-
-
Sanare MCP server called as a tool inside Prompt Opinion's agent platform
-
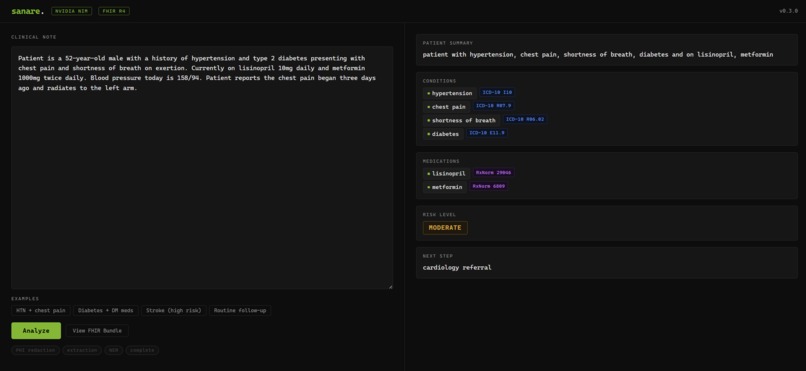
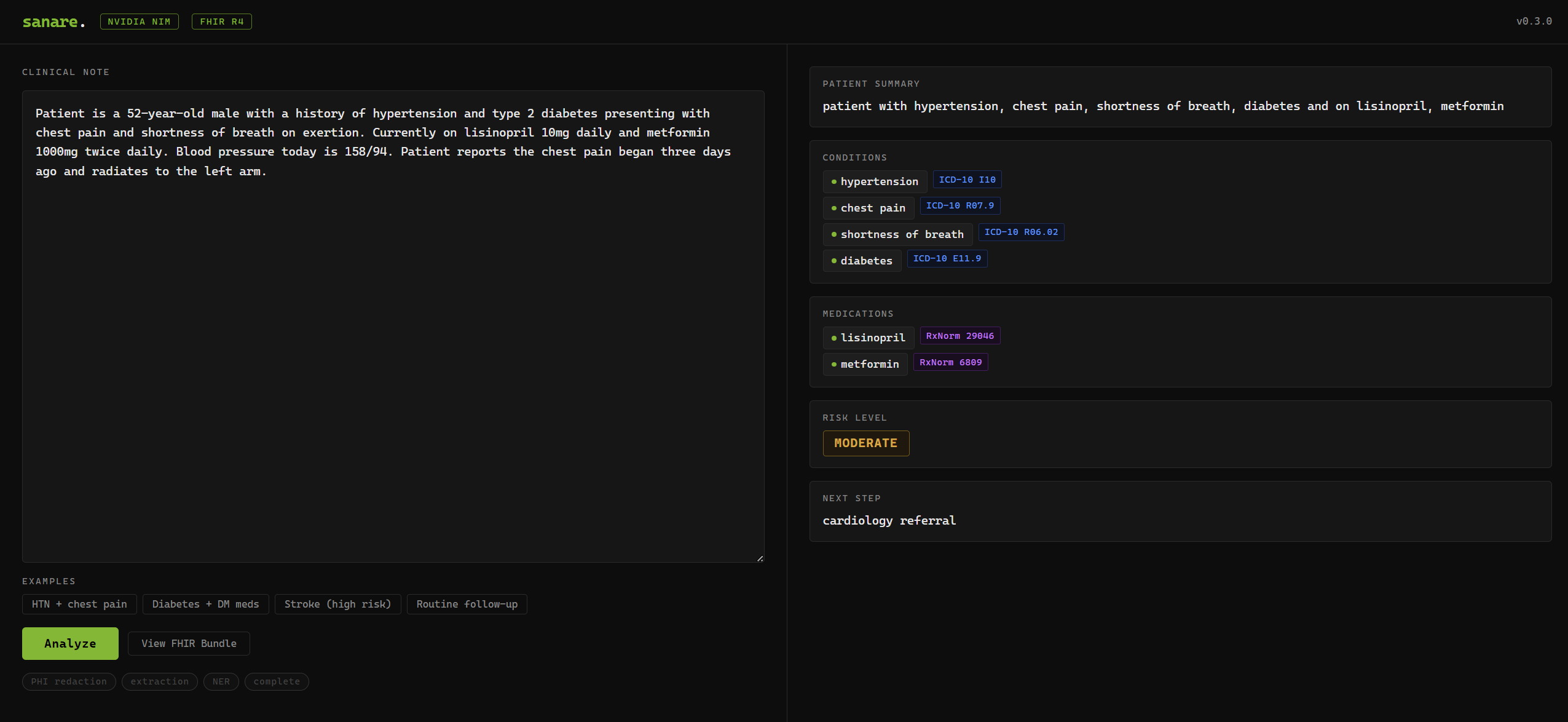
Sanare streaming UI — live clinical note extraction with ICD-10 codes, risk level, and FHIR output
Inspiration
Every day, clinicians spend hours re-entering information that already exists, buried in free-text notes. A doctor writes "68F HTN chest pain on lisinopril SOB exertion" and somewhere downstream, a human has to read that, interpret it, and manually enter hypertension, chest pain, shortness of breath, and lisinopril into a structured system. That gap, between what clinicians write and what EHR systems can read, is where patient data gets lost, billing gets delayed, and care coordination breaks down.
The Agents Assemble hackathon framed this perfectly: the "last mile" problem. Raw intelligence exists. The infrastructure to deliver it into real clinical workflows does not. Sanare is our attempt to close that gap.
What It Does
Sanare is a clinical NLP MCP server that takes any unstructured clinical note and returns:
- Extracted conditions mapped to real ICD-10-CM codes via the NLM Clinical Tables API
- Medications mapped to RxNorm codes via the NLM RxNav API
- Patient risk level (low / moderate / high) with a recommended next step
- A FHIR R4 Bundle (Patient, Condition, Observation, MedicationStatement) ready for EHR ingestion
- PHI redaction — names, MRNs, SSNs stripped before any AI sees the note
When connected through Prompt Opinion's FHIR extension, Sanare automatically receives the patient's existing conditions and medications from the live EHR session and uses them to enrich the extraction. No manual context passing required.
How We Built It
The stack is deliberately layered so each component adds something the one below it cannot do alone:
- PHI de-identification runs first, before the note touches any external API
- NVIDIA NIM (meta/llama-3.1-8b-instruct) performs structured JSON extraction with constrained output schema
- A biomedical NER model (d4data/biomedical-ner-all) independently validates extractions and scores confidence. Hybrid agreement between LLM and NER gets the highest confidence rating.
- Real NLM API lookups (RxNorm + ICD-10-CM) replace any hardcoded terminology dictionaries
- FHIR R4 mapping converts the structured output into a standards-compliant bundle
- The whole pipeline is exposed as an MCP server via FastMCP, mounted inside a FastAPI app that also serves a streaming demo UI
The streaming UI was important to us. We wanted the extraction to feel live, showing PHI being redacted, tokens streaming from the model in real time, then fields appearing one by one with ICD-10 chips and grounding indicators.
Challenges
The SHARP integration was the hardest part. Prompt Opinion's FHIR extension requires declaring custom capabilities in the MCP initialize response, something FastMCP does not expose directly. We ended up patching get_capabilities on the underlying MCP server to inject the ai.promptopinion/fhir-context extension, and using FastMCP's internal _current_http_request ContextVar to read the FHIR headers (X-Patient-ID, X-FHIR-Server-URL, X-FHIR-Access-Token) automatically at tool call time.
Mounting FastMCP inside FastAPI was also non-trivial. FastMCP's HTTP transport has its own lifespan manager that must be initialized before any requests arrive. Mounting it as a sub-app initially failed with a 500 because FastAPI's lifespan was not wired to FastMCP's. The fix was passing lifespan=mcp_asgi.lifespan to the FastAPI constructor.
Eval quality was a recurring challenge. It is easy to build an eval suite that passes because you evaluated against the same heuristic you used to generate expected outputs. We caught this early and replaced the circular eval with three independent layers: a heuristic consistency test, 30 independently authored clinical cases, and 148 cases derived from real MTSamples clinical transcriptions.
What We Learned
Building on open standards (MCP, FHIR R4, SMART scopes) forces good architecture. Because everything has to serialize to JSON and conform to a schema, you cannot hide complexity. It either works end-to-end or it does not. That constraint made Sanare better than it would have been if we had built it as a closed API.
What's next for Sanare
Next, we want to move Sanare from a working MCP prototype toward a production-ready clinical integration layer.
Our first priority is expanding evaluation quality. We are scaling the test set from hundreds of examples to 5,000+ clinical cases across specialties, note styles, abbreviations, and edge cases. The goal is not just to improve extraction accuracy, but to measure when Sanare should abstain, flag uncertainty, or require clinician review. In healthcare, a confident false positive can be just as harmful as a missed extraction.
We also want deeper EHR interoperability. Sanare already produces FHIR R4 Bundles and can consume live patient context through Prompt Opinion's FHIR extension. Next, we want to support fuller SMART-on-FHIR workflows: reconciling new findings against existing Conditions and MedicationStatements, generating draft chart updates, and letting clinicians approve changes before anything is written back.
Another focus is explainability. Every extracted condition, medication, code, and risk score should include evidence from the original note, the source used to validate it, and the confidence signal behind it. Clinicians should be able to see exactly why Sanare selected an ICD-10-CM or RxNorm mapping without digging through logs.
Long term, we want Sanare to become reusable infrastructure for healthcare agents. Any clinical AI workflow should be able to call Sanare, receive clean FHIR-ready data, and continue safely without rebuilding PHI redaction, medical coding, context retrieval, or EHR mapping from scratch.
The vision is simple: clinicians should write naturally, systems should understand safely, and critical patient information should not stay trapped in free text.

Log in or sign up for Devpost to join the conversation.