-
-

Midjourney generated logo
-
Sarah Home page
-

Sarah generates new research paper
-
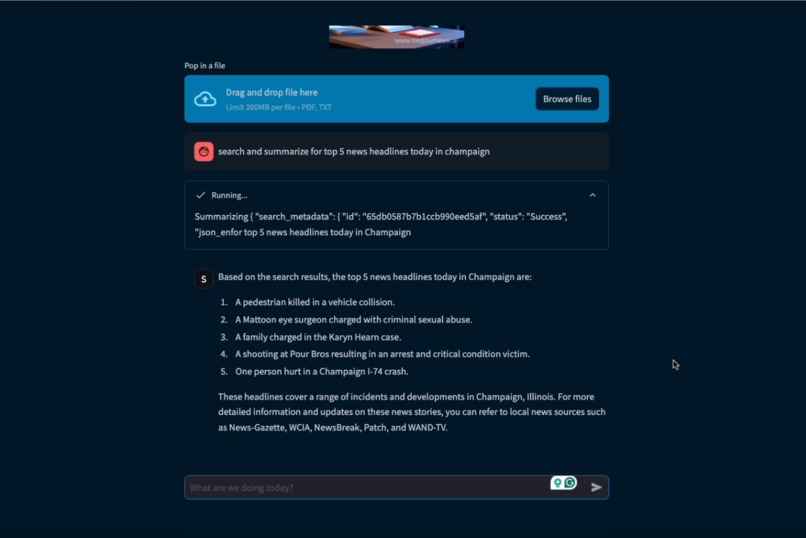
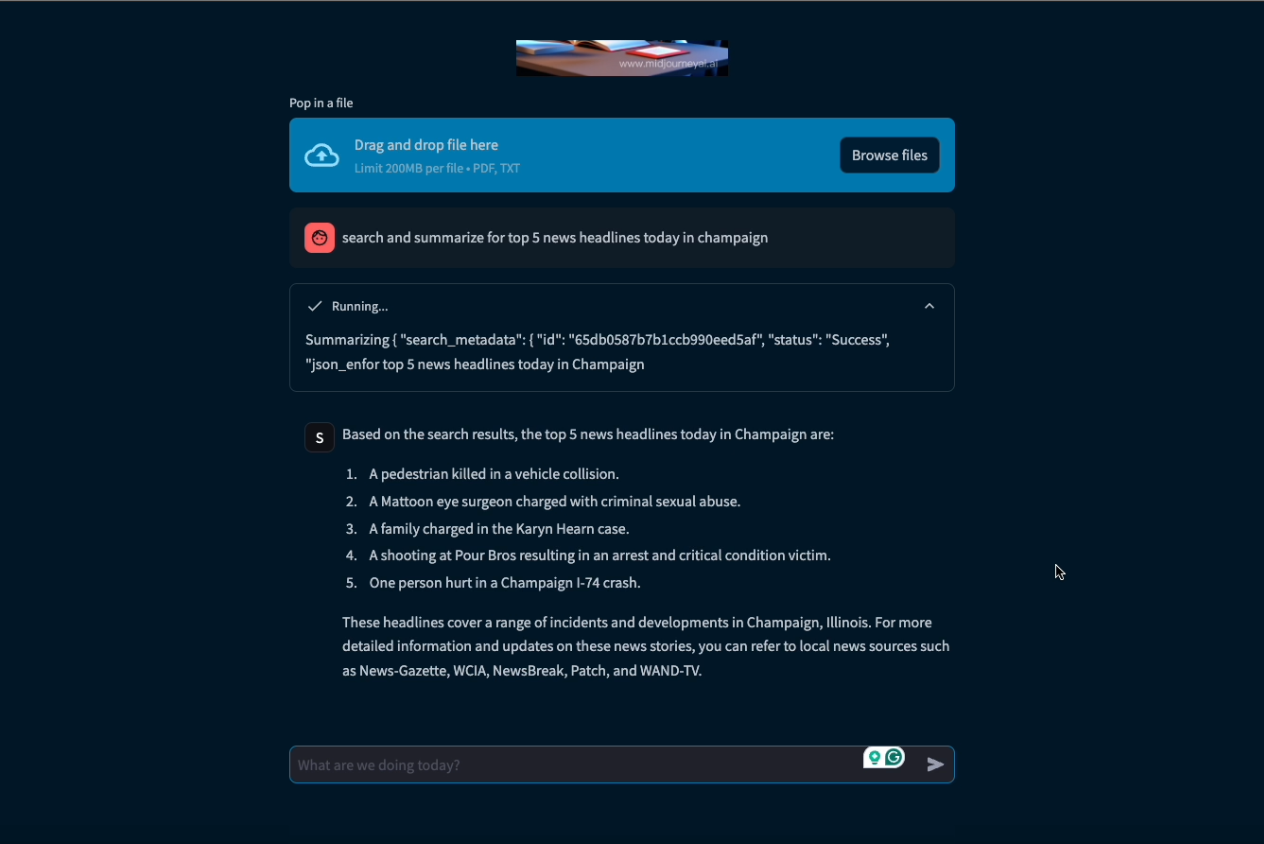
Sarah gives a news glimpse


Inspiration
We're basking in the era of AI. Large Language Models are verging on human intelligence and it's only time to not fear them but to raise them for humanity's betterment. LLMs are capable of performing several tasks indepdently but would it be possible to make them reason and perform tasks one after the other? Like a command-following bot that writes it's own implementational details? Turns out it was possible, afterall.
What it does
Sarah.AI can access your documents, database, and the internet to find any information that you might need.
- Want to recollect your last Zoom meeting? Just drop in the file and Sarah will summarize it for you.
- Want to find out where Taylor Swift will be in March? Sarah will find out and tell you the cost of the - tickets too.
- Want to automate mundane Google searches? Sarah will do it for you. The possibilities are endless.
You dream it, Sarah will do it.
How we built it
Sarah uses GPT4 and GPT3 creatively in conjunction with VectorDatabases using a technique called Retrieval Augmented Generation. Internally, it uses state-of-the-art research in Large Language Models like Chain-of-thought prompting, Context map-reduce summarization, multi-agent hierarchical delegation, Function Calling, Hypothetical Document Embeddings, vectorDatabase similarity search, reason-and-act prompting, few-shot learning, prompt engineering and so much more...
Challenges we ran into
- This model’s maximum context length is 16385 tokens. However, your messages resulted in 17942 tokens. Please reduce the length of the messages. I Solved it by summarizing the webpage with map-reduce and reducing chunk size. It might get a bit too costly because of several requests.
The model is too dumb. It gave “nothing found” and wasn’t using SearchTool. I solved it by assigning priority to tools using modified prompts. Also upgraded the agent to gpt4 only for the decision-making process and modified prompts to just search in times of uncertainty.
NotImplementedError: get_num_tokens_from_messages() is not presently implemented for model cl100k_base. This was because of using conversationSummaryMemory as memory. I didn't want to spend extra money for each summarization call and didn't expect the conversation to be too long hence updated the ChatAgent memory with ConversationBufferWindowMemory with the last 10 interactions.
The cost per request is over $1. Modified agent prompt to use only 2 Google searches. Modified Summarizer prompt to use it sparingly. Updated summarizer to use MapReduce with larger chunk sizes thereby reducing requests. Replaced summaryMemory with BufferWindowMemory.
Too expensive. Delegated some of the simpler tasks to GPT3 so the core decisionmaking can still be smart with GPT4.
Accomplishments that we're proud of
- Captures long-range patterns. Uses all available tools optimally.
- The cost of one request is just under 1 cent. Seriously took a lot of effort to bring it from 1$ per query which would have been unsustainable.
- Performs multi-hop reasoning. Uses the information of one search to perform the next search/task.
- Has long-term memory and conversation history to utilize past search results.
What we learned
- LLMs, GPT, LangChain, Prompt engineering, vectorDataBases
What's next for Sarah - Like Siri but WAY better
- Adapt to Computer Vision, improve reasoning
- Implement custom fine-tuned model for cheaper and faster inference.
- Give Sarah a personality. A little sassiness like J.A.R.V.I.S maybe?
Built With
- ai
- gpt
- langchain
- python





Log in or sign up for Devpost to join the conversation.