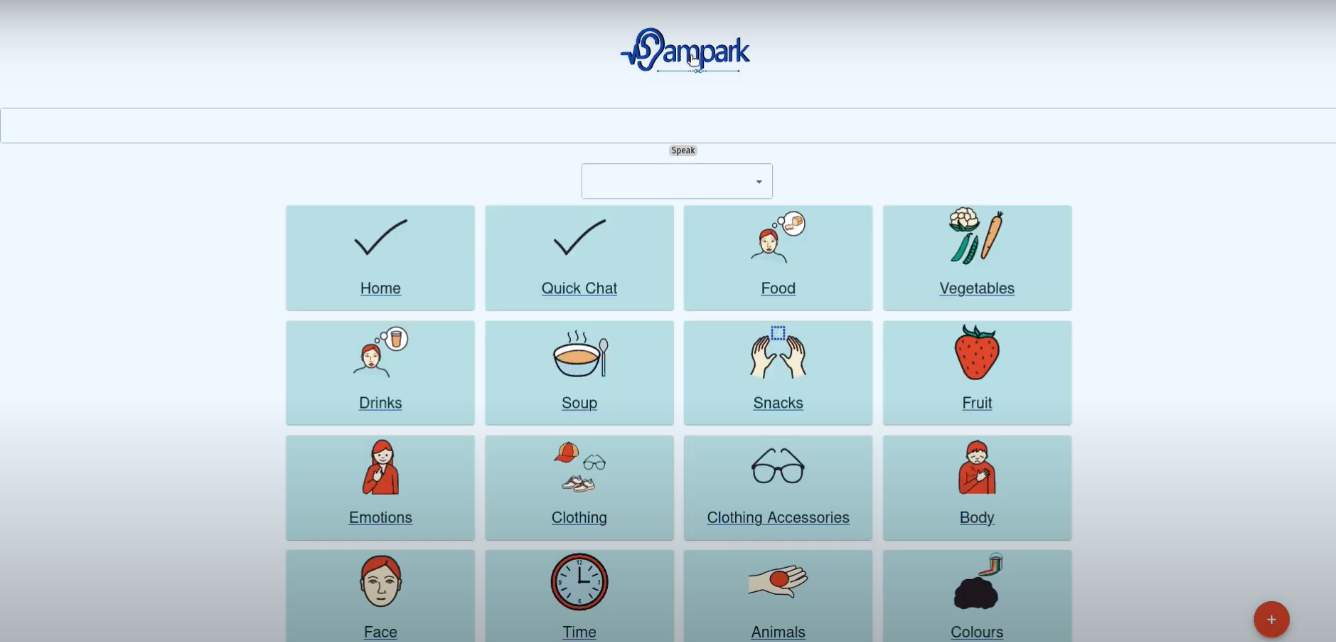
Landing page Image Board . Built With flaskmachine-learningreactsocket.iotensorflowwebrtc Try it out youtu.be github.com
Updates Atishay Srivastava started this project — Oct 17, 2021 09:57 AM EDT Leave feedback in the comments! Log in or sign up for Devpost to join the conversation.
Atishay Srivastava started this project — Oct 17, 2021 09:57 AM EDT Leave feedback in the comments! Log in or sign up for Devpost to join the conversation.

Log in or sign up for Devpost to join the conversation.