-
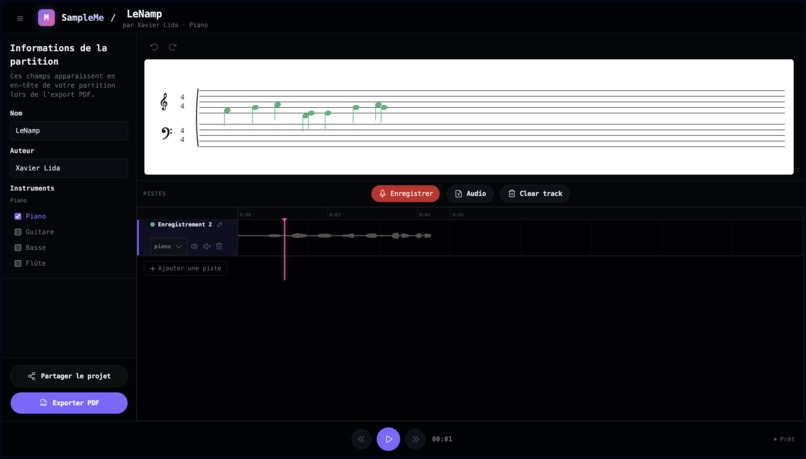
Desktop version
-
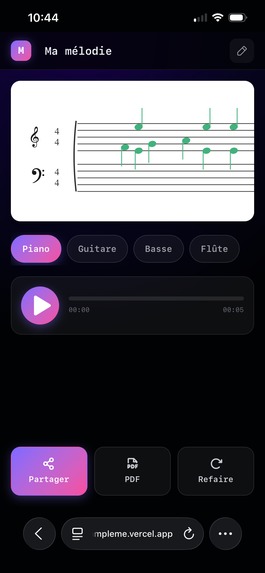
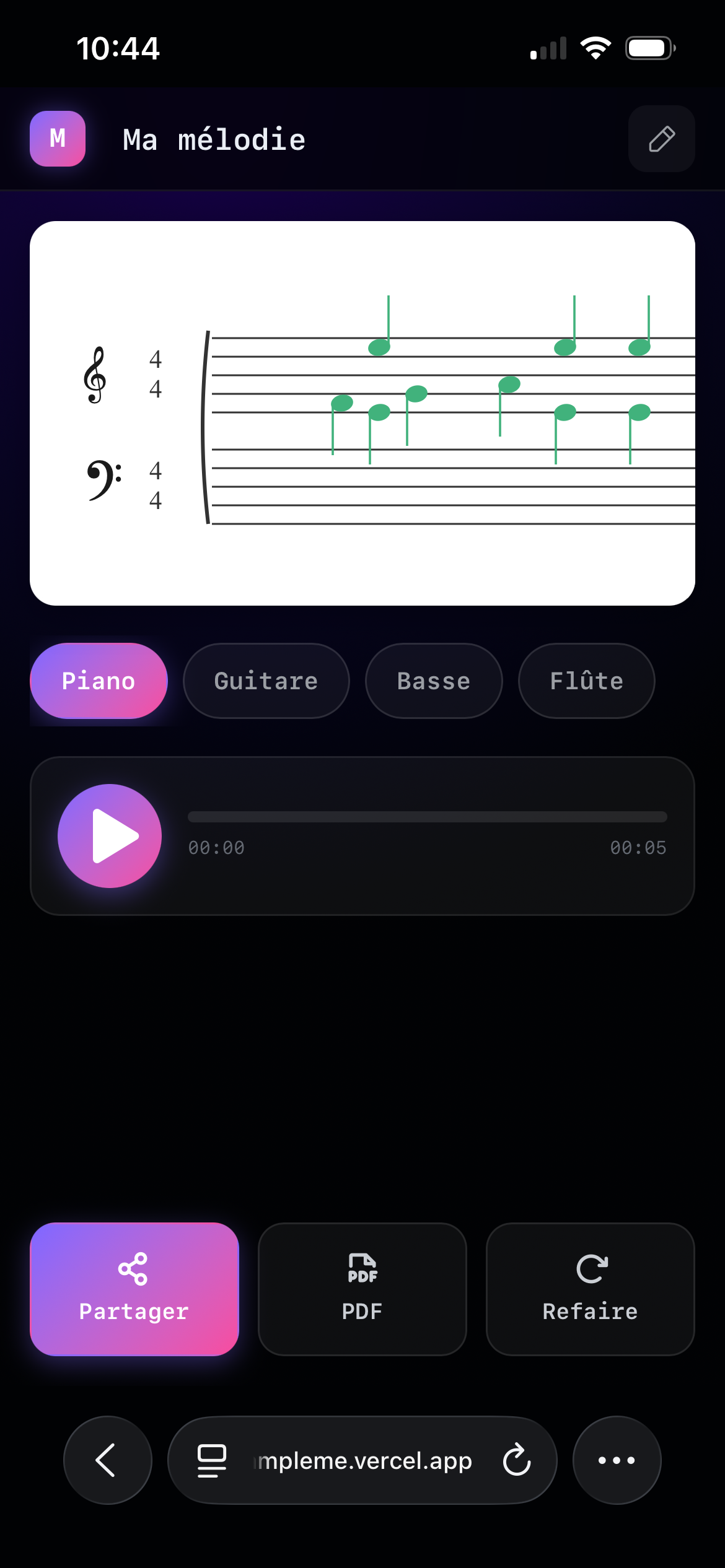
Mobil piano tracks
-

Mobile analyzing
-
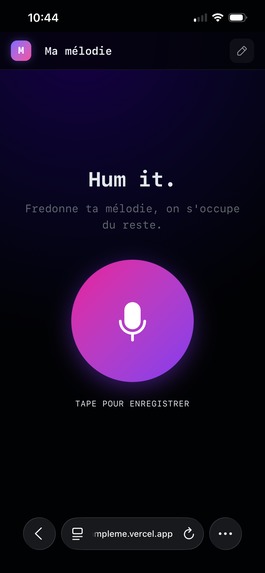
Mobile home page
-

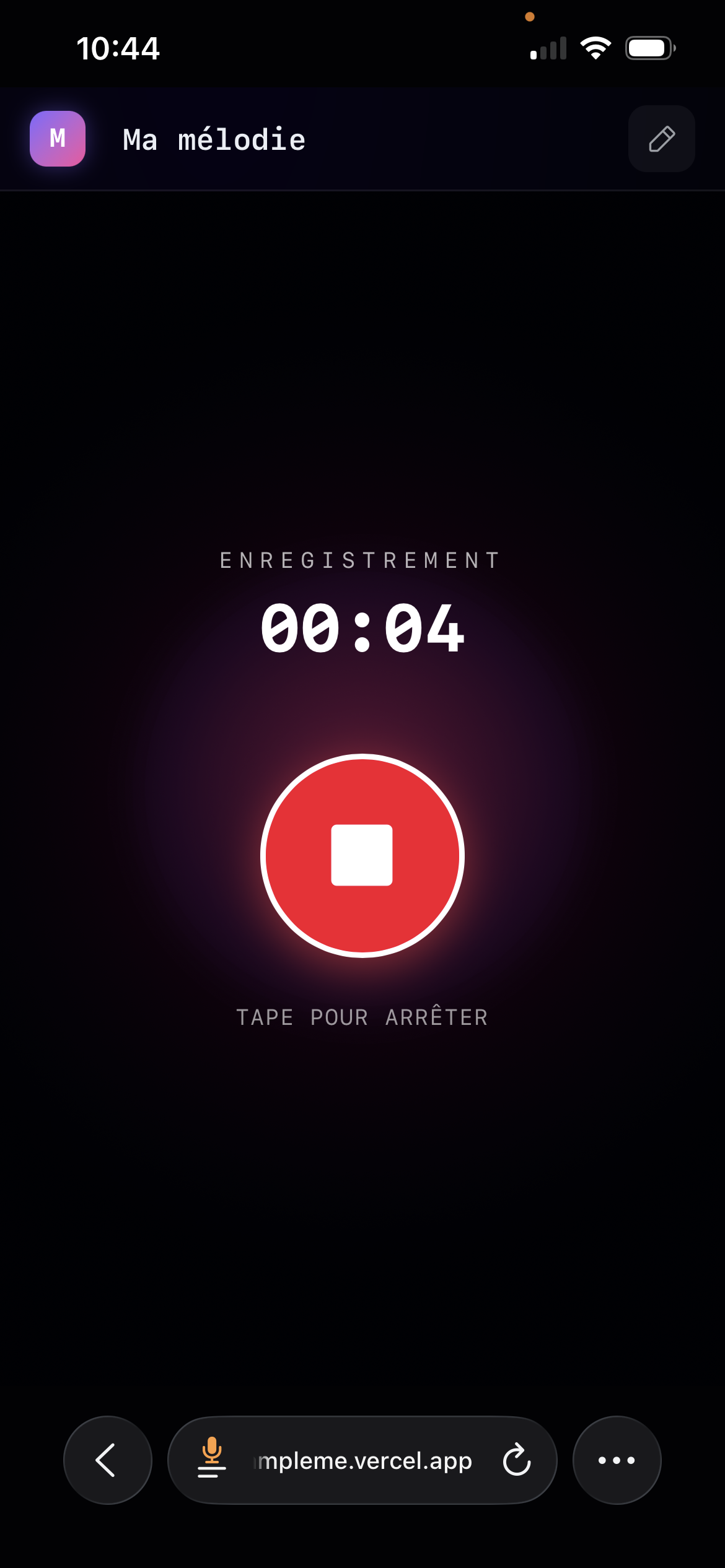
Mobile recording
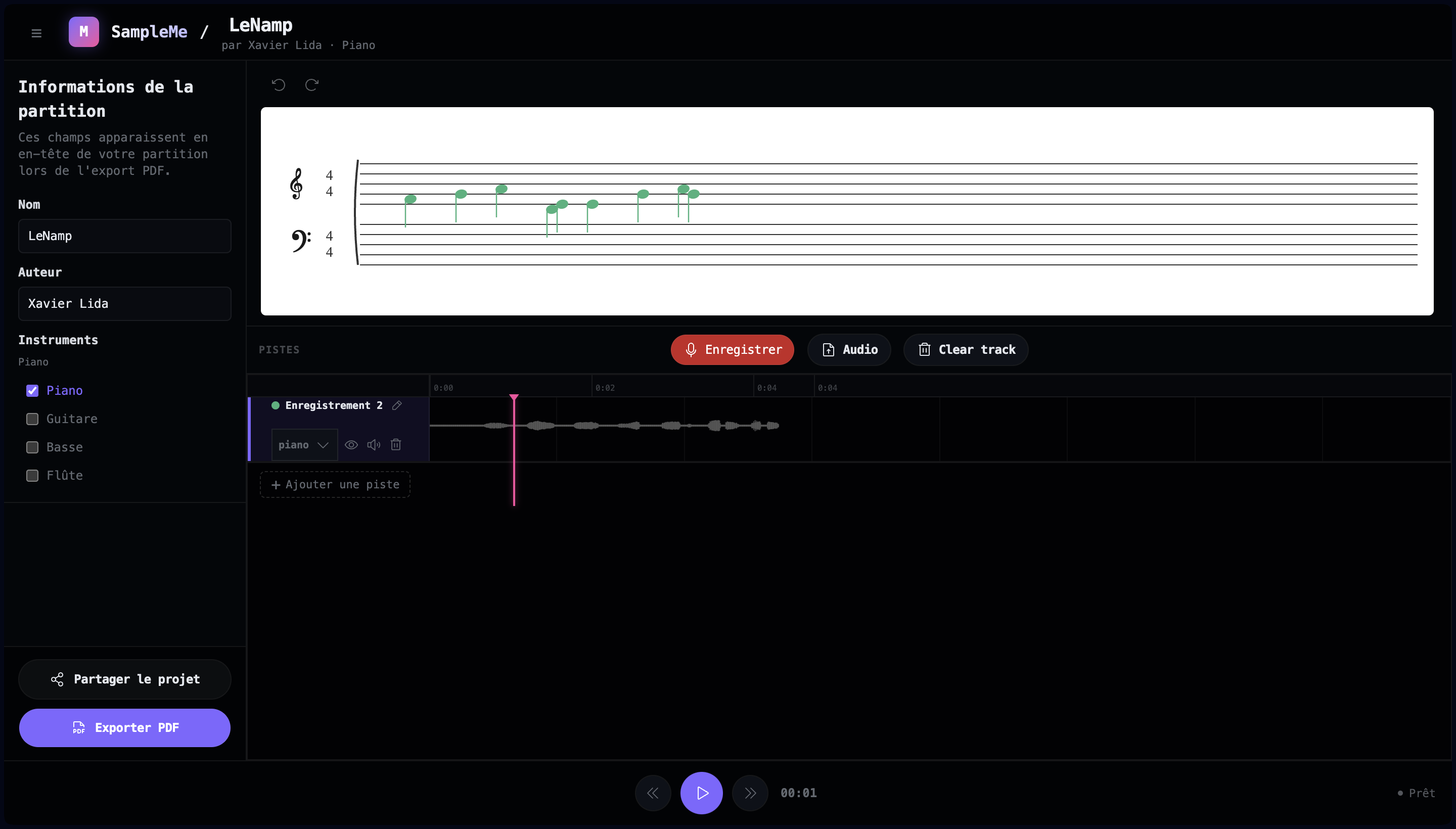


SampleME
Fredonnez, transcrivez, composez
Inspiration
La musique vit dans notre tête bien avant d'exister sur une partition. Combien de fois avez-vous fredonné une mélodie sans pouvoir la noter ? SampleME est né de cette frustration : rendre la transcription musicale accessible à tous, qu'on soit musicien expert ou simplement curieux. On voulait créer un outil où il suffit de chanter ou de jouer un audio pour voir apparaître une partition en temps réel, sans connaissances en solfège, sans logiciel complexe.
Ce que fait SampleME
SampleME transforme votre voix ou n'importe quelle source audio en partition musicale. L'utilisateur peut :
- Enregistrer directement via le microphone ou importer un fichier audio
- Visualiser la partition générée en temps réel
- Gérer plusieurs pistes (Piano, Guitare, Basse, Flûte)
- Exporter la partition en PDF
- Partager le projet facilement
L'application est pensée pour une utilisation mobile.
Tech Stack
Frontend — Next.js / TypeScript Interface réactive avec affichage dynamique des partitions, gestion des pistes audio, et export PDF. Entièrement adapté au mobile.
Backend — FastAPI (Python) Pipeline de traitement audio reposant sur :
- Basic Pitch (Spotify) — modèle de transcription audio-to-MIDI
- Librosa — analyse et traitement du signal audio
- NumPy / SciPy — manipulation des données et quantification rythmique à 120 BPM
Le flux : audio capturé → envoyé au backend → analysé et transcrit en notes → renvoyé au frontend sous forme de partition.
Nos défis
- Précision du modèle : obtenir une transcription fiable sur des voix humaines, avec leurs imprécisions naturelles de justesse et de timing, a été le défi central du projet.
- Affichage des partitions : intégrer un rendu de partition musical propre et lisible dans une interface web moderne, sans lib dédiée.
- Gestion des BPM variables : quantifier correctement des sources audio avec des tempos irréguliers ou différents de 120 BPM sans casser la lisibilité musicale.
- Voix vs audio externe : la qualité du signal varie énormément selon la source (voix directe au micro, audio depuis un autre appareil), ce qui complique la normalisation du traitement.
- Compatibilité microphone : gérer les différences de comportement entre navigateurs et appareils pour la capture audio en temps réel.
Nos fiertés
- Un projet fonctionnel en 24h : aller de zéro à une app qui transcrit de l'audio en partition exportable, c'est la victoire dont on est le plus fiers.
- Adaptation mobile complète : l'interface fonctionne vraiment bien et légèrement différemment sur téléphone.
- Le progrès collectif : chaque heure, le projet s'améliorait visiblement, entendre la partition pour la première fois a été un moment marquant.
Nos apprentissages
- L'importance du prétraitement audio avant toute transcription : garbage in, garbage out.
- Comment interfacer un backend Python (FastAPI) avec un frontend Next.js pour du traitement multimédia en temps réel.
- Les limites et les forces des modèles de transcription audio comme Basic Pitch sur des sources vocales réelles (On a échoué avec Crêpe).
La suite pour SampleME
- Meilleure précision de reconnaissance : affiner le pipeline de traitement et explorer des modèles complémentaires pour mieux gérer les voix et les instruments acoustiques.
- Amélioration du système multi-trame : optimiser la gestion des trames audio pour une transcription plus fluide et cohérente sur des enregistrements longs.
- Support de BPM variables : détecter automatiquement le tempo d'une source et adapter la quantification en conséquence.
Built With
- basic-pitch
- fastapi
- librosa
- numpy
- python
- react
- scipy
- typescript

Log in or sign up for Devpost to join the conversation.