
SATYA - AI-Powered Truth Engine & Digital Forensics Platform
Inspiration
Our generation lives in a world of sixty second clips. News, history, and even life advice are increasingly consumed through short form videos that are designed to be fast, engaging, and emotionally convincing. While this has made information more accessible than ever, it has also made it harder to understand complex topics in a balanced way.
As individuals who have pursued engineering for most part, we are well aware that we don’t have much knowledge when it comes to other spheres of academia like economics, history, biology, nutrition etc and so do many other people, any individual cannot know everything. In practice, that often means we rely on whatever explanation reaches us first through our feed. The issue is not always misinformation or outright lies. In fact, the most persuasive content is often built on true facts. The problem lies in how those facts are framed.
A creator can take valid data, remove surrounding context, and present it within a personal narrative that subtly pushes the viewer toward a specific conclusion. When this happens at scale hundreds of times a day it becomes unrealistic for users to independently verify or explore every claim in depth.
We also realized that there is no dedicated truth or fact-checker general tool especially for videos. When we tried using standard LLMs to check these narratives, the results were often disappointing. They were either biased, prone to hallucination, or simply summarized the top few search results without deep investigation. If the training data didn't cover the specific niche topic, the LLM would confidently state falsehoods or miss the nuance entirely.
This motivated us to build SATYA (Sanskrit for "Truth"). The goal is not to accuse creators or assume bad intent, but to restore the context that short-form content often leaves out. By presenting supporting evidence, counter-points, and missing assumptions, the tool helps users see the broader picture and understand how different interpretations emerge from the same facts.
Rather than telling people what to think, this project aims to give them better tools to think with. In a media environment optimized for speed and engagement, I believe restoring nuance is not just valuable — it’s necessary.
What it does
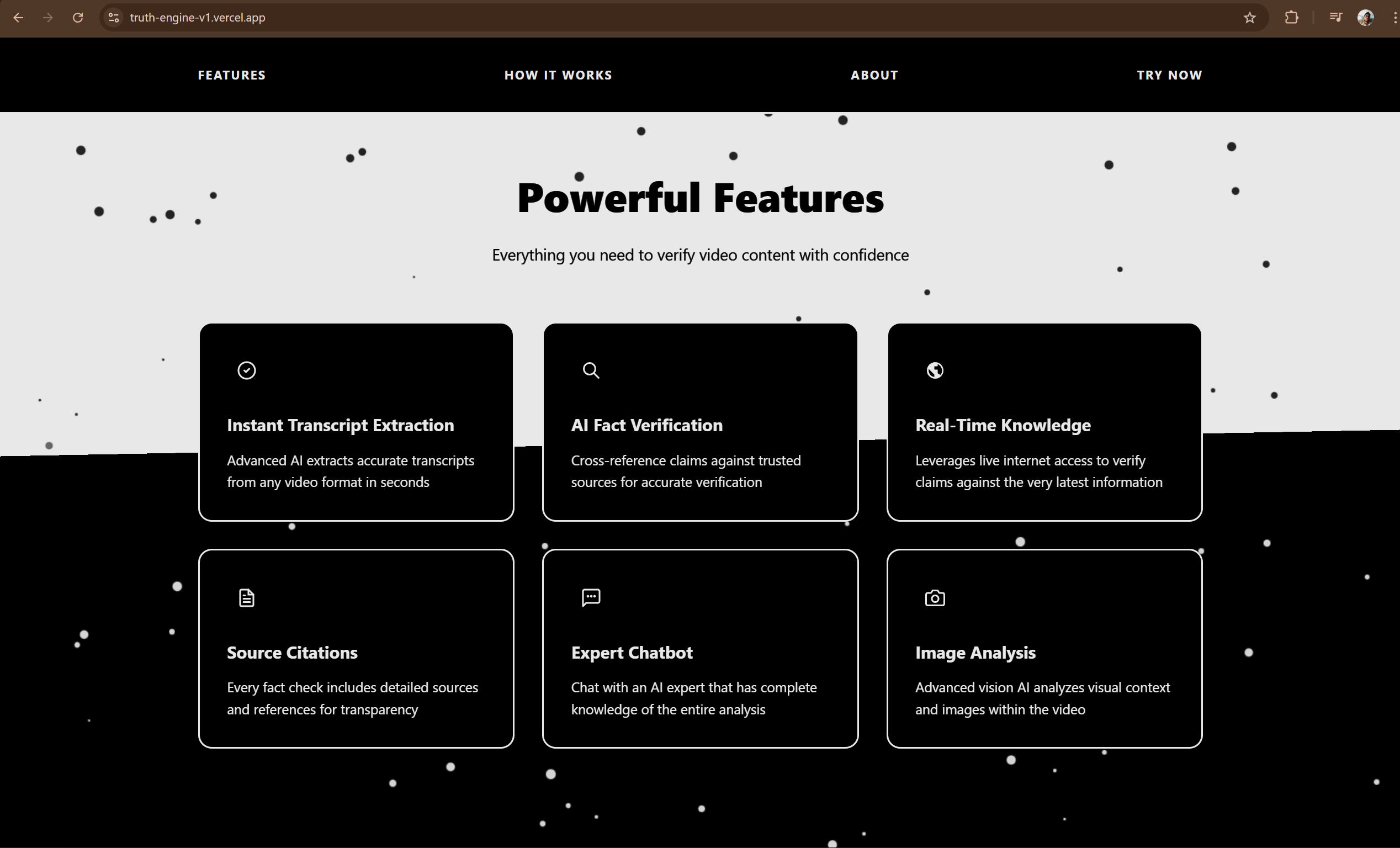
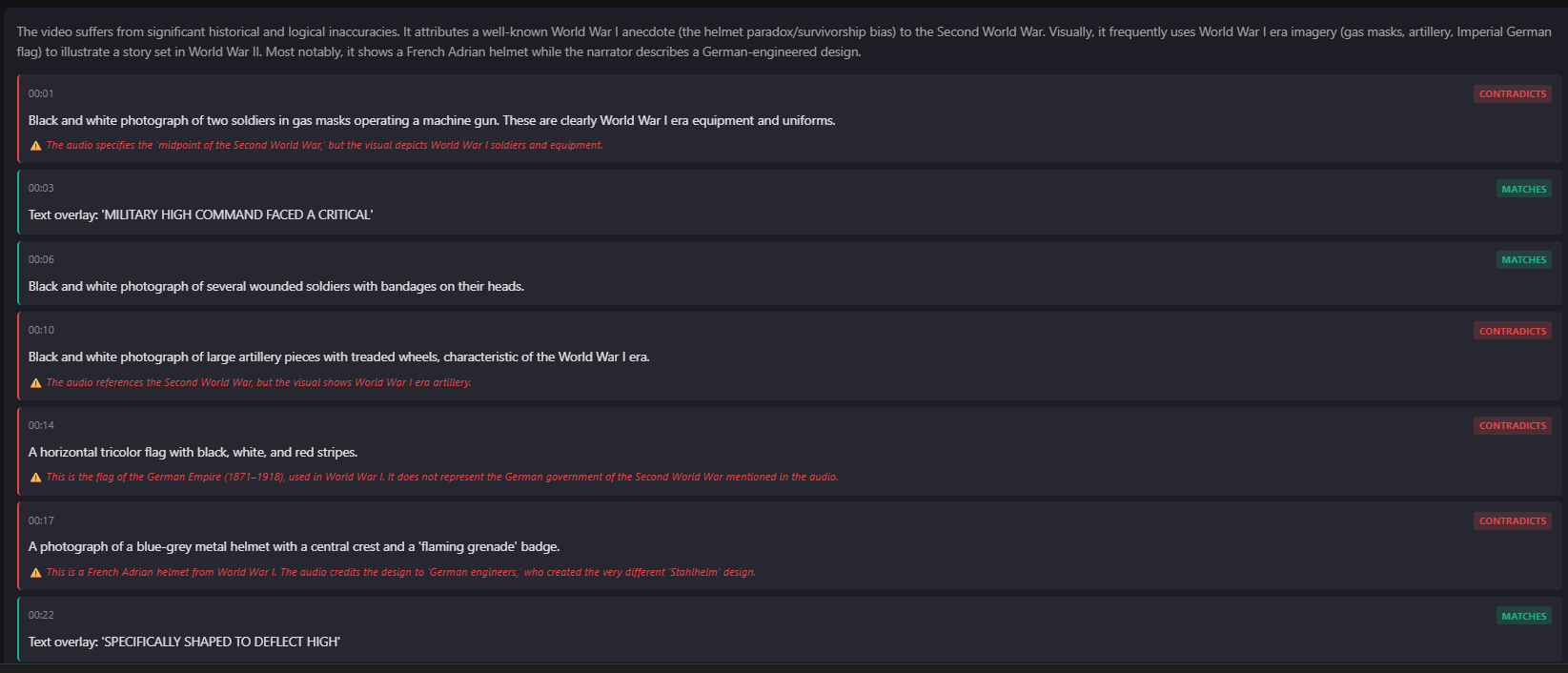
SATYA is an autonomous investigative platform that verifies video content or a general query comprising of claims and implication with the rigor of a professional research team. Unlike standard tools that look for literal keyword matches or solely depends on the top websites showing up on the internet, SATYA understands implication — what the video is trying to make you believe, not just what it says.
It employs a novel Digital Courtroom architecture:
The Prosecutor and Defender: Two separate AI agents actively search for conflicting evidence. One tries to debunk the claim, while the other tries to verify it. This adversarial approach prevents confirmation bias.
The 3-Tier Verification Shield: To solve the "internet reliability" problem, we built a robust filtration system:
- Tier 1 (Instant): Checks against Google’s Fact Check Tools API for existing professional verdicts.
- Tier 2 (Reputation): Cross-references claims against a curated Trust Index of high-credibility domains (Reuters, BBC, WHO, etc.), filtering out noise from low-quality blogs.
- Tier 3 (Consensus): The most powerful layer. It analyzes 10+ disparate sources to determine the consensus of reality. Based on the system's logic:
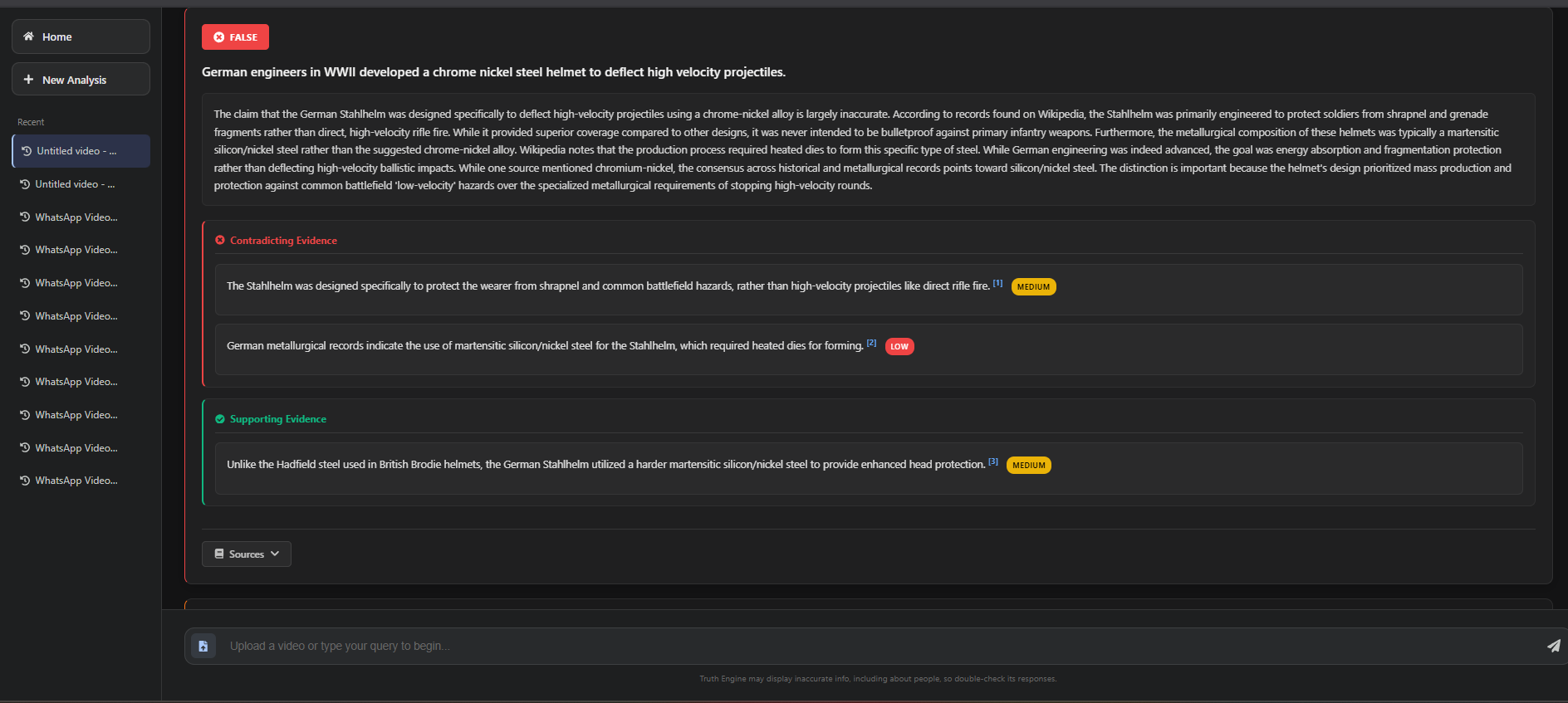
High Confidence: If 7 or more sources (70%+) agree, the fact is considered established.
Medium Confidence: If 5 to 6 sources (50–69%) agree, the consensus is accepted but with medium confidence.
Low Confidence / Unclear: If fewer than 5 sources (less than 50%) agree, the result is considered unclear or low trust.
Finally, an AI Judge synthesizes all this — not into a simple "True/False" stamp, but into a nuanced verdict with citations, context, and a Truth Score.
How we built it
The Core: A Smart "Courtroom" Engine
We architected the backend using LangGraph to create a state machine that mimics a legal trial.
- Implication Engine: Uses Gemini 3.0 Flash to decompose videos into testable claims.
- Query Generators: Generate opposing search queries for prosecution and defense.
- Advocates (Defender & Prosecutor): Use Tavily API for real-time web searches.
- Lead Promoter: Dynamically spins up new sub-investigations when strong tangential evidence is found.
- Judge Node: Gemini 3.0 Pro with High Thinking mode issues final verdicts.
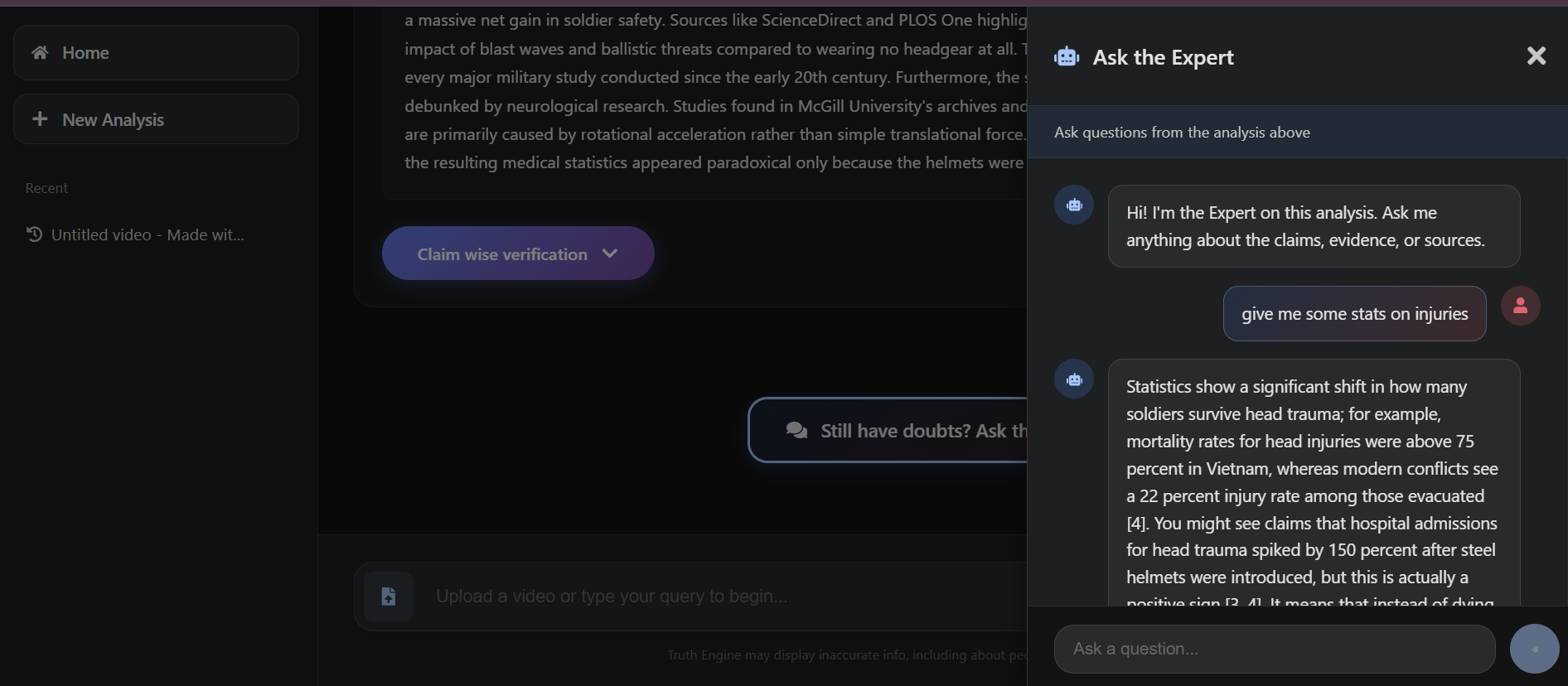
The Brain: Expert Chat & RAG
We established a ChromaDB vector store with Gemini Embeddings (gemini-embedding-001). Every verified fact and source is indexed using RETRIEVAL_DOCUMENT mode for storage and QUESTION_ANSWERING mode for query processing, enabling interactive follow-up conversations.
The Interface
Built with React + Vite featuring a Future Interface aesthetic. GSAP powers high-performance animations with a glassmorphic design that organizes complex data into digestible Verdict Cards. The landing page features a spinning background representing the journey toward truth.
Challenges we ran into
The Poor Quality Results
Initially, we relied on "top-k websites" logic, which surfaced low-quality sources like Reddit and Quora. We filtered out discussion forums and used Prompt Engineering to extract only concrete, checkable facts with numbers, dates, and citations.
# backend/services/courtroom/nodes/advocate.py
4. Each fact MUST contain SPECIFIC, CHECKABLE information:
- Numbers, percentages, statistics
- Dates, years, time periods
- Names of people, organizations, studies
- Citations to research, court cases, laws, scriptures
The "Hallucination" Trap
The AI was too agreeable, marking anything as "Verified." We built the Adversarial Prosecutor Node to actively search for debunking evidence, forcing the model to scrutinize every claim.
The "Rate Limit" Wall
We hit Gemini's rate limits quickly. Solution: Batch Processing (4-5 sources per call) and a "Thinking Budget" allocator—high reasoning for the Judge, low for simple tasks. This cut API calls by 75%.
# Low thinking: Fast tasks (decomposition, query generation)
llm_decomposer = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", thinking_level="low")
# Medium thinking: Analysis tasks
llm_analyzer = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", thinking_level="medium")
# High thinking: Final verdict
llm_judge = ChatGoogleGenerativeAI(model="gemini-3-flash-preview", thinking_level="high")
The "Context" Problem
Vector databases gave irrelevant results. We switched to task-specific embeddings (RETRIEVAL_DOCUMENT for storage, QUESTION_ANSWERING for queries), drastically improving retrieval accuracy.
Information Retrieval Issue
Tavily was too specific, finding only claim mentions instead of surrounding evidence. We hardcoded query formats with terms like "(debunked)" and "(verified)" instead of free-form LLM queries.
Inconsistent Answer Issue
Results varied based on which sources were fetched. We fixed this by:
- Setting temperature to 0 with fixed query formats
- Using 5 websites per defender/prosecutor query for robustness
- Implementing Consensus Search across 10 websites in Tier-3 verification
Issue When Implication Becomes the Claim
When users input only an implication (e.g., "Earth is Flat") without separate claims, our Lead Promoter searches the web for 5 key evidences and converts them into verifiable claims for investigation.
Accomplishments that we're proud of
- The "Implication" Standard: Most fact-checkers verify strictly what is said ("The sky is green"). We built SATYA to verify the implication ("Therefore, aliens exist"). Connecting distinct, isolated facts to validate or debunk a central narrative is a massive leap forward in context-aware AI.
- Three-Tier Verification Logic: Beyond simple fact-checking, we implemented a granular trust system. Tier 1 does a rapid API check, but Tier 2 is where the magic happens: the LLM dynamically assigns "Trusted Source" badges to evidence based on domain reputation, ensuring high-authority sources weigh more in the final verdict.
- The Verified Consensus Engine: Building the Tier-3 consensus logic was our proudest technical achievement. Seeing the system correctly identify a "partial truth" by autonomously weighing conflicting reports from CNN, Fox, and impartial scientific journals was a validation that our weighted-voting system works.
- The "Adversarial" Architecture: We didn't just build a fact-checker; we built a courtroom. By engineering a "Prosecutor" node that actively tries to destroy the claim and a "Defender" node that supports it, we solved the "AI Sycophancy" problem where models just agree with the user.
- Verdict Robustness: One major issue with LLM-based checkers is variance running the same claim twice often yields different results. Our Consensus Search and fixed-format querying solved this. The verdict doesn't sway just because the search found slightly different sources this time; the consensus mechanism ensures stability and consistency.
- Efficiency at Scale: We hit the rate limit wall and broke through it. By implementing a "Thinking Budget" allocator—routing simple tasks to fast models and complex reasoning to "High Thinking" models—we achieved 75% cost reduction while maintaining deep analytical capability.
- Visual Forensics: Integrating Gemini's vision capabilities allowed us to verify not just what was said, but what was shown. We can now debunk out-of-context video clips where the audio might be real, but the visual context contradicts the claim.
- A "Living" Knowledge Base: Because we integrated real-time Google Search grounding, SATYA never has outdated knowledge. Unlike static models limited by their training data cutoff, SATYA verifies against the internet as it exists right now.
What we learned
- Reliability > Speed: A fact-checker that is fast but wrong is worse than useless; it's harmful. We learned to prioritize the slow, expensive "Thinking" models for the final verdict over rapid but shallow responses.
- Prompt Engineering is Logic Engineering: Getting structured JSON out of a reasoning model requires more than just asking. We learned to treat prompts like code conventions, using strict schemas and adversarial constraints to control the AI's "thought process."
- The User doesn't want "False": They want to know why. We shifted our UI from big red X marks to detailed analytical paragraphs because persuasion requires explanation, not just adjudication.
- Adversarial Testing is Verification: Simply finding supporting evidence proves nothing in the age of the internet. We learned that true verification comes from actively trying to disprove a claim (the Prosecutor Node) and failing, rather than just finding confirmation.
- Resource Orchestration: Not every task needs a PhD-level analysis. We learned to treat "Thinking" as a scarce resource to be allocated (Thinking Budget), using high-reasoning models only for the Judge node while using faster models for standard extraction.
- User Intent > User Input: Users often state implications, not verifiable facts. We learned that a robust system must proactively investigate the implication (Lead Promoter) when direct claims are missing, rather than rejecting the input as "unverifiable."
What's Next for SATYA
- Deepfake Audio Detection: We plan to integrate audio spectral analysis to identify and flag AI-generated voices before fact-checking even begins, adding a crucial layer of authenticity verification.
- Deepfake Video Detection: Expanding beyond audio, we aim to detect visual manipulation in video content, ensuring users are protected from sophisticated visual forgeries.
- Browser Extension: We are developing a browser extension to bring SATYA directly to your social feeds (Twitter/X, Facebook), auto-flagging suspicious video clips in real-time as you scroll.
- Community "Jury": We want to empower users to submit their own evidence to the "Courtroom." The AI Judge will then rigorously evaluate this user-submitted evidence, reasoning against or for it in future verdicts, creating a collaborative truth engine.
- Multi-Language Detection: While Gemini supports multi-language analysis, our current frontend is optimized for English display. We plan to upgrade the UI to fully support and display multi-language fact-checks, making truth accessible globally.
Built With
- antigravity
- chromadb
- docker
- fastapi
- gemini-3-flash-preview-api
- gemini-embedding-001
- google-cloud-run
- google-fact-check-api
- google-generativeai
- javascript
- langchain
- langgraph
- python
- react
- tavily-api
- vercel
- vite



Log in or sign up for Devpost to join the conversation.