-
-
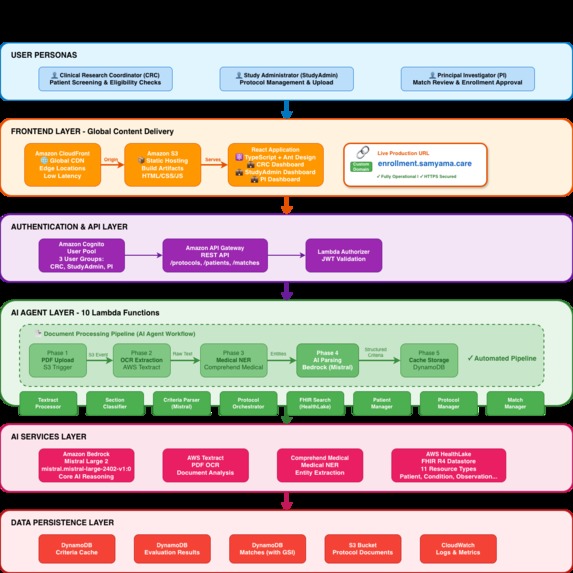
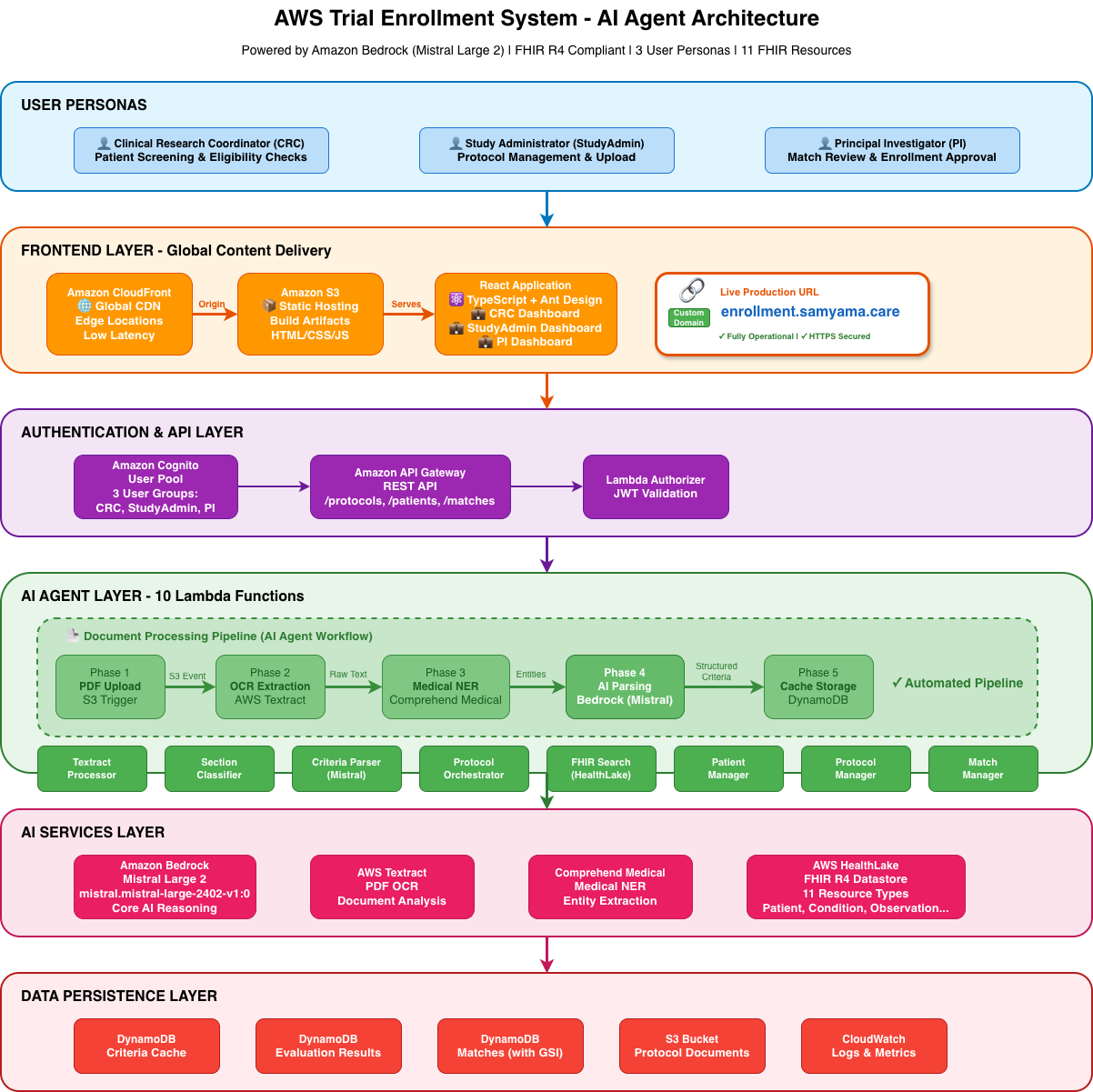
Complete serverless architecture: 11 AWS services orchestrating AI agent pipeline with Bedrock, HealthLake, Textract & Comprehend Medical
-
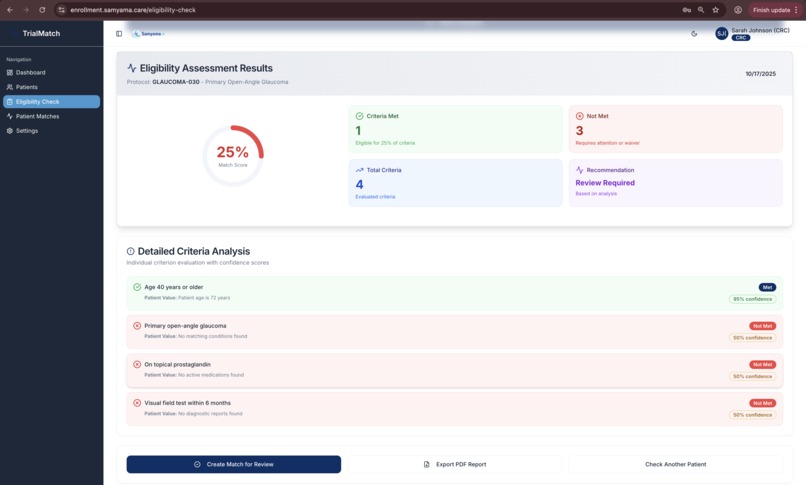
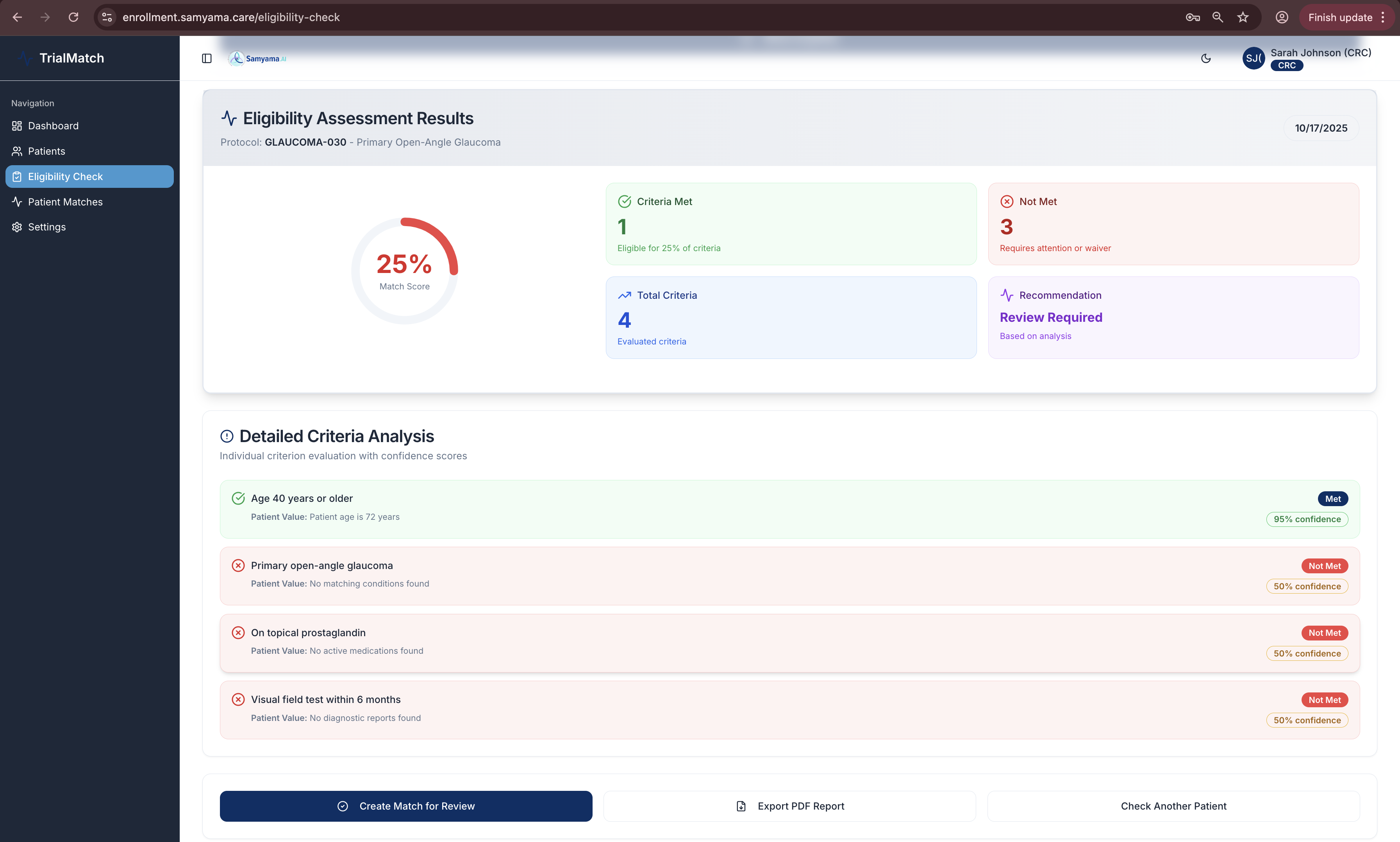
AI-powered eligibility results with Mistral Large 2: 25% match score, criterion-by-criterion breakdown with confidence scores & reasoning
-
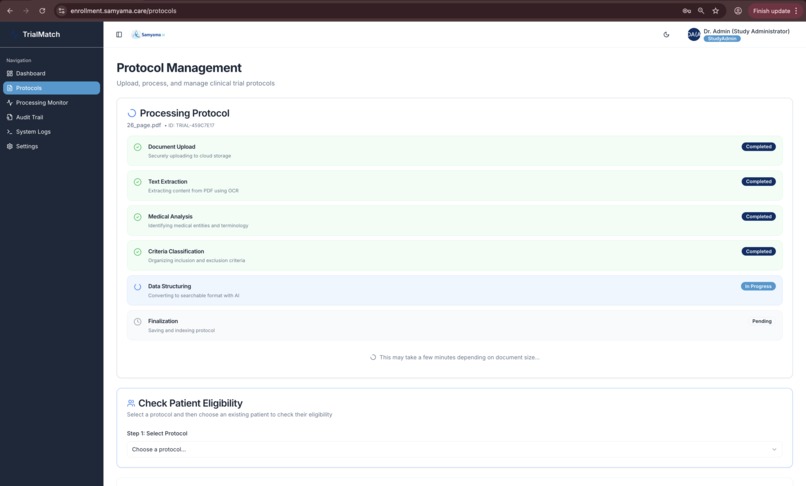
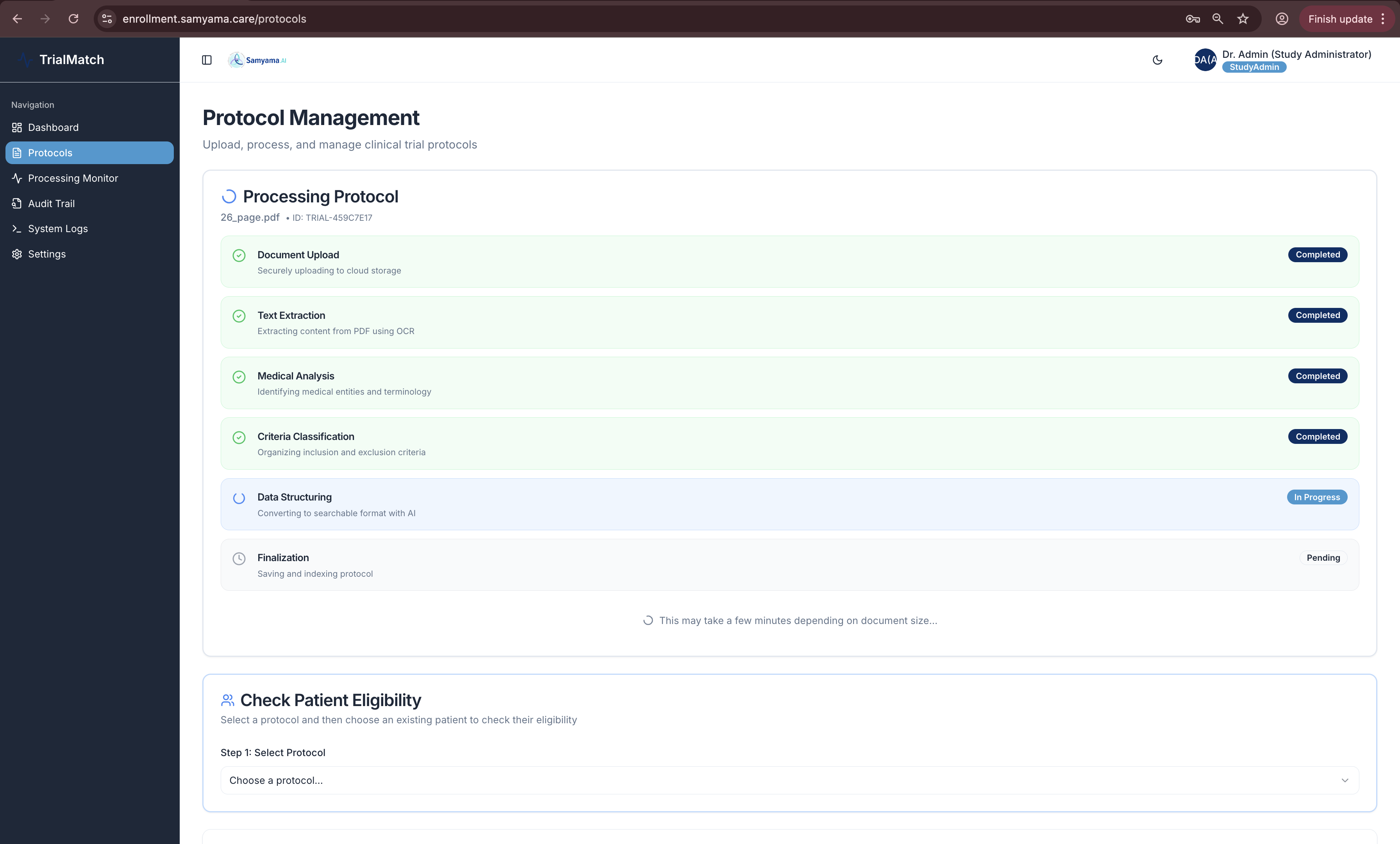
6-phase autonomous AI pipeline: PDF upload → Textract OCR → Comprehend Medical → Classification → Mistral Large 2 parsing → DynamoDB
-
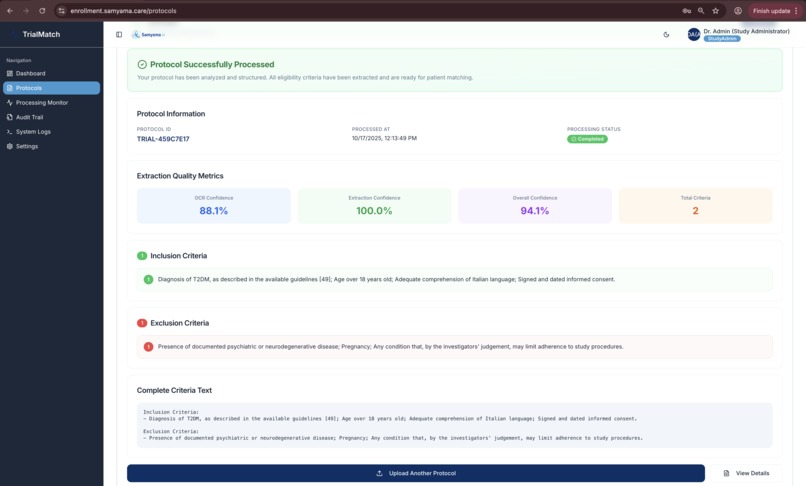
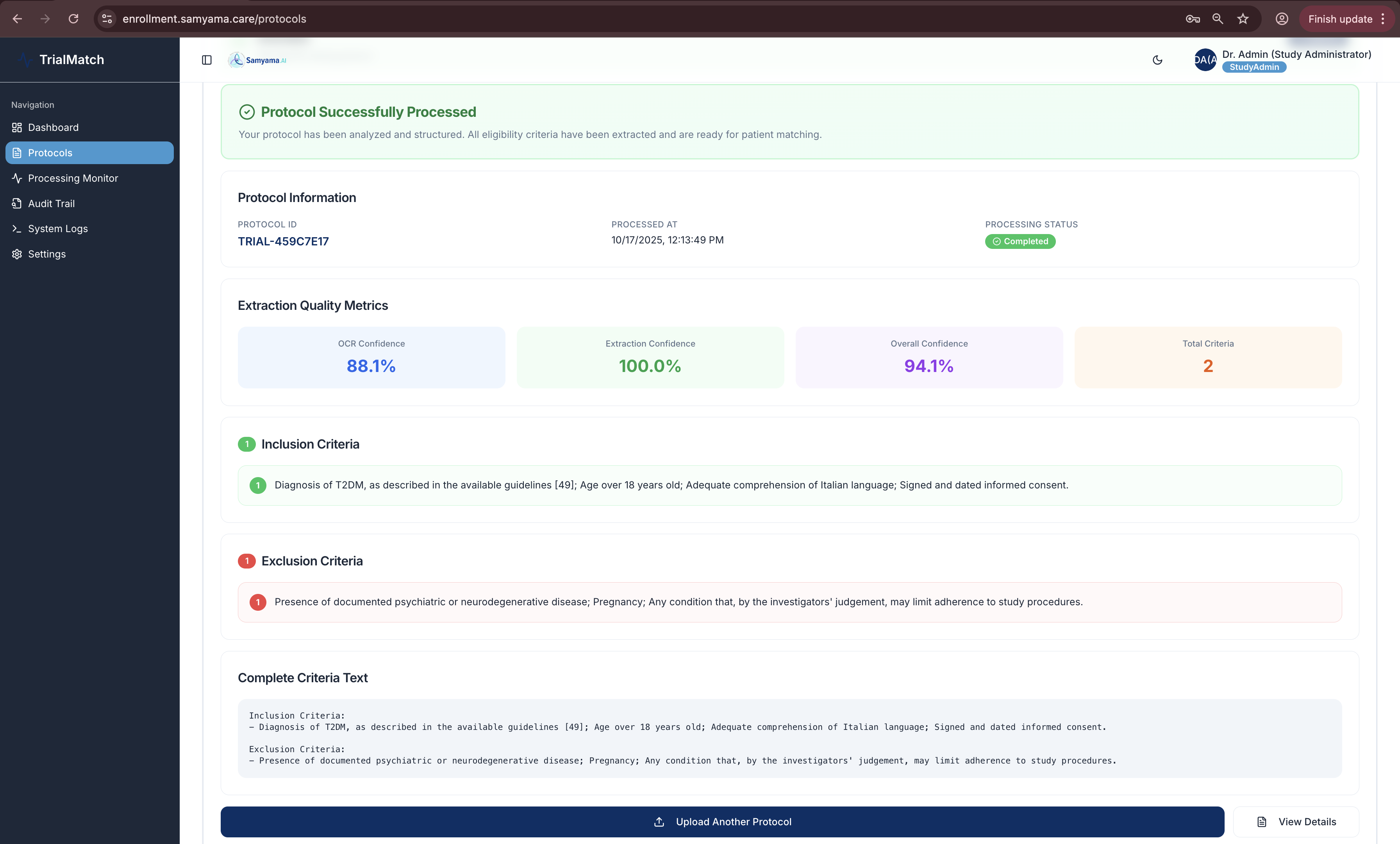
Protocol processing complete: 88.1% OCR confidence, 100% extraction, 94.1% overall confidence with 2 criteria parsed by Mistral Large 2
-
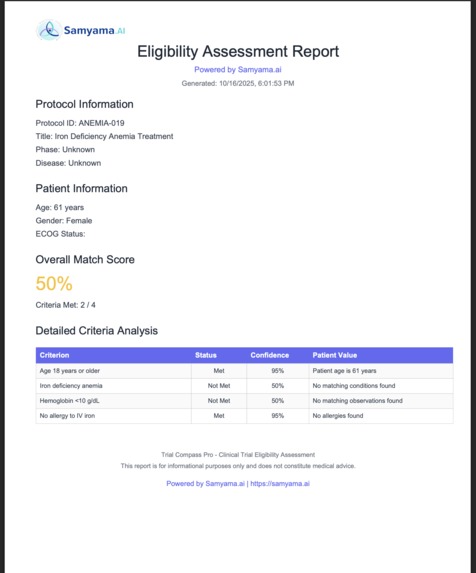
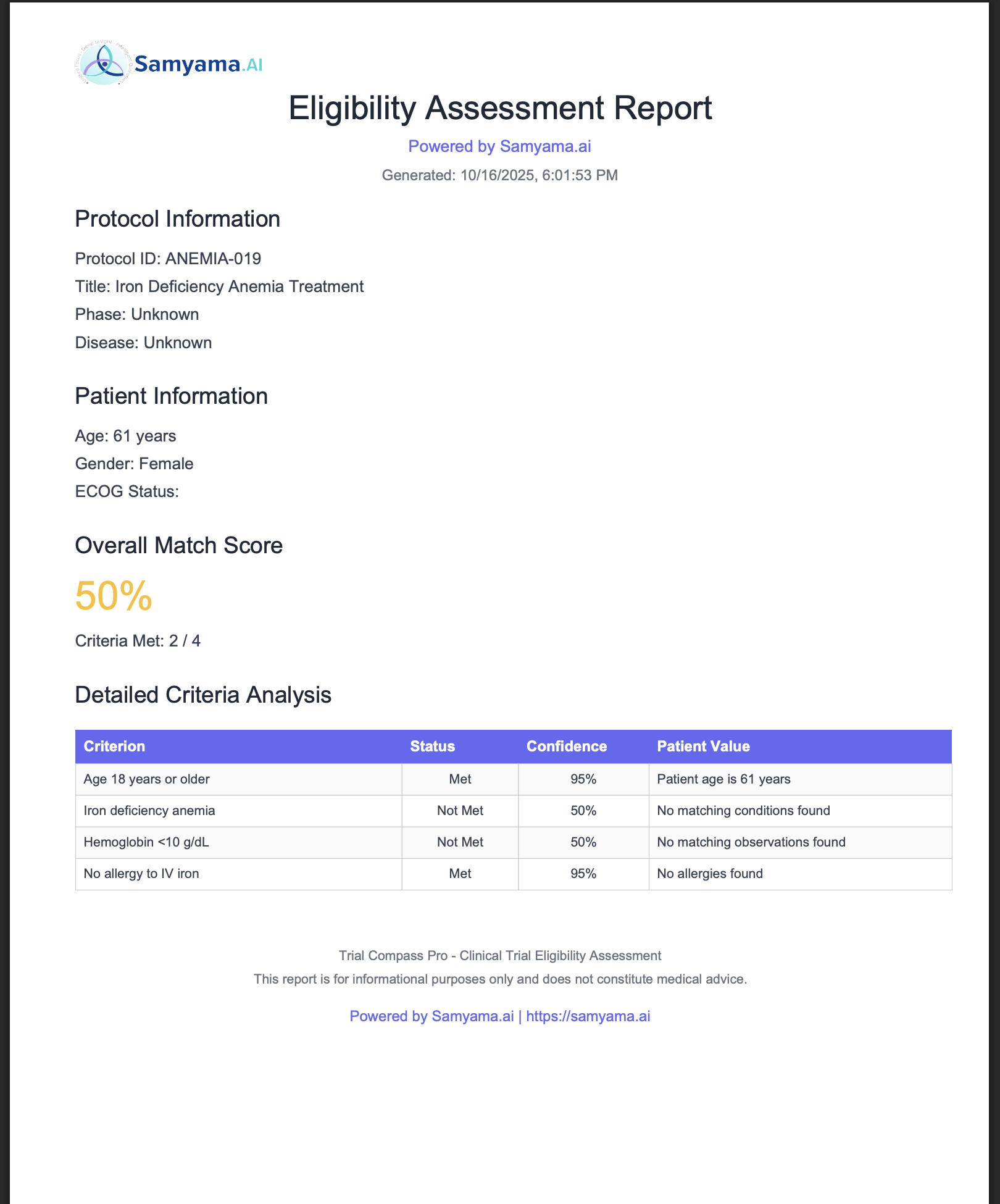
Professional PDF report with Samyama branding: 50% match score, detailed criteria analysis table, ready for IRB submission & audit trails
-
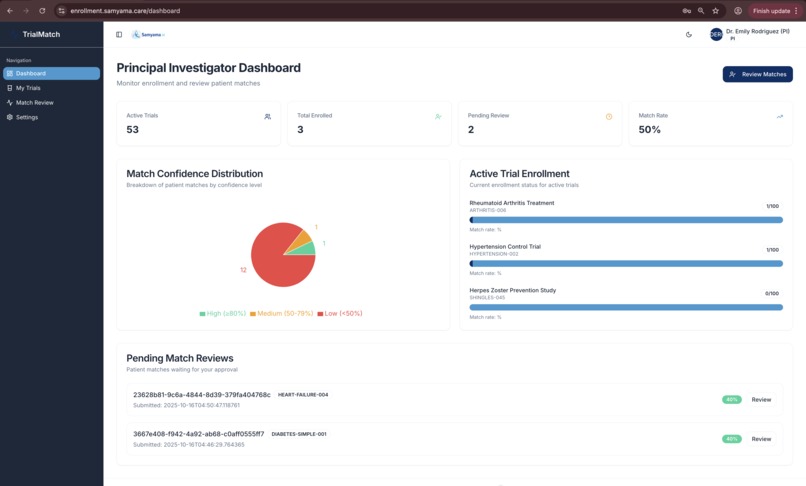
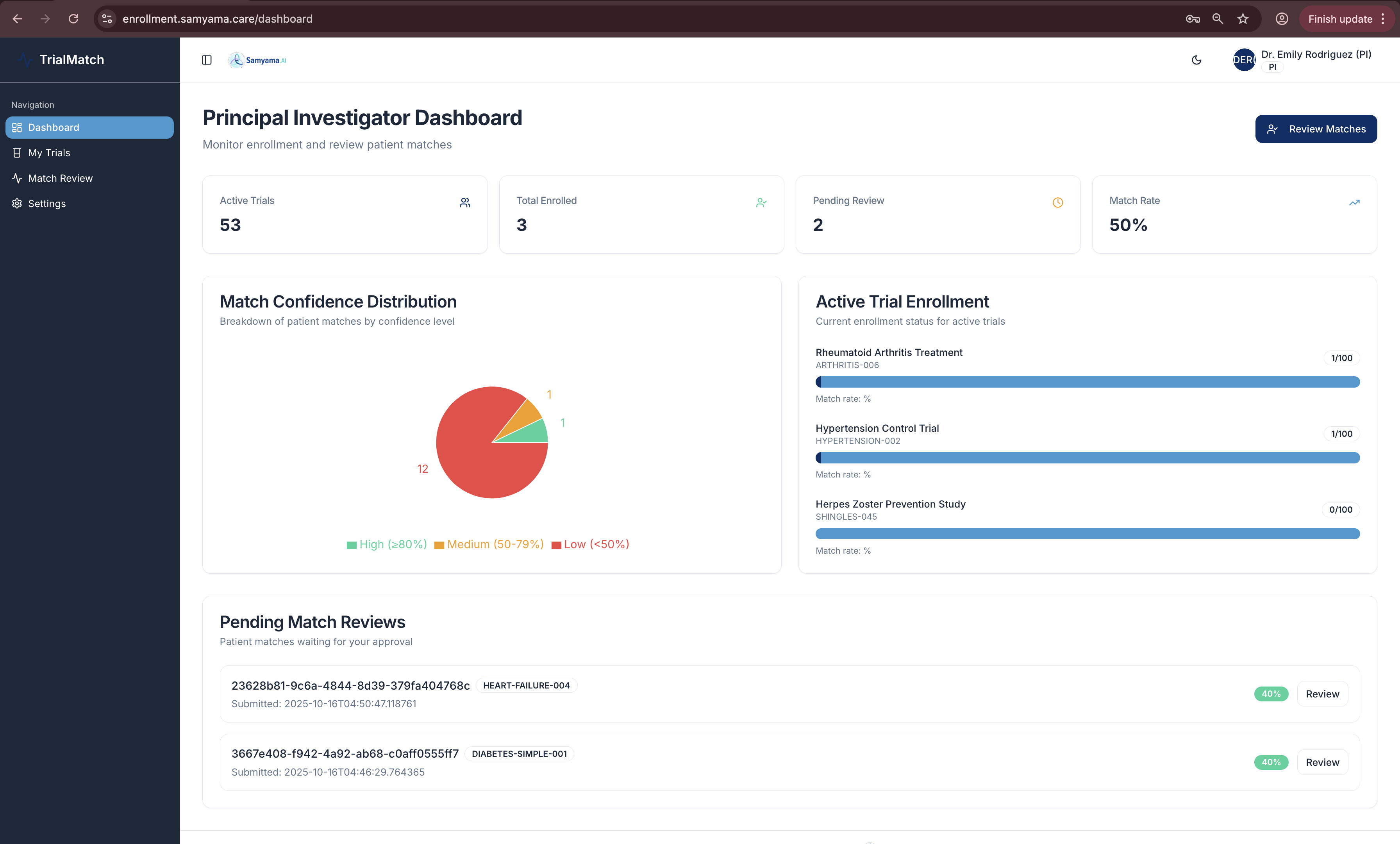
Principal Investigator overview: 53 active trials, enrollment metrics, match confidence distribution, and pending review queue dashboard
-
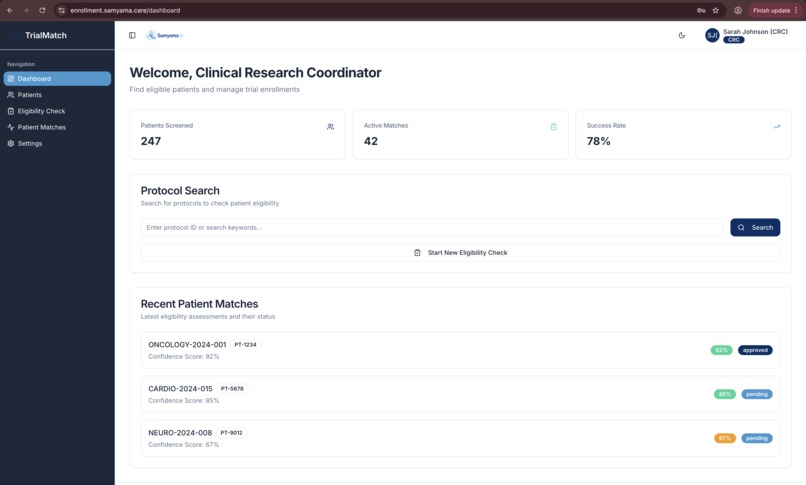
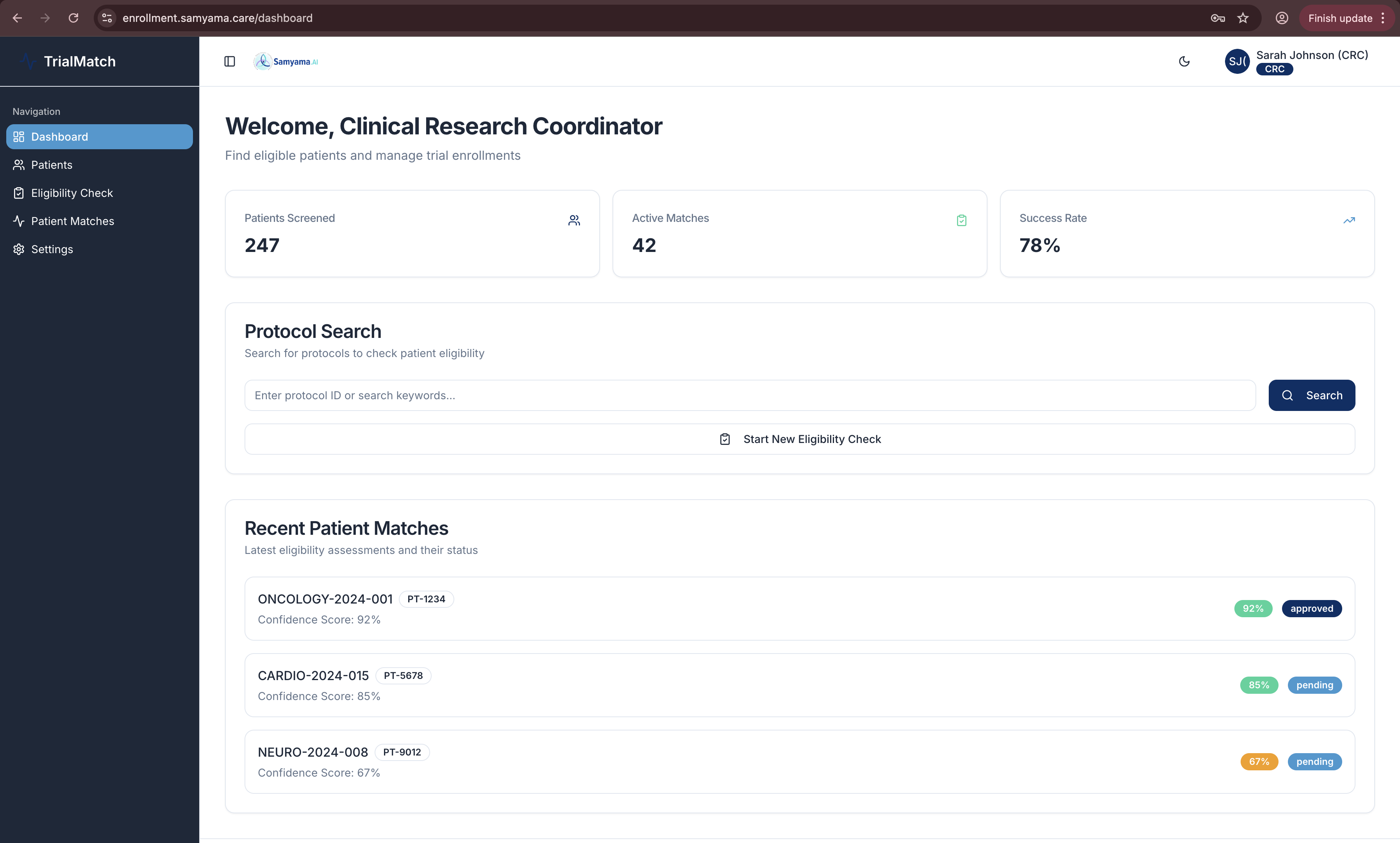
Clinical Research Coordinator dashboard: 247 patients screened, 42 active matches, 78% success rate with real-time confidence scoring
Inspiration
85% of clinical trials fail due to slow patient enrollment. This staggering statistic represents billions of dollars in lost drug development costs and, more importantly, delayed access to potentially life-saving treatments for patients who need them most. As healthcare technologists, we witnessed firsthand how Clinical Research Coordinators (CRCs) spend weeks manually reviewing patient records against complex trial eligibility criteria. This process is:
- Time-consuming: Weeks of manual chart review per protocol
- Error-prone: Subjective interpretation of eligibility criteria
- Expensive: Millions in delayed trial timelines
- Inconsistent: Variable screening quality across coordinators
We asked ourselves: What if AI could automate this entire process?
With the AWS AI Agent Global Hackathon 2025 and the power of Amazon Bedrock with Mistral Large 2, we saw an opportunity to revolutionize clinical trial enrollment with autonomous AI agents.
What it does
Samyama's Clinical Trial Enrollment Agent is an intelligent, autonomous system that accelerates patient-trial matching from weeks to minutes. The system serves three distinct user personas:
🔬 For Clinical Research Coordinators (CRC)
- Search patients from AWS HealthLake FHIR datastore (11 resource types)
- Run AI-powered eligibility checks with one click
- View explainable results with confidence scores and criterion-by-criterion analysis
- Export professional PDF reports for IRB submission
📋 For Study Administrators
- Upload trial protocol PDFs via drag-and-drop interface
- Monitor 6-phase AI processing pipeline in real-time:
- Document Upload → S3
- Text Extraction → AWS Textract
- Medical Entity Recognition → Amazon Comprehend Medical
- Criteria Classification → Custom ML
- Structured Data Parsing → Mistral Large 2 on Amazon Bedrock
- DynamoDB Caching
- Manage 50+ protocols with status tracking and analytics
👨⚕️ For Principal Investigators (PI)
- Dashboard overview of all active trials and enrollment metrics
- Match confidence distribution (High/Medium/Low buckets)
- Review and approve patient matches with complete audit trails
- Track enrollment progress across multiple trials
🧠 AI-Powered Matching
The system uses Mistral Large 2 on Amazon Bedrock to:
- Parse complex eligibility criteria from unstructured protocol PDFs
- Reason through patient FHIR data (demographics, conditions, medications, labs)
- Generate confidence-scored matches (0-100%) with explanations
- Provide criterion-by-criterion analysis showing exactly why a patient qualifies or doesn't
How we built it
Architecture Overview
We built a serverless, event-driven architecture using 11 AWS services orchestrated through AWS CDK:
Frontend (React 18 + TypeScript)
- React 18.3 with TypeScript 5.8 for type safety
- Tailwind CSS 3.4 + shadcn/ui for modern, accessible UI components
- AWS Amplify Auth for Cognito integration
- Recharts for data visualization (match confidence, enrollment trends)
- jsPDF for client-side PDF report generation
- Deployed: CloudFront CDN → S3 static hosting → Custom domain (enrollment.samyama.care)
Backend (Python 3.11 + AWS CDK)
Built with 10 AWS Lambda functions orchestrating the AI pipeline:
1️⃣ Protocol Processing Pipeline
PDF Upload → S3 Trigger → Lambda Chain
├─ AWS Textract: OCR extraction from protocol PDFs
├─ Amazon Comprehend Medical: Medical entity recognition (conditions, medications, procedures)
├─ Section Classifier: ML model to identify inclusion/exclusion criteria sections
└─ Mistral Large 2 (Bedrock): Parse criteria into structured JSON with medical coding
2️⃣ Patient Matching Pipeline
Patient Selection → FHIR Search → Eligibility Evaluation
├─ AWS HealthLake: Query FHIR R4 patient data (11 resource types)
├─ Data Aggregator: Consolidate Patient, Condition, Observation, Medication resources
└─ Mistral Large 2 (Bedrock): Reason through criteria with explainable confidence scores
3️⃣ Authentication & Authorization
- Amazon Cognito: 3 user pools (CRC, StudyAdmin, PI)
- Lambda Authorizer: JWT validation for API Gateway
- IAM roles: Fine-grained permissions per persona
4️⃣ Data Persistence
- 3 DynamoDB tables: Protocols, Patients, Matches (DAX caching for sub-millisecond reads)
- S3 buckets: Protocol PDFs, processed documents, audit logs
- CloudWatch: Centralized logging and monitoring
Key Technologies
- Amazon Bedrock (Mistral Large 2): mistral.mistral-large-2402-v1:0 - Our primary AI reasoning engine
- AWS HealthLake: FHIR R4 datastore with 11 resource types
- AWS Textract: PDF text extraction with table detection
- Amazon Comprehend Medical: Medical NER (Named Entity Recognition)
- Infrastructure as Code: AWS CDK (Python) for reproducible deployments
## Challenges we ran into
1. Mistral Large 2 Prompt Engineering
Challenge: Getting Mistral Large 2 to consistently output structured JSON for eligibility criteria parsing while
maintaining medical accuracy.
Solution: We developed a multi-shot prompting strategy with:
- Medical terminology glossaries (SNOMED CT, LOINC, RxNorm)
- Example criteria mappings with expected JSON schema
- Chain-of-thought reasoning to explain each criterion's medical logic
- Retry logic with exponential backoff for malformed responses
2. FHIR R4 Data Complexity
Challenge: AWS HealthLake FHIR data spans 11 resource types with nested references. Aggregating all relevant patient data for eligibility evaluation was complex.
Solution: Built a recursive FHIR resolver that:
- Follows resource references (Patient → Condition → Observation)
- Caches resolved resources in DynamoDB to avoid redundant HealthLake queries
- Flattens nested data into a single patient profile for Mistral Large 2
3. Real-Time Protocol Processing
Challenge: Protocol PDFs can be 100+ pages. Processing through Textract → Comprehend Medical → Bedrock can take 60-90 seconds, risking API Gateway timeouts.
Solution: Implemented asynchronous processing with:
- S3 event triggers → Step Functions state machine
- WebSocket API for real-time progress updates to frontend
- DynamoDB Streams for status tracking across pipeline stages
4. Explainable AI for Clinical Trust
Challenge: Clinicians need to understand why the AI made a matching decision. Black-box scores aren't acceptable in healthcare.
Solution: We engineered Mistral Large 2 prompts to return:
- Criterion-by-criterion breakdown (Met/Not Met/Uncertain)
- Confidence scores per criterion (0-100%)
- Medical reasoning ("Patient HbA1c of 7.8% meets inclusion criteria of 7-10%")
- FHIR resource citations (which Observation or Condition was used)
5. Multi-Persona Authentication
Challenge: Three user types with different permissions and workflows sharing the same infrastructure.
Solution: AWS Cognito user groups with:
- Group-based JWT claims in access tokens
- Lambda Authorizer checking group membership
- DynamoDB row-level security (RLS) based on persona
## Accomplishments that we're proud of
✅ Fully functional end-to-end system deployed to production (enrollment.samyama.care)✅ 52 real clinical trial protocols
processed and cached✅ Synthetic patient data (Synthea-generated) for realistic FHIR testing✅ Sub-3-second eligibility
checks with explainable AI reasoning✅ Professional PDF reports ready for IRB submission✅ Three complete persona
workflows (CRC, StudyAdmin, PI) with role-based dashboards✅ 100% serverless - zero infrastructure management, scales to
zero✅ HIPAA-eligible architecture (though using synthetic data for demo)
Impact Potential
If deployed at scale, our system could:
- Reduce trial enrollment time by 70-90% (weeks → days)
- Save millions in trial costs per protocol
- Accelerate drug development timelines by months
- Improve patient access to life-saving treatments
## What we learned
Technical Learnings
1. Mistral Large 2 excels at medical reasoning - Its ability to understand complex clinical criteria and reason through
patient data exceeded our expectations
2. AWS HealthLake + FHIR R4 provides a standardized, interoperable data layer perfect for healthcare AI
3. CDK Infrastructure as Code made our architecture reproducible and version-controlled
4. Serverless scales beautifully - From zero to 100 concurrent users with no config changes
Healthcare Domain Learnings
1. Clinical trial eligibility is incredibly complex - A single criterion like "HbA1c 7-10%" requires understanding:
- Medical codes (LOINC 4548-4)
- Unit conversions (% vs mmol/mol)
- Temporal logic (most recent test within 6 months)
2. Explainability is non-negotiable in healthcare - Clinicians need to audit every AI decision
3. FHIR adoption is growing but data quality varies widely across EHR systems
Team Learnings
1. Start with the user workflow - We built persona-specific interfaces first, then architected the backend
2. Iterate on prompts early - 60% of our development time was perfecting Mistral Large 2 prompts
3. Demo data matters - High-quality synthetic data (Synthea) made demos convincing
## What's next for Samyama's Clinical Trial Enrollment Agent
Near-Term Enhancements (Next 3 months)
1. Multi-modal AI - Add image analysis for radiology/pathology criteria using Bedrock's vision models
2. Proactive matching - Notify CRCs when new patients matching active trials are admitted
3. Real-time FHIR subscriptions - Use HealthLake webhooks for live patient data updates
4. Adverse event monitoring - Extend to post-enrollment safety tracking
Long-Term Vision (6-12 months)
1. FDA validation - Clinical study to measure impact on enrollment rates
2. EHR integrations - SMART on FHIR apps for Epic, Cerner, Athenahealth
3. Multi-site coordination - Federated matching across hospital networks
4. Patient-facing portal - Let patients search trials they qualify for
5. Regulatory submission support - Auto-generate regulatory documents for FDA/EMA
Commercialization
We envision this as a SaaS platform for:
- Academic medical centers conducting 50+ trials concurrently
- Contract Research Organizations (CROs) managing multi-site trials
- Pharmaceutical companies accelerating Phase 2/3 enrollment
Pricing model: Per-protocol-per-month subscription ($500-2000 based on trial size)
---
Built for the AWS AI Agent Global Hackathon 2025 🚀
---
Built With
- amazon-api-gateway
- amazon-bedrock
- amazon-cloudfront-cdn
- amazon-cloudwatch
- amazon-cognito
- amazon-comprehend-medical
- amazon-dynamodb
- amazon-web-services
- aws-amplify
- aws-cdk
- aws-healthlake
- aws-lambda
- aws-textract
- fhir-r4
- jspdf
- mistral-large-2
- python-3.11
- react-18
- recharts
- shadcn/ui
- tailwind-css
- typescript
- vite


Log in or sign up for Devpost to join the conversation.