-
-
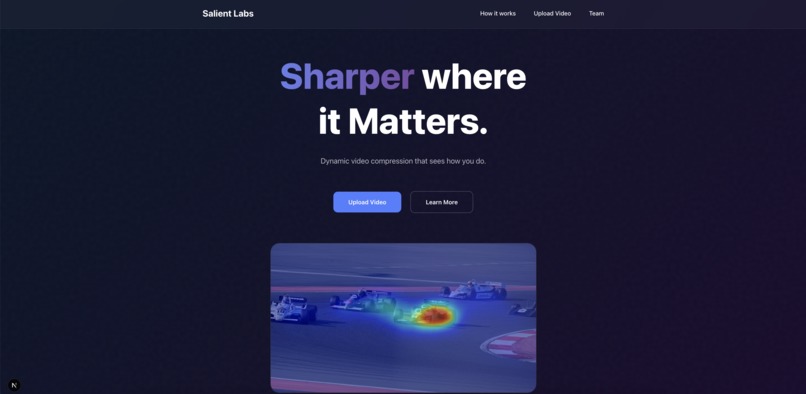
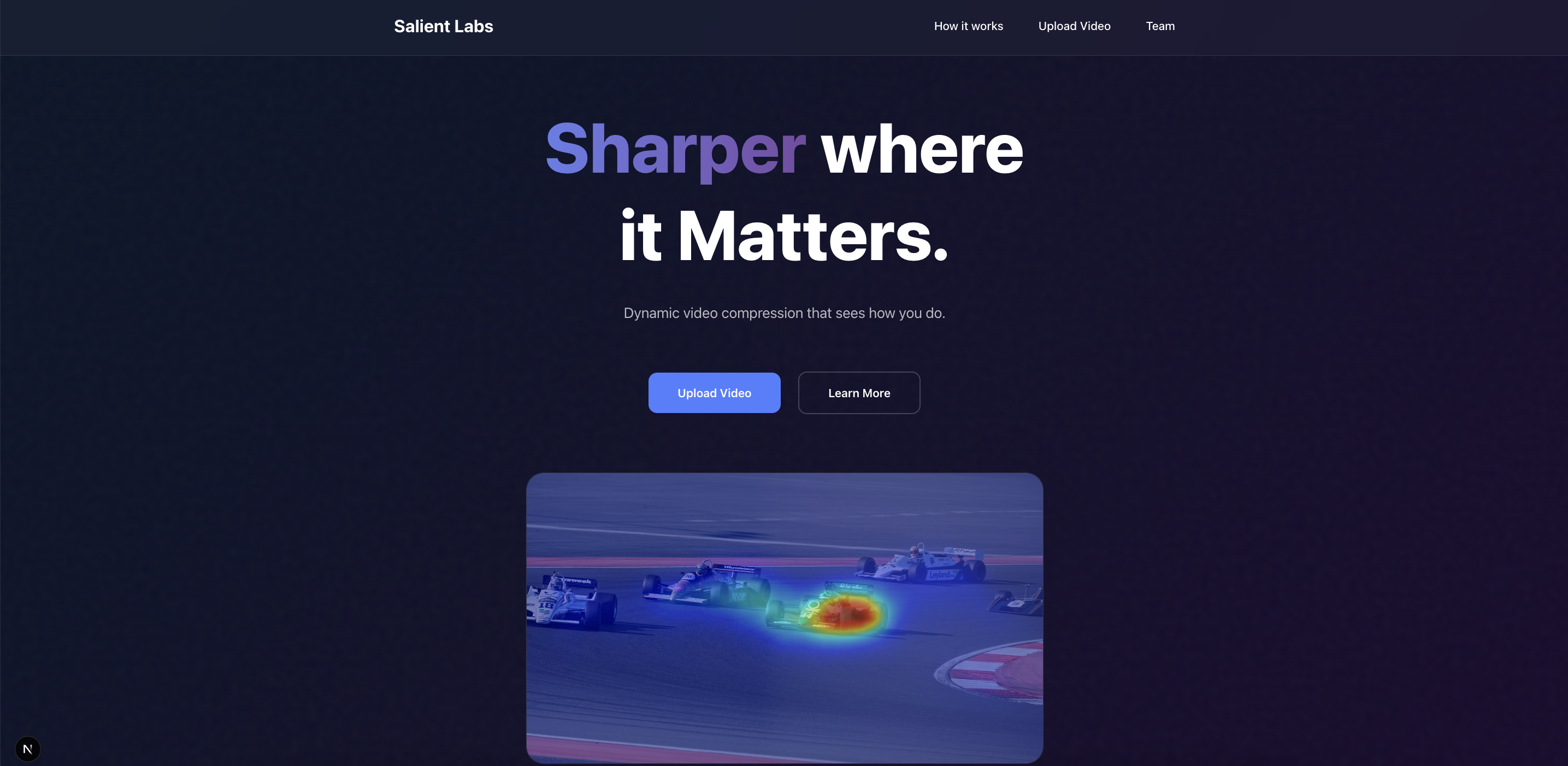
Landing
-

Saliency Heatmap
-
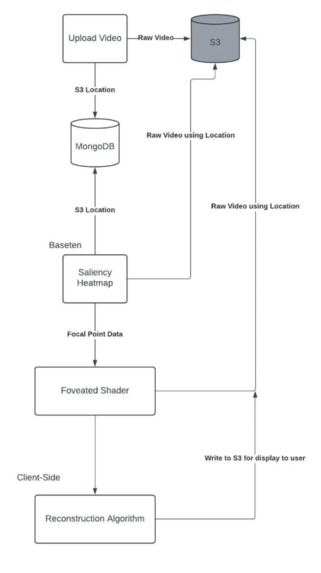
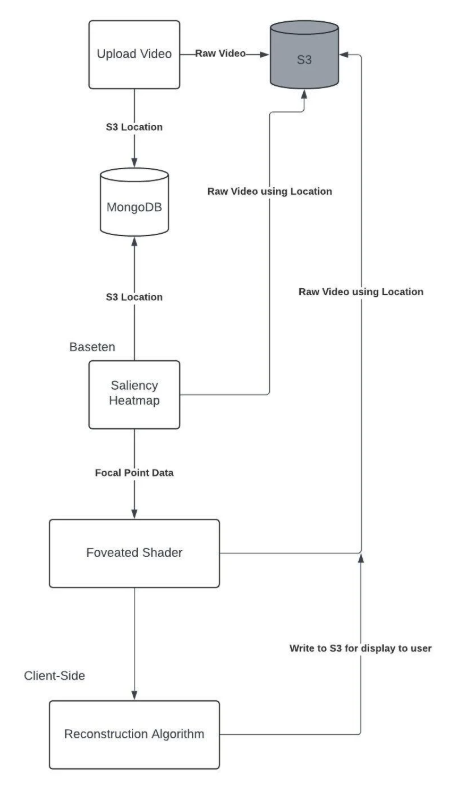
Architecture Design
-
Upload
-
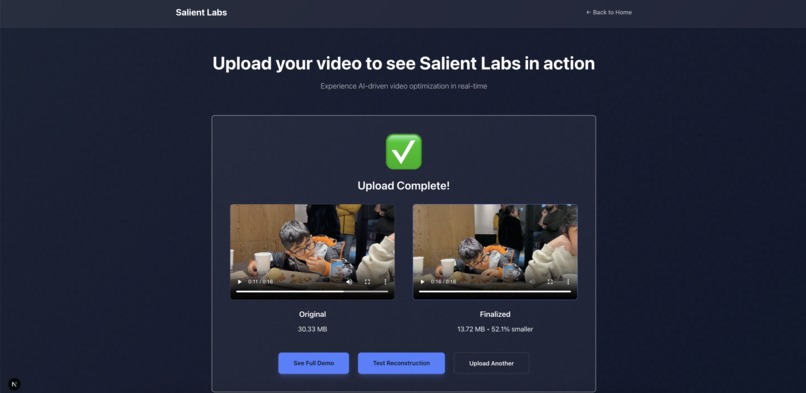
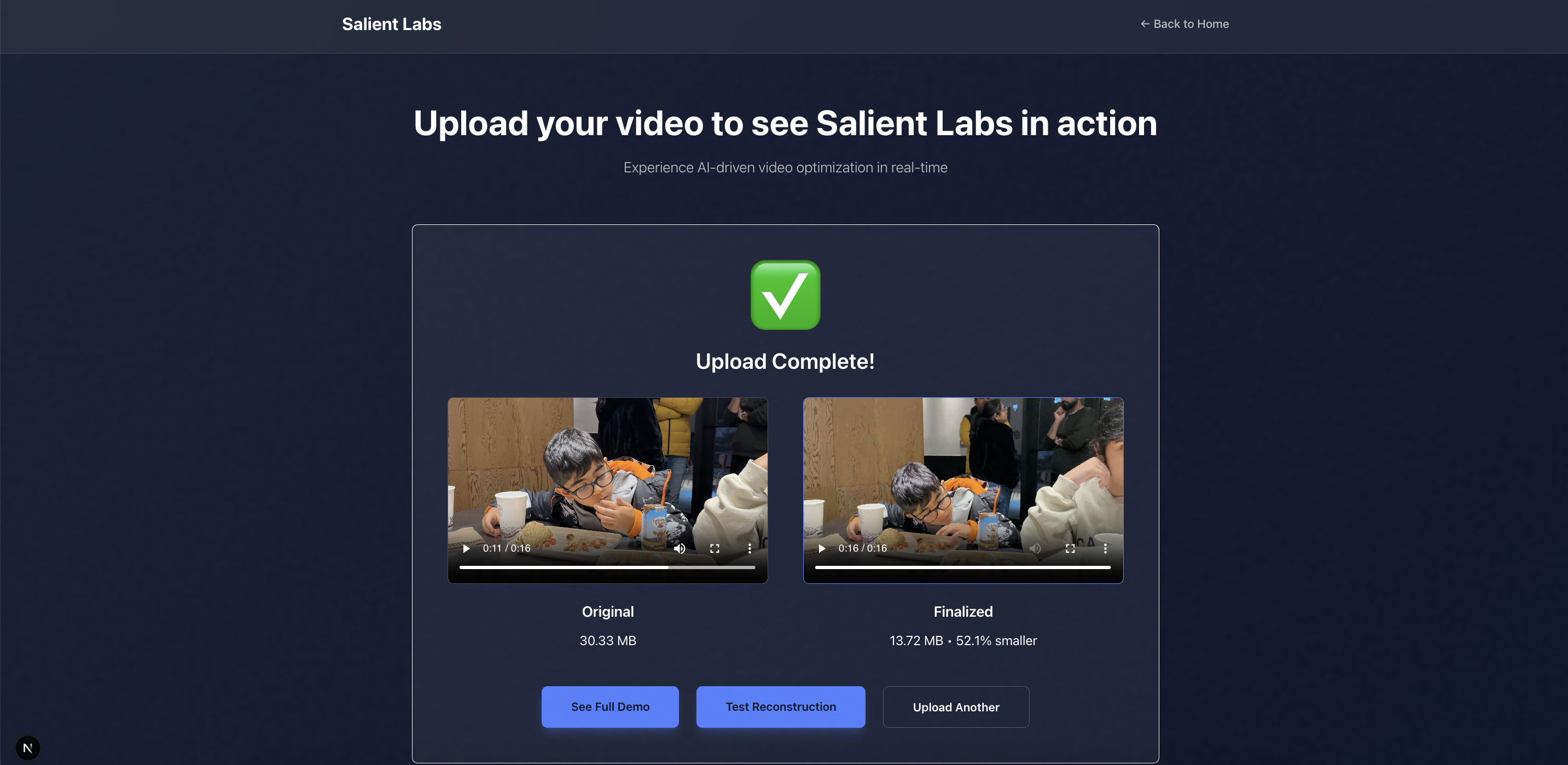
Uploaded

Inspiration
SOCIAL IMPACT
Machine learning–based video compression can shrink file sizes and cut bandwidth needs by up to 50%, directly lowering streaming infrastructure costs by 30–40%. By reducing the data required to deliver high-quality video, this technology makes online education, healthcare, and communication accessible to the 2.6 billion people still offline due to costly and limited internet access. We are motivated to actively work to bridge this digital divide in order to bring connection and opportunity to millions worldwide.
DEMAND
Why Buffering is Every Video Providers Worst Nightmare
Twitch Shuts Down in South Korea
Streaming Services Cutting Bitrates to Save Money
Even before COVID-19, video providers were already losing massive engagement — a mere 1% increase in buffering time translated into about 2.9 billion hours of lost viewing in a single quarter. With the global video streaming market valued at roughly US$674 billion in 2024, even a slight reduction in viewer hours or increase in cost can equate to hundreds of millions in lost revenue or extra expense. At the same time, streaming platforms are taking desperate measures — slashing bitrate, reducing quality, and squeezing compression — to cut bandwidth and delivery costs that run into the billions annually across the industry. Mounting engagement risk plus soaring delivery cost creates a compelling demand for a solution that both preserves viewer experience and lowers data usage.
What it does
Our system rethinks video compression by mirroring how the human eye perceives importance in a scene. Rather than preserving every pixel equally, it identifies the regions that naturally capture attention—faces, motion, or areas of high contrast—and keeps those sections sharp, while less noticeable regions are transmitted at lower resolution. On the viewer’s side, these regions are simply scaled back up, creating a smooth but visibly adaptive level of detail across the frame.
How we're unique
What makes this approach unique is that it doesn’t just compress data: it compresses perception. Traditional codecs work uniformly across the screen, but this is the first model that embraces resolution variation as part of the design, keeping the experience realistic while using a fraction of the data. The effect is subtle yet powerful: scenes look natural, but the underlying file is dramatically smaller. The method has clear potential in both pre-processed content (YouTube and Netflix), where bandwidth directly affects cost, and live video (Zoom and FaceTime), where fluctuating network speeds are prevalent.
How we built it
We designed our system to mirror how the human eye selectively processes visual information, balancing computational efficiency with perceptual realism.
- Neural Saliency Detection: Implemented using ViNet, a PyTorch-based video saliency prediction model trained on DHF1K, Hollywood-2, and UCF-Sports datasets for visual attention, with additional fine-tuning on DIEM, AVAD, Coutrot-1/2, SumMe, and ETMD for visual saliency cues. The model outputs a spatiotemporal saliency heatmap for each frame, predicting where human gaze is most likely to focus based on motion, contrast, and semantic context.
- Preprocessing Pipeline: Frames are extracted, normalized, and batched using OpenCV and NumPy, converted into tensors, and passed through ViNet in float16 precision for GPU-optimized inference.
- Heatmap Postprocessing: Each saliency map is normalized and discretized into percentile bins (e.g., top 20%, 50%, 80%) to classify regions by visual importance.
- Server-Side Compression: A GPU-accelerated OpenGL fragment shader processes the frame using the saliency mask, preserving high-saliency pixels at full resolution while adaptively downsampling lower-saliency regions. The shader executes in parallel on the GPU using GLSL
texelFetchoperations for direct texture access, ensuring real-time throughput. - Encoding Pipeline: The mixed-resolution output frame is encoded via FFmpeg (H.264/H.265), with saliency metadata embedded as sidecar data to guide client-side scaling.
- Client-Side Scaling: On playback, the client reads the saliency metadata and uses a lightweight OpenGL upscaling shader to scale low-resolution areas back up to the original frame size, maintaining smooth transitions between resolution zones.
Challenges we ran into
- Real-Time Performance: Achieving frame-level saliency detection and GPU compression in real time was difficult. The PyTorch model alone could process only a few frames per second initially, so we experimented with quantizing it, optimizing batch loading, and pipelining the inference with shader execution.
- Shader Synchronization: Getting the OpenGL shader and PyTorch inference to share memory efficiently without stalling the baseten API was challenging, and we had to pivot approaches multiple times.
- Compression Artifacts: Early versions of the shader created visible seams and inaccurate pixels where resolution zones met. We had to fine-tune the saliency thresholds and interpolation filters to make transitions appear smoother while keeping data savings significant.
- Bandwidth Variability: Simulating unstable network conditions to test adaptive thresholding was harder than expected. We tested this by changing the resolution of the source video's frames randomly.
- Model Generalization: ViNet’s saliency predictions worked well for cinematic and YouTube-style videos but struggled with static or low-motion footage. We experimented with temporal smoothing and custom fine-tuning to improve stability across diverse content.
- Integration Overhead: Coordinating the PyTorch inference server, shader renderer, and FFmpeg encoder into one containerized pipeline required careful dependency management.
Despite these challenges, each bottleneck led to a better understanding of how to balance neural inference, rendering, and compression in one real-time system.
Accomplishments that we're proud of and What We Learned
Despite these challenges, we’ve achieved something remarkable:
- Functional Prototype: We built a fully operational system that dynamically adjusts video resolution in real time based on predicted viewer attention.
- Perceptual Compression: Our approach maintains sharpness where it matters most, proving that compression doesn’t have to be uniform to feel natural.
- Massive Efficiency Gains: Testing shows file sizes can be reduced by 2×–3× while retaining strong perceptual quality, dramatically lowering bandwidth and storage costs.
- GPU-Accelerated Pipeline: We achieved real-time performance by fusing a PyTorch saliency model with an OpenGL shader pipeline—compressing and transmitting frames at streaming speeds.
- Cross-Platform Applicability: The system runs efficiently for both pre-processed video (like streaming platforms) and live feeds, adapting dynamically to network fluctuations.
- End-to-End Integration: We combined deep learning, GPU rendering, and adaptive encoding into a single pipeline that can slot directly into existing video delivery workflows.
What's next for Salient Labs
Salient Labs is committed to pushing the boundaries of machine learning–driven compression through rigorous experimentation and user testing, aiming for stable 50%+ efficiency and 95%+ satisfaction. As a research-oriented team, we plan to extend our work to other bandwidth and infrastructure challenges that limit global connectivity.
Built With
- amazon-web-services
- baseten
- ffmeg
- next
- opengl





Log in or sign up for Devpost to join the conversation.