-
-
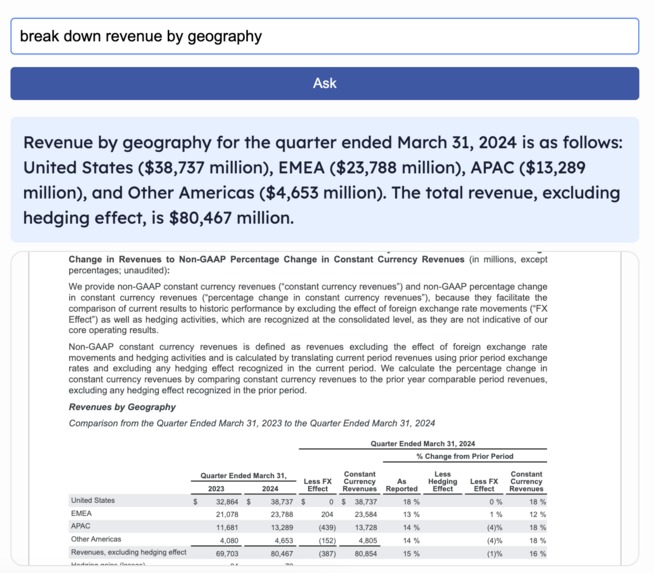
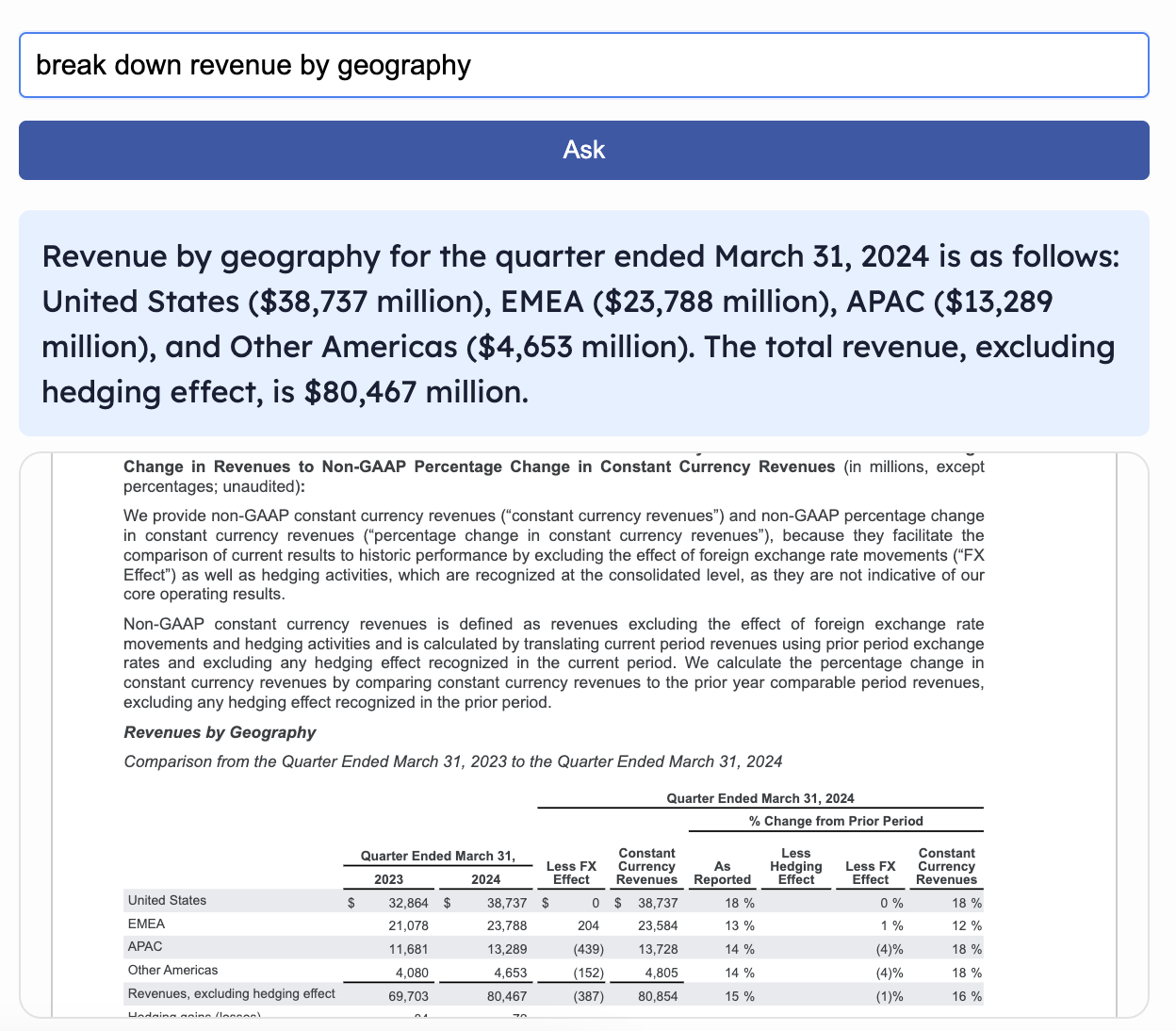
Search with Citation
-
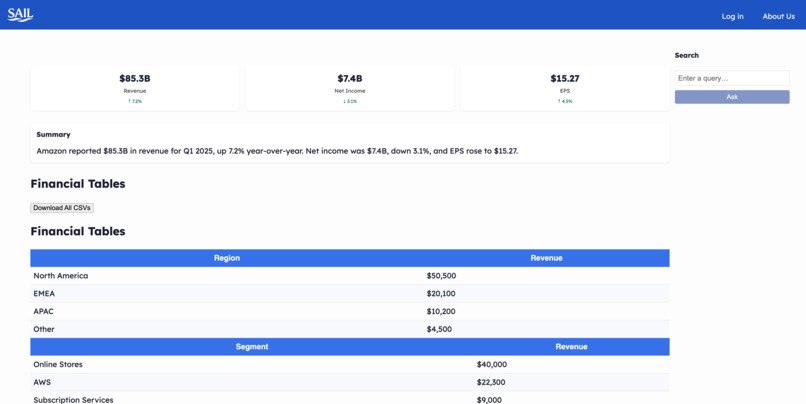
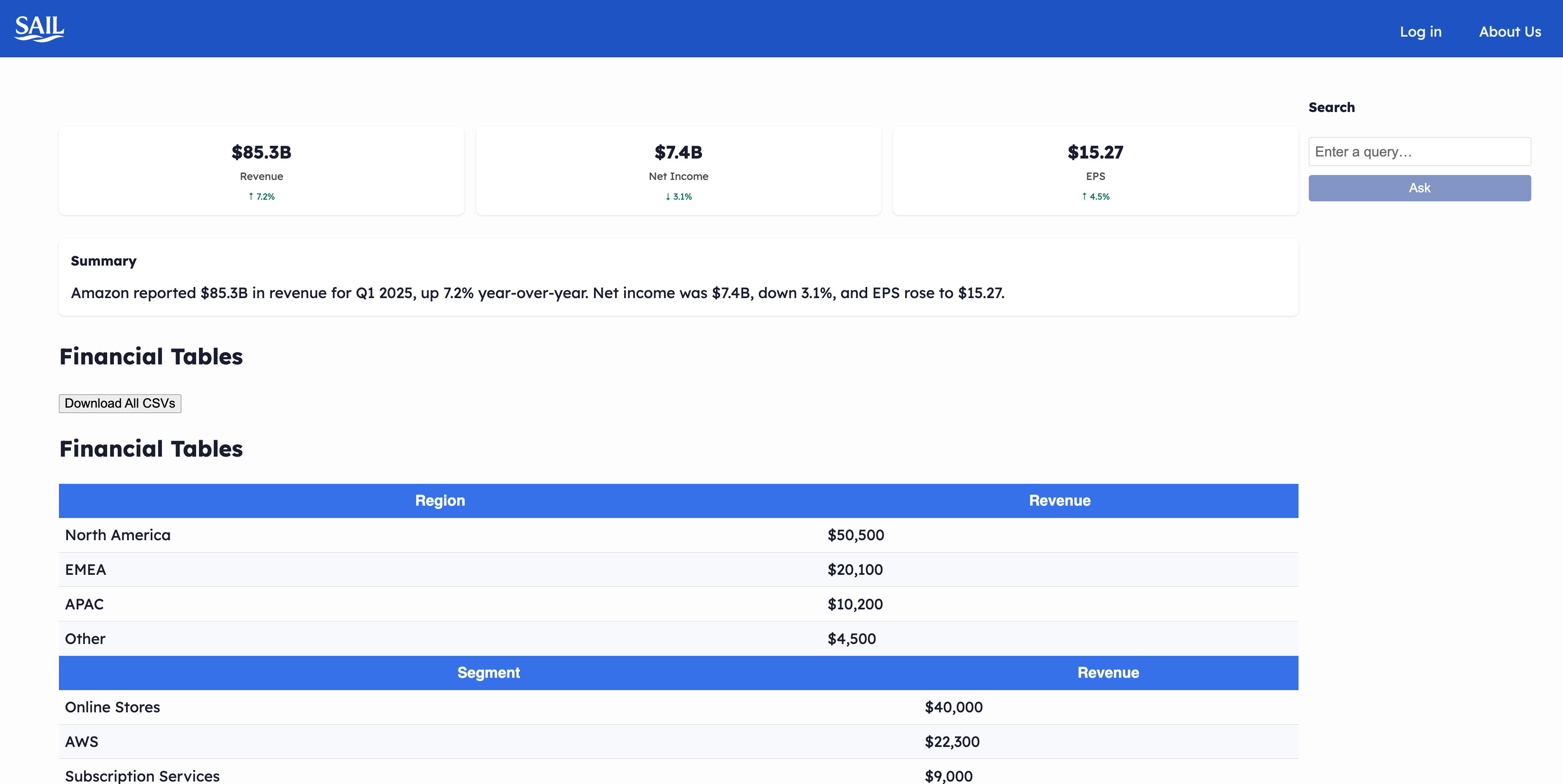
Dashboard
Inspiration
Every day, financial analysts and interns waste hours on manual data—copy-pasting tables from PDFs, hunting through slide decks for KPIs, and flagging forward guidance. According to Vena Solutions, up to 75% of an analyst’s time is spent gathering and processing data - not analyzing it.
That's why we built SAIL.
What SAIL Does
SAIL eliminates the grunt work and turns financial documents into a powerful insights engine—so your team spends less time wrangling data and more time making decisions.
- Instant Structuring: Automatically detects and cleans tables, KPIs, and guidance from PDFs—no formatting or retyping required.
- AI-Powered Q&A: Ask natural-language questions and get fast, citation-backed answers from the original document.
- Reliable Outputs: Normalized, error-free data you can trust—ready for analysis, export, or presentation.
- Plug-and-Play Workflow: Download clean CSVs, generate summaries, or integrate directly into your dashboards and BI tools.
With SAIL, navigating financial reports becomes as easy as asking a question—freeing analysts to move from documents to decisions in seconds.
How we built it
Under the hood, SAIL is a modular, end-to-end pipeline combining the best of computer vision, NLP, and advanced LLM models like perplexity sonar:
- Automated Sourcing
Perplexity Sonar API to fetches and caches the latest earnings‐release PDFs with a simple ticker or URL input. - Modular Extraction
A computer‐vision layer (Detectron2 + LayoutParser) identifies tables, figures, and text blocks, which are then parsed by Tabula into structured data. - Robust Cleaning
Lightweight Python pipeline for data cleaning, align headers, merge split rows, normalize formats, dedupe replicate chunks for a consistent dataset, etc. - AI‐Driven Analysis
LangChain chunks text and runs them through a map‐reduce pipeline on our LLM to extract key metrics. - Dynamic Q&A
Cleaned tables and narrative chunks are indexed in a Chroma vector store with MiniLM embeddings. At query time, an MMR retriever surfaces diverse context and a final LLM call produces precise, citation‐backed answers. - Sleek UX & Scalability
A lightweight API backend pairs with a React SPA for instant insights and CSV exports. The entire stack is containerized, CI‐tested, and ready to scale.
Challenges we ran into
- PDF variability: footnotes, multi-column layouts, and inconsistent spacing and fonts made table detection brittle. We layered Detectron2 and Tabula and built fallback logic to output raw CSV when parsing failed.
- API & memory limits: processing large pages triggered out-of-memory errors and free token usage limits; we implemented page-by-page streaming and chunked embedding to keep usage stable.
- Index growth: as we loaded years of filings across multiple companies, our Chroma store expanded rapidly. We added metadata filters and tuned MMR parameters to maintain sub-second query times.
Accomplishments that we’re proud of
End-to-End Automation We built a fully automated pipeline—from PDF ingestion and table detection to RAG-powered question answering—that turns static earnings releases into an interactive analytics hub with a single click.
-Sub-Second Query Responses By caching extracted JSON and tuning our Chroma vector store + MMR retriever, ad-hoc natural-language queries against 50+-page reports now complete in under one second.
-Citation-Backed Answers Every insight our LLM returns is footnoted with the exact table title and page number, giving users full transparency and auditability in their decision-making.
-Seamless UX & Export Our React frontend combines a draggable split-pane PDF viewer, scroll-to-page highlights, downloadable per-table and “Download All” CSVs, and a clean SAIL theme—so analysts spend zero time fiddling with formatting.
What we learned
Tables Are Tricky
Real-world financial PDFs come with merged headers, split cells, footnotes and captions. Combining Detectron2→tabula→pand as cleaning steps taught us that no single tool “just works”—you need layered heuristics and an LLM-guided cleanup.Prompt Engineering Matters
Even with a 70B-param model, careful prompt design and output parsing (JSON schemas, score-thresholded reranking) were critical to reliable KPI extraction and overall summarization.Metadata Is King
Adding simple labels liketable_title,page, and content type let us filter and rerank retrieval results far more accurately than naïve cosine similarity search alone.Caching Makes a Difference
Persisting extracted JSON means repeat users get almost instant load time on previous reports. Storing document and anlysis data in vector DB allows for cross document analysis and creates time-series data for future models.
What’s next for SAIL
- OCR integration: many filings are scanned images. We’re testing llama Scout or another vision-enabled LLM for OCR to handle scanned PDFs.
- Enhanced table recovery: use deep-learning-based table reconstruction (e.g. Microsoft’s Table Transformer) to improve header alignment and merged-cell handling.
- Multi-year comparisons: build dashboards that automatically compare KPIs across consecutive quarters or peer companies.
- Collaboration features: shared workspaces, annotations, and audit logs for team workflows. -AI-Driven Insights: Integrate forecasting, anomaly detection, and “what-if” scenarios powered by fine-tuned LLMs and time-series models. -Performance and Scale: Migrate to paid LLM API tiers and a cloud‐hosted deployment for significant gains in throughput and latency.


Log in or sign up for Devpost to join the conversation.