-
-
Sanctuary home page.
-
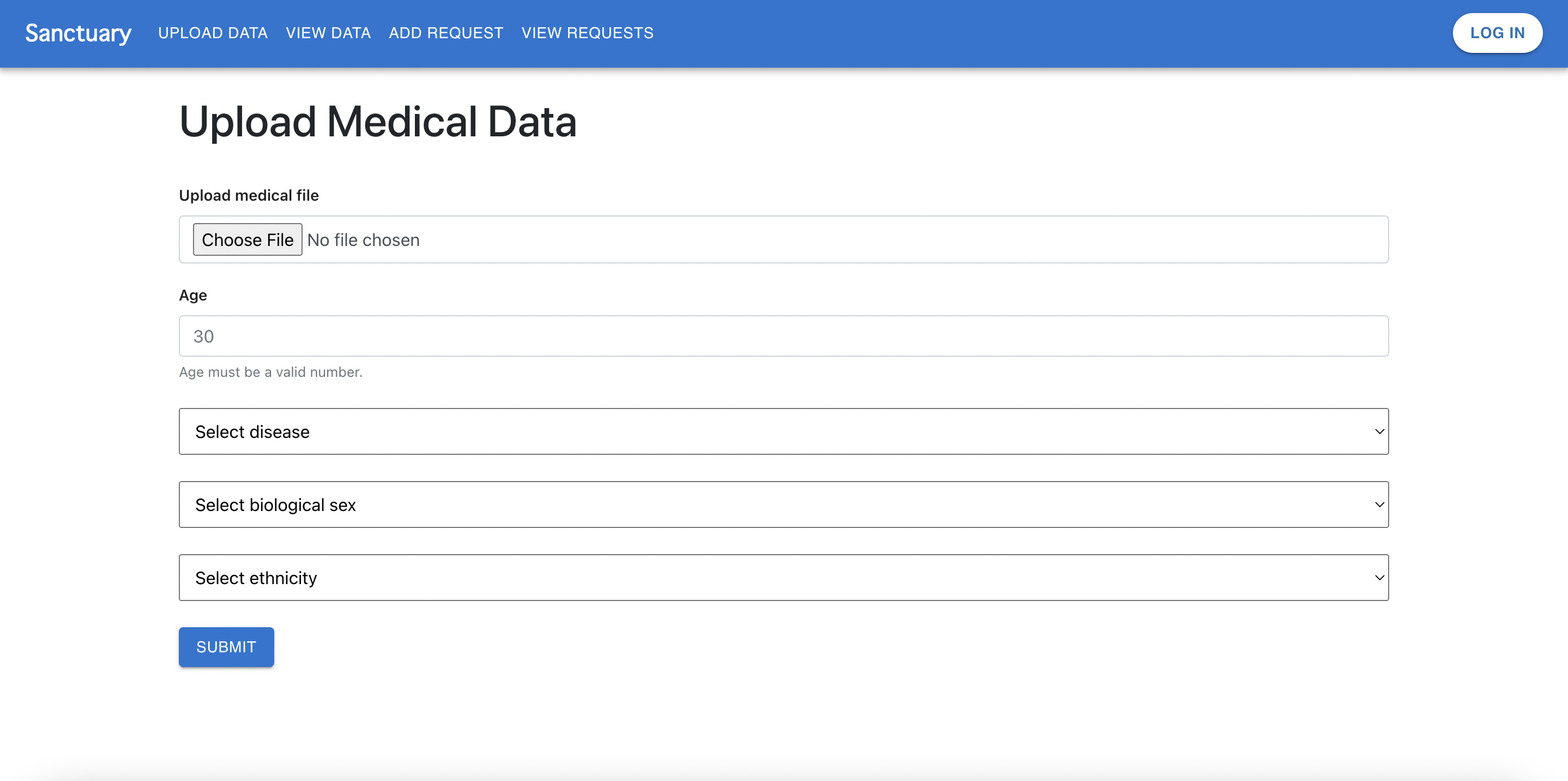
Sanctuary upload page.
-
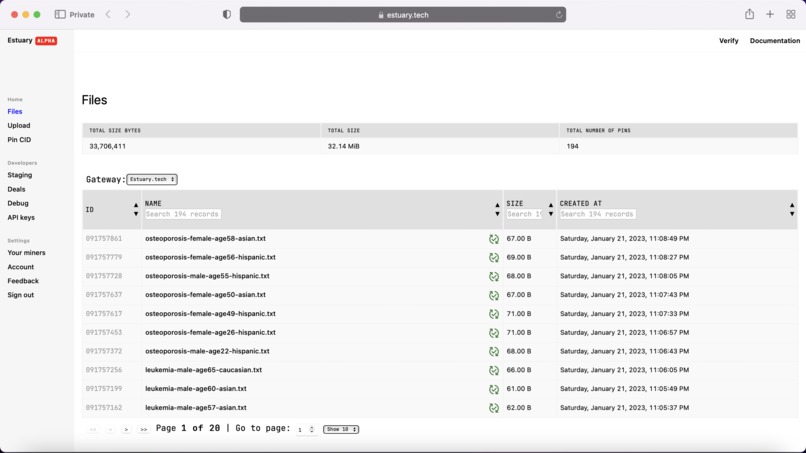
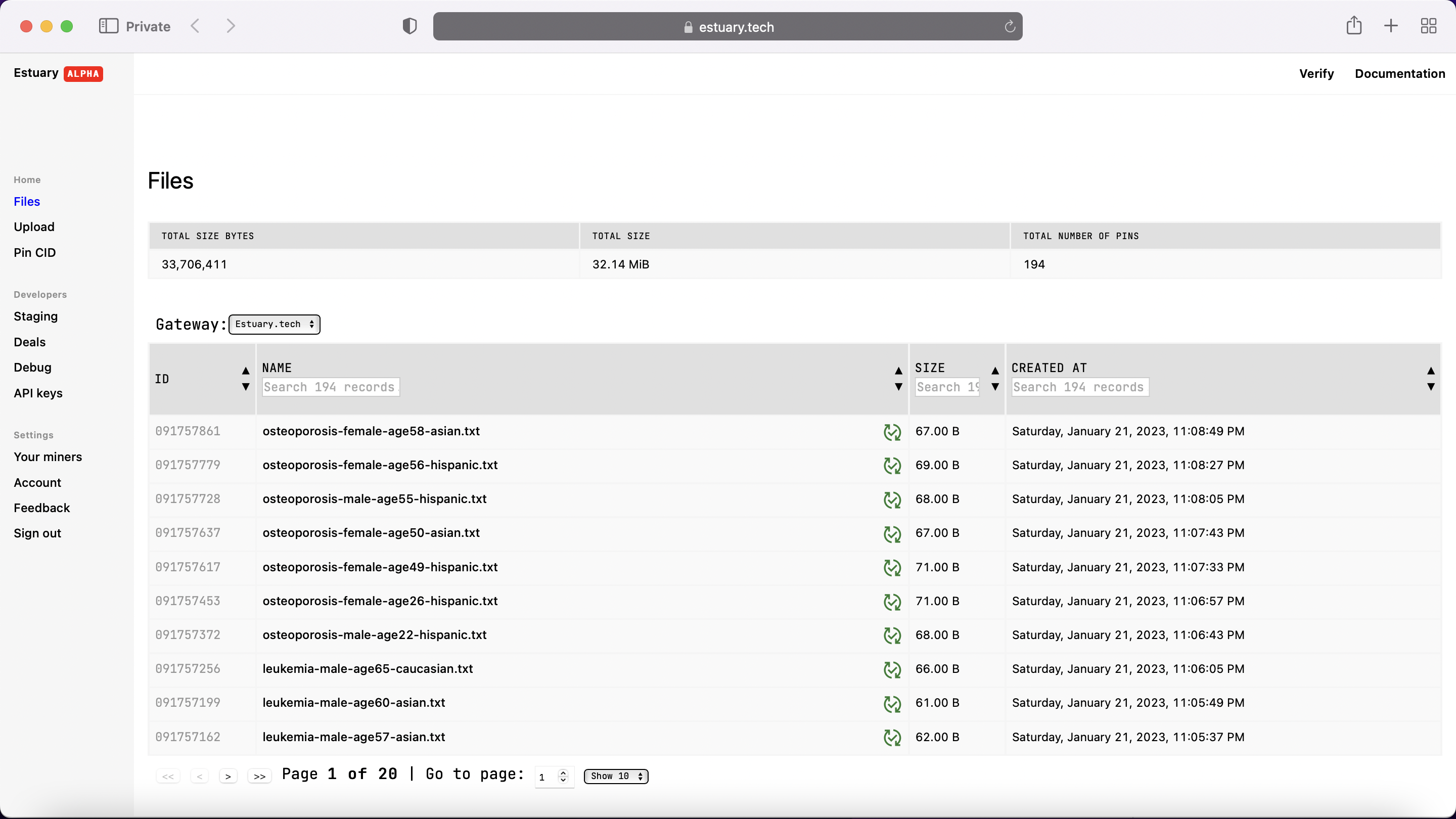
Example medical data stored in Estuary.
-
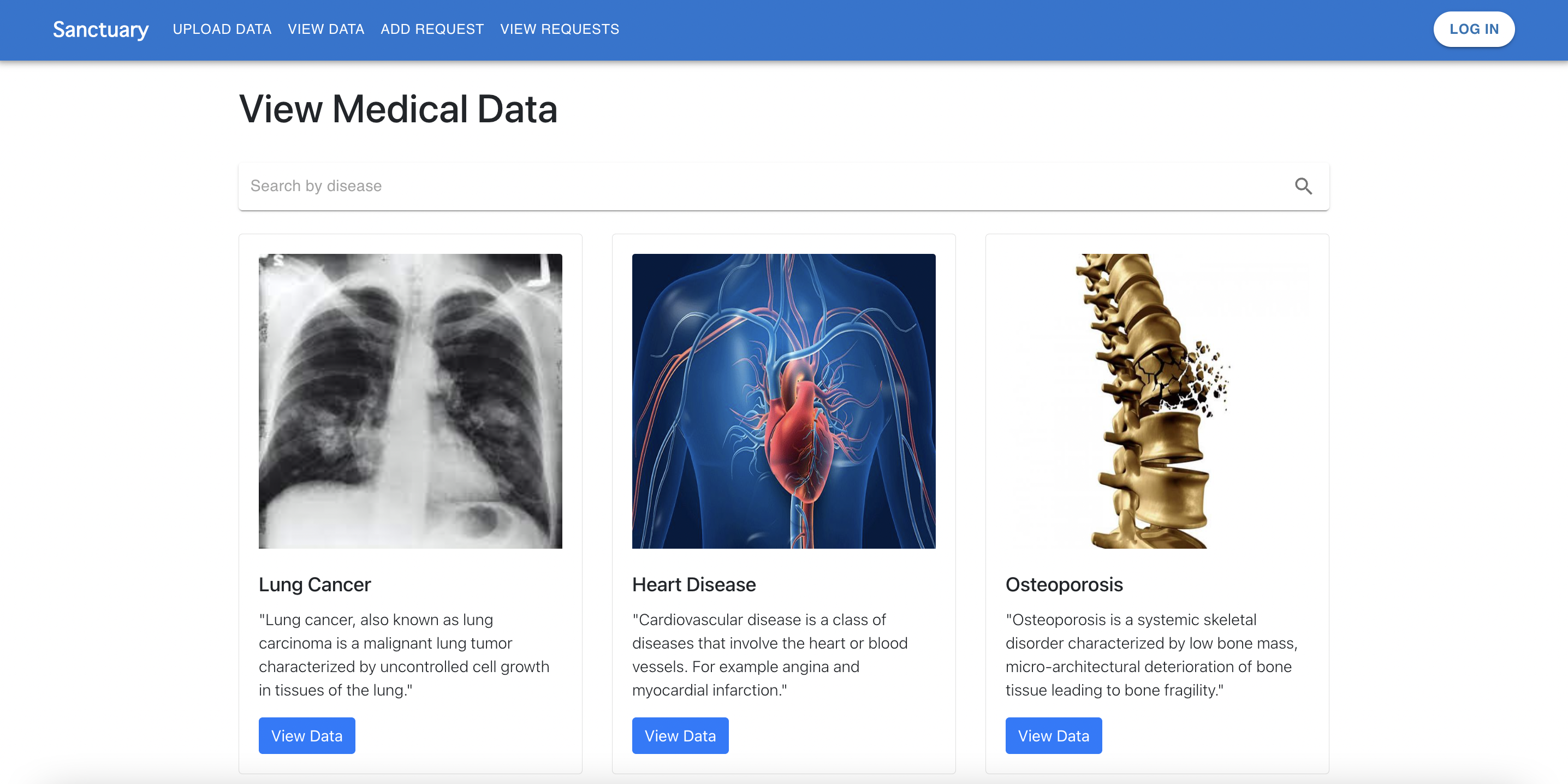
Sanctuary view page.
-
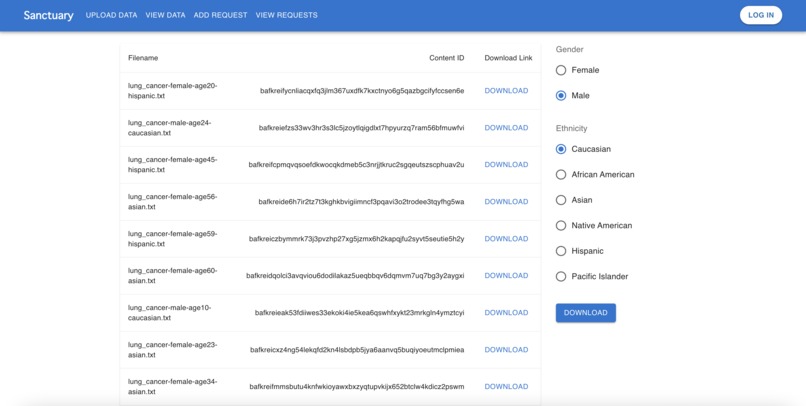
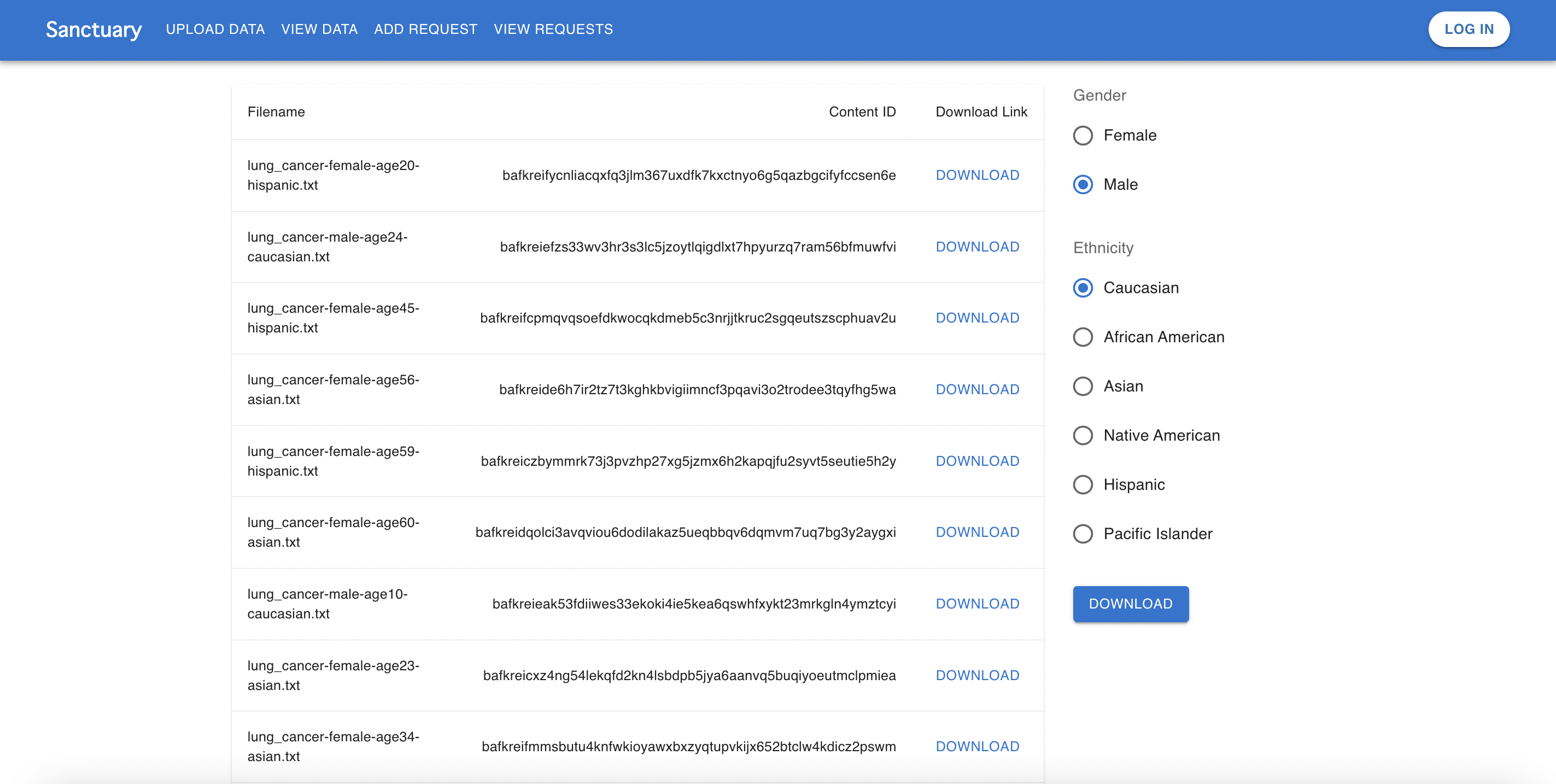
Sanctuary grid page.
-
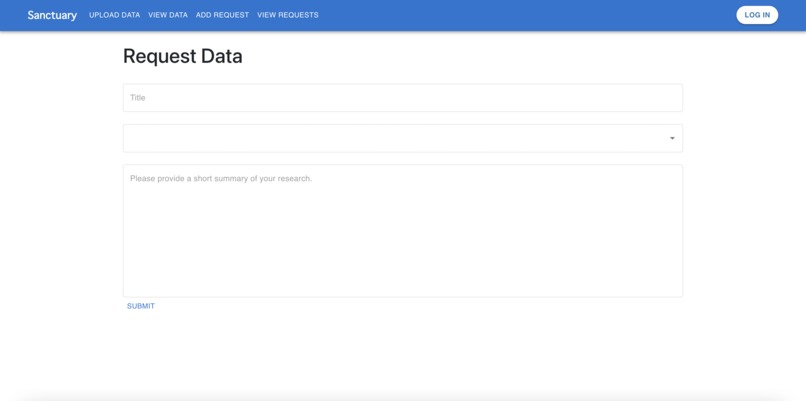
Sanctuary request edit page.
-
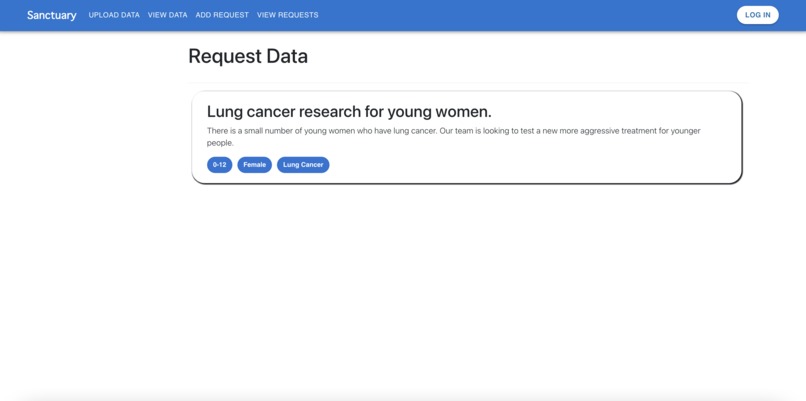
Sanctuary view request page.
Inspiration
We were inspired by two main issues with medical data today. The first issue is during the development of medicines and treatments, there is almost always an underrepresentation of data of various demographic groups. For example, “ProPublica found that in trials for 24 of the 31 cancer drugs approved in the past three years, less than 5 percent of the subjects were [people of colour. It is troubling because people of colour] have the highest death rate and shortest survival rate of any group in the United States for most cancers” source. The second issue with medical data today is that it is difficult to collect large scale datasets. Because healthcare providers collect information from patients and/or local volunteers, data is limited regionally and/or prone to loss through patients filling out paper forms source.
Our project resolves these two issues. (1) We allow users to retrieve specific datasets through the use of disease and demographic tags (e.g, “lung cancer”, “Asian”, “65 years old”). This way they can increase representation of various demographic groups in their dataset. We also have a feature for researchers to create a call for more data for specific tags. This way, the community can work together to upload more data for those tags. (2) We provide a means to actively “crowdsource” and collect data (data is always recent). All the collected data is stored digitally/permanently/securely through decentralization, and it can be accessed anytime.
What it does
Sanctuary is an interface to upload, retrieve, and analyze medical data that is stored on Estuary. Data is anonymous, and uploaded and retrieved with disease and demographic tags. Specific data uploads can be requested by researchers adding a call for data for specified tags. Sanctuary provides graphs and other visualization tools for users to analyze the medical information that they retrieved.
We envision our system being used internationally by healthcare workers (e.g., doctors, researchers). An example use case is a trial requiring data for rare disease X. A doctor in another country sees a patient with disease X and asks if the patient approves their anonymous data being uploaded for medical research. The data requested by a researcher and uploaded by a doctor is streamlined and simple.
How we built it
We built Sanctuary using the MERN (MongoDB, Express.js, React.js, Node.js) stack. Express and Node were used to create the backend API to interact with the Estuary API, and store our data on and retrieve our data from Estuary. The frontend was built with React and Bootstrap, with CSS styling.
Challenges we ran into
We ran into challenges with classification and preserving labels on our data when stored in Estuary. We used Estuary classification and set theory (intersection of classifications) to preserve all of the data’s labels. Another challenge that we had was working through designing our dashboard to display clean, simple, and interactive visuals to analyze the medical data.
Accomplishments that we're proud of
We are proud of our full integration of Estuary and leveraging decentralized data storage (Web3). We are also proud of our data visualization tools and simple UI design that provides users with a seamless experience to retrieve all the information/data that they desire.
What we learned
Through building Sanctuary, we learned about how to use Estuary, the benefits of decentralized storage of data, and how to build an end-to-end React/Bootstrap app from scratch.
What's next for Sanctuary
Using machine learning to recognize label variants is next for Sanctuary. For example, the labels “leukemia” and “blood cancer” should return the same data.








Log in or sign up for Devpost to join the conversation.