-
output_2
-
output_3
-
output_1
🇮🇳 Sarkari Saathi Empowering citizens through AI-driven government scheme discovery.
💡 Inspiration India has over 3,400 life-changing government schemes, but they are often buried in complex PDFs or English-only portals. We wanted to build a "Government Friend" that explains these benefits to any citizen in their own language, removing the technical and linguistic barriers to entry.
⚙️ How we built it We followed a professional Data Engineering and AI lifecycle natively on Databricks:
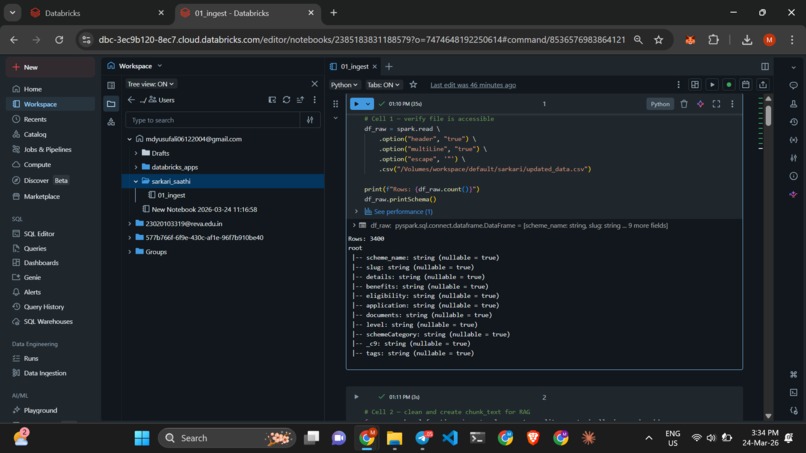
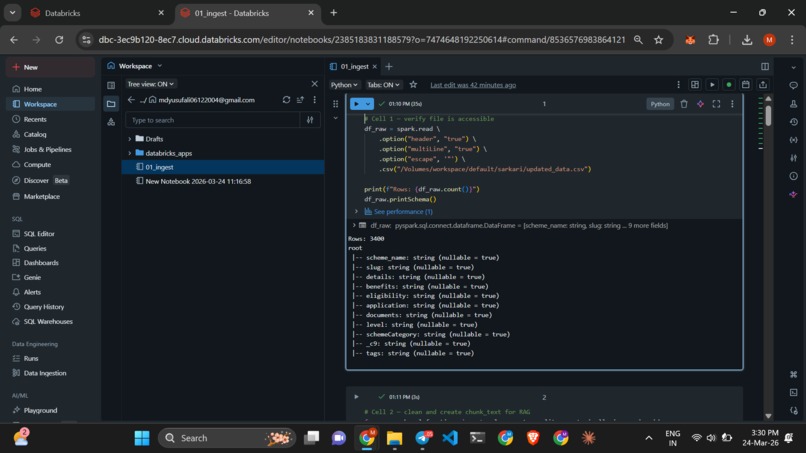
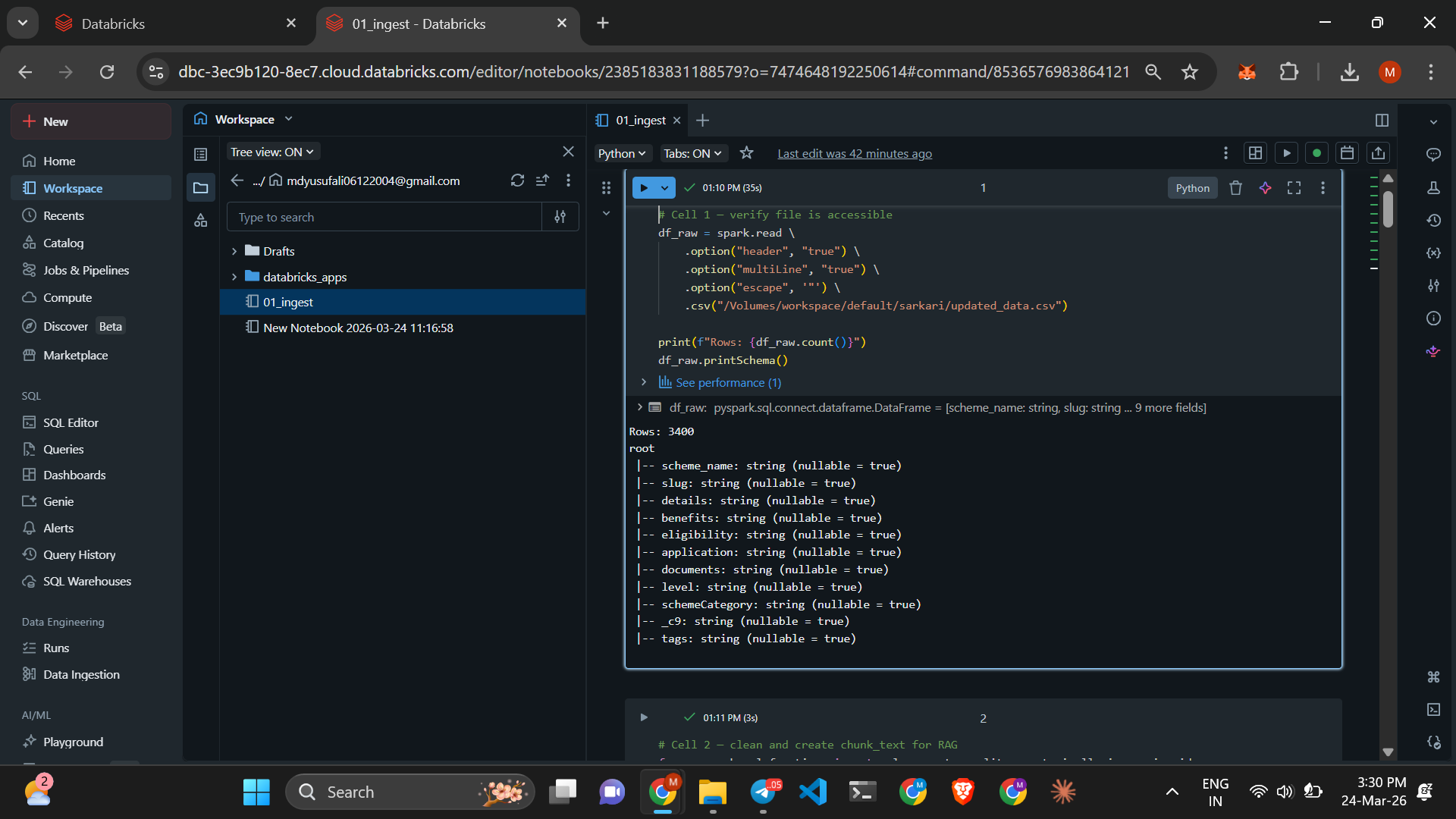
Data Lakehouse: Raw scheme data was ingested into the Databricks environment and cleaned using PySpark. We stored this "Golden Source" in a Delta Lake table for ACID compliance.
AI Embeddings: We utilized the paraphrase-multilingual-MiniLM-L12-v2 open-source model to generate 384-dimensional vector embeddings. This allows the app to understand the meaning of a query across English and regional Indic languages.
Vector Search: We indexed these embeddings using FAISS and stored the index in a Databricks Volume (Unity Catalog) for high-speed retrieval.
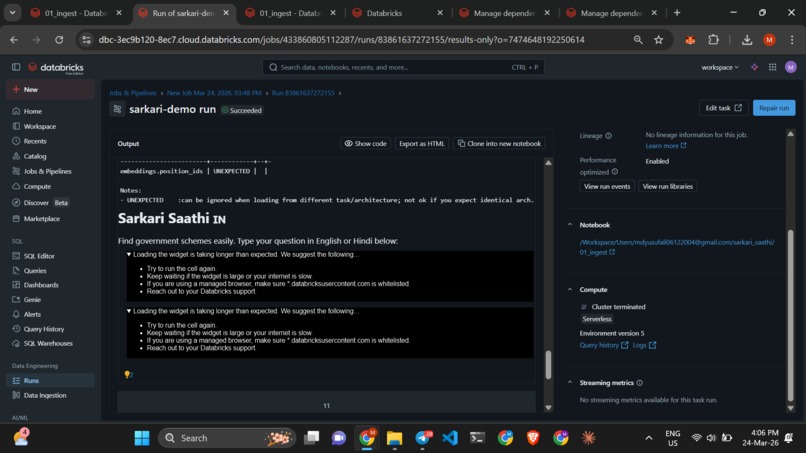
RAG Pipeline: When a user asks a question, the system embeds the query, finds the top relevant schemes via FAISS, and retrieves the verified data from our Delta table.
🚧 Challenges we faced Navigating network firewalls to ensure the AI models loaded correctly and managing 3,400+ schemes with varied formatting were our biggest hurdles. We overcame this by creating a context-rich "Unified Chunk" for each scheme, combining name, eligibility, and benefits.
🎓 What we learned We mastered the use of Databricks Volumes for persisting ML artifacts and saw firsthand how Delta Lake serves as the perfect foundation for reliable RAG (Retrieval-Augmented Generation) pipelines.
Built With
- databricks
- delta-lake
- faiss
- hugging
- pyspark
- python
- sentence-transformers
- unity-catalog

Log in or sign up for Devpost to join the conversation.