-
-
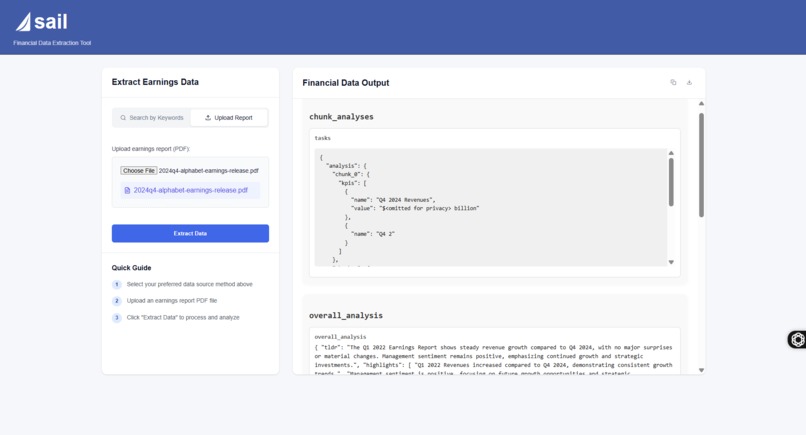
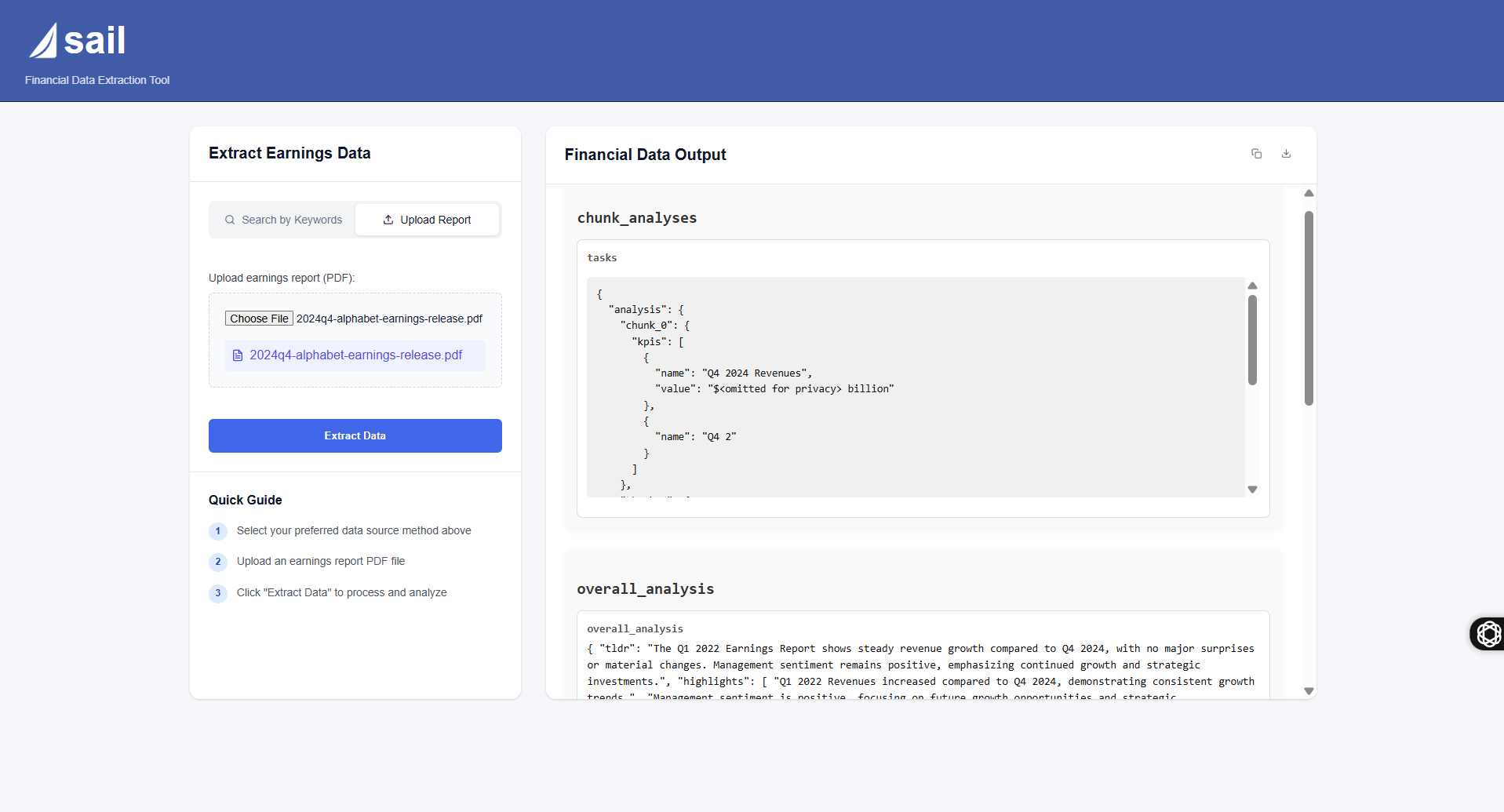
Sail Main Page
SAIL: Financial Document Intelligence Pipeline
Project Technology Stack The SAIL project integrates a suite of tools carefully selected for their strengths in handling the challenges of financial document analysis. This toolset enables the proposed dual-workflow architecture and the Retrieval-Augmented Generation (RAG) extension for semantic search. For processing unstructured text, LangChain serves as the central orchestrator, managing interactions with LLMs (via the OpenAI API or alternatives like LlamaIndex). LangChain facilitates prompt chaining—such as extracting forward guidance, identifying KPIs, and classifying sentiment—while managing context and chunking of large documents. Data handling and validation rely on Pandas for tasks like verifying extracted table totals and structuring outputs, with JSON as the primary data format and sqlite3 as an optional lightweight storage solution.
For structured data processing, specialized open-source libraries like pdfplumber and PyMuPDF are used to parse PDF structure and detect table boundaries, while Tabula and Camelot extract data from those detected tables. Backend services are planned using FastAPI or Flask to serve endpoints for file upload, processing, and querying. React will power the front-end user interface, allowing users to upload PDFs and search within them. For the RAG system, vector databases like FAISS, ChromaDB, Pinecone, or Qdrant are considered to store text embeddings for efficient semantic search, with PostgreSQL or SQLite offered as alternatives for non-semantic storage. Finally, development utilities like virtualenv, requirements.txt, and Streamlit are incorporated for streamlined setup and optional dashboard creation. This pragmatic, modular approach focuses on rapid prototyping and demonstrating core functionality efficiently—ideal for hackathon contexts or early proof-of-concept phases.
Project Impact and Importance SAIL promises to significantly improve the efficiency of analyzing financial documents by automating data extraction and enabling richer insights. Its primary importance lies in addressing the inefficiency and limitations of manual analysis when dealing with documents blending structured financial tables and unstructured narratives. The project provides substantial efficiency gains, automating laborious extraction tasks and enabling scalable, rapid analysis across large volumes of public filings. The dual-workflow design—separately handling tables and narratives—ensures high-quality outputs, converting previously locked PDF data into accessible, structured formats like JSON or databases. This facilitates downstream analytics, real-time access, and further applications like financial modeling or risk analysis.
Importantly, SAIL moves beyond basic data extraction by targeting qualitative insights often missed in purely quantitative approaches. Extracting guidance, KPIs, forward-looking statements, and sentiment enriches understanding of a company’s strategic positioning and outlook. The addition of the RAG component represents a transformative upgrade, turning SAIL into an interactive discovery platform. Users will be able to query past uploads using natural language and receive contextually relevant, insightful responses—an intuitive, powerful alternative to traditional keyword searches. This evolution from static data extraction to dynamic semantic querying significantly enhances the project’s value to analysts and business intelligence teams.
Development Challenges Faced Despite its strong potential, the development of SAIL—particularly under hackathon time constraints—poses several challenges. A major hurdle is document variability: financial reports vary widely in layout, formatting, and language, which can complicate the consistent performance of tools like pdfplumber and Tabula. Poorly scanned or inconsistently formatted PDFs are especially problematic. Extraction accuracy and validation present further difficulties. Ensuring the correctness of extracted table data demands robust validation logic, using Pandas to check totals and consistency, while ensuring the LLM correctly extracts financial guidance and KPIs is complicated by the risk of hallucination or misunderstanding of industry-specific terminology.
Prompt engineering within LangChain also presents a technical hurdle. It requires iterative refinement to create prompts that reliably extract the intended information while respecting token limits and managing model behavior across diverse text samples. The integration complexity of combining multiple components—PDF parsing, table extraction, LLM pipelines, backend APIs, frontend interfaces, and vector search systems—into a smooth, cohesive workflow demands meticulous architecture and engineering. Finally, implementing RAG introduces its own technical challenges, including choosing the best embedding models, designing smart chunking strategies, managing vector databases efficiently, and optimizing retrieval quality to ensure both speed and relevance for end-users. Each of these challenges highlights both the technical sophistication of the project and the rigor required to bring it to a production-ready MVP.
Built With
- beautiful-soup
- css
- flask
- html
- javascript
- langchain
- python
- react
- selenium
- tabula


Log in or sign up for Devpost to join the conversation.