🐯 Sandokan
Train with reasoning, optimize with precision.
A CPU-only, header-only C++ neural network training engine built for on-device learning —
no Python, no PyTorch, no GPU required.
💡 Inspiration
Most neural network training assumes a GPU and a Python runtime. That assumption breaks in the places where learning matters most:
- A microcontroller updating a sensor model in the field
- A robot adapting its controller between episodes
- An embedded vision system that must improve on the device it runs on
The trend toward giant GPU-trained models obscures a different class of problem: systems that must keep learning after deployment, with local data, on hardware that has no network connection or power budget for a GPU. Sandokan was built for those environments.
🔧 What It Does
Drop a single header into any C++ project and get a complete training pipeline:
| Feature | Details |
|---|---|
| Architectures | Fully connected networks, residual blocks |
| Optimizers | SGD, Adam (with bias correction) |
| Schedulers | LinearLR |
| Loss functions | CrossEntropy, BCE, MSE |
| Datasets | IDX image data (EMNIST, MNIST), numeric CSVs |
| Persistence | Custom .sand binary format with normalization |
| Inference | Top-k predictions, ASCII art previews |
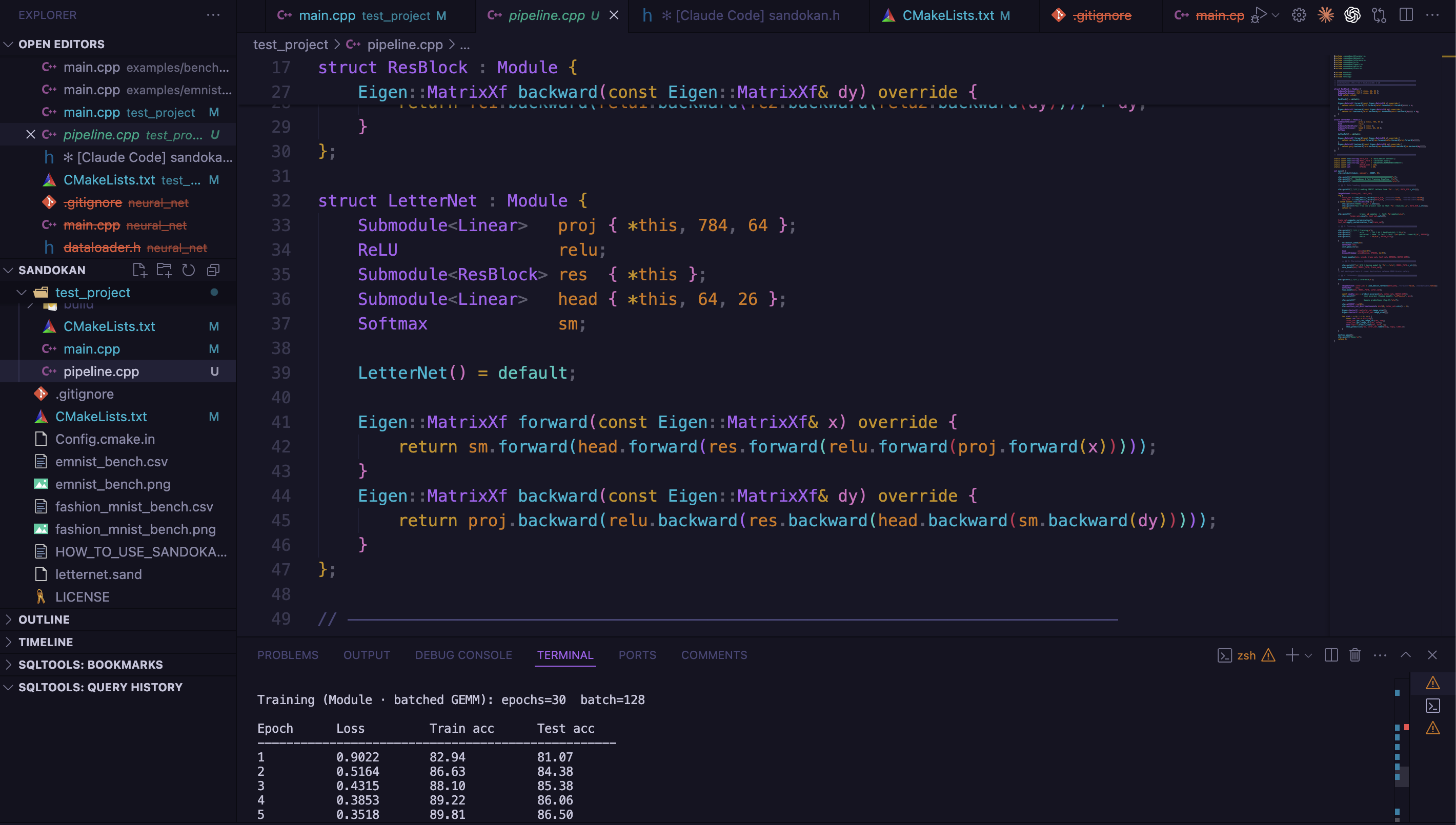
Networks are defined by composing typed submodules — Submodule<T> auto-registers on construction, so you can't accidentally forget a register_module call:
struct LetterNet : Module {
Submodule<Linear> proj { *this, 784, 64 };
ReLU relu;
Submodule<Linear> head { *this, 64, 26 };
Eigen::MatrixXf forward(const Eigen::MatrixXf& x) override {
return head.forward(relu.forward(proj.forward(x)));
}
};
⚙️ How We Built It
PMAD Slab Allocator — zero-fragmentation gradient memory
The standard allocator story for neural network training is painful: thousands of separate heap allocations per epoch, fragmentation over long runs, malloc unavailable on some embedded targets.
PMAD (Pre-allocated Memory Arena for Derivatives) solves this at the layer level. Before training begins, it walks the network topology, computes the exact size class for every gradient buffer, and satisfies them all from one contiguous slab. During training there are zero malloc/free calls.
LetterNet net;
init_pmad_for(net); // walks topology → computes sizes → allocates slab → migrates pointers
Benefits:
- Cache-friendly: all gradient buffers for a pass are packed contiguously → L2/L3 cache fits them together
- Deterministic latency: no allocator lock contention, no OS page-fault surprises mid-epoch
- Topology-aware: add a layer, re-call
init_pmad_for(), and the slab is rebuilt automatically
mmap-backed Datasets — bounded memory regardless of dataset size
Image data is memory-mapped from disk. Pages are faulted on demand during batch assembly, so the working set stays bounded even over 100k+ samples. The OS page cache deduplicates reads across runs — a second training run costs zero disk I/O.
ImageDataset train = load_emnist_letters("data/Emnist Letters", /*train=*/true);
train.compute_normalization();
test.apply_normalization_from(train); // never leaks test distribution
Apple AMX Acceleration
Batched GEMM is routed through Eigen + Apple Accelerate on Apple Silicon. Combined with PMAD's cache-friendly layout, this is the primary driver of the training speedups below.
📊 Performance
Architecture
784 → 64 → 64 → 26| batch = 128 | Apple Silicon (M-series)
EMNIST Letters — 124,800 training samples
| Backend | ms / epoch | samples / sec |
|---|---|---|
| Sandokan single-sample | 1,508 | 82,757 |
| Eigen single-sample | 1,851 | 67,408 |
| Sandokan batched + parallel | 77 | 1,615,666 |
| Eigen batched | 123 | 1,015,951 |
Sandokan's batched path is 19.5× faster than single-sample and 1.5× faster than plain Eigen.
Fashion MNIST — 60,000 training samples
| Backend | ms / epoch | samples / sec |
|---|---|---|
| Sandokan batched + parallel | 34.4 | 1,742,000 |
| Eigen batched | 40.9 | 1,464,000 |
🎯 Accuracy
| Dataset | Architecture | Optimizer | Result |
|---|---|---|---|
| EMNIST Letters | 784 → 64 → ResBlock(64) → 26 | Adam + LinearLR | 88.25% test accuracy |
| Fashion MNIST | 784 → 64 → 64 → 10 | SGD | ~85% |
🧱 Tech Stack
- C++17 — no runtime dependencies beyond the standard library
- Eigen 3 — linear algebra backend
- Apple Accelerate / AMX — hardware BLAS on Apple Silicon
- CMake ≥ 3.15 — build system
🚧 Challenges
- Designing PMAD's size-class inference to work generically across arbitrary network topologies without requiring the user to annotate buffer sizes manually
- Folding the Softmax Jacobian into the CrossEntropy backward pass correctly — Softmax's own
backwardbecomes a passthrough, which avoids materializing the full Jacobian matrix while still producing the right gradient - Keeping the API ergonomic (single-header, no registration boilerplate) while giving the allocator enough topology information at init time
🏆 Accomplishments
- A complete training pipeline with zero external runtime dependencies beyond Eigen
- 1.5× speedup over plain Eigen batched training on EMNIST Letters
- 88.25% test accuracy on a 26-class letter recognition task, trained entirely on CPU
- Deterministic, allocation-free gradient memory during training via PMAD
📚 What We Learned
- Slab allocation is surprisingly portable and powerful for neural network workloads — the key insight is that gradient buffer sizes are statically determined by the network architecture, so they can be committed upfront
- mmap is underused for ML datasets; bounded RSS matters enormously on devices where RAM is the constraint, not disk
🔮 What's Next
- Convolutional layers for on-device vision
- ARM NEON / CMSIS-NN support for non-Apple embedded targets
- INT8 quantization for microcontroller deployment
- ONNX export for interoperability with inference runtimes
🔗 Links
Built with C++17 · Eigen · Apple Accelerate · CMake


Log in or sign up for Devpost to join the conversation.