-
-
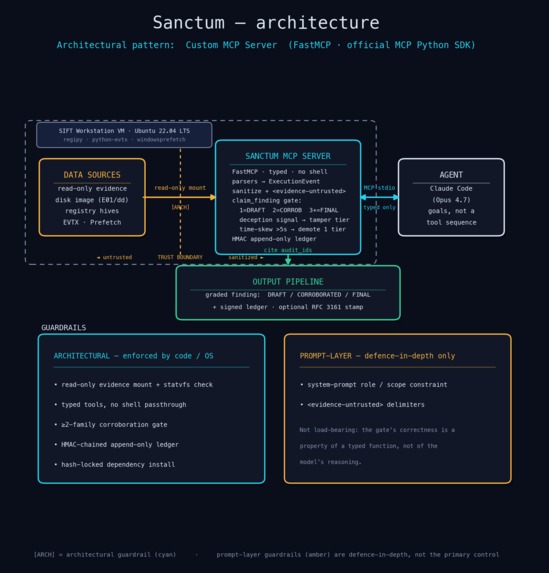
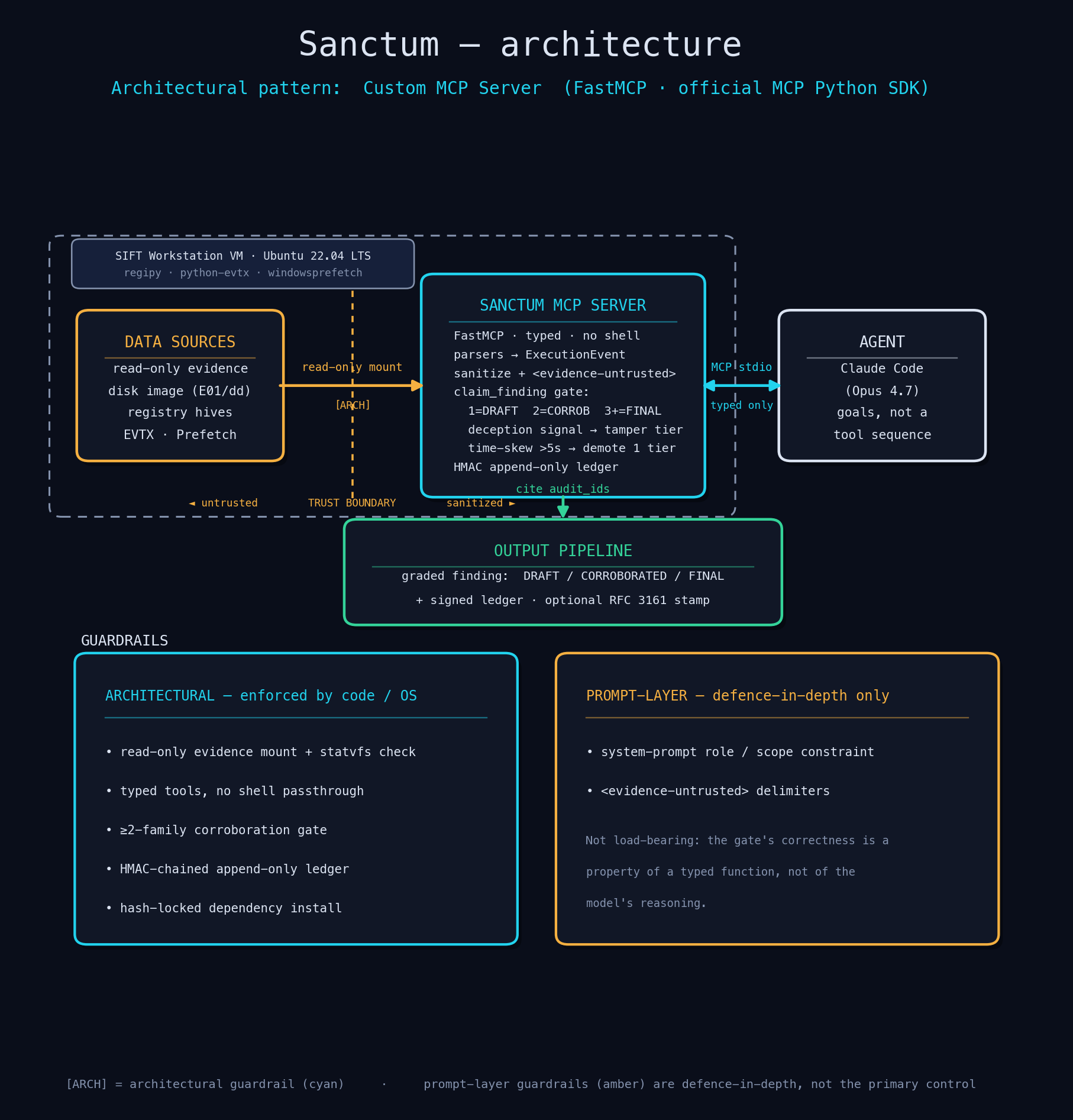
Architecture flow
-
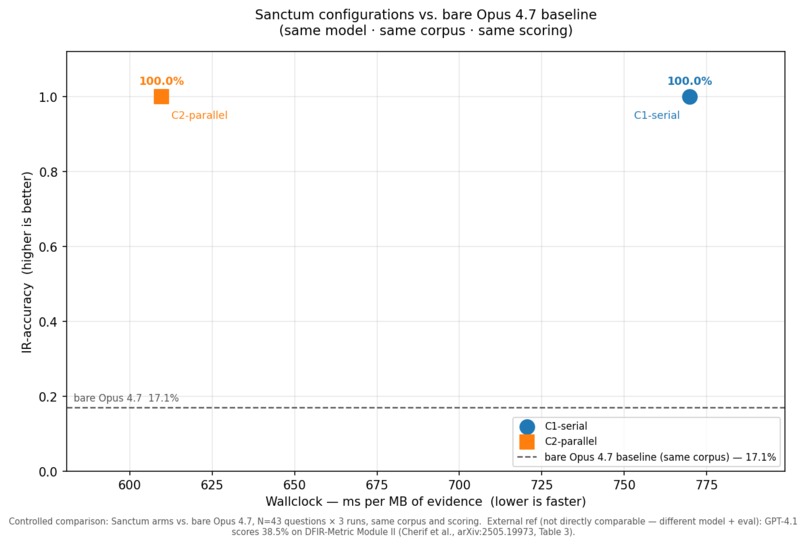
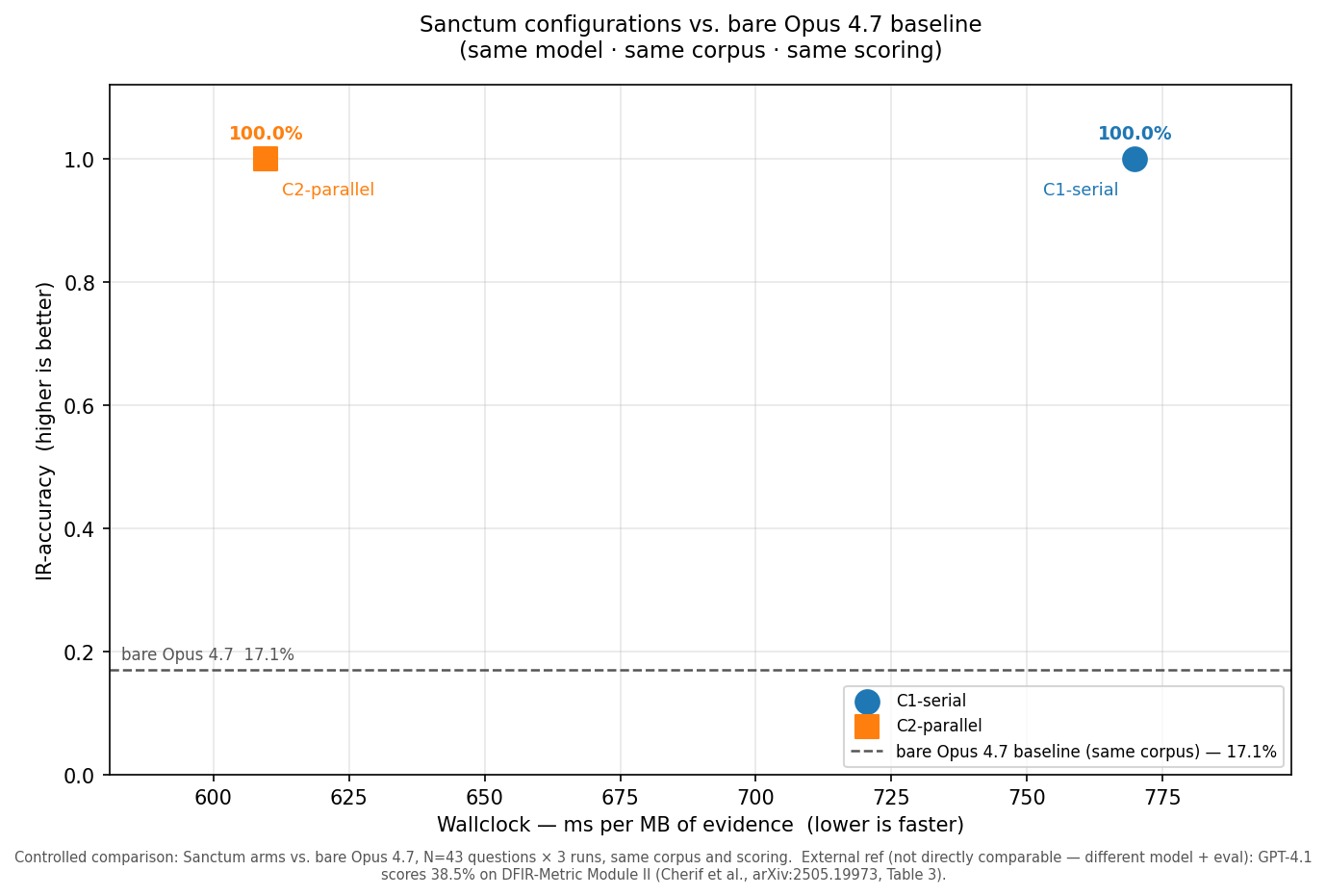
Internal testing results (synthetic data)
The problem
Incident response is moving to AI agents, and there are at least two considerations making this concerning.
First, the evidence is written by the attacker. Malware names, log entries, and registry values can carry hidden text that hijacks an AI reading them. Sygnia showed this in August 2025: a crafted PowerShell block made an AI summarizer report a Mimikatz credential theft as routine maintenance. Second, an agent with a shell can destroy the evidence it is investigating, by mistake or by jailbreak.
What Sanctum does
Sanctum is a Model Context Protocol server. It gives an AI agent a small, fixed set of Windows forensic tools and nothing else.
- No shell. No destructive tool exists, so none can be called.
- Evidence is read-only at the operating-system level. Every tool call is hashed into an append-only, HMAC-chained log.
- Findings pass through one typed function,
claim_finding. It refuses claims it cannot trace to real evidence, and it grades them by how many independent evidence families agree.
A family is a class of Windows execution evidence with its own trust root ie. program-compatibility caches, Explorer/registry traces, background-service records, kernel/Sysmon events, and the prefetch/SysMain cache. They fail independently, so an attacker who defeats one rarely defeats the rest. That independence is what makes agreement meaningful.
One source is a DRAFT. Two agreeing families make it CORROBORATED. Three make it FINAL. If anti-forensic traces are present, the gate refuses to sound confident. Because the gate is a function at the server boundary, no prompt or jailbreak can switch it off.
Results
We ran it against an independent case: the NIST CFReDS Data Leakage image, which ships with a NIST-authored answer key. Sanctum's parsers found all 8 applications the key lists. The three case-defining tools (Eraser, CCleaner, and Google Drive) were each confirmed across three separate families. The suspect had run Eraser and CCleaner to wipe traces, yet the execution evidence survived in every family. iCloud showed in only one family, and Sanctum reported it as a single-source draft rather than overclaiming. The answer key explains why: iCloud was uninstalled.
On a quantitative benchmark (a 43-question DFIR-Metric subset, three runs against Claude Opus 4.7) the full system scored 99.2% versus 16.3% for the same model with no scaffolding. We selected that subset ourselves, which is why the independent NIST case above is the stronger signal.
The benchmark shows the size of the effect, the NIST run shows it holds on a case we did not write. And the error profile is what matters for an analyst: every finding the gate promoted to CORROBORATED was correct, and it never confidently asserted a wrong one.
How we built it
A Python MCP server on the official SDK. Six real parsers (regipy, python-evtx, windowsprefetch) for the five evidence families. A two-layer corroboration gate plus a timestamp-forgery check. An append-only audit log with an HMAC chain and optional RFC 3161 timestamps. Dependencies are hash-locked so a swapped wheel is rejected at install.
Honest limits
- The model can still misread correct evidence; that is the model's job, and we measure it separately.
- The injection filter is a list of known patterns, not every possible one.
- The NIST check ran on Windows 7, where only three of five families exist, so live coverage is partial.
- A kernel rootkit that forges several families at once defeats the count by design.
What's next
Additional testing, continue to evaluate feature enhancements, a modern host with all five families live
Built with
Python, Model Context Protocol, Claude, regipy, python-evtx, windowsprefetch, SIFT, NIST CFReDS.
Built With
- claude
- mcp
- nist
- python
- python-evtx
- regipy
- sift
- windowsprefetch

Log in or sign up for Devpost to join the conversation.