-
-
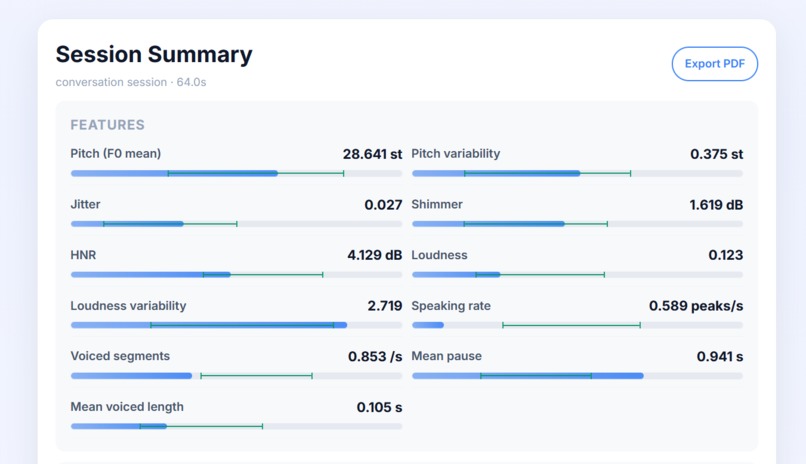
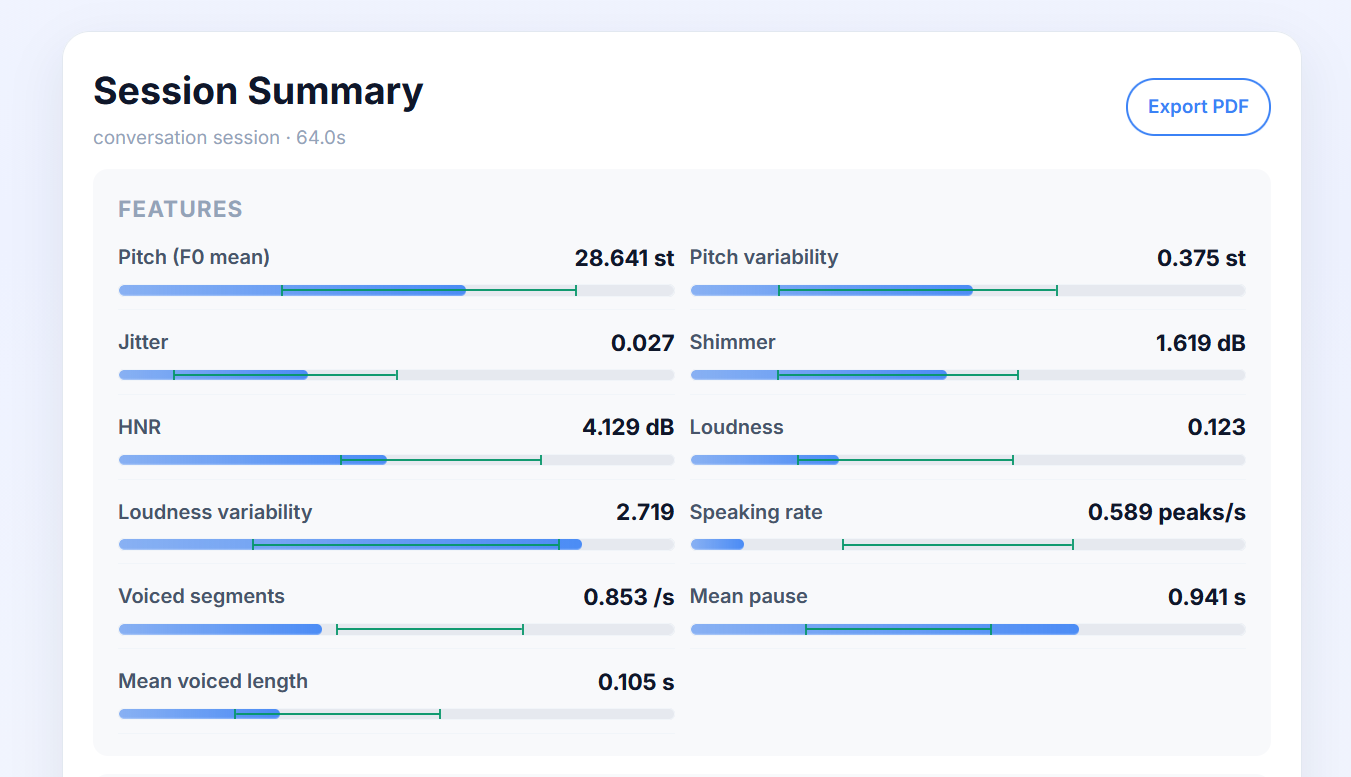
Sample voice acoustic analysis
-
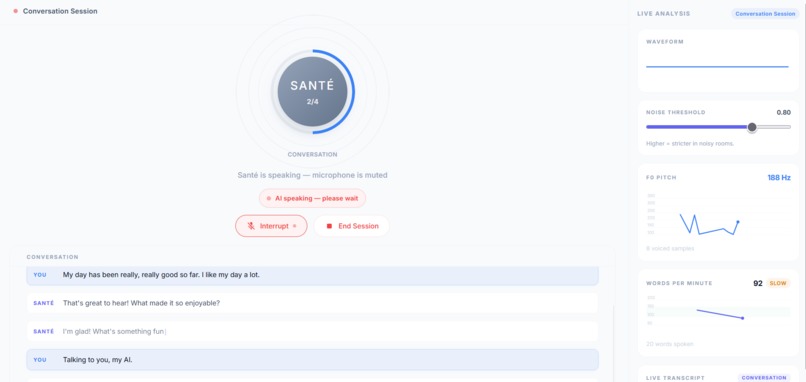
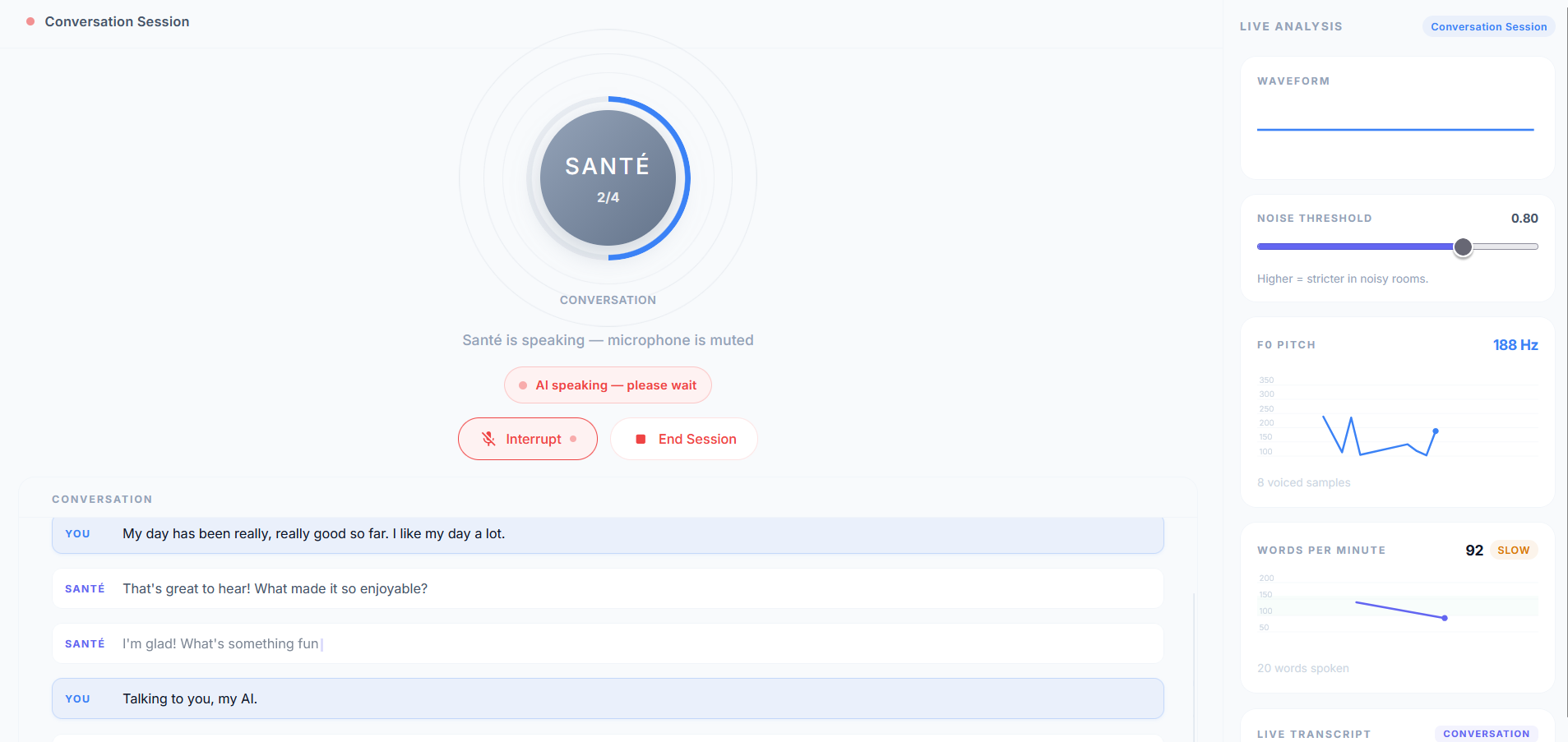
Live conversation
-

Landing page

Inspiration
Voice AI in healthcare is a vastly underexplored area of research in consideration of its impactful applications. Acoustic features alone can monitor and diagnose a wide range of conditions, including neurological and neurodegenerative diseases, voice and speech/language disorders, and even Type II Diabetes (yes, you read that right)!
There is an increasing need for remote healthcare via phone calls, especially with the rise of the elderly population coupled with the increasing demand for automation. The problem with phone-centric healthcare is that critical diagnosis information gets lost over slow and brittle discovery calls every day. In a multi-billion-dollar market growing 2.2x year-over-year, there is an opportunity to simultaneously save doctors and patients millions of hours each week as well as deliver them more accessible care by utilizing cutting-edge research and agentic AI. Inspired, we developed Santé.
What it does
We built Santé around the theme of voice is a biomarker. Santé is able to extract clinical-grade acoustic and phonemic biomarkers and simulate an end-to-end clinical simulation and diagnosis workflow. During a session, Santé:
- Conducts a structured real-time voice interview (conversation + read-aloud phases) through adaptive AI agents.
- Captures and analyzes acoustic biomarkers like pitch variability, jitter, shimmer, HNR, loudness dynamics, speaking rate, pause structure, and voiced segment behavior.
- Runs phoneme/disfluency analysis using a cutting-edge DysfluentWFST pipeline to detect repetition/insertion/deletion-level speech irregularities.
- Streams live session telemetry (waveform, pitch trends, transcript progression) for immediate visibility.
- Generates a clinician-facing report with quality scoring, risk-oriented signal summaries, and safety-aware triage guidance.
- Exports reports for easy sharing and enables configurable follow-up alerting workflows.
In short: Santé turns unstructured phone conversations into structured, actionable clinical signal.
How we built it
Santé is a full-stack, multi-agent voice intelligence system:
- Frontend: Next.js + React for a real-time clinical UX with live transcript and voice analytics panels.
- Backend: FastAPI for orchestration across live WebSocket pipelines, analysis endpoints, and reporting.
- Realtime voice: OpenAI Realtime for low-latency conversational interaction and transcription.
- Acoustic biomarker extraction: openSMILE-based feature processing for robust speech signal analysis.
- Phoneme/disfluency engine: DysfluentWFST-based inference pipeline deployed on RunPod serverless GPU endpoints.
- Telephony + async workflows: Twilio + Redis/rq worker queue for call ingestion and post-call processing.
- Reporting + safety layer: Multi-agent summary generation, quality-aware scoring, and safety signal escalation logic.
The key architectural decision was parallelizing voice stream processing so conversation, transcription, acoustic analysis, and phoneme/disfluency inference can coexist in one coherent workflow.
Challenges we ran into
- Latency vs. depth tradeoff: Clinical-grade signal extraction is expensive; keeping the session responsive required aggressive pipeline optimization.
- Audio interoperability: Bridging telephony codecs, browser audio formats, and model input requirements was unexpectedly hard.
- Model cold starts: Serverless inference is cost-effective but introduces startup delays that affect user experience.
- Signal reliability in noisy settings: Real-world calls vary wildly in microphone quality, background noise, and speaking style.
- Safety calibration: We needed to reduce both false alarms and missed urgent cues in a sensitive healthcare context.
- Trustworthy output design: Presenting exploratory signal estimates without overclaiming diagnosis required careful UX and language framing.
Accomplishments that we're proud of
- Built a working end-to-end healthcare voice pipeline.
- Integrated conversation agents, acoustic biomarkers, and phoneme/disfluency intelligence into one product.
- Deployed a scalable serverless inference architecture that remains practical on cost.
- Added safety-aware report generation with structured summaries clinicians can act on faster.
- Created a clear patient/doctor-oriented workflow that makes voice AI tangible for real clinical operations.
What we learned
- Voice in healthcare is far more information-dense than most teams assume.
- Phonemic + acoustic fusion is much more powerful than transcript-only analysis.
- Infrastructure decisions (queueing, codec handling, fallbacks) matter as much as model quality.
- Clinical usability depends on transparency, confidence framing, and quality scoring—not raw model output alone.
- “AI that helps clinicians” is mostly about reducing friction, preserving nuance, and improving handoff quality.
What's next for Santé
- Run prospective pilot studies with clinicians to validate utility and workflow impact.
- Improve personalization across age, accent, and condition-specific speech patterns.
- Expand multilingual support and broader speech/language disorder coverage.
- Deepen longitudinal tracking so voice changes can be monitored over time.
- Integrate with clinical systems (EHR/workflow tooling) for real deployment readiness.
- Continue advancing the phoneme/disfluency stack on top of the latest DysfluentWFST research.
Built With
- fastapi
- openai
- python
- redis
- runpod
- twilio
- typescript







Log in or sign up for Devpost to join the conversation.