
The problem Saransh solves Exactly a year ago we faced the largest crisis of the 21st century. - The COVID-19 pandemic. Amidst the chaos, the generation eventually found a way to get the job done by introducing automation in every other aspect of life. After the hit of the pandemic, we have encountered a rise of 87% in video conferencing tools for daily communications. The communications ranging from online meetups, college lectures, business meets, almost everything got hosted over to the internet, which being virtual, encroached the chances of unfruitful communications. In fact, the data collected from employees of all domains, show that people often miss important points because they find taking minutes of those meetings a time-consuming, distracting, and really boring task and over 37 billion dollars is wasted over these unproductive meetings.
Solution💡:
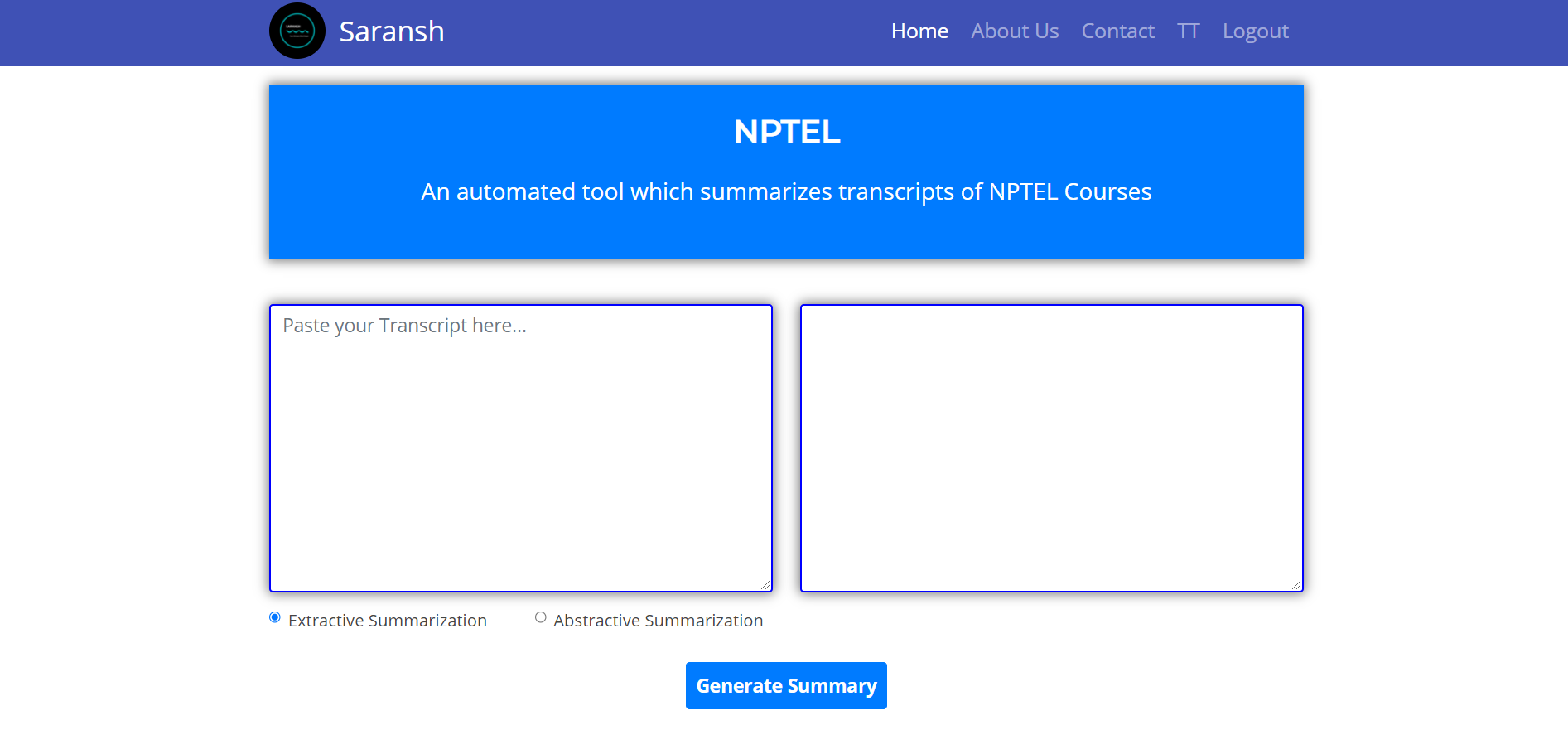
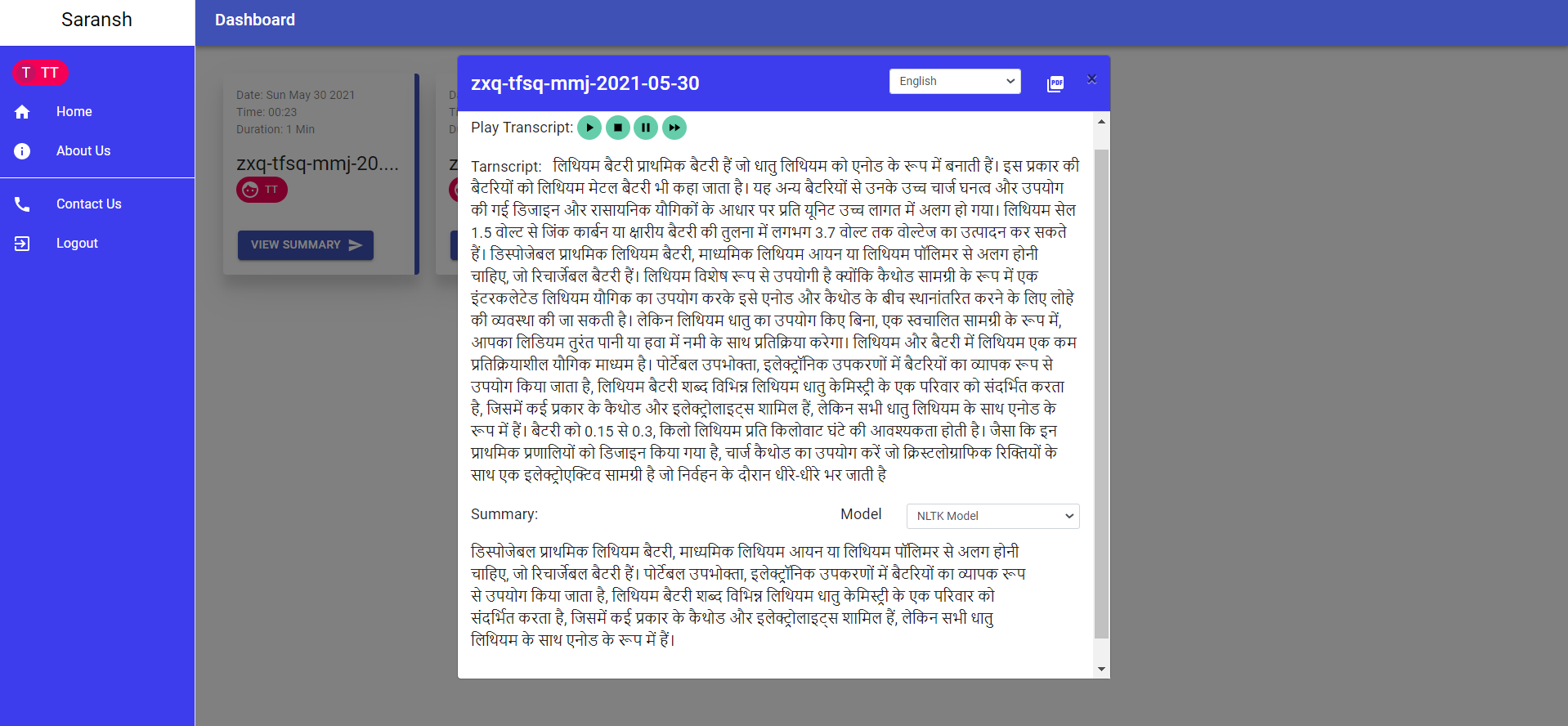
So we have decided to automate the tasks of making minutes of online meetings to save time and resources. We have also processed the summarized text into multilingual audio which can be heard in the user's native language, thus giving him a better understanding of the topic and breaking the language barrier.
Also, this feature can be a golden halcyon for those who are visually impaired as they can hear the summarized text in their desired languages.
Control Flow :
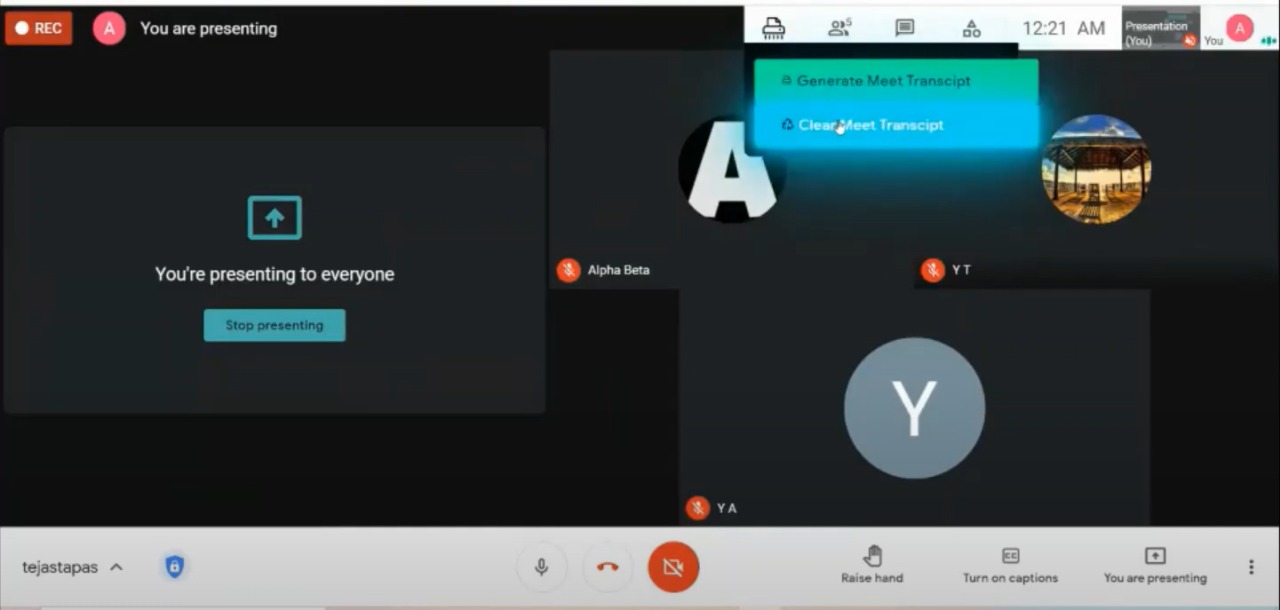
- The user logs on to his SARANSH account and enables the chrome extension.
- The chrome extension extracts the audio from the meet concerning every speaker and transcribes it via chrome extension.
- This extracted transcript is further sent to the backend where hardcore Machine Learning techniques are applied for the text summarization.
- This ultra-processed text is then directed towards the translator to elucidate the extract into the user's desire
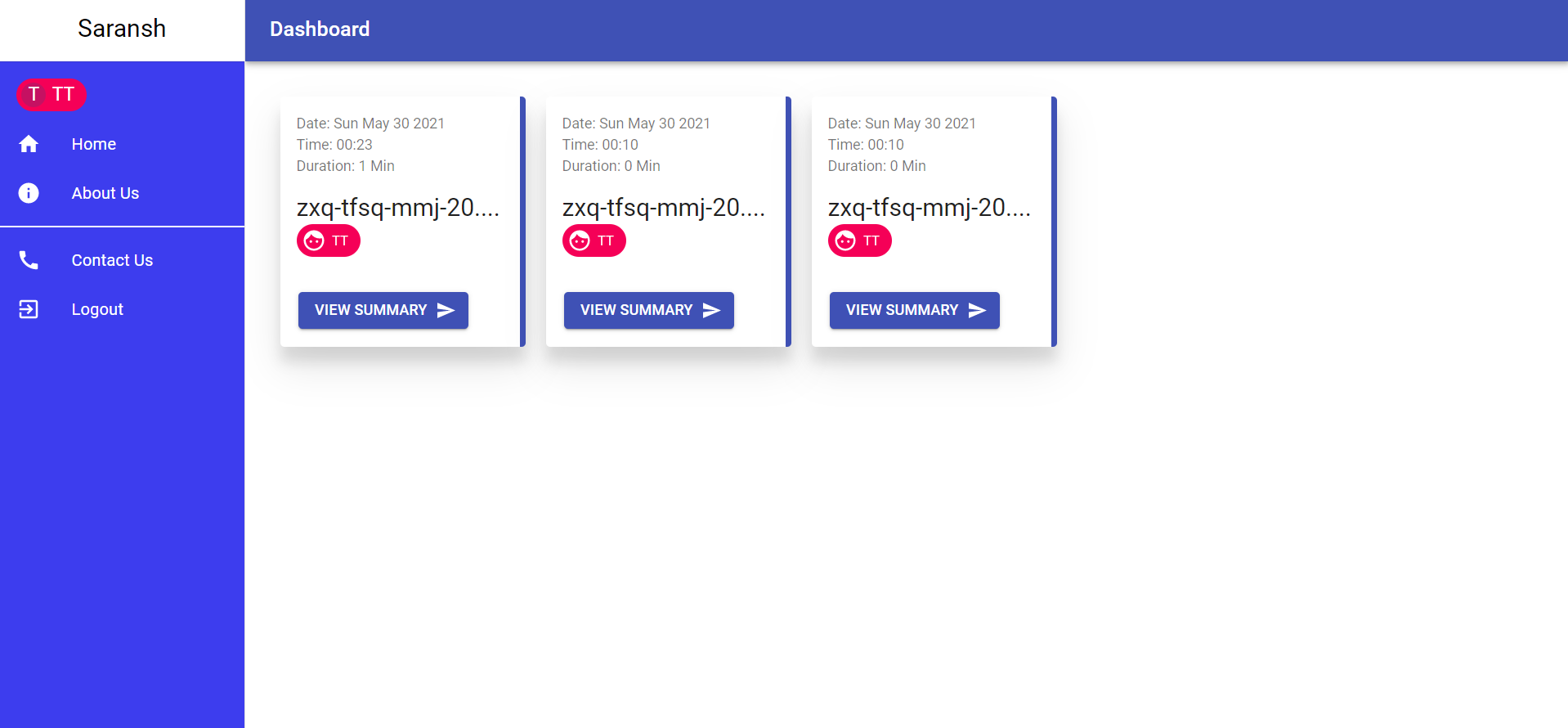
- This transcript can then be downloaded or even heard on the dashboard according to the user's wish.
So this is how TEAM SARANSH contributed to the pandemic-driven automation.
Challenges I ran into 1) Extracting Transcripts from Google Meet We extracted text from the captions provided by the google meet platform but this was a tedious task as we were not through with the Chrome extension part and had to completely understand the DOM structure of the Google meet platform.
2) Selection of NLP models for Summarization Though there are many NLP models for the task of text summarization we had to select the most appropriate and efficient model. We analyzed each model using ROUGE analysis and found NLTK and T5 models appropriate for extractive and abstractive summarization respectively.

Log in or sign up for Devpost to join the conversation.