace back to an actual source. It happens constantly. A cousin shares it in the family group. A neighbour reposts it on their story. By the time it reaches you, it has already been forwarded ten times, stripped of any context, and dressed up to look official. Almost nobody stops to check if it's real before reacting, sharing it further, or quietly panicking about it.
We've all been on the receiving end of this ourselves. That small jolt of worry when you see "URGENT: School closed tomorrow" land in a group chat at eleven at night, the moment of second-guessing whether to believe a fee-hike notice that has no letterhead, no signature, nothing but a screenshot and a caption in all caps. And the frustrating part is that the real answer usually does exist somewhere, Karnataka's Department of School Education and Literacy (DSEL) actually does publish official circulars and notifications, but that information lives on a government portal that almost nobody thinks to check, written in a format that almost nobody has the patience to search through, while the rumor itself is sitting right there in your pocket, already convincing you.
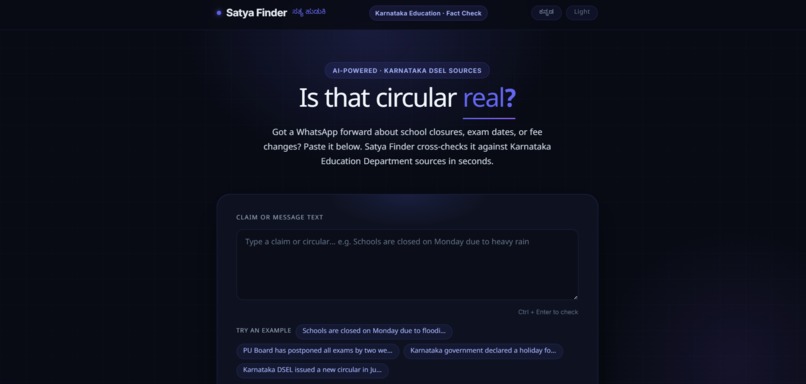
That gap between what people see and what's actually verified is what we kept coming back to. Not because misinformation in general is an abstract problem, but because we had personally felt what it's like to not know whether to trust something that affects your own kid, your own school, your own week. We didn't want to build another generic "misinformation checker" that asks people to read paragraphs of disclaimers. We wanted something as low-effort as the rumor itself — paste the message, or just upload the screenshot you already have open, and get back a real, evidence-backed answer in the time it takes to make tea. That's what Satya Finder is.
How We Built It
We split the system into three independent services from day one, mainly because we knew we'd be iterating on each piece at a very different pace, and we didn't want a frontend tweak to risk breaking the part that actually does the thinking.
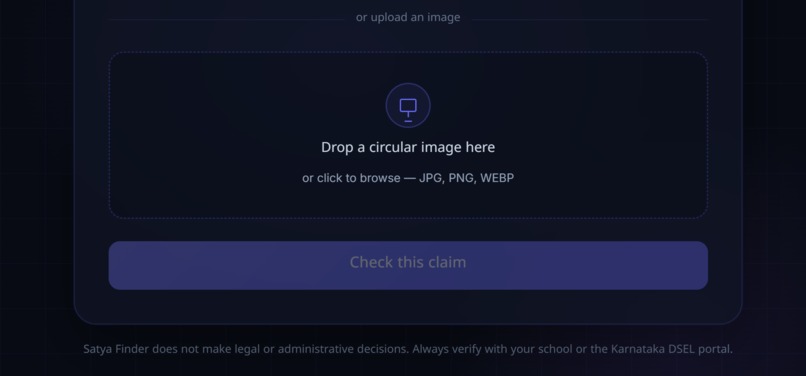
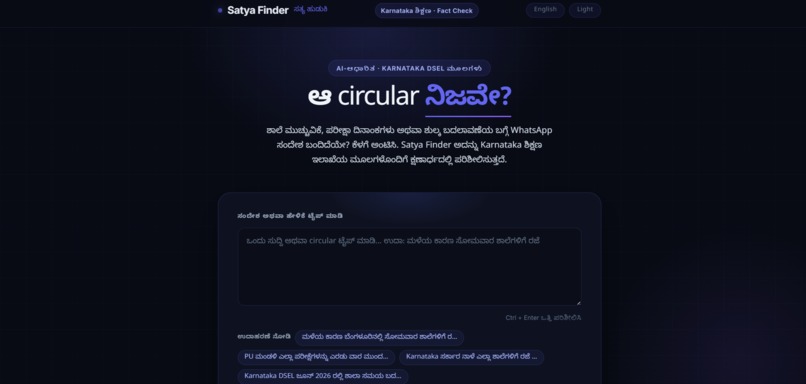
The frontend is built in SvelteKit and deployed on Vercel. It's deliberately simple: a text box for typing or pasting a claim, a drag-and-drop area for uploading a screenshot of a circular or a forwarded message, and support for both English and Kannada, since the rumors we were trying to catch don't show up in just one language. We wanted someone's first interaction with the tool to feel as effortless as forwarding a message to a friend, not like filling out a form.
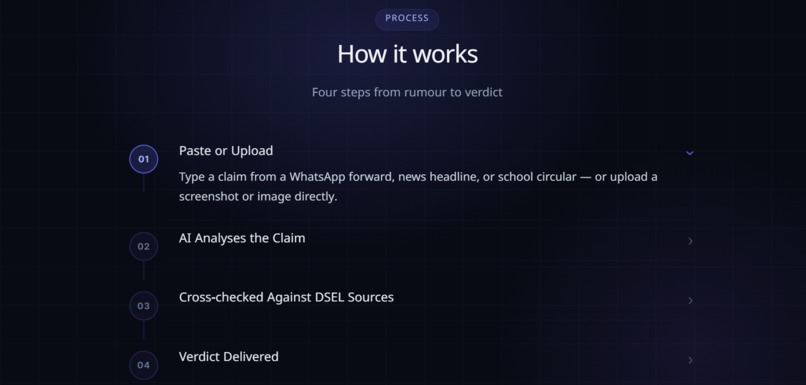
The backend is a FastAPI service that owns all the business logic around a claim. It receives the request from the frontend, forwards the claim (and image, if there is one) to the AI agent, waits for a verdict, and then makes a decision of its own: based on how confident the AI says it is, should this verdict be shown to the user as a final answer, or should it be flagged for a human to review first? We deliberately kept this decision-making layer separate from the AI-facing code, so that if we ever needed to change the storage layer, retry behaviour, or the confidence threshold itself, we could do it without touching a single line of how the model reasons. Verified or flagged claims are then persisted to MongoDB, which also gives us a running record of what's actually being asked, which has been genuinely interesting to look through.
The agent is its own microservice, and it's where most of our actual engineering effort went. It's built with LangChain on top of Groq, running Llama 3.3 70B. Rather than answering purely from what the model already knows, which is exactly how stale or convincing misinformation slips through, the agent is bound to two tools: a web search tool and a page-fetching tool. It runs in a loop, and critically, it decides for itself when to use them — what to search for, which results look authoritative versus which look like a random forum post, and when it has gathered enough evidence to actually commit to a verdict instead of just guessing. The system prompt enforces real research discipline that we wrote and rewrote many times: never settle for a search snippet alone, always fetch and read at least one full page before searching again, and if the claim itself is too vague to investigate — "the school" with no name, "next week" with no date — stop and ask one clarifying question instead of inventing an answer to a question that was never actually asked.
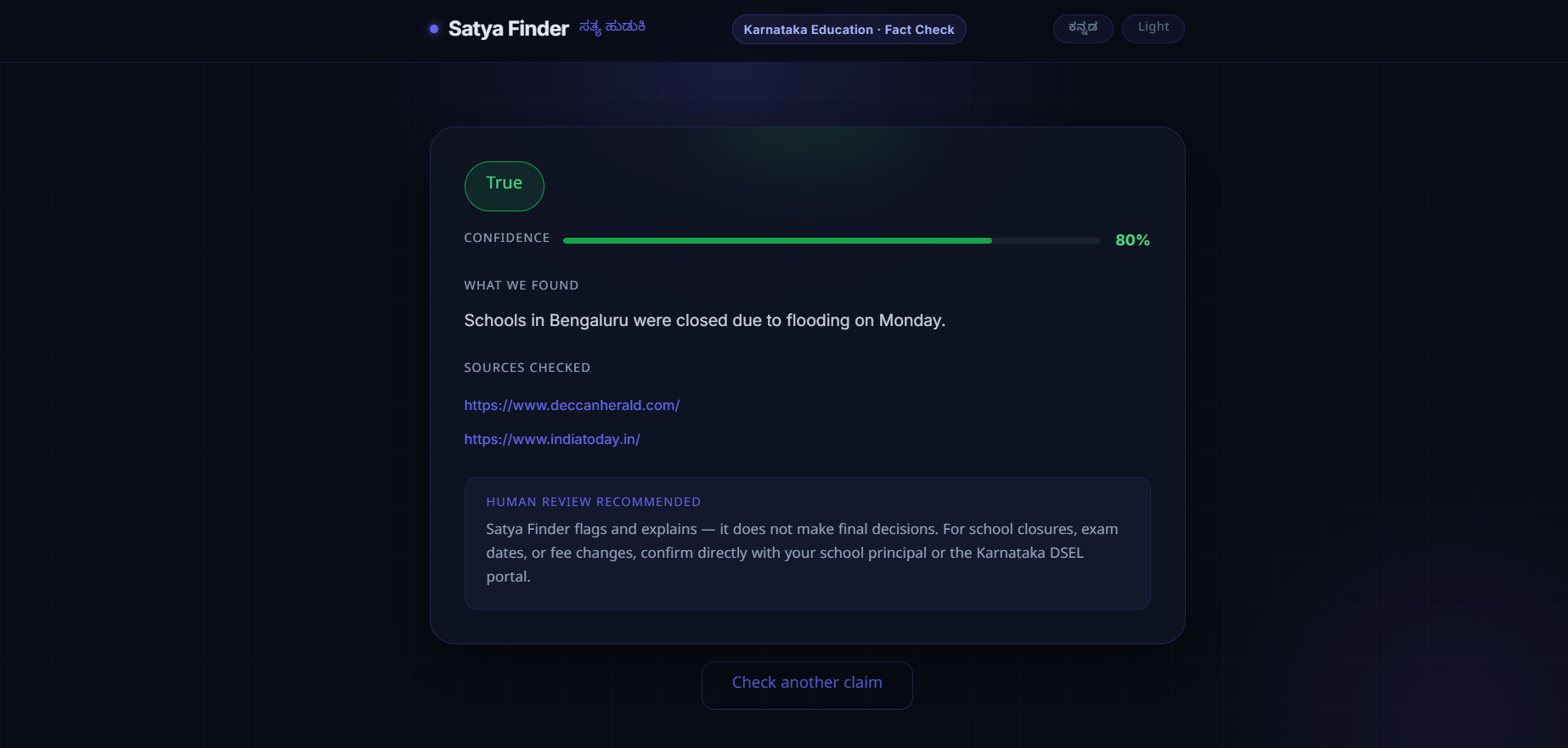
Once the agent reaches a conclusion, it returns one structured answer: a verdict, a plain-language explanation, a list of the sources it actually used, and a confidence score. The backend then applies a simple but important rule to that confidence score before deciding whether a human needs to step in:
$$\text{flagged} = (\text{confidence} \times 100) < 60$$
If the AI's own confidence falls below that threshold, the verdict is automatically routed for human review instead of being shown as a settled fact. We liked this rule precisely because it's so simple — it doesn't try to be clever about when the AI might be wrong, it just respects the AI's own uncertainty and treats that as a signal worth acting on.
Challenges We Ran Into
The hardest problem we faced wasn't getting the agent to research well. It was getting it to fail gracefully when it didn't, which turned out to happen far more often than we expected. Free-tier LLM responses aren't always perfectly formed. Occasionally the model would try to call a tool by writing it out as plain text instead of using a proper function call. Sometimes its final answer would technically be JSON, but wrapped in stray commentary or a trailing comma that broke parsing. And every so often, a request would fail entirely mid-conversation, with the actual content the model was trying to generate buried inside an error response instead of coming back cleanly. The first version of our pipeline would just crash whenever any of this happened, which is not exactly reassuring behaviour for a tool that's supposed to be giving people calm, trustworthy answers during a moment of confusion.
So we built a layered recovery system instead of hoping the model would always behave. We clean up near-valid JSON before parsing it. We scan messy text for a properly balanced JSON object hiding inside it. And as a last resort, if the model wrote out a tool call as plain text instead of calling it properly, we parse that out using pattern matching and recover the attempt rather than discarding it. None of this was glamorous work, and honestly a lot of it felt like debugging the model's bad handwriting rather than building features. But it's the difference between a demo that looks great until the model hiccups once, and a system that actually holds up when real people are typing real, messy, panicked claims into it.
A second challenge was reining in the agent's own research habits. Left completely unconstrained, it would either search the same idea five different ways without ever actually concluding anything, burning time and tokens, or it would jump to a verdict off a single thin, out-of-context snippet because it technically mentioned the right keywords. Neither of those is acceptable for a fact-checker. We had to explicitly engineer rules into the prompt rather than trust good behaviour to emerge on its own: cap how many searches it can run back-to-back before it has to actually read a page, and spell out in plain terms what "enough evidence" really means versus what just looks like enough evidence.
The third challenge, and honestly the one that mattered most to us, was trust itself. A fact-checking tool that occasionally invents its own evidence isn't just unhelpful, it's actively dangerous, because it looks exactly as confident when it's wrong as when it's right. We had to be completely strict that the agent could only ever cite a URL it had genuinely retrieved during that specific session, with zero exceptions and zero "close enough." It sounds like a small rule, but enforcing it properly, and testing that the model couldn't quietly slip a plausible-but-fake source past us, took far more care than building the search loop itself did.
Impact
Think about what actually happens when a rumor lands in a school parent group and nobody checks it.
A parent sees "schools closed tomorrow due to flooding" at 11pm. They don't know whether to believe it or not, but they're not going to stay up hunting through government portals to find out, so they keep their child home just to be safe. Their child misses a full day of school, maybe an exam, maybe something that mattered — because of a message that turned out to be completely made up, forwarded by someone who also didn't check, who got it from someone else who also didn't check. The rumor didn't need to be true to cause real disruption. It just needed to sound plausible and arrive at the right moment.
Now flip that around. A student reads a forwarded message claiming the school has hiked fees by thirty percent starting next month. Their family isn't wealthy. That message lands differently — it doesn't just cause confusion, it causes genuine anxiety, the kind that sits with you for days while you try to figure out whether it's real and what it means for whether you can continue. And then it turns out to be a completely fabricated screenshot that someone made to stir outrage, and the real fee structure hasn't changed at all. The damage from that week of worry doesn't disappear just because the fact was eventually corrected.
This is the specific harm Satya Finder is built to interrupt. Not misinformation as a broad, abstract societal problem — but that precise, mundane, everyday moment when a message lands in your hand and you genuinely don't know what to do with it. Satya Finder changes what happens in that moment. Instead of forwarding it, ignoring it, or acting on it blindly, someone pastes it in, gets back a sourced verdict in seconds, and makes a decision based on actual evidence rather than anxiety. That one action — checking before forwarding — also means the rumor stops with them instead of reaching the next ten people in their contact list.
The people this tool is built for aren't tech-savvy researchers who know how to verify sources. They're parents picking up their phones between cooking and putting children to bed. They're students who see something worrying about their school and have no one to ask. They're teachers who keep getting the same question from parents and have no easy way to point them toward the truth. These are people who would never navigate a government portal but will absolutely paste a message into a simple text box if it means knowing whether to worry or not. That accessibility — the same effort as forwarding, but the opposite outcome — is the design choice that makes the impact real rather than theoretical.
And beyond the individual moments, there's a quieter, longer-term effect: every time someone uses Satya Finder and gets back a "False" verdict on something they were about to share, that rumor travels one step less far. It doesn't reach the next parent group, the next classroom, the next anxious family. The tool doesn't fix the information ecosystem overnight, but it puts one small, reliable checkpoint between a false claim and the next person who would have believed it — and in a place like Karnataka, where school-related misinformation circulates constantly and affects millions of families, that checkpoint is worth building.
What We Learned
Building this taught us that prompt design is real engineering, not just careful wording you sprinkle on top at the end. The rules governing when the agent searches, when it stops, and when it asks for clarification ended up mattering just as much to the final output quality as the model choice itself. We also learned, somewhat the hard way, that working with smaller or free-tier models means you have to design for failure from the very beginning, because you simply cannot assume every response is going to come back clean and well-formed.
But the lesson that stuck with us most was about restraint. It would have been easy to make the AI sound confident all the time, because confident answers feel more impressive in a demo. Instead, we kept coming back to the same idea that started this whole project: the rumors we see every day on Facebook, Instagram, and in our own WhatsApp groups are convincing precisely because they sound certain, even when they're not. We didn't want to build another confident-sounding thing. We wanted to build something that knows the difference between "I found solid evidence" and "I'm genuinely not sure," and is honest enough to say so out loud, even if that means handing the final call to a human instead of pretending it has all the answers.
Built With
- beautiful-soup
- duckduckgo-search
- fastapi
- gridfs
- groq
- httpx
- javascript
- langchain
- langchain-groq
- langgraph
- llama-3.3-70b
- mongodb
- pydantic
- python
- svelte
- sveltekit
- uvicorn
- vercel


Log in or sign up for Devpost to join the conversation.