

Inspiration The inspiration for Sanctuary AI came from a critical observation of the current "Privacy-Performance Paradox" in HealthTech. While Large Language Models (LLMs) offer unprecedented support, their reliance on cloud processing creates a massive vulnerability. For individuals in high-security sectors, students, or those living in conflict zones, sharing intimate mental health data with a third-party server is a risk they cannot afford.
We wanted to build a "Sanctuary" — a place where the "delete" button actually works because the data never left the device. A tool that works in airplane mode, in a bunker, or in a remote area without Wi-Fi, providing clinical-grade support 24/7.
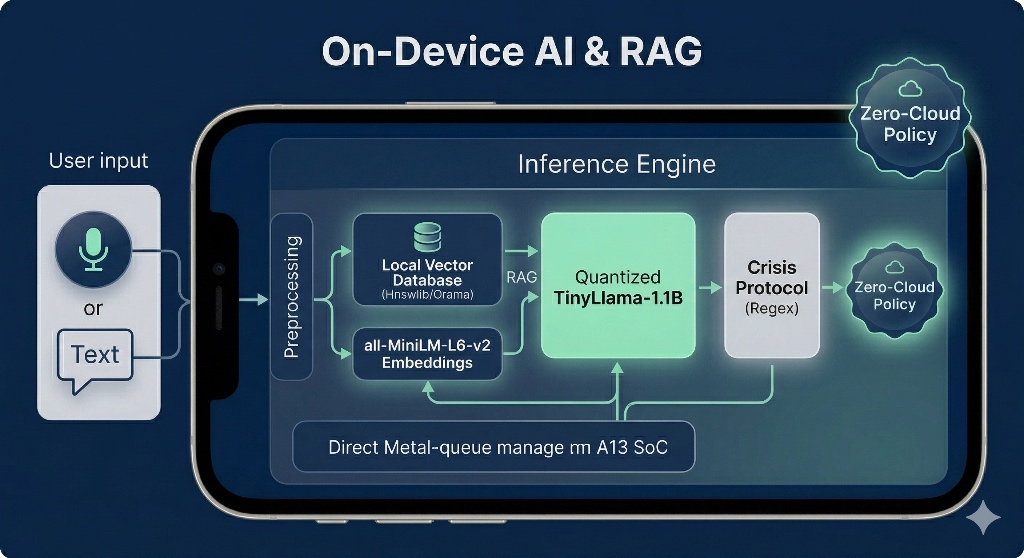
How we built it Building an LLM-powered therapist that runs on an iPhone 11 required a deep dive into Edge AI optimization.
Model Selection & Quantization: We utilized TinyLlama-1.1B, optimized through 4-bit quantization (GGUF) to reduce the footprint while maintaining perplexity.
Inference Engine: We integrated llama.cpp with the Metal API via Dart FFI to gain direct hardware access to the Apple A13 Bionic GPU.
Persistent Memory (RAG): To solve the "short memory" issue of small models, we implemented a local Vector Database. Each session is converted into embeddings on-device, allowing the AI to reference user history from months ago without cloud syncing.
Clinical Logic: We didn't just build a chat-bot; we built a system that follows CBT (Cognitive Behavioral Therapy) decision trees to ensure safety and prevent hallucinations.
What we learned This project was a masterclass in resource management. We learned that "Desktop-class AI" is no longer a privilege of high-end GPUs. By understanding low-level memory mapping (mmap) and GPU queue management, we can deliver sophisticated AI experiences on everyday mobile hardware. We also learned that in mental health tech, transparency is the ultimate feature.
Challenges we faced The biggest technical hurdle was the "Battle for RAM." The iOS Jetsam limit on an iPhone 11 is roughly 2.5 GB. If the app exceeds this, the OS kills it instantly.
The Solution: We implemented Lazy Initialization and Inference Cooldown logic to keep our peak usage under 2.2 GB.
Thermal Throttling: Running heavy GPU tasks on a phone leads to heat. We had to balance the token generation speed (~15-20 t/s) with power consumption to ensure the device stays cool during long therapeutic sessions.


Log in or sign up for Devpost to join the conversation.