
Sandbox: An AI-Powered Teach-Back Workspace That Measures Understanding, Not Recall
Inspiration
As college students in computational biology and pre-med tracks, we constantly work through dense, complex material - metabolic pathways, signaling cascades, regulatory networks. We realized something unsettling: we could memorize definitions and still struggle to explain the system from scratch.
Flashcards optimize for recall. Exams demand reconstruction.
The moment that inspired Sandbox was this: If you can’t draw it and teach it without notes, you don’t fully understand it.
In a world where AI can instantly give answers, the real differentiator is the ability to explain your thinking. We didn’t want another tool that generates solutions - we wanted a tool that evaluates understanding. Sandbox was built to turn students from answer-consumers into idea-builders.
What it does
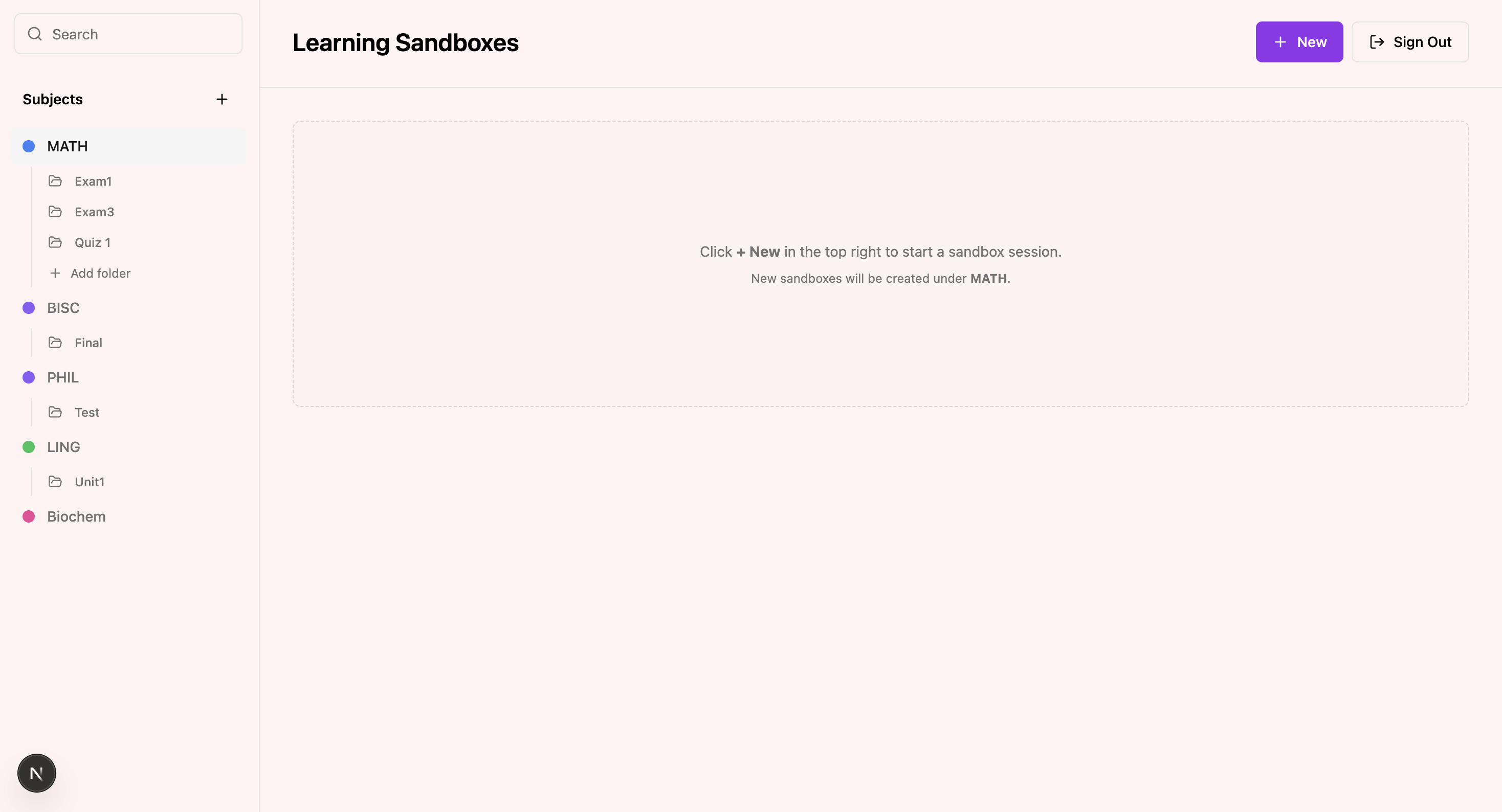
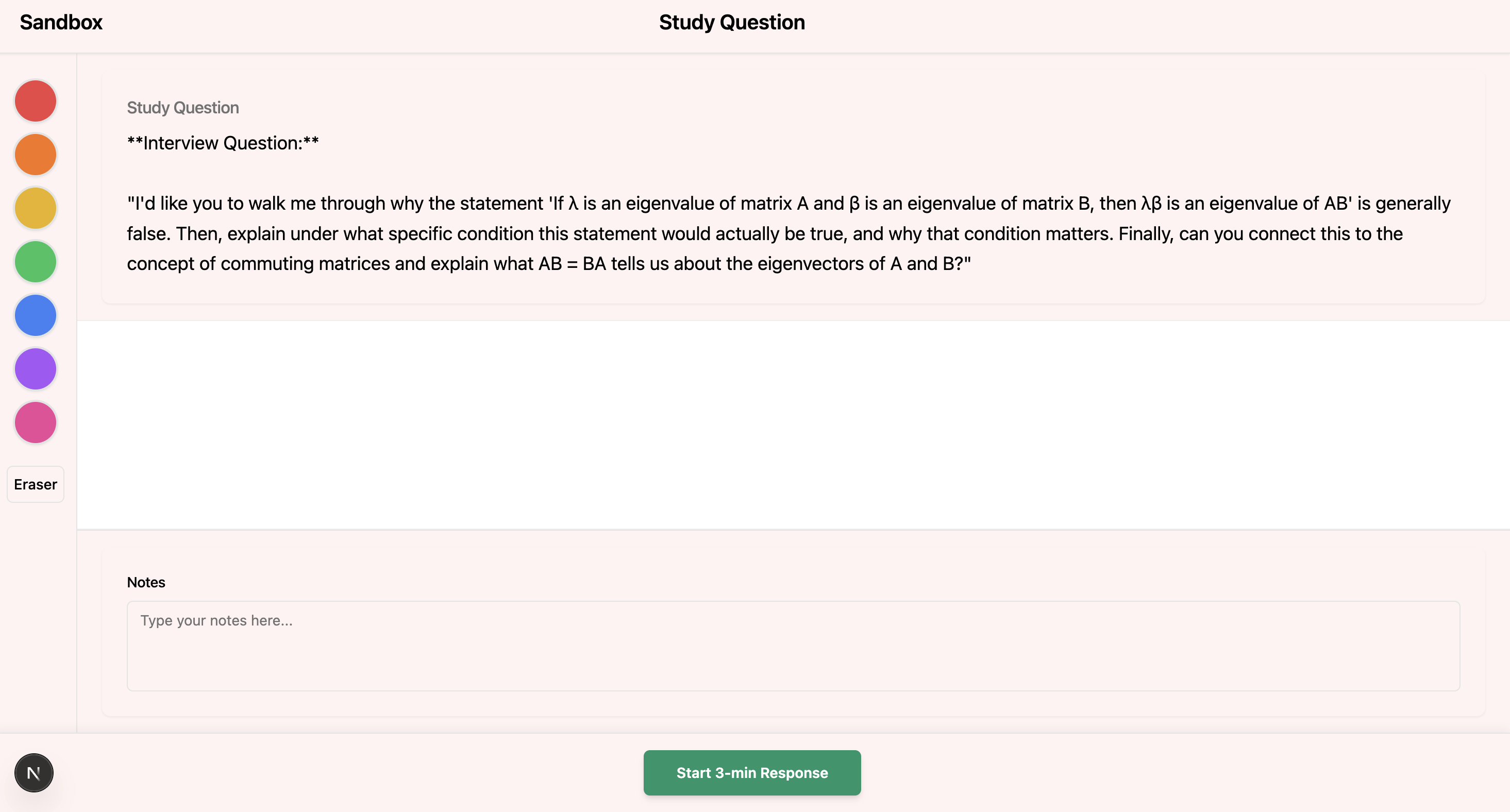
Sandbox is an AI-powered teach-back workspace designed to help students learn by explaining ideas visually and verbally. Instead of asking, “What’s the answer?”, Sandbox asks, “Can you reconstruct the idea?” The core belief is that true understanding comes from being able to teach a concept - not just recall it.
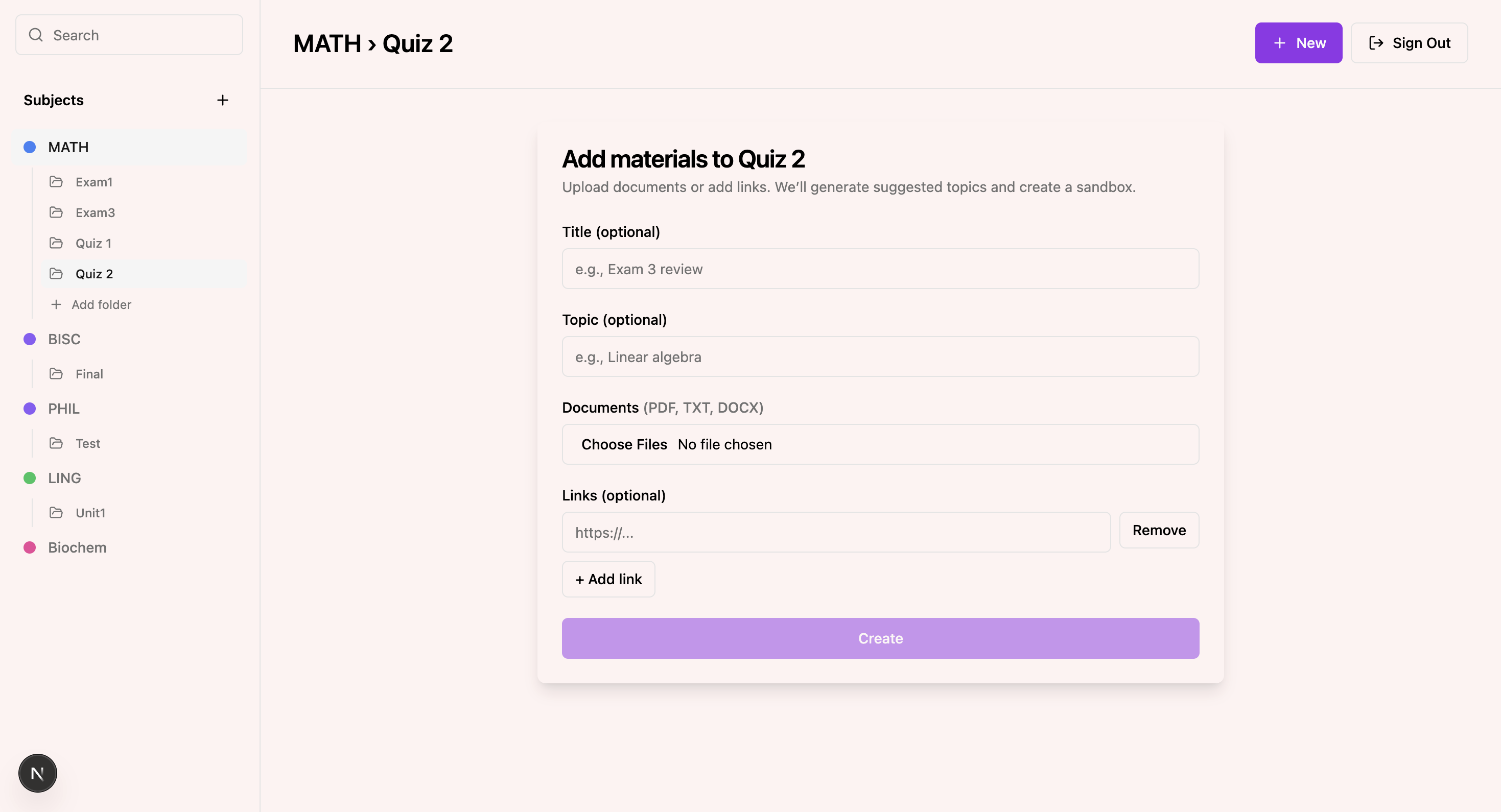
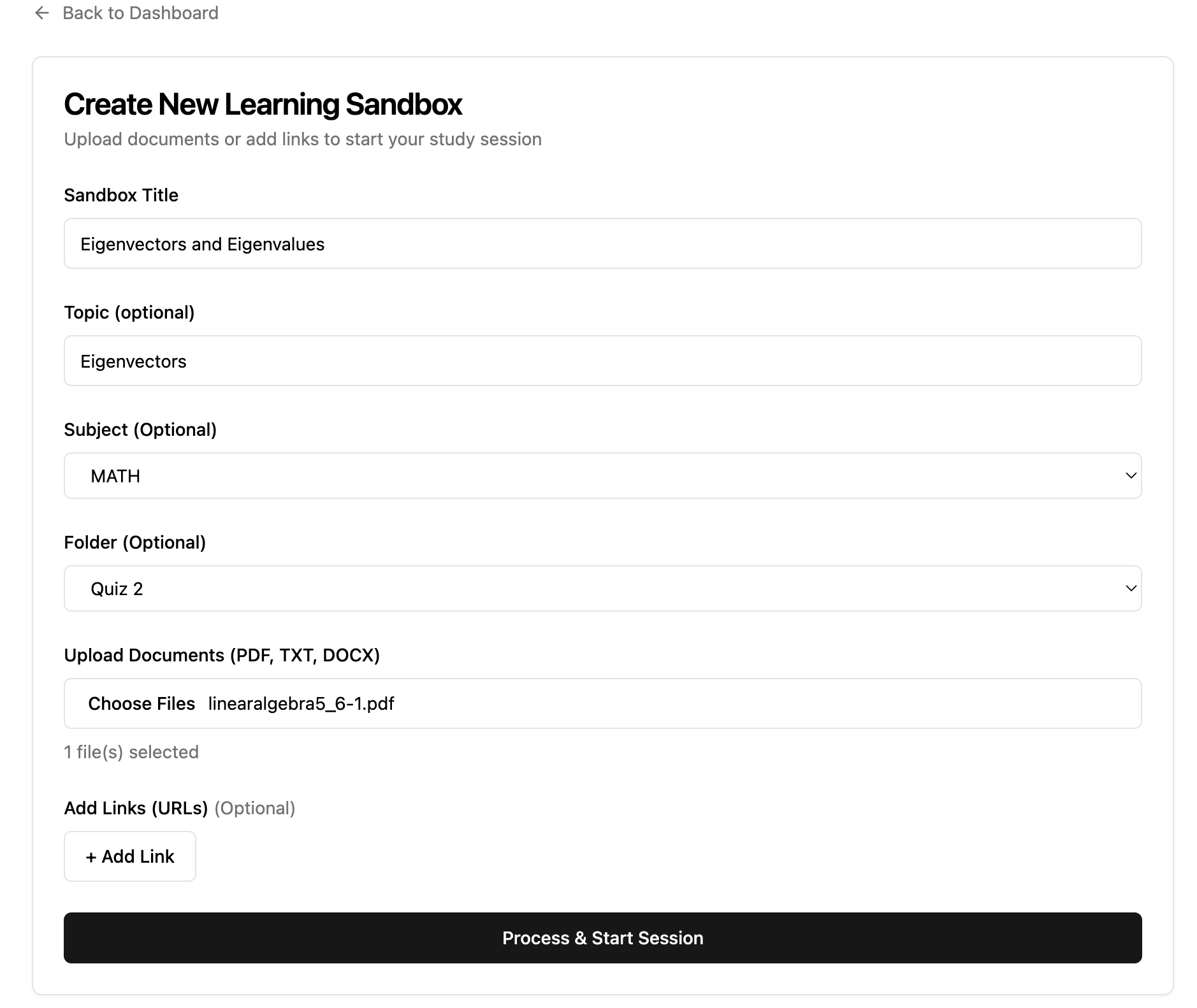
The user flow begins with signing in through Supabase authentication and organizing content into folders by subject or topic. Students upload dense material such as PDFs, lecture slides, or notes. When they start a learning session, they ask a question based on their uploaded content and then record themselves drawing and explaining their reasoning.
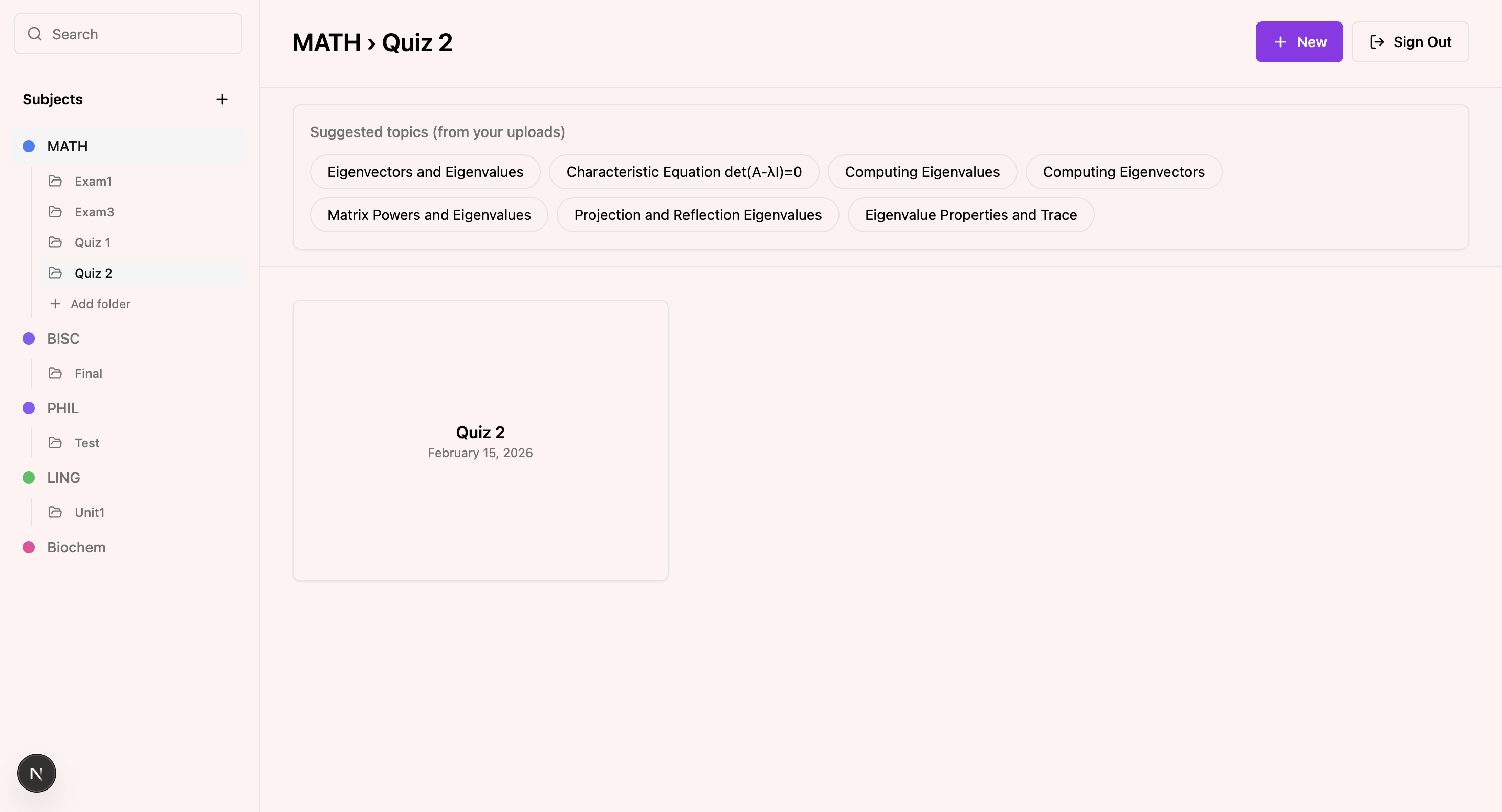
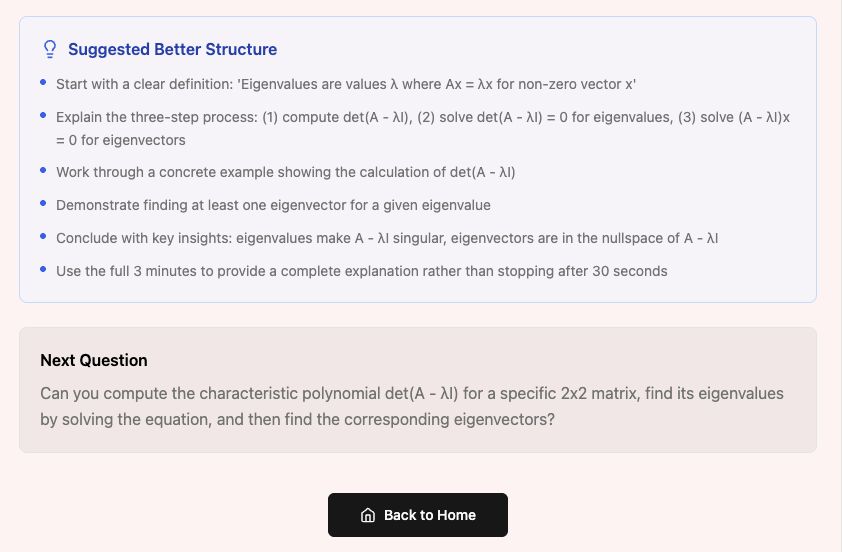
Rather than returning a solution, Sandbox evaluates the student’s explanation. It analyzes conceptual coverage, structural clarity, logical flow, missing components, and potential misconceptions. The goal is not to check whether the answer is correct, but to measure how deeply the student understands the system.
We model understanding as something more nuanced than binary accuracy. Instead of grading correctness, Sandbox evaluates understanding as a function of coverage, structure, causal reasoning, and conceptual connections:
U = f(coverage, structure, causal reasoning, connections)
Sandbox gives feedback on how well a student rebuilt the system from memory - not whether they memorized it.
How we built it
We architected Sandbox as a full-stack, AI-powered system centered around grounded document understanding and multimodal evaluation. The system is designed to tightly integrate structured content ingestion, semantic retrieval, and real-time teach-back analysis into a single cohesive learning workflow. Rather than building a simple Q&A interface, we engineered a pipeline that transforms static documents into structured, retrievable knowledge representations that power evaluation of student reasoning.
On the frontend, we built a modular web application using React and Next.js (v16 with Turbopack), written in TypeScript for type safety and maintainability. The application follows a folder-based architectural structure that mirrors the cognitive model of learning: subjects contain folders, folders contain documents, and documents power sessions. The codebase reflects this modular philosophy, with clearly separated concerns across components such as a custom Canvas for drawing explanations, folder upload panels for document ingestion, dashboard sidebars for structured navigation, subject and folder dialog modals, sandbox session cards, and authentication providers.
The frontend handles user authentication (via Supabase), session management, subject/folder organization, document uploads, and recording of drawing-based explanations. Each teach-back session is structured as a stateful interaction, ensuring that visual explanations, prompts, and user metadata are stored in a way that downstream AI evaluation can interpret semantically rather than superficially.
On the backend and AI infrastructure layer, we implemented a semantic retrieval system using Pinecone as our vector database. Every uploaded document (PDFs, lecture slides, notes) is parsed, chunked, and embedded into high-dimensional vector representations. These embeddings are stored in Pinecone, enabling contextual retrieval grounded strictly in the user’s uploaded material. This allows Sandbox to generate session questions and evaluate explanations based on semantically relevant content rather than generic model knowledge.
By combining structured document ingestion, vector-based retrieval, and multimodal explanation capture (drawing + speech/thought process), Sandbox moves beyond correctness-based grading. The system evaluates conceptual coverage, structural coherence, causal reasoning, and knowledge connections. In other words, we model understanding as a reconstruction problem, not an answer-matching problem.
Technically, the architecture cleanly separates: 1) UI/interaction layer (Next.js + React + TypeScript), 2) Authentication and session persistence (Supabase), 3) Document ingestion and preprocessing pipeline, 4) Vector storage and semantic retrieval (Pinecone), 5) AI reasoning layer for teach-back evaluation
Challenges we ran into
One of our biggest challenges was defining and measuring “understanding.” Grading correctness is easy, but evaluating structure, reasoning, and conceptual completeness is not. We had to formalize what conceptual coverage means, design heuristics for structural feedback, and avoid leaking the “right answer.” This required shifting from answer-generation to reasoning-analysis - building a system that critiques reconstruction instead of outputs.
Grounding the AI properly was another core challenge. Our retrieval system needed to be fast, strictly scoped to user-uploaded content, and isolated across users and folders. Designing clean namespace logic in Pinecone was critical to preventing cross-contamination and ensuring context-aware, hallucination-resistant feedback. We also faced multimodal complexity. Aligning drawing input, transcribed speech, and document-grounded retrieval is far more complex than a text-only chat interface. The system had to interpret structure and conceptual flow across modalities.
Finally, full-stack integration under hackathon time pressure was intense. We were configuring Supabase authentication, Pinecone indexing, embedding pipelines, Next.js (Turbopack + TypeScript), environment variables, and resolving server conflicts. But the system now runs fully end-to-end.
Accomplishments that we're proud of
First, we built a fully functional teach-back evaluation engine - not a prototype, but a working end-to-end system. A student can upload dense material, trigger document ingestion and embedding, store vectors in Pinecone with clean namespace isolation, start a learning session, ask a grounded question, record a visual explanation, and receive structured reasoning feedback. The pipeline runs seamlessly from embedding to similarity retrieval to evaluation - all grounded strictly in the student’s uploaded content.
Second, we successfully integrated a complex full-stack architecture under tight constraints. We combined Supabase authentication and database storage, Pinecone vector indexing, a modular ingestion and embedding pipeline, transcription services, and a React + Next.js (TypeScript, Turbopack) frontend with organized subject/folder/session management. Each backend service — embedding, retrieval, ingestion, evaluation, Supabase access - is modularized, allowing the system to scale and evolve cleanly.
Third, and most importantly, we shifted the role of AI in learning. We deliberately avoided building “just another AI tutor” that generates answers. Instead, we built a cognitive feedback system. Sandbox evaluates reasoning - conceptual coverage, structure, causal flow, and connections - rather than correctness. That philosophical shift reframes AI from answer-provider to thinking evaluator, and that’s the core innovation we’re proud of.
What we learned
Through building Sandbox, we learned that AI is exceptionally good at generating answers - but very few systems are designed to measure thinking. If AI is going to meaningfully support learning, it can’t just produce explanations; it has to evaluate how a student reconstructs ideas. Retrieval grounding proved essential for trust - without strict context isolation and vector-based retrieval, feedback becomes generic or unreliable. We also realized that learning requires productive friction. Students don’t need more information; they need structured reflection that forces them to organize, connect, and rebuild concepts themselves.
We also grew as engineers. We architected a modular backend, integrated vector search with user-scoped namespaces, and tested the system using both white-box validation of service logic and black-box simulation of full user workflows. Under time pressure, we debugged environment variables, API key issues, and index mismatches while maintaining system integrity. More importantly, we learned how to communicate clearly when systems broke, divide responsibilities based on team strengths, and make architectural decisions collaboratively. Building Sandbox wasn’t just about writing code - it was about thinking systematically, testing rigorously, and executing as a team.
What's next for Sandbox
Looking ahead, our vision for Sandbox is to transform it from a powerful prototype into the default way students test mastery. We plan to introduce structured evaluation dashboards that score and visualize conceptual coverage over time, allowing students to compare teach-back sessions and track longitudinal gaps in understanding. We also want to add a collaborative “teach each other” mode and expand beyond STEM into domains like law, language learning, and test preparation - making Sandbox a universal cognitive feedback platform.
On the AI side, we aim to deepen multimodal alignment between drawing and speech, enabling more precise interpretation of diagram structure and conceptual flow. We plan to implement concept graph reconstruction, automated misconception detection, and adaptive follow-up questioning that dynamically probes weak areas. The goal is to evolve Sandbox from structured feedback into an intelligent reasoning coach.
From a systems perspective, we plan to optimize our Pinecone indexing strategy for scale, introduce caching layers to reduce retrieval latency, refine embedding chunking strategies for better semantic coherence, and expand our Supabase schema to support richer session analytics. We also intend to move toward production-grade infrastructure beyond a development server, preparing Sandbox for scalable deployment.
Loom Video: https://www.loom.com/share/5001005d45774bc4a88b705fb97ed9fa
Built With
- next.js
- node.js
- pinecone
- postcss
- python
- react
- shadcn/ui
- supabase
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.