-
-
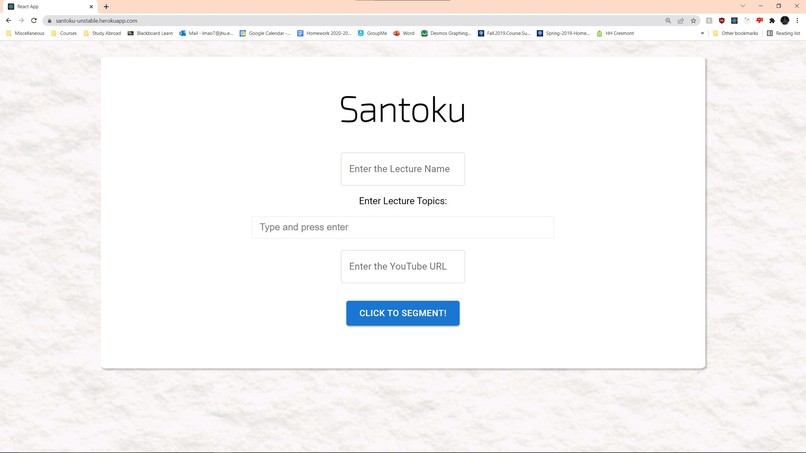
Landing Page
-
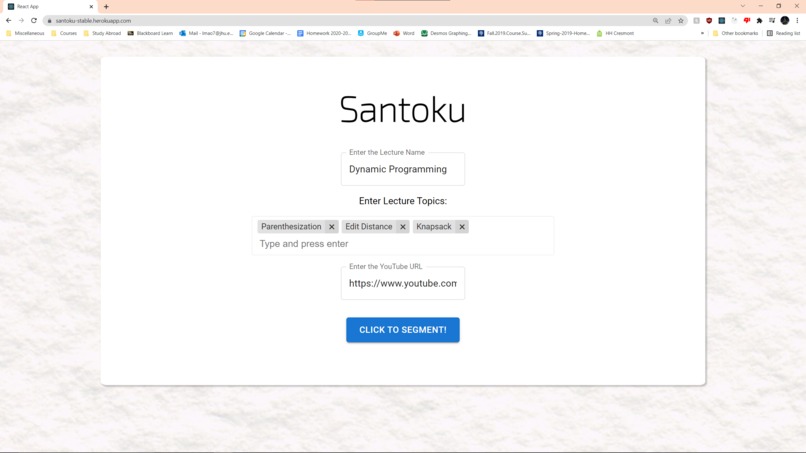
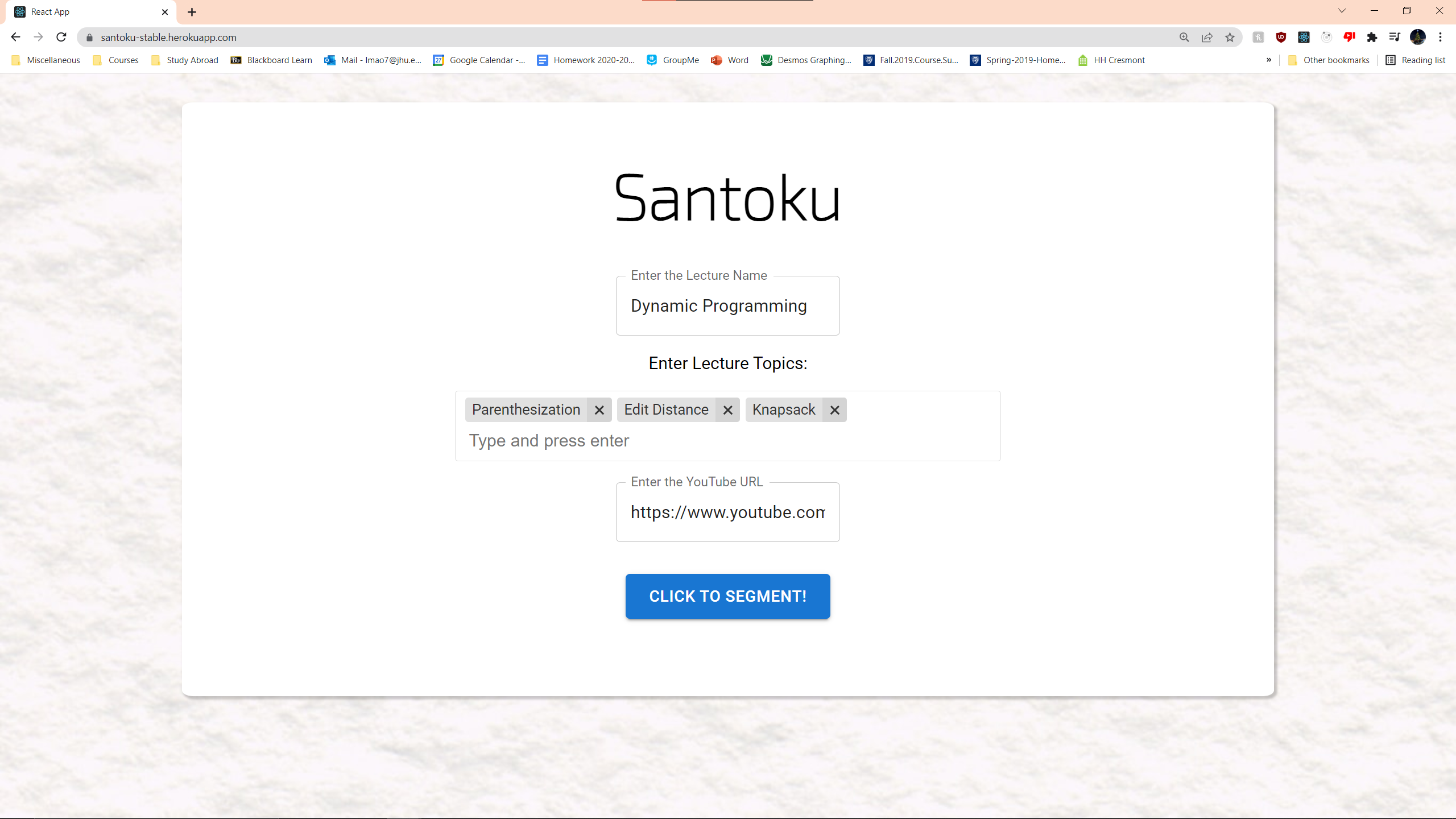
Example Input
-

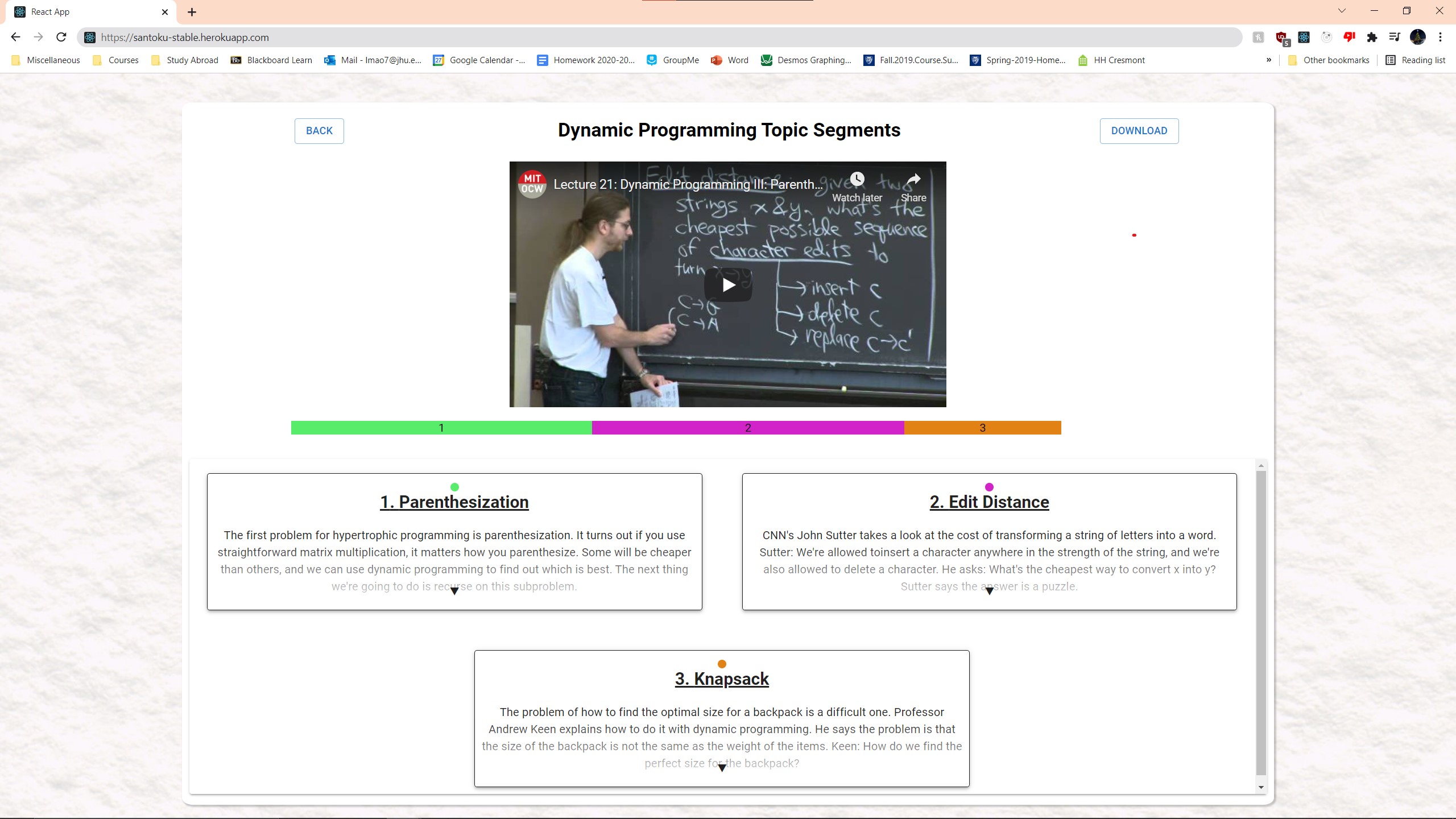
Video Topics Page
-
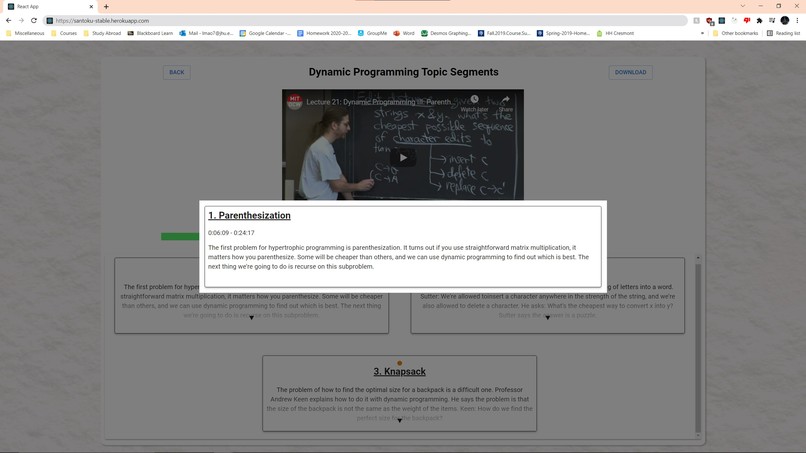
Inflated Topic Summary Card


Inspiration
We've all stared down an impossibly long video that we don't have the time to watch, or just can't seem to find the motivation to. If you're a content creator then you know how laborious it is to summarize the information you're presenting. That's why we made Santoku: to streamline the process of organizing and summarizing videos.
What it does
Santoku allows users to input Youtube video URLs and their key topics and view the segments of video where those topics are talked about, as well as summaries of those sections. This app is not just limited to academic content such as lecture recordings. Anyone who wishes to make any information digestible is free to use this. Want to learn how to play the guitar? Or how a cool speedrun works? Well, Santoku is perfect for helping you navigate that information quickly and efficiently.
How we built it
Our back-end architecture, made primarily with Flask, is centered around a job queue and worker system called Redis Queue, designed to handle potentially time-consuming video ingest requests. WebSocket connections are used when the user first enters the Santoku website to connect the client and server. When the user submits a URL, a request is sent to the backend and a new job is enqueued, allowing a background process to idly service it while the main Flask process can continue to respond to other user requests. Loaded transcripts are segmented into semantically coherent sections through the detection of topic clusters. The Text-To-Text Transfer Transformer and BART autoencoder are then used to generate one-line summaries and extended summaries respectively via the Hugging Face Inference API. And finally, summaries and timestamps are serialized and set back to the client via WebSockets.
The interactive frontend website is made with a combination of React, Material-UI, RJS-Popup, React-Youtube, and CSS transitions. Media query breakpoints help make the website accessible from more devices.
Challenges we ran into
Given that topic segmentation is still an area of continued research, attempting to create a tool that performed just that proved to be a very intellectually difficult challenge for us, especially as this was our first foray into anything NLP-related. Working with Flask was also a novel experience for us as well, and package management proved to be a bit of an issue, but luckily our experience with Python and the tool's ease of use made the process much smoother.
Accomplishments that we're proud of
Given, as stated earlier, our relative lack of experience working in NLP, the fact that we were able to make a tool that works well and gives the user a sleek experience is what makes us proudest.
What we learned
In addition to our newfound knowledge in language processing and in using Flask, we learned to much better adapt our finished product to various different users, maintaining sleek design through things like media query breakpoints.
What's next for Santoku
There were some features that did not make it to the final product for one reason or another. While the segmentation algorithm originally used Jaro similarity to locate words related to the topics (for example, "searches" and "searching" for "search"), problems with the Python package led to this idea being scrapped. Topic inference through Azure proved to be too inconsistent. Finally, automatic video scrolling, section downloading, and enabling users to upload their own videos were also things that we would have liked to have included. With more time, these are definitely things we would like to include.
Built With
- heroku
- huggingface
- javascript
- material-ui
- python
- react
- react-youtube
- redis
- rjs-popup
- websockets

Log in or sign up for Devpost to join the conversation.