-
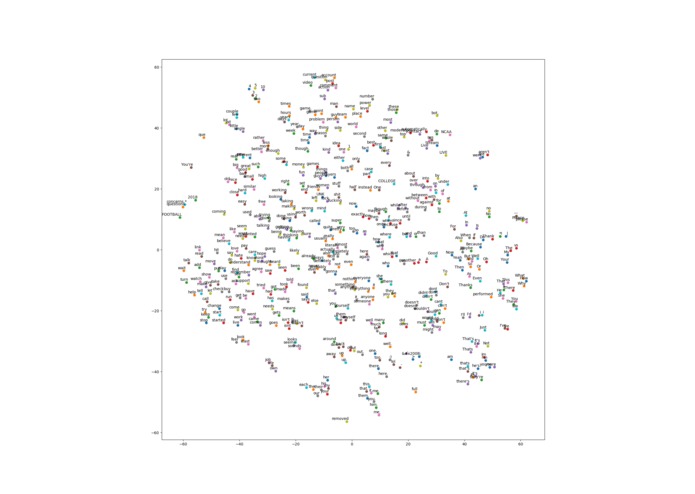
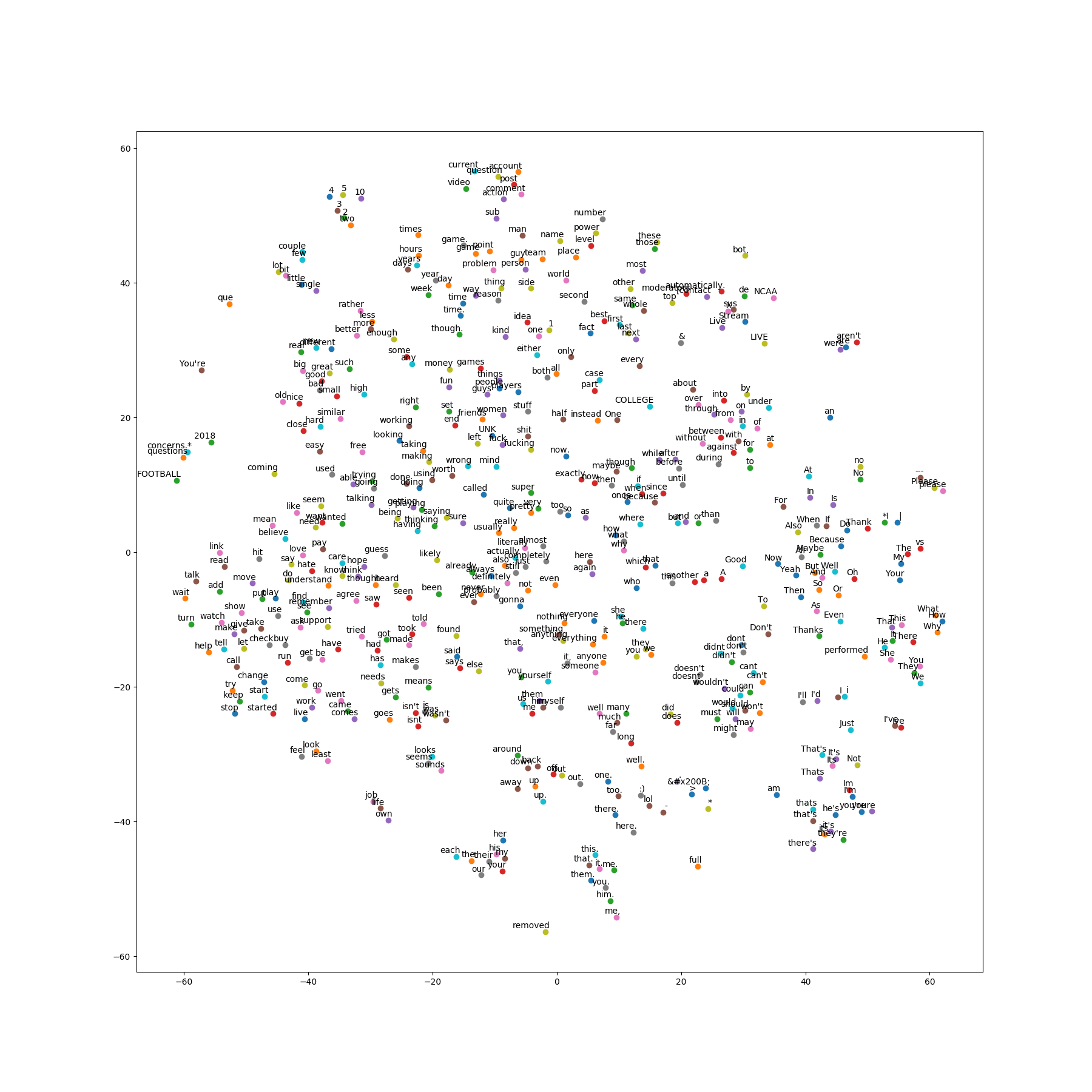
TSNE graph (grouped by use-context)
-
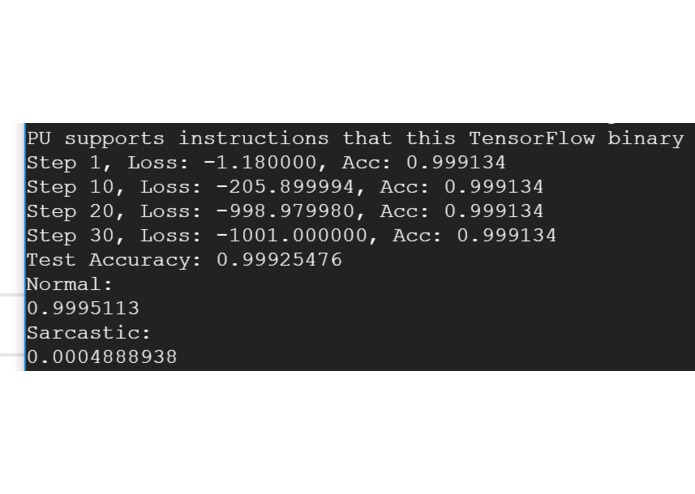
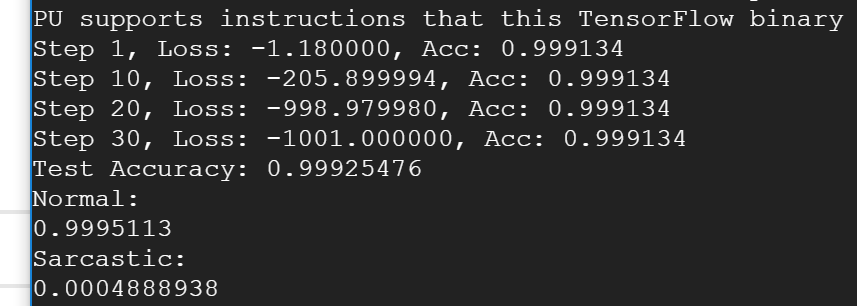
Sample output from the ML! It decided that this one wasn't sarcastic (with 99.9% certainty)
Inspiration
There's a common saying on the internet that it's nearly impossible to determine sarcasm using just text. To remedy this, most people write '/s' to denote sarcasm. We decided to test just how difficult it is to determine if someone is sarcastic or not.
What it does
First, our reddit bot scrapes all incoming comments and sorts them into two files: sarcasm.txt and no_sarcasm.txt based on whether or not the comment contains '\s'. After doing a bit of machine learning, it will, given a string input, try to determine whether or not the person is being sarcastic.
How we built it
We used the reddit api and python to scrape comments as they came in and sort them. Then, all the comments were slightly sanitized and all the words put into a context-based tsne graph using a neural network. This allows similar points to represent similar words; ideas are clustered together. We then used random forests to represent the paths taken; this works on the assumption that sarcastic sentences take different paths than non-sarcastic sentences
Challenges we ran into
Getting a good data set and training in such a short amount of time is extremely difficult. After running the bot overnight, we only got ~1000 sarcastic comments-- nowhere near enough to fully train out bot.
Accomplishments that we're proud of
Even though the bot doesn't work too well, all of the framework is there. Given more time, we would be able to get better results.
What we learned
We all learned a lot about python, tensorflow, and using google cloud. Even though the bot doesn't work as well as we want, we're still excited about how much we've learned in such a short amount of time.
What's next for SarcasticBot
Ideally we'd keep expanding our data set and throwing more compute power (and possibly more/better regression methods) to get a better result. We're also working on a naive version to compare the ML to that.
Built With
- google-cloud
- python
- tensorflow
Log in or sign up for Devpost to join the conversation.