-
-
Multilingual
-
Core Features on Landing Page
-
Discover non profits and their offerings
-
High Level Architecture
-
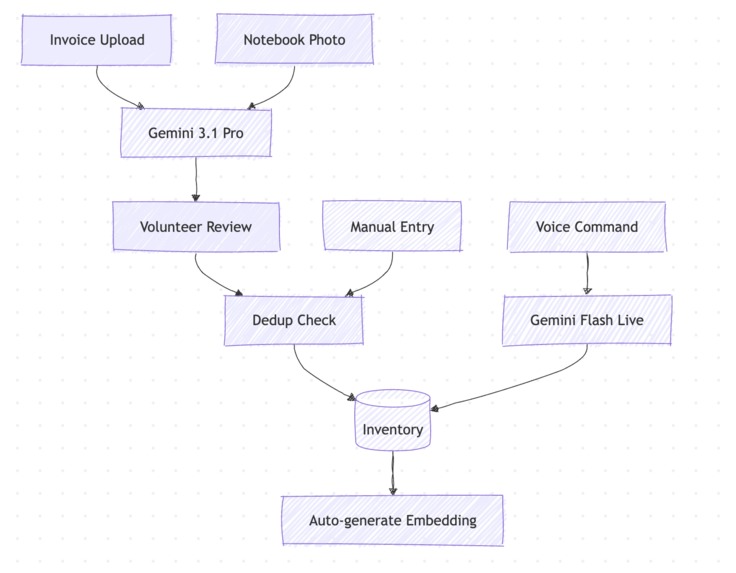
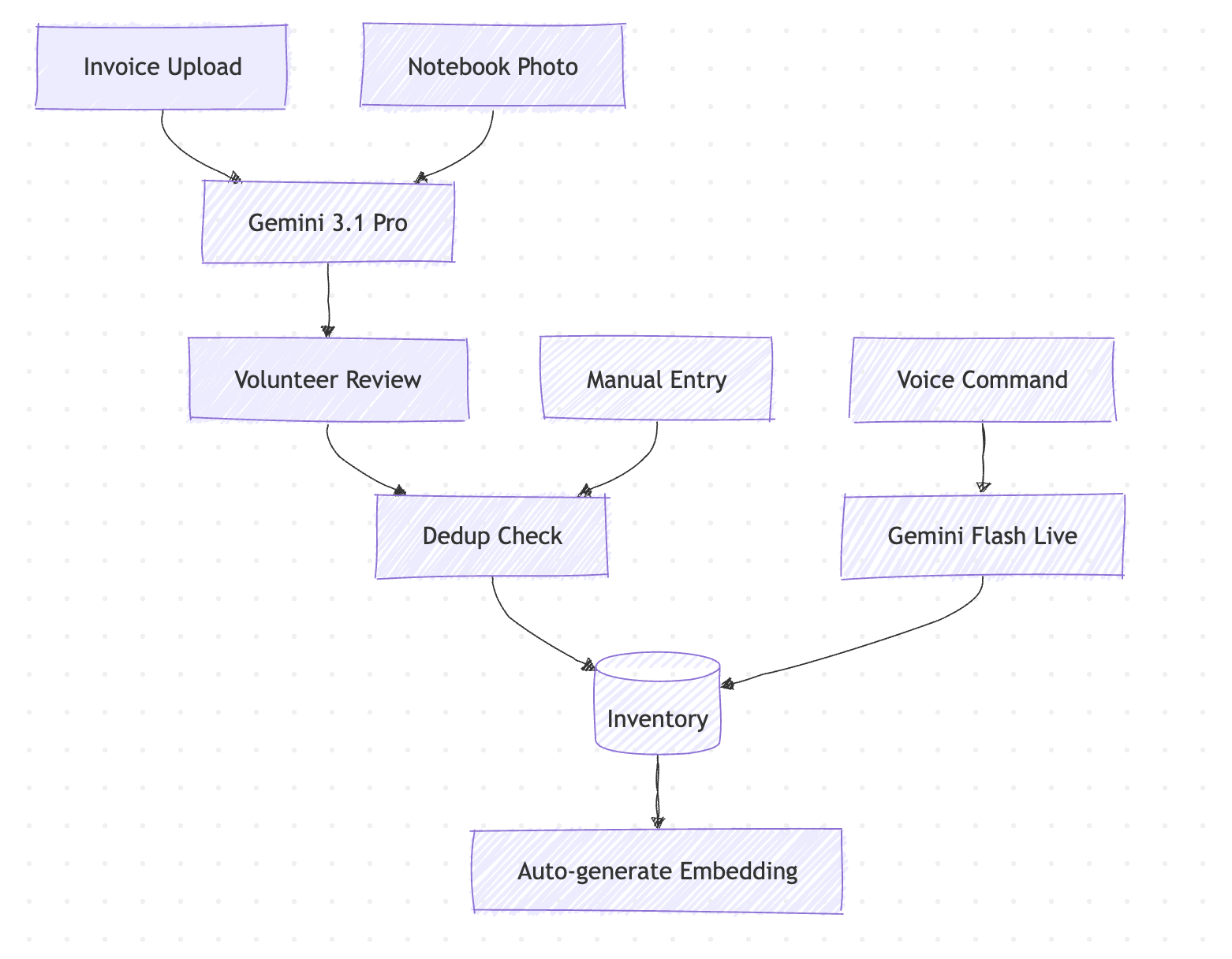
Data Flow
-
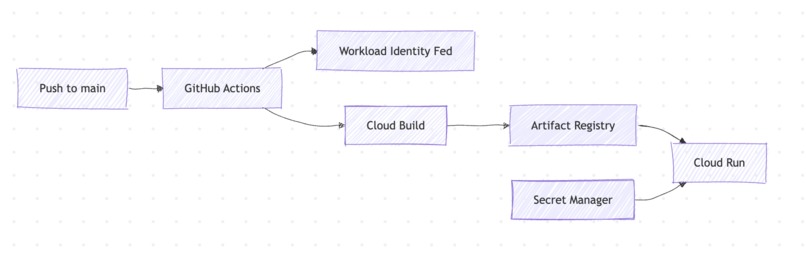
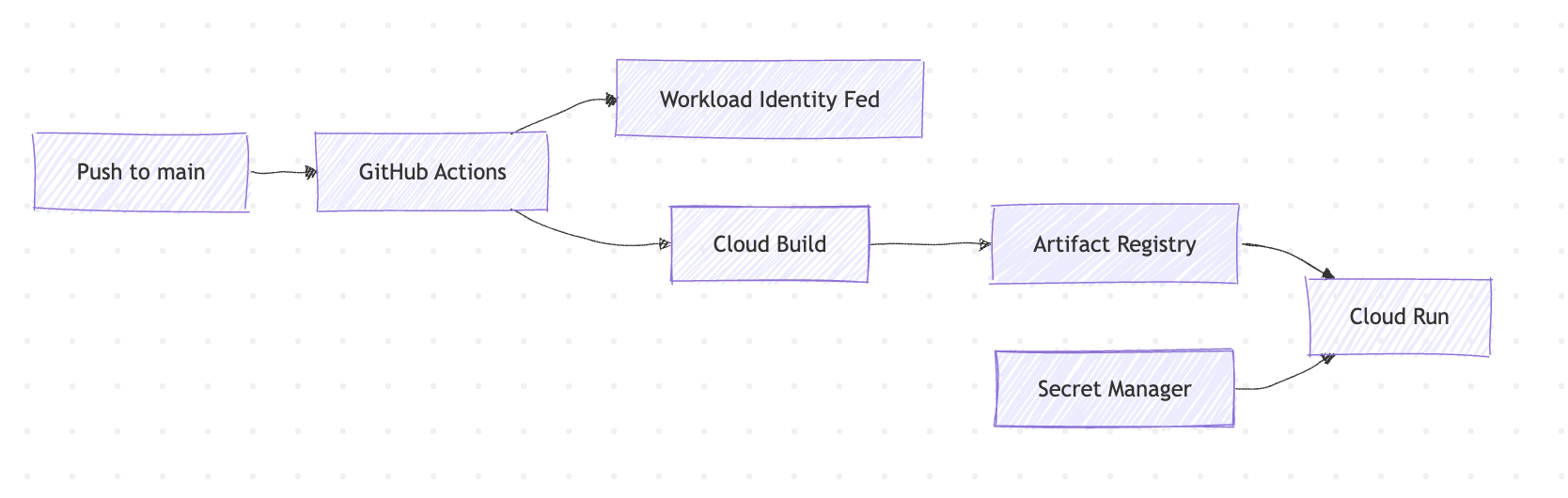
CI/CD Pipeline
-
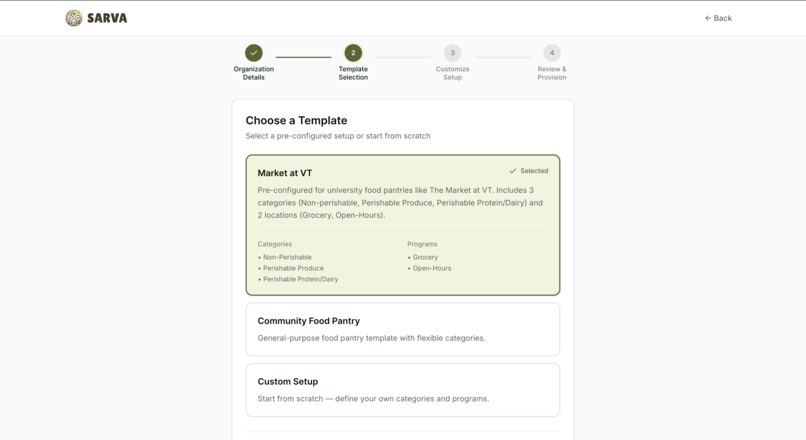
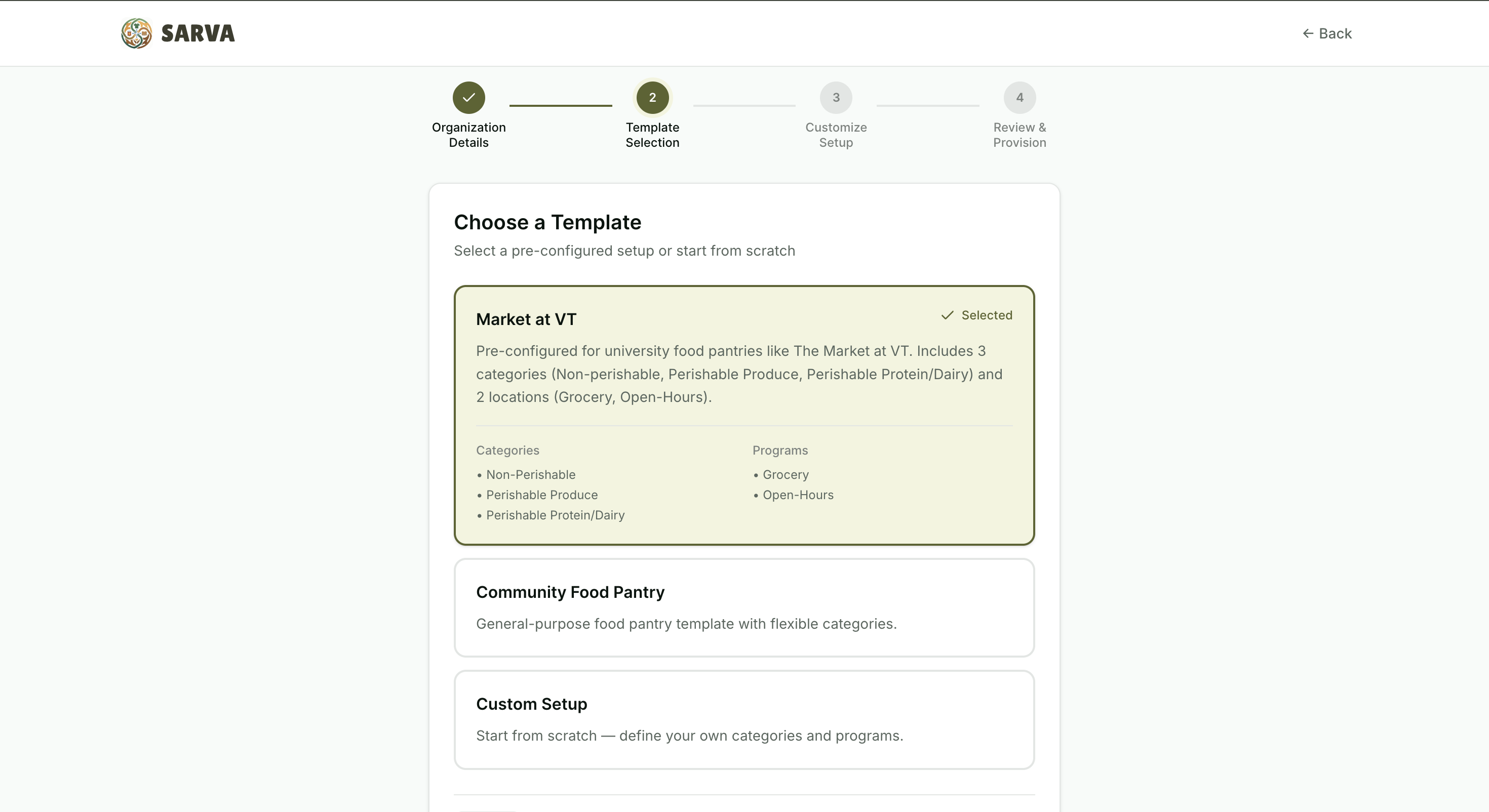
Choose template
-
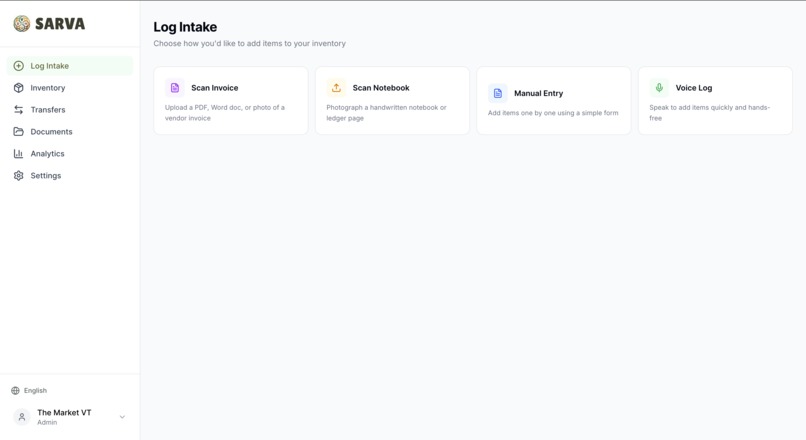
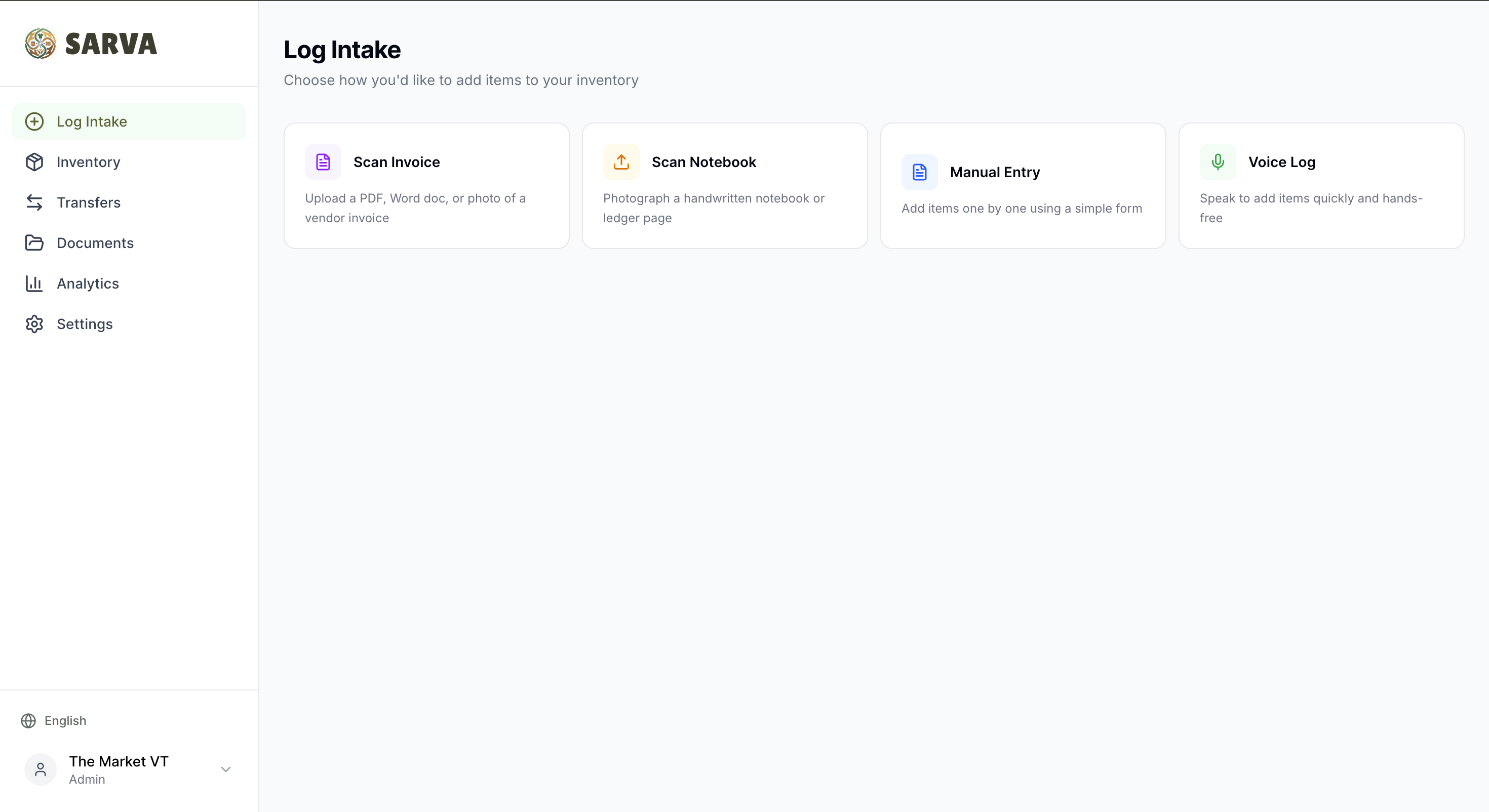
Log Inventory - 4 ways
-
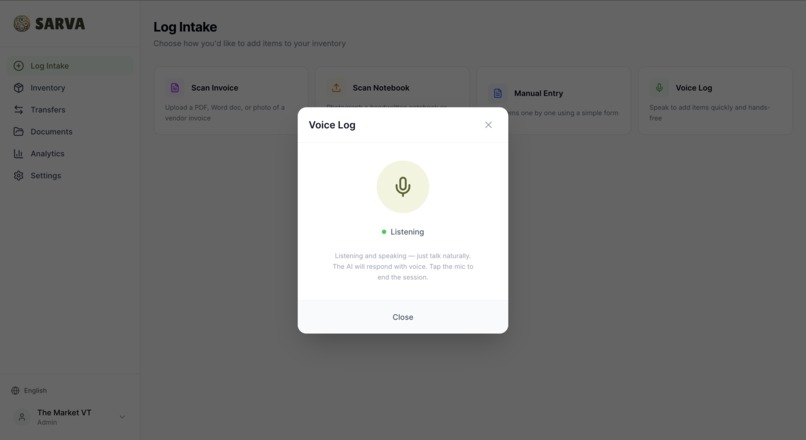
Voice Feature
-
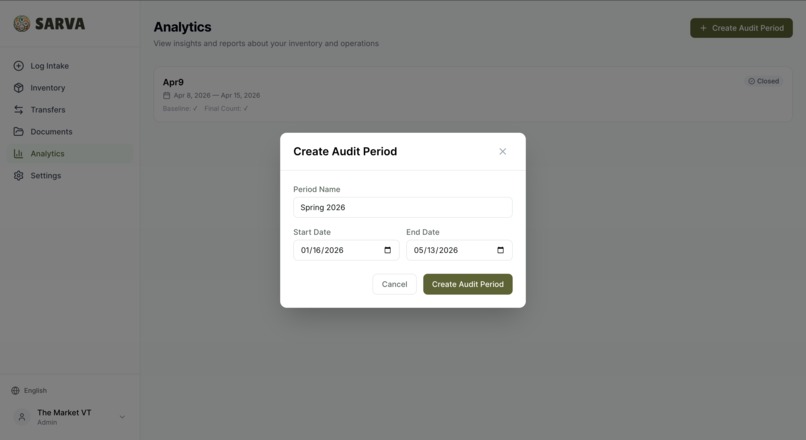
Custom analytics period for flexibility
-
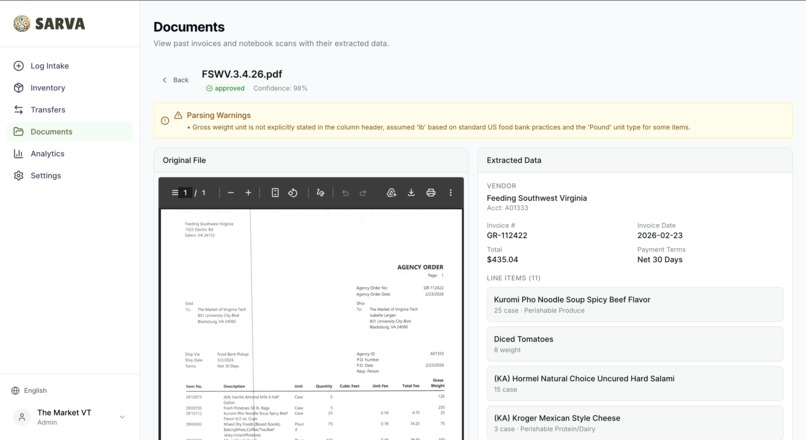
Documents Uploaded to system
-
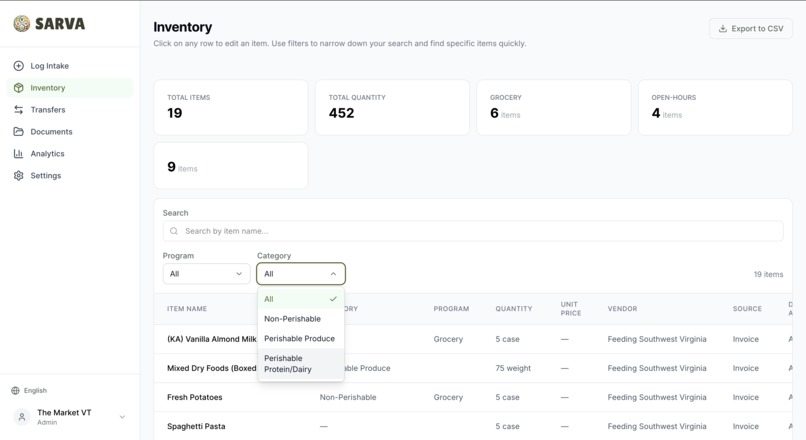
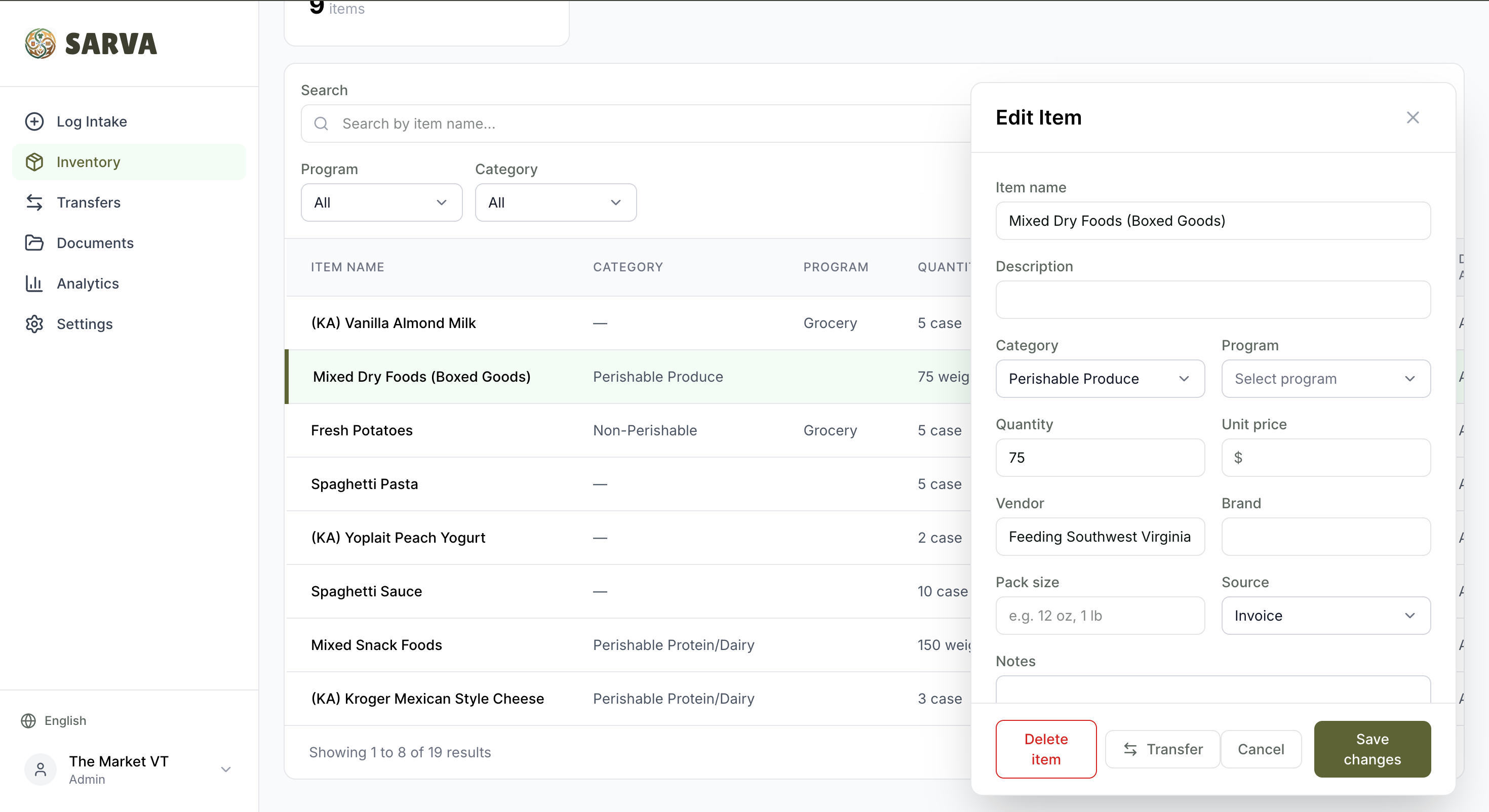
Inventory page
-
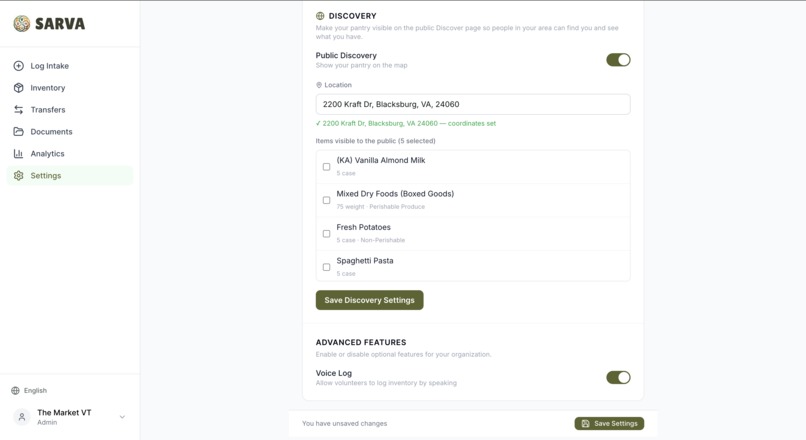
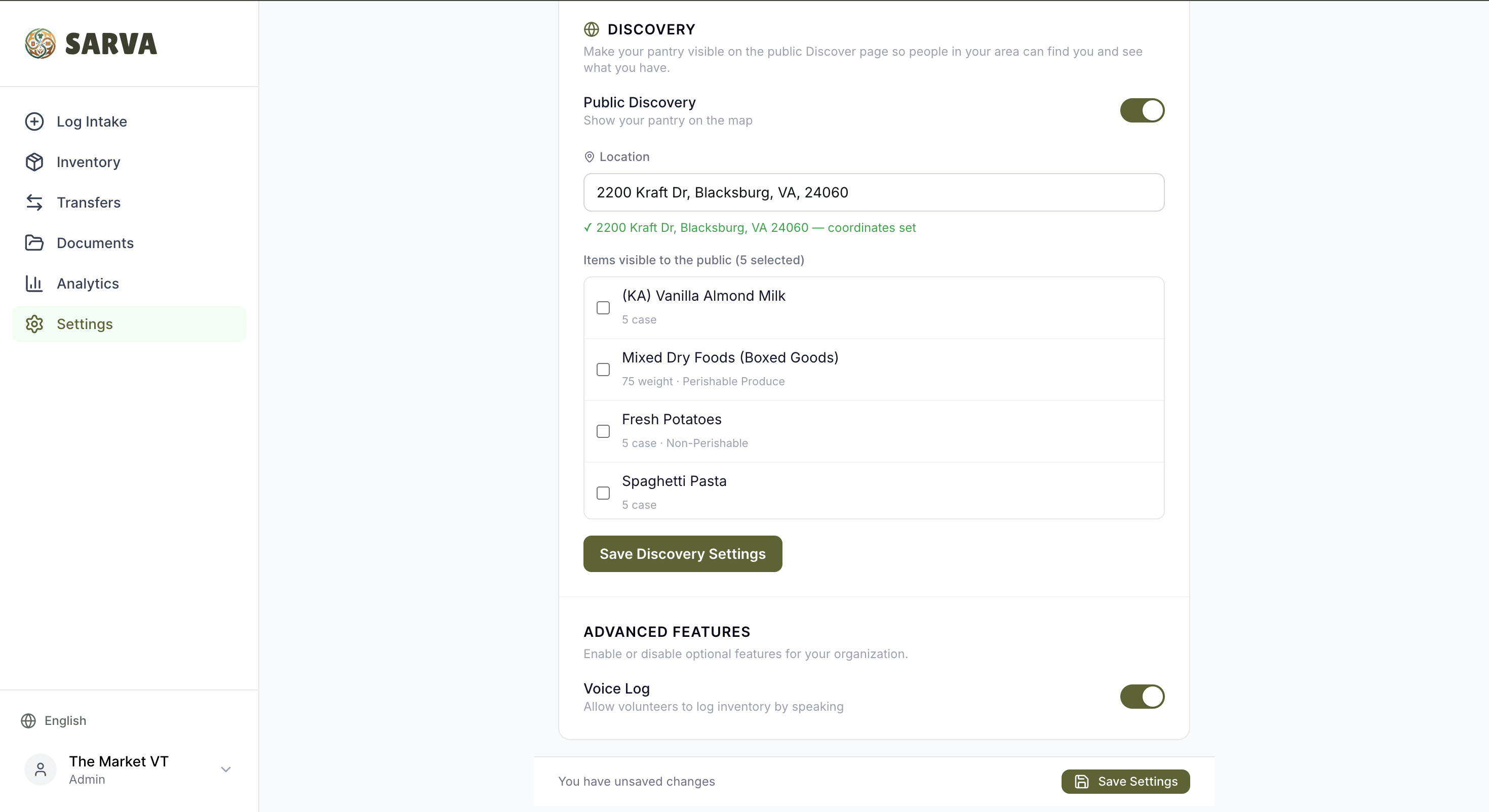
Organization Settings - set discovery mode
-
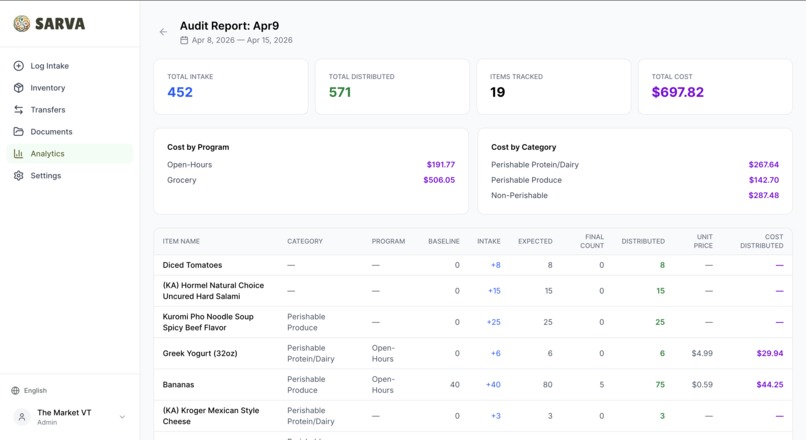
Audit Report
-
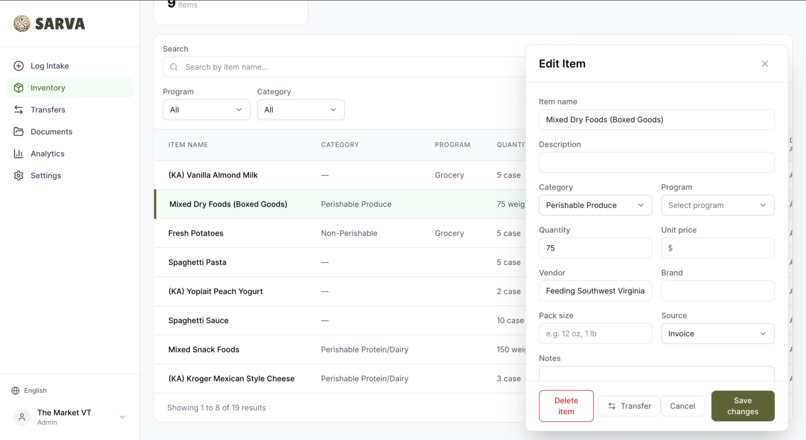
Item edit
-
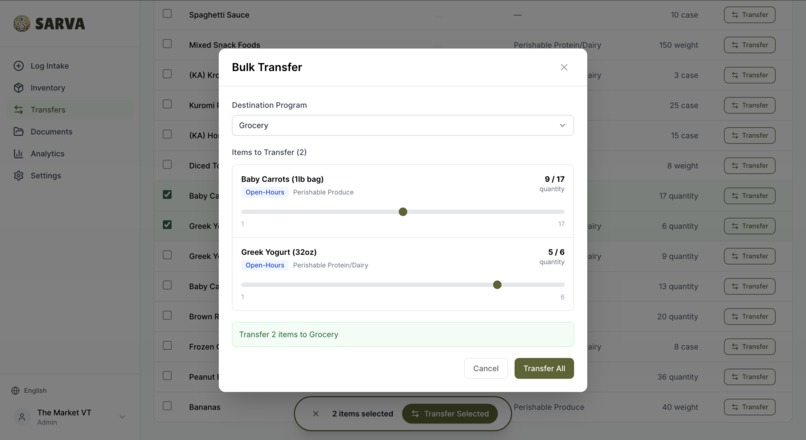
Bulk transfer
Sarva — One Platform for Every Nonprofit That Moves Inventory
Inspiration
Over 295 million people across 53 countries faced acute hunger in 2024 — a sixth consecutive annual increase. Globally, roughly one-third of all food produced — 1.3 billion tonnes — is wasted every year, representing $1 trillion in economic value and 8–10% of global greenhouse gas emissions. The organizations fighting this crisis — food banks, pantries, clothing drives, school supply programs — are overwhelmed, understaffed, and running on paper.
The Global FoodBanking Network reports that food banks across 46 countries served 38 million people in 2024, with 436,000 volunteers — a 40% increase over the prior year. Yet over 80% of nonprofits struggle with digital readiness, and 30% still rely on spreadsheets for core operations, losing 10+ hours per week to manual data entry. These aren't tech companies with IT departments — they're volunteer-driven organizations where every hour spent on paperwork is an hour not spent feeding people.
We connected with Isabelle Largen, Assistant Director for Food Access Initiatives at The Market at Virginia Tech — a campus food pantry serving 115 to 200 students every week. Volunteers there log thousands of pounds of donated food into a physical notebook, then re-enter it all into Excel. Isabelle told us:
"Any given week, we're getting thousands of pounds of products — 30 to 60 different items. We're literally having to go in and track it all by hand. There's just a lot of room for human error."
The Market at VT was able to reach out to us — but they represent just one of over 1.8 million nonprofits in the US alone that manage physical inventory. Globally, the number is far larger. Most of these organizations are neglected by technology — too small for enterprise software, too resource-constrained to build their own, and too diverse for one-size-fits-all solutions.
We sat down with Isabelle for a full stakeholder meeting. We came with 13 prepared questions across three priority tiers — core logistics, data constraints, and feature validation — and left with answers that completely reshaped our architecture:
- No checkout tracking at all. Student anonymity is non-negotiable. You can't log what leaves the shelves. So how do you know what was distributed? We had to invent a new approach.
- No barcodes. Donations arrive as random bulk boxes from Feeding America at 9 cents a pound. Items are loose, damaged, unlabeled. Traditional inventory systems are useless here.
- Only 3 categories. Not 50 SKU types — just Non-perishable, Perishable (Produce), and Perishable (Protein/Dairy). Granular tracking creates friction for volunteers who rotate weekly.
- Invoices arrive as chaos. Word documents, multi-page PDFs, scanned images — about 3 per week from vendors like US Foods and Feeding America. Every format different.
- Physical notebooks are the source of truth. Handwritten entries, sometimes illegible, with org-specific shorthand like "Enrolled" meaning the Grocery program and "Open" meaning Open-Hours.
- No digital expiration tracking. They use physical FIFO shelving. Adding expiration fields would slow volunteers down for zero benefit.
- Audits happen 1–2 times per semester, not daily. The baseline-to-baseline cycle is the unit of measurement.
Every one of these answers became a design decision. We didn't build what we assumed a pantry needed — we built what The Market at VT actually told us they needed, then abstracted it so any organization anywhere in the world could use it.
This is not a VT-specific app. This is a global platform. There are over 60,000 food pantries in the United States alone, food banks operating across 46 countries on 6 continents, and over 1.8 million nonprofits in the US that manage physical inventory — food, clothing, school supplies, hygiene products. Globally, the number of organizations that could benefit from this is orders of magnitude larger. If just 1% of those 60,000 US pantries adopted this platform and each recovered 5 hours of volunteer time per week, that's 3 million volunteer hours per year redirected from paperwork to feeding people. Scale that worldwide, and the impact multiplies.
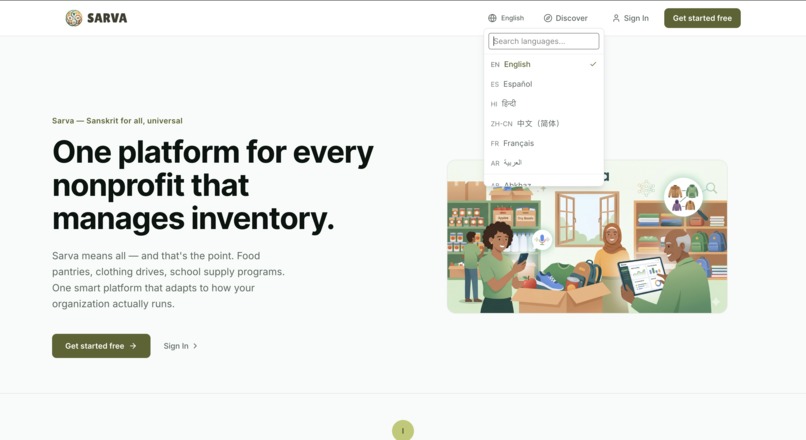
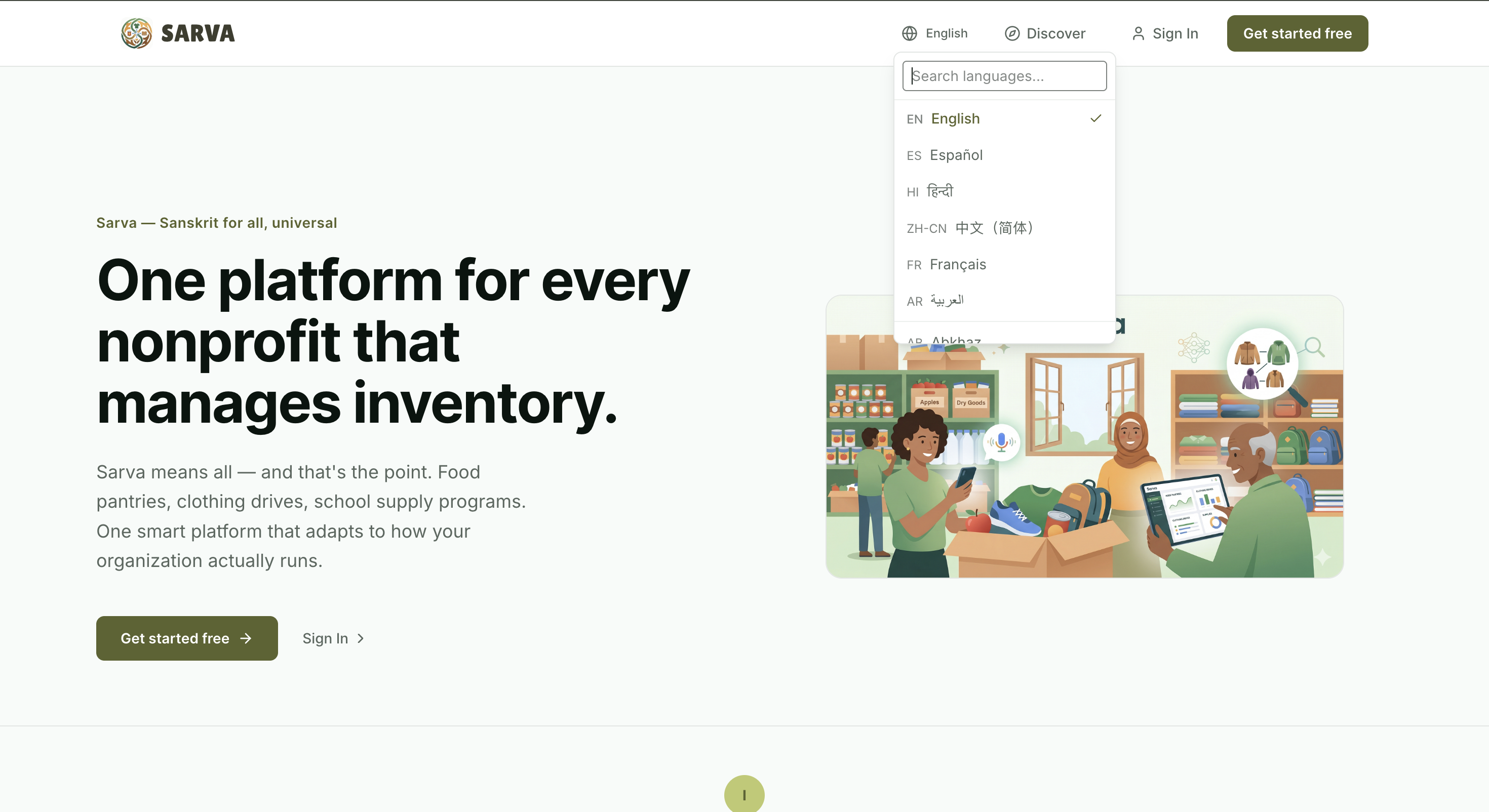
The language barrier alone excludes millions. 25.7 million people in the US have limited English proficiency, and globally, language is one of the most significant barriers to humanitarian aid delivery — when people can't communicate with service providers, they can't access the help that exists. A platform that only works in English, or that requires literacy and typing, is already excluding the people who need it most. That's why Sarva supports 100+ languages across the entire UI and offers a multilingual voice agent — so a volunteer in Bogotá, a pantry director in Nairobi, or a student worker in Blacksburg can all use the same platform in the language they're most comfortable with.
What It Does
Sarva (Sanskrit for "all, universal") is a multi-tenant SaaS platform that digitizes nonprofit inventory operations with zero friction. Organizations sign up, pick a template, get a personal URL and PINs, and start logging immediately.
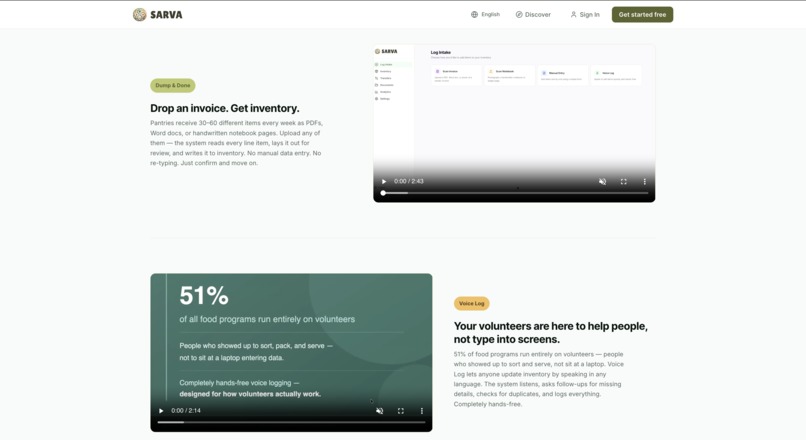
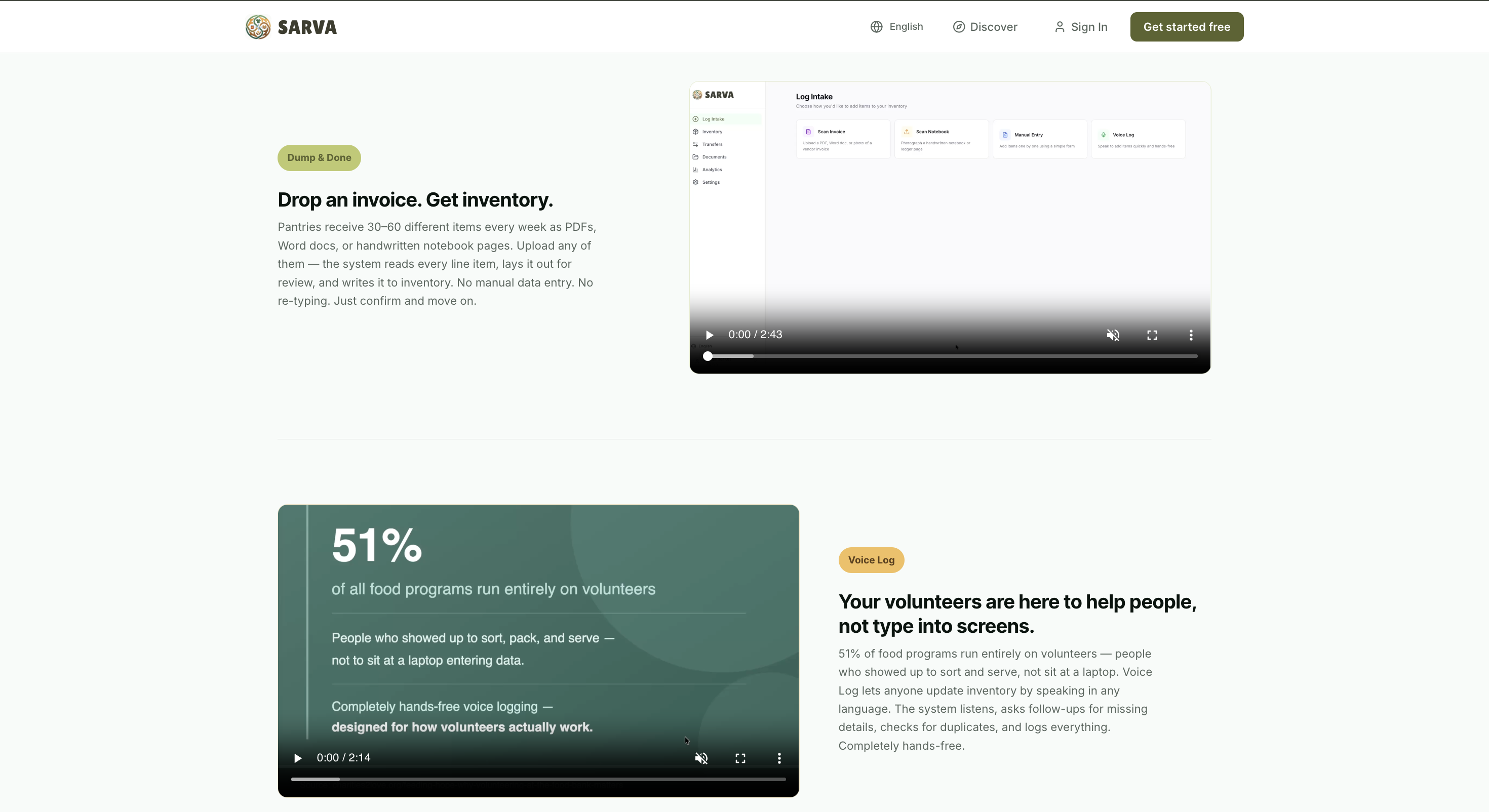
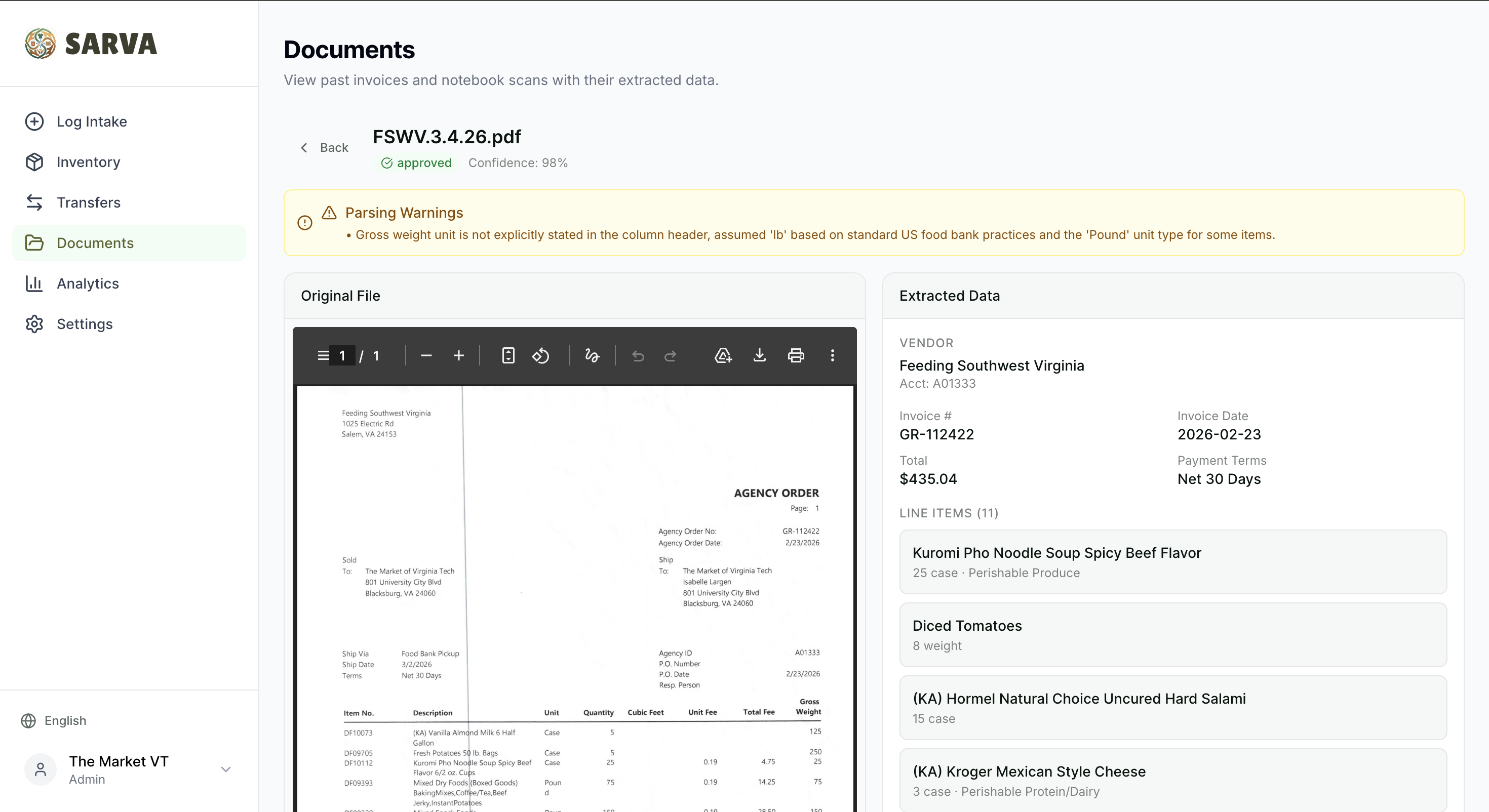
Dump & Done — AI Document Parsing
Logging a delivery shouldn't take longer than the delivery itself. Manual invoice processing takes an average of 12 minutes per document — and that's for trained staff, not rotating volunteers.
Drop a PDF invoice, Word document, or photo of a handwritten notebook page — the AI reads every line. Item names, quantities, prices, brands, pack sizes, temperature zones — all extracted automatically and laid out side-by-side with the original document for review. Fix anything that looks off, hit confirm, and it flows straight into inventory.
The handwriting recognition handles messy cursive, sparse entries, org-specific shorthand, and even circled annotations on inventory sheets. Items marked illegible get flagged with warnings instead of silently skipped. The original file is stored in Google Cloud Storage for audit trail.
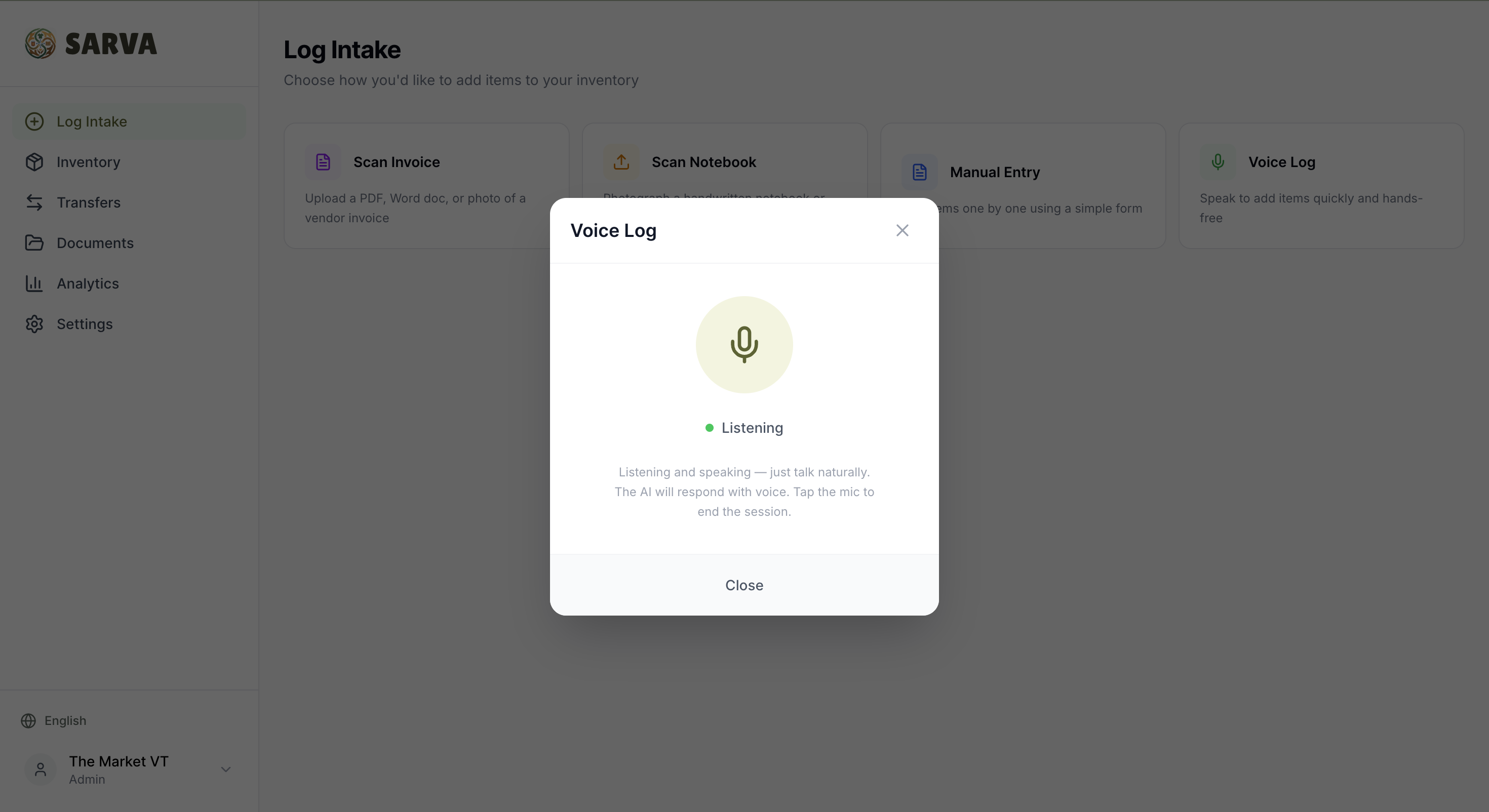
Voice Log — Hands-Free Inventory in 100+ Languages
51% of all food programs run entirely on volunteers — people who showed up to sort, pack, and serve, not to sit at a laptop entering data.
Voice Log lets anyone update inventory by speaking. In any language. In real time. A volunteer walks through intake and says what they're receiving — the AI listens, asks follow-up questions for missing details (quantity? category? which program?), checks for duplicates against existing inventory, and logs everything automatically. Completely hands-free, opt-in per organization, and designed for the reality of how pantries run — fast, physical, and driven by people who are there to serve.
This is where the global vision comes alive. A Spanish-speaking volunteer in Texas, a Swahili-speaking aid worker in Kenya, or a Mandarin-speaking student at VT can all log inventory by voice without switching languages or navigating a UI. The voice agent powered by Gemini Live understands context, asks clarifying questions naturally, and executes inventory operations through function calling — search duplicates, create items, update quantities, list inventory — all through conversation.
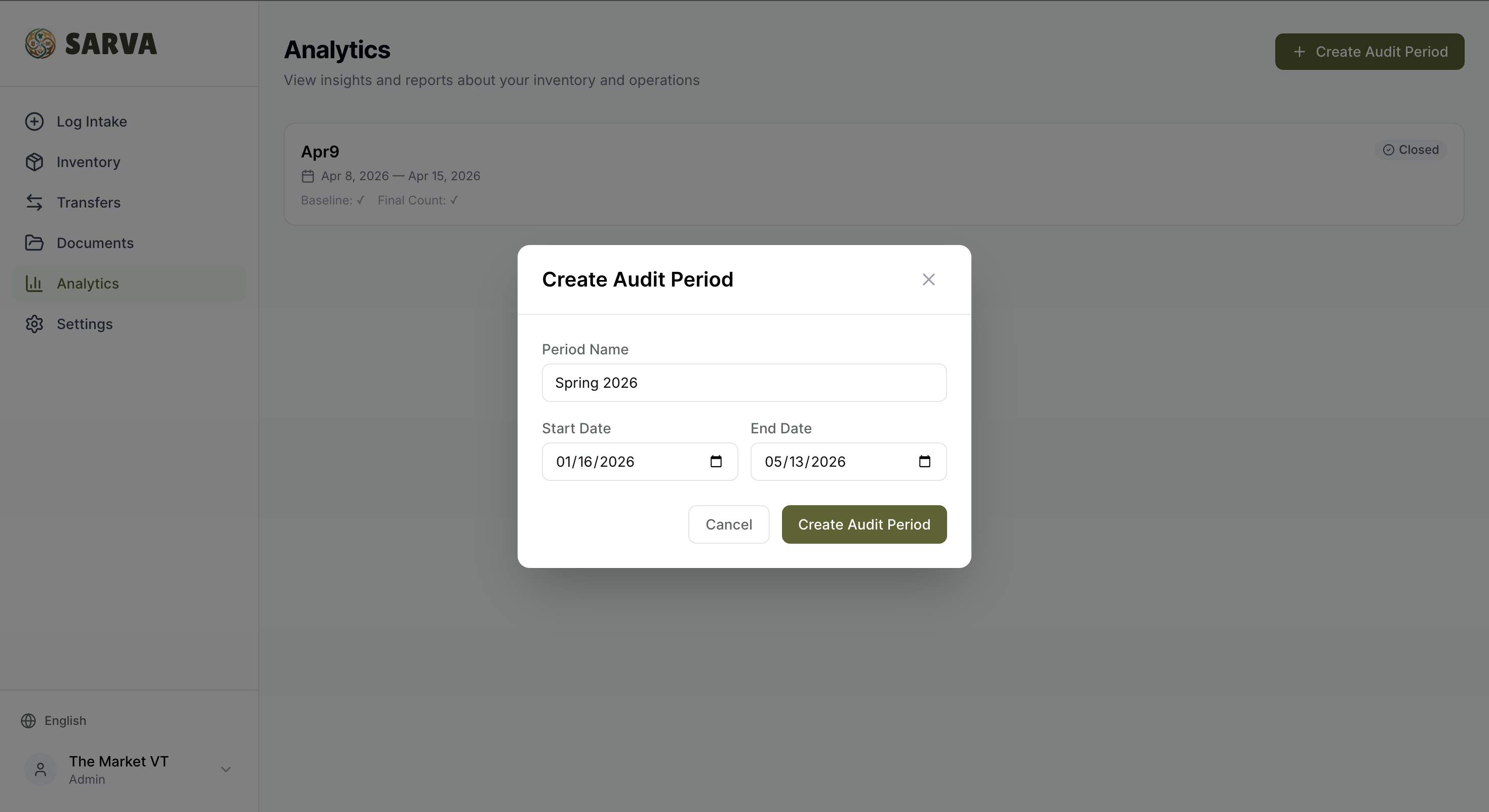
Smart Dashboard — Temporal Audit Math
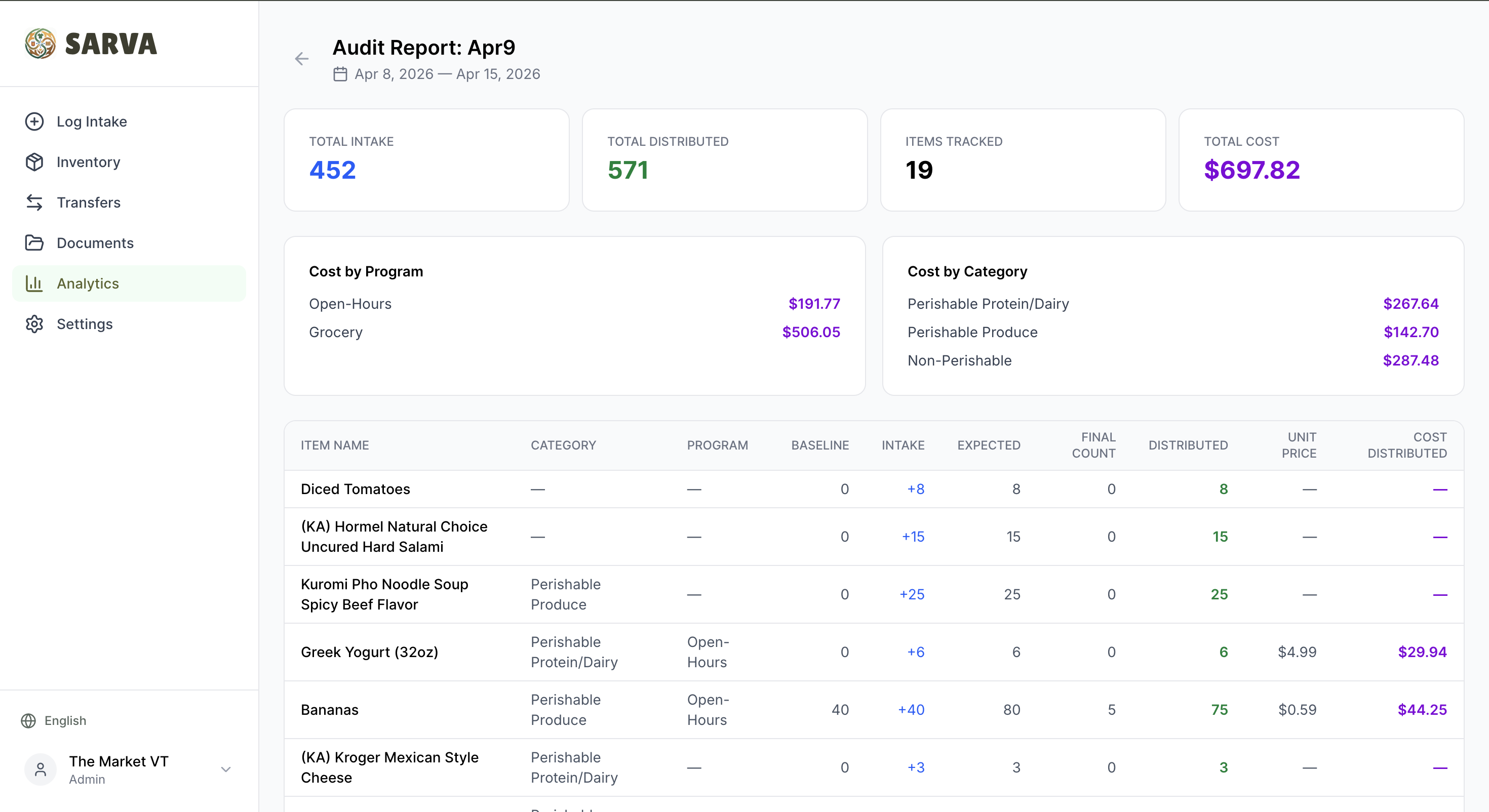
Most pantries can't track individual checkouts — and shouldn't have to. The Market at VT strictly forbids it to protect student anonymity. So we invented Temporal Audit Math:
Distributed = Baseline + Total Intake − Final Physical Count
Record what you start with at the beginning of a period. The system automatically tracks every item that comes in (from invoices, notebooks, voice, manual entry). At the end of the period, count what's left on the shelves. The system calculates exactly how much was distributed, broken down by program and category — perfect data for government and NGO grant reports, with zero privacy concerns.
Rollover is built in: the final counts from one period become the pre-filled baseline for the next.
Make It Your Own — Template Engine
There are over 1.8 million nonprofits in the US — every one of them running differently, using different names, different programs, different categories. A one-size-fits-all system works for none of them.
Every organization gets its own personal URL and a fully configurable platform from day one. Choose a template — University Pantry (pre-loaded with VT's 3 categories and 2 programs), Community Pantry, or Custom — and categories, program names, and terminology are pre-configured. The University Pantry template even includes AI context mappings (e.g., "Enrolled" → Grocery program) that get injected into every parsing prompt, so the AI understands your org's shorthand from the first upload.
Multilingual Interface — 100+ Languages
25.7 million people in the US have limited English proficiency — and they are among the most likely to need food pantries, clothing drives, and community nonprofits.
The entire platform auto-translates into 100+ languages using Google Cloud Translation API v3, with results cached in Firestore so it only ever translates once per language. Every button, label, category, and form — translated and ready. Placeholder variables like {{name}} are protected during translation using notranslate spans. A SHA-256 hash of the English source dictionary ensures stale translations are automatically refreshed when the UI text changes.
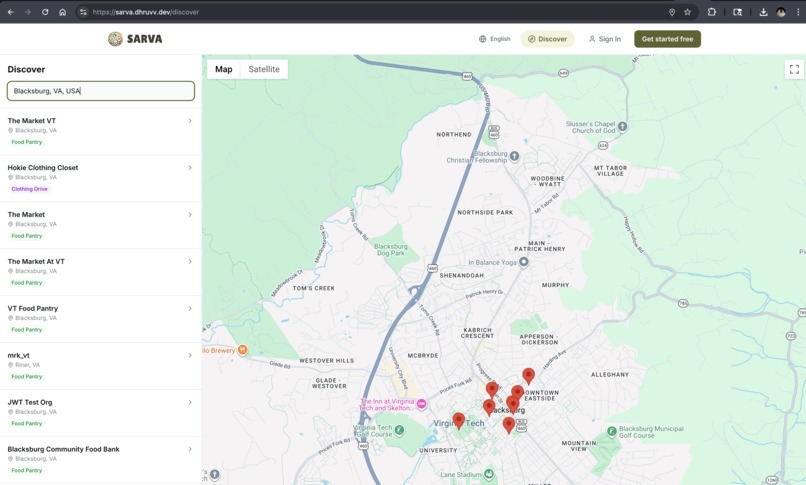
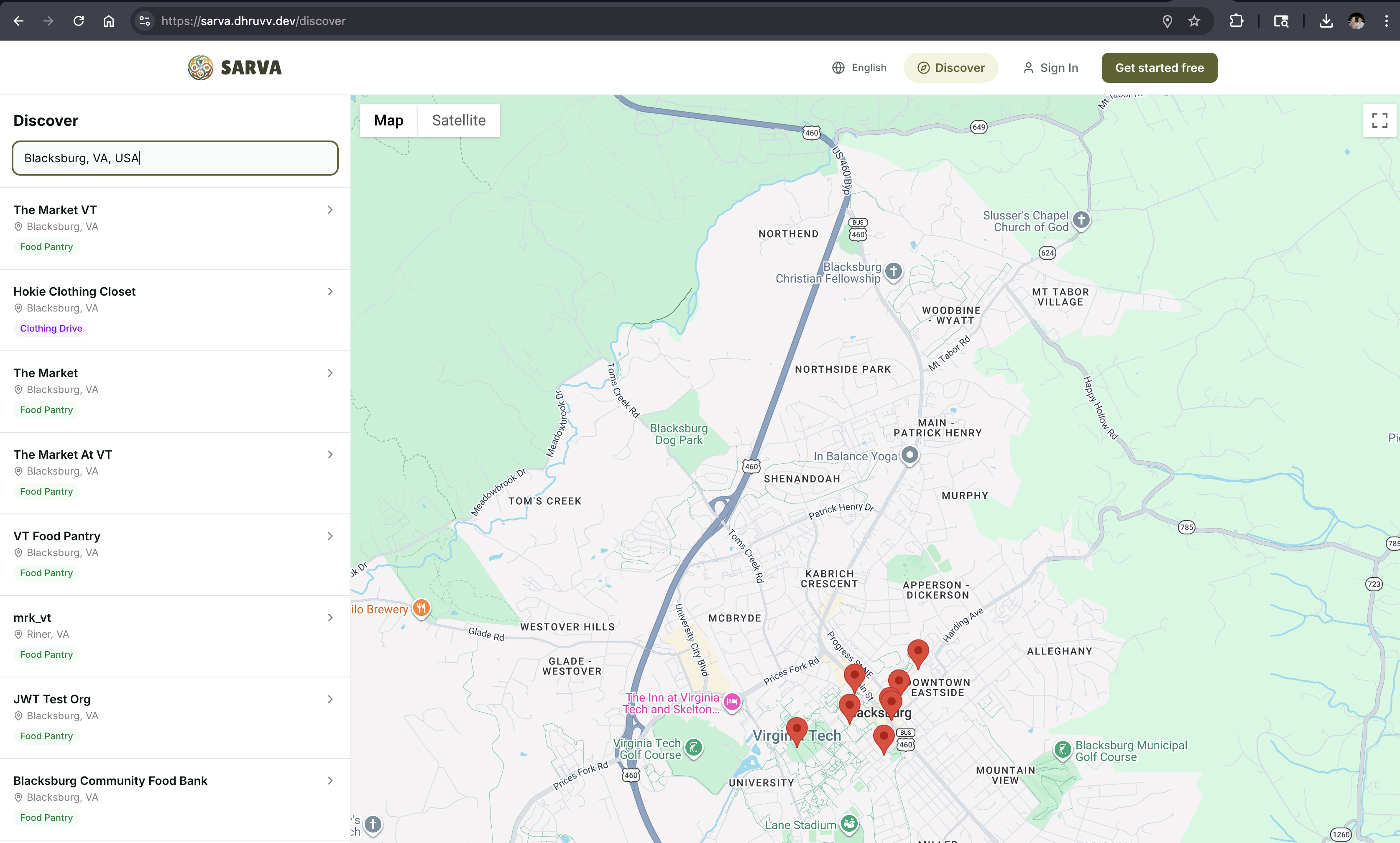
Local Network — Pantry Discovery
Nearly 50% of surplus food is currently sent to landfill — not because there's no one who needs it, but because no one nearby knew it was available. Feeding America alone runs a network of over 60,000 pantries — yet most smaller organizations have no way of knowing what's available two miles away.
Every organization on Sarva can opt in to become discoverable on a public map. Admins choose which inventory items are publicly visible, set their location via Google Places Autocomplete, and appear on the /discover page — a Google Maps-powered interface where anyone (no login required) can search by area and browse nearby pantries and their available items.
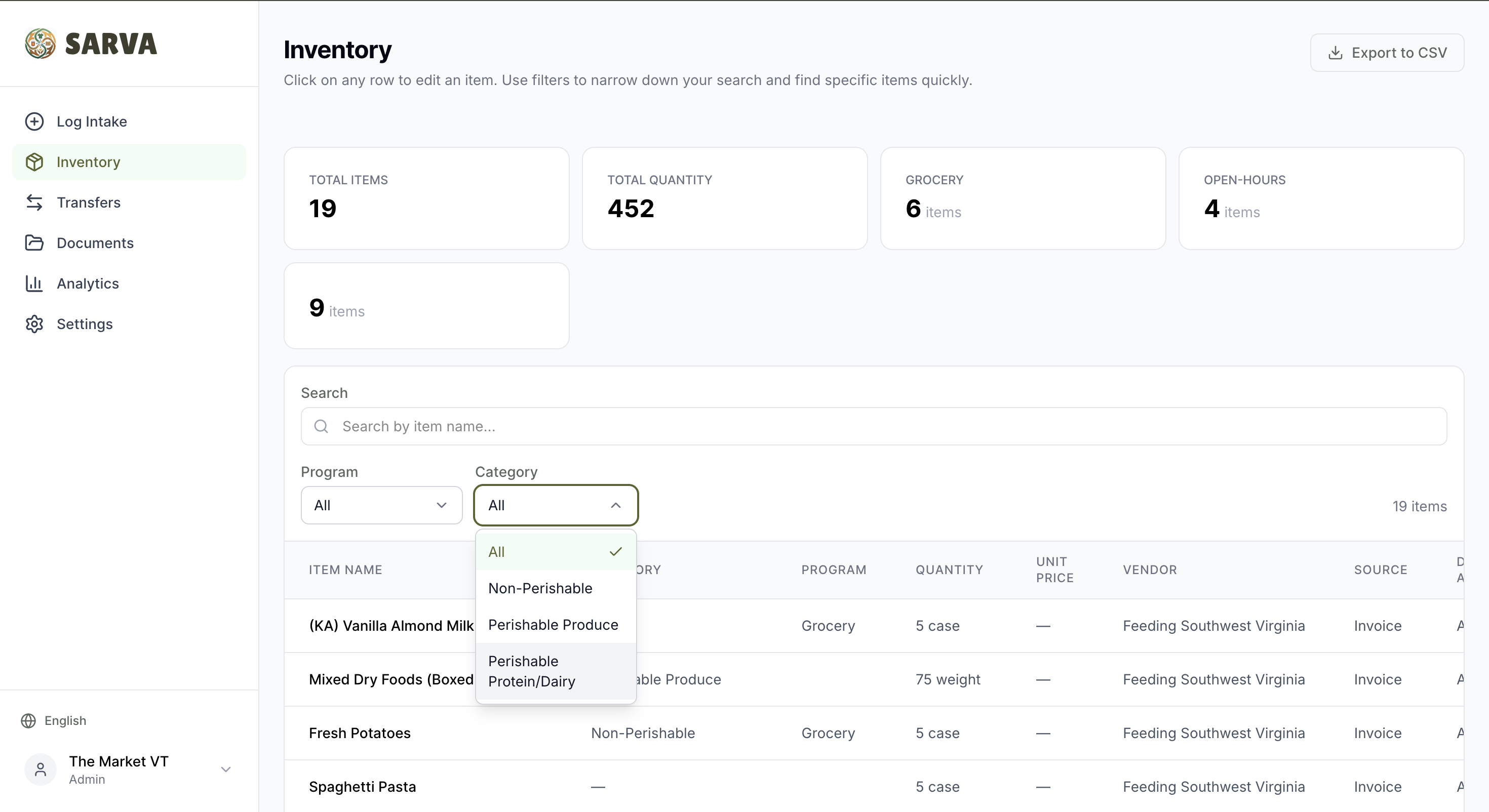
Smart Deduplication — AI-Powered Vector Search
Volunteers name things differently. "Fuji Apples" and "apples" and "instant oatmeal packs" and "oatmeal" shouldn't become four separate inventory items. This is a classic fuzzy matching problem, but traditional string matching (Levenshtein distance, trigrams) fails on semantic similarity — "canned corn" and "corn" are 50% different as strings but 100% the same item.
We solved this with AI vector embeddings. Every inventory item gets a 768-dimensional vector embedding generated by Vertex AI (text-embedding-005 or gemini-embedding-001). These embeddings capture semantic meaning, not just character overlap. The embedding is stored directly on the Firestore document as a name_embedding field, and Firestore's native find_nearest API runs sub-100ms cosine similarity KNN queries — no separate vector database needed.
The dedup system operates at two layers: (1) as the volunteer types, a local autocomplete shows existing items matching the substring (instant, no API call); (2) when the volunteer leaves the name field, a vector search fires and surfaces semantically similar items with match percentages and a merge option. If a match is found, the volunteer can merge into the existing item instead of creating a duplicate. Embeddings are generated automatically in the background via asyncio.create_task on every create and update — zero UX friction, zero blocking. Bulk imports stagger embedding requests 500ms apart to avoid rate limit spikes.
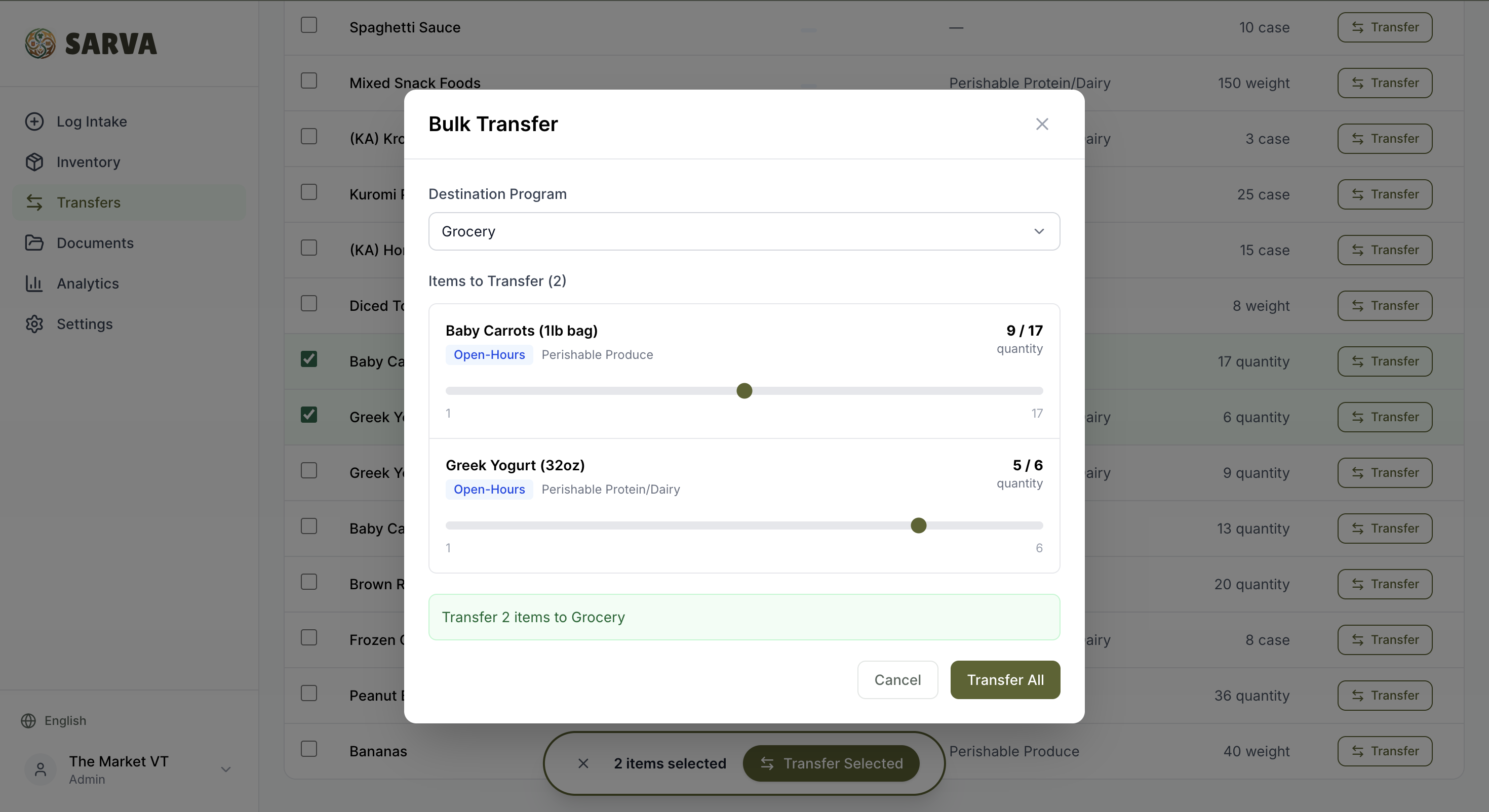
Quick Transfers
Items move constantly between programs. The Market at VT shifts stock between Grocery and Open-Hours based on immediate need. A slider UI lets admins select an item, pick source and destination programs, drag to set the quantity, and confirm — one gesture, instant update.
How We Built It
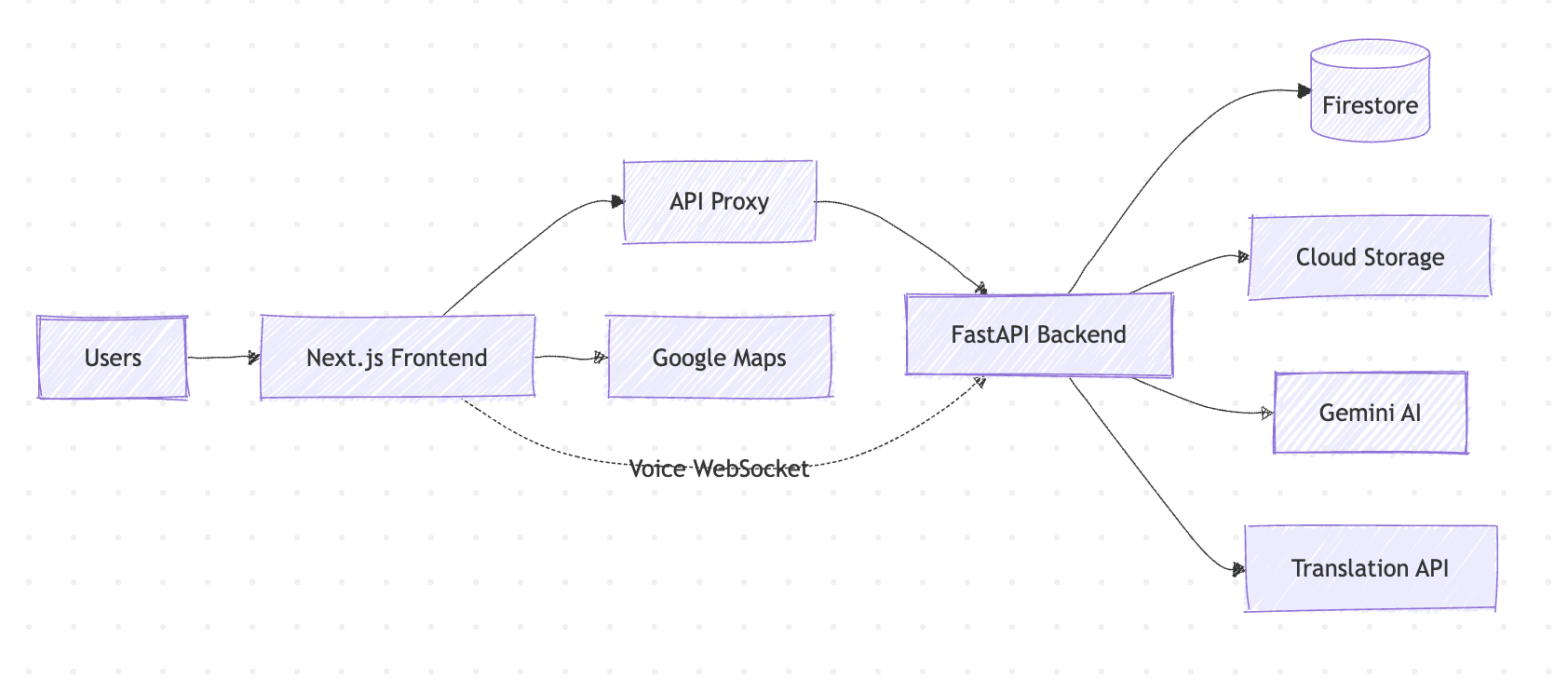
Architecture
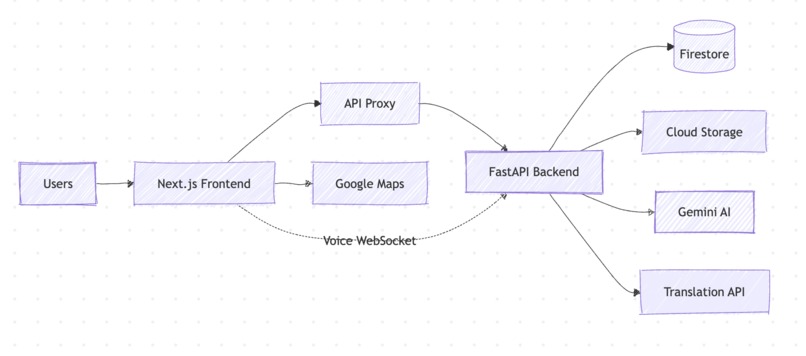
We built Sarva as two independently deployable services with a feature-based modular architecture designed for parallel development.
Backend: FastAPI + Python 3.13, deployed on Google Cloud Run with scale-to-zero. Each feature module (auth, intake, ledger, inventory, dashboard, voice, dedup, i18n, discovery, forecasting) is a self-contained package with its own router, schemas, service layer, and models — no cross-feature imports. Shared utilities (embeddings, database, security) live in app/core/ and app/common/.
Frontend: Next.js 16 + React 19 + Tailwind CSS 4, also deployed on Cloud Run with standalone output. The frontend never talks directly to the backend — all requests go through a Next.js API proxy that injects the API key server-side, keeping secrets out of the browser entirely. File uploads use a separate multipart proxy route.
Database: Google Cloud Firestore in Native mode, with multi-tenant isolation via org_id collection hierarchy. Every query is scoped by organization. Schemaless documents mean new features (like discovery fields) can be added to existing org documents without migrations.
Google Cloud Services — Deep Integration
We leaned heavily into the Google ecosystem. Every major capability runs on a Google service:
| Google Service | How We Use It |
|---|---|
| Cloud Firestore | Primary database — org metadata, inventory, invoices, ledger entries, audit periods, voice session logs, i18n translation cache, slug index. Multi-tenant via org_id partitioning. Native vector search for dedup (768-dim cosine KNN on name_embedding field). |
| Vertex AI — Gemini 3.1 Pro | Invoice parsing (PDF/Word/image → structured JSON with line items, vendor info, confidence scores) and handwriting recognition (notebook photos → digitized entries with illegibility detection). We tried Gemini 2.5 Flash first — it was insufficient for parsing quality. Gemini 3.1 Pro with carefully engineered 50+ line prompts achieves ~95% accuracy. |
| Vertex AI — Gemini Live API (3.1 Flash) | Real-time bidirectional audio streaming for the voice agent. WebSocket relay architecture: client audio (16kHz PCM) → backend → Gemini Live session, with Gemini audio streamed back. Native function calling dispatches to inventory/dedup services with 10-second execution timeouts. |
| Vertex AI — text-embedding-005 | 768-dimensional vector embeddings for fuzzy deduplication. Dual-path: Google AI API key approach with gemini-embedding-001 (higher rate limits) or Vertex AI service account with text-embedding-005. Both produce compatible 768-dim vectors. |
| Firestore Vector Search | Native find_nearest KNN queries on embedding vectors — sub-100ms cosine similarity search without a separate vector database. |
| Cloud Translation API v3 | Auto-translates the entire UI dictionary (~395 keys) into 100+ languages. Placeholder protection via notranslate HTML spans. Results cached in Firestore with source hash invalidation. Hard cap of 60 cached languages for cost protection. |
| Google Maps JavaScript API | Map display with AdvancedMarker and InfoWindow components on the public discovery page. |
| Google Maps Places API | Address autocomplete on the discovery page and admin settings — type an address, pick from suggestions, auto-fills coordinates for map placement. |
| Cloud Storage (GCS) | Raw file storage for invoices and notebook photos (audit trail) under invoices/{org_id}/raw/ and ledger_entries/{org_id}/raw/. Signed URLs generated via IAM signBlob API on Cloud Run (no local key files needed). Separate public bucket (sarva-public) for landing page demo videos. |
| Cloud Run | Serverless container hosting for both backend and frontend. Scale-to-zero billing. 400-second request timeout for long AI parsing operations. Secrets injected at runtime from Secret Manager. |
| Cloud Build | Docker image builds triggered by GitHub Actions on push to main. |
| Artifact Registry | Docker image storage for both services. |
| Secret Manager | Stores SECRET_KEY (JWT signing), API_KEY (global middleware), and GOOGLE_MAPS_API_KEY. Referenced by Cloud Run service configs and CI/CD pipelines. |
| Workload Identity Federation | Keyless GitHub Actions → GCP authentication via OIDC tokens. No service account keys stored in GitHub. Scoped to the repository only. |
| IAM signBlob API | GCS signed URL generation on Cloud Run without local key files — uses the metadata server credentials with iam.serviceAccountTokenCreator role. |
| Google Search Console | Domain ownership verification for Cloud Run custom domain mapping. |
We also used Gemini extensively as a deep research tool throughout development — investigating Firestore vector search capabilities, debugging the google-genai SDK's evolving API surface (the Blob requirement change in v1.70+, the receive() single-turn behavior), understanding Cloud Run's IAM signBlob flow for signed URLs, and researching the Gemini Live API's function calling architecture. Gemini served as both a building block inside the product and a research accelerator for the team building it.
Security & Access Control (RBAC)
- Role-Based Access Control (RBAC): Every user is either an Admin or a Volunteer, determined at login by which PIN they enter. Admins have full access — settings, audit periods, discovery configuration, org management. Volunteers can log intake, view inventory, and make transfers, but cannot modify org settings or run audits. This is enforced at the API level via FastAPI dependency injection (
require_admin), not just hidden in the UI. Every protected endpoint checks the JWT role claim before executing. - JWT Authentication: HS256-signed tokens with 24-hour expiration, embedding
org_idandrole. Every authenticated endpoint validates the token via FastAPI dependency injection. - API Key Middleware: Custom ASGI middleware enforcing
X-API-Keyon all HTTP requests (except health/docs). WebSocket connections bypass this layer and use their own JWT auth via query parameter. - Multi-Tenant Isolation: Every Firestore query scoped by
org_id. No org can access another org's data — enforced at the database query level, not just the application layer. - Workload Identity Federation: GitHub Actions authenticates to GCP via OIDC — zero stored credentials.
- Server-Side API Proxy: The frontend's Next.js proxy injects the API key server-side, keeping it out of the browser entirely.
CI/CD Pipeline
Push to main triggers GitHub Actions → Cloud Build → Cloud Run, separately for backend and frontend. The frontend pipeline fetches GOOGLE_MAPS_API_KEY from Secret Manager and passes it as a Docker build arg (since Next.js inlines NEXT_PUBLIC_* variables at build time, not runtime).
Testing
- Backend: 51 tests across 8 files using pytest + pytest-asyncio + httpx AsyncClient. Covers health endpoints, JWT security, template engine, Pydantic schema validation across all features (auth, inventory, dashboard, dedup, i18n, intake), config, embedding utilities, Firestore model helpers, and auth service helpers.
- Frontend: 15 tests across 2 files using Vitest v2. Covers API client functions (proxy routing, auth token injection, error handling, 204 No Content), and runtime API entity contract shape validation.
Challenges We Ran Into
1. Handwriting quality. Initial OCR approaches failed on messy notebook pages with sparse, illegible entries and org-specific shorthand. Solution: Gemini 3.1 Pro with a prompt specifically tuned for handwriting — it marks [illegible] items with warnings instead of skipping them, infers categories from item names, cleans obvious misspellings, and detects "circle program switch" patterns common on physical inventory sheets (where a circled arrow like "Open → Enrolled" sets the destination program for all items on the page).
2. Invoice format chaos. Vendors send PDFs, Word docs, scanned images, multi-page tables with misaligned columns. Solution: A 50+ line extraction prompt with specific rules for verbatim pack size extraction (no reinterpretation), MM/DD/YY → YYYY-MM-DD date parsing, row-by-row vendor item code alignment to prevent misalignment across table sections, symbol/annotation legend detection, and brand/temperature zone extraction into dedicated fields. The difference between a naive "extract this invoice" prompt and our engineered prompt is the difference between 60% and 95% accuracy.
3. Deduplication without blocking UX. Embedding generation takes 50–100ms per item. Solution: Background asyncio.create_task calls so API responses aren't blocked. Bulk imports stagger embedding requests 500ms apart to avoid rate limit spikes. Firestore's native vector index enables sub-100ms similarity search. The entire dedup system degrades gracefully — if the vector index is missing or any error occurs, the app returns empty matches instead of crashing.
4. Voice agent session management. WebSocket lifecycle + Gemini Live bidirectional audio relay + tool call dispatch is a complex concurrency problem. We hit multiple issues:
- The
google-genaiSDK'sreceive()method only yields messages for a single model turn — it breaks onturn_complete. Without wrapping it in awhile Trueloop, the conversation died after the first exchange. - The SDK changed its
audioparameter from raw bytes to requiringBlobobjects in v1.70+, causing silent validation errors. - Starlette's HTTP middleware can't handle WebSocket upgrade requests — it returns 403 when it tries to send an HTTP response on a WebSocket connection. We rewrote the API key middleware as a raw ASGI class that checks
scope["type"]and passes WebSocket connections through untouched. - Frontend audio playback used a timing heuristic to detect when Gemini stopped speaking, which misfired during tool-call gaps. We replaced it with a reference counter that tracks active audio sources.
5. Multi-tenant data isolation. Ensuring org A can't access org B's data. Every Firestore query is scoped by org_id. JWT tokens embed the org_id and role. Admin-only endpoints verify role via FastAPI dependency injection. The slug-based login system uses a separate org_slugs collection as a lookup index.
6. Cloud Run signed URLs. GCS signed URL generation requires a private key to sign. On Cloud Run, auth comes from the metadata server (Workload Identity), not a key file. Locally it worked fine; deployed, every document showed "Original file not available." Solution: detect when no local key file exists and fall back to the IAM signBlob API, passing service_account_email and access_token from google.auth.default() credentials. The refresh-first order is critical because compute engine credentials start with token=None until refresh() is called.
Accomplishments We're Proud Of
Zero training required. Non-technical volunteers can use it immediately. The AI handles the complexity — parsing invoices, reading handwriting, understanding voice commands, deduplicating items — while the volunteer just confirms what looks right. In a sector where 51% of programs run entirely on volunteers and turnover is constant, a system that requires training is a system that fails.
Built for the world, not just one campus. VT's specific constraints (3 categories, 2 programs, no barcodes, no checkout tracking) are abstracted into templates. The same platform works for a clothing drive in Mumbai, a school supply program in São Paulo, or a hygiene kit distribution center in Berlin — any nonprofit that moves physical inventory. The template engine, configurable categories/programs, org-specific AI context mappings, 100+ language support, and multilingual voice agent mean Sarva works for organizations across 46 countries where food banks already operate and beyond. The Market at VT was our first user — but the architecture was global from day one.
Real-time voice in 100+ languages. A Spanish-speaking volunteer can log inventory hands-free while carrying boxes. A Pashto-speaking aid worker can update stock without touching a screen. The Gemini Live function calling pipeline — WebSocket relay, bidirectional audio, tool dispatch with 10-second timeouts, session audit logging — is production-grade. In a world where language is one of the most significant barriers to humanitarian aid, a voice agent that works in any language isn't a nice-to-have — it's the difference between inclusion and exclusion.
Audit math without checkout tracking. We solved the student anonymity constraint with period-based distribution calculation. No privacy violations, no checkout logging, and the numbers are exactly what grant applications need. This approach works for any organization that can't or shouldn't track individual recipients — which is most of them.
Structured approach to problem-solving. We didn't guess what The Market at VT needed. We prepared 13 stakeholder questions across three priority tiers, conducted a full meeting with Isabelle Largen and her team, and let every answer drive a design decision. The clarified PRD (v2) documents every constraint and how we addressed it. Every feature traces back to a real operational pain point — not a hypothetical one.
Production-deployed on Google Cloud. Both services running on Cloud Run with Secret Manager, IAM, Workload Identity Federation, RBAC (admin/volunteer roles enforced at the API level), scale-to-zero billing, CI/CD auto-deploy on push to main, and a 400-second request timeout for long AI operations. Custom domain mapped via Cloud Run Domain Mapping. This isn't a prototype — it's deployed, tested (66 tests across backend and frontend), and serving real organizations.
What We Learned
Prompt engineering is the difference between a demo and a product. The gap between "extract this invoice" and a 50-line prompt with rules for date parsing, column alignment, symbol detection, and org-specific terminology injection is the gap between 60% and 95% accuracy. We iterated on prompts more than on code.
Firestore native vector search is production-ready. Sub-100ms KNN queries on 768-dimensional embeddings without spinning up a separate vector database. The find_nearest API with cosine distance just works — and it's free within Firestore's existing pricing.
Gemini Live function calling works for real-time voice agents. Bidirectional audio streaming + tool dispatch is viable for production voice interfaces. The key insight: the SDK's receive() only covers one model turn, so you need an outer loop to keep the conversation alive across multiple exchanges.
Multi-tenancy is easier to architect from day one than retrofit. Every collection path, every query, every JWT claim includes org_id. We never had to go back and add tenant isolation — it was there from the first line of code.
Stakeholder meetings change everything. Our original PRD had assumptions about checkout tracking, expiration dates, and category granularity that were all wrong. The meeting with Isabelle's team saved us from building features nobody wanted and pointed us toward problems we hadn't considered (like the "circle program switch" pattern on notebook pages).
Gemini is a research tool, not just a product feature. We used Gemini throughout development for deep research — understanding Firestore's vector search internals, debugging SDK breaking changes, investigating Cloud Run IAM flows, and exploring the Gemini Live API's undocumented behaviors. It accelerated our development velocity as much as it powers the product itself.
The global problem is bigger than any single pantry. 295 million people faced acute hunger in 2024. The organizations fighting this are drowning in paperwork. Building for VT taught us the constraints; building for the world taught us that those constraints are universal. Every pantry we talked to — regardless of size, location, or type — had the same core problems: manual data entry, volunteer turnover, language barriers, and no way to see what's happening nearby. Sarva addresses all of them.
What's Next for Sarva
- ML Forecasting: Vertex AI AutoML to predict when categories will deplete based on historical audit velocity — alert admins to stock up before finals week.
- Broadcast Network: One-tap surplus alerts to nearby pantries when items are approaching expiry. One pantry's overflow becomes another family's dinner.
- Granular IAM: Individual user accounts instead of shared PINs, with role-based permissions.
- Export & Impact Reports: Calculate the economic value of food saved from landfills, volunteer hours recovered, and items distributed — formatted for grant applications.
- Data Sovereignty: Automated bi-weekly CSV exports to Google Drive, plus a one-click "Export All Data" button. The entire GCP project (IAM, billing, services) can be transferred to Virginia Tech's IT department upon graduation.
Built With
- FastAPI
- Python 3.13
- Next.js 16
- React 19
- Tailwind CSS 4
- Google Cloud Firestore
- Google Cloud Run
- Google Cloud Build
- Google Artifact Registry
- Google Secret Manager
- Google Vertex AI (Gemini 3.1 Pro)
- Google Gemini Live API (3.1 Flash)
- Google Vertex AI text-embedding-005
- Google Firestore Vector Search
- Google Cloud Translation API v3
- Google Cloud Storage
- Google Maps JavaScript API
- Google Maps Places API
- Google Workload Identity Federation
- Google Search Console
- GitHub Actions
- Vitest
- pytest
Built With
- fastapi
- firestore
- gemini
- github
- pydantic
- python
- react
- tailwind
- typescript
- vertex-ai

Log in or sign up for Devpost to join the conversation.