-
-
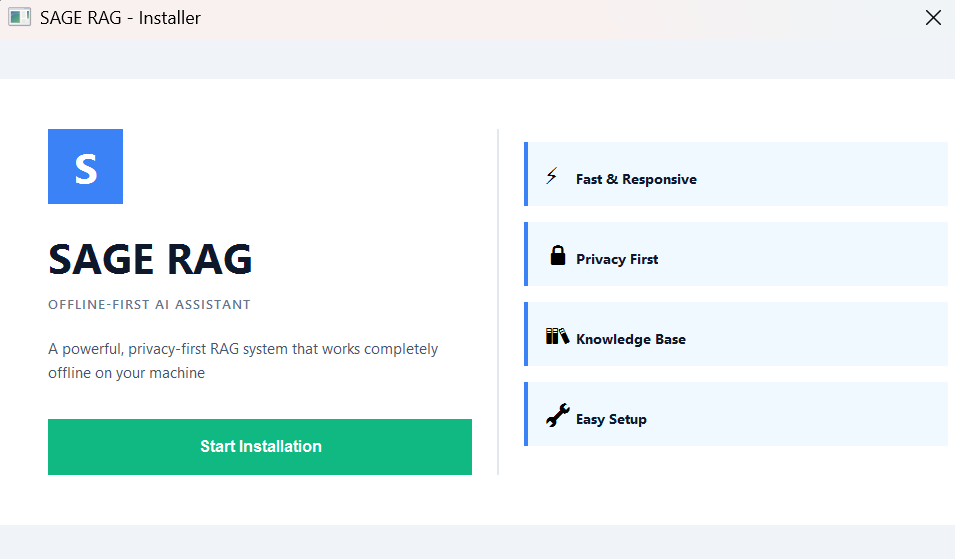
Installation Wizard Landing Page
-
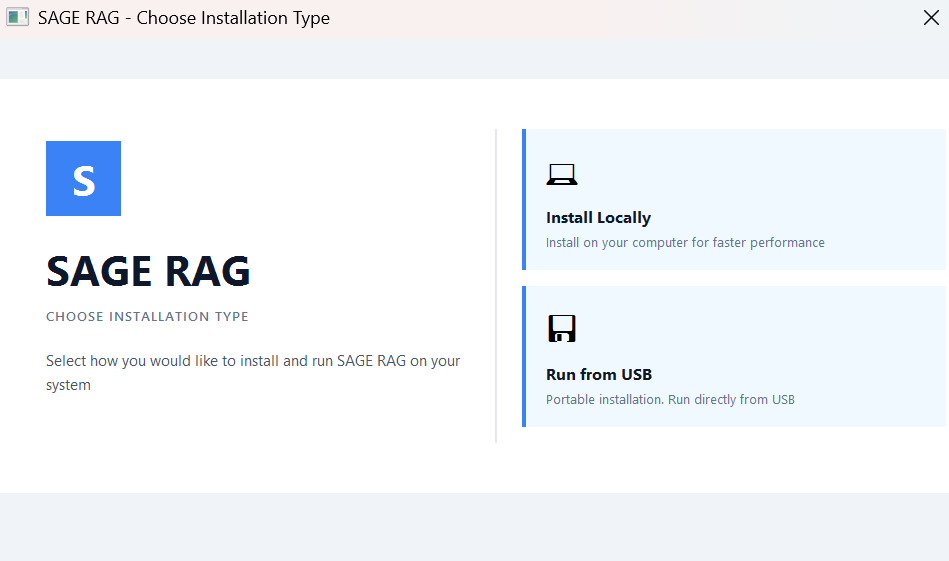
Installation Wizard Options
-
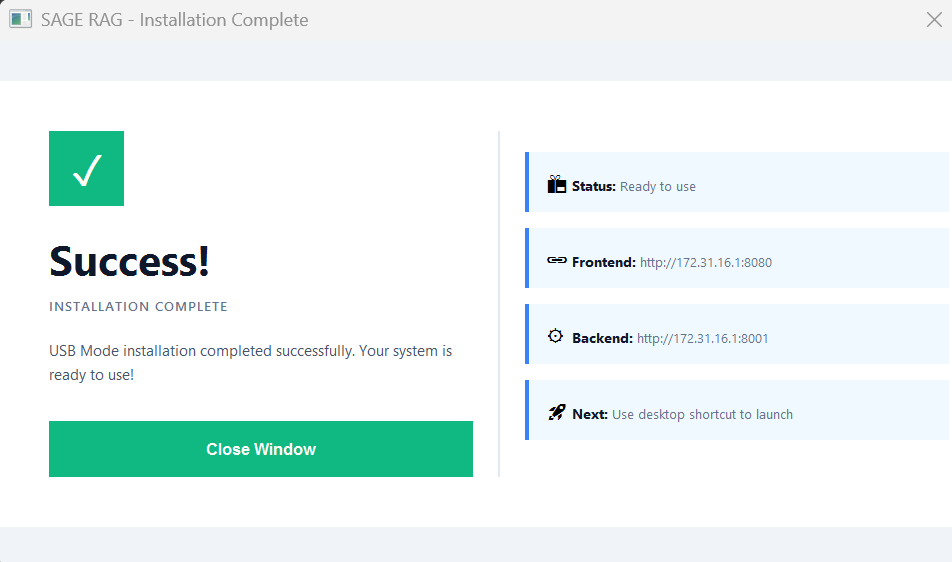
Installation Wizard Completion
-
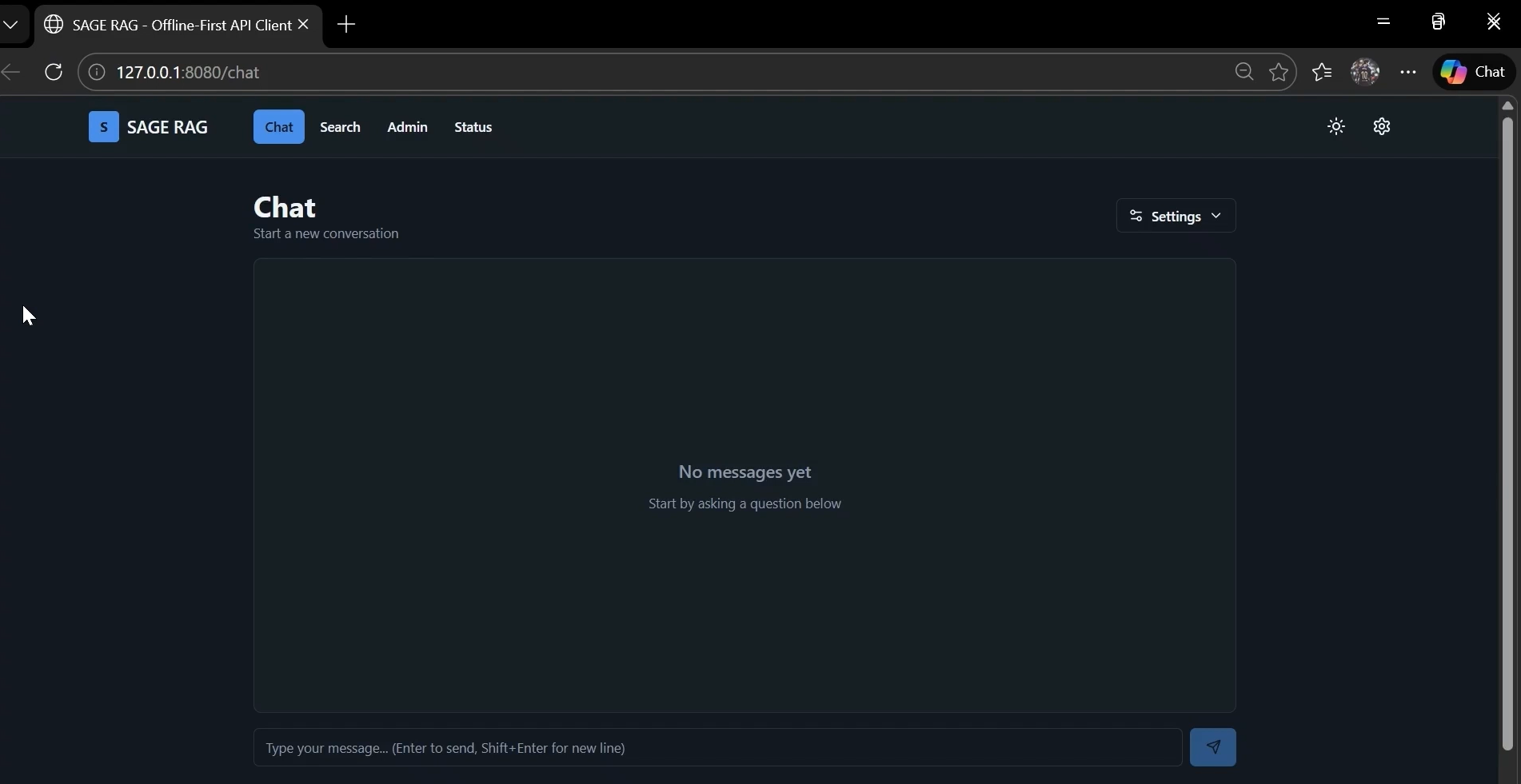
Website homepage (chat interface)
-
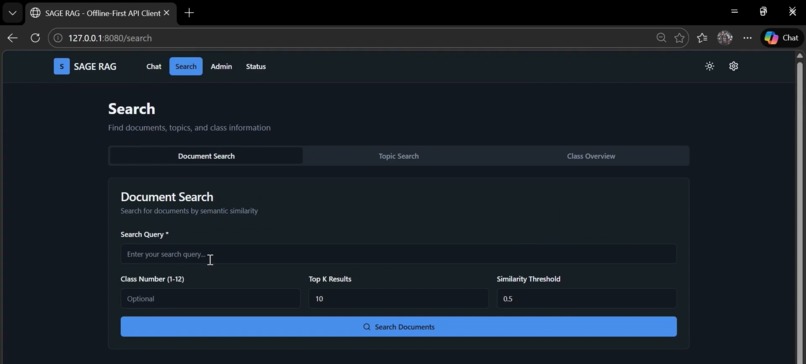
Document Search
-
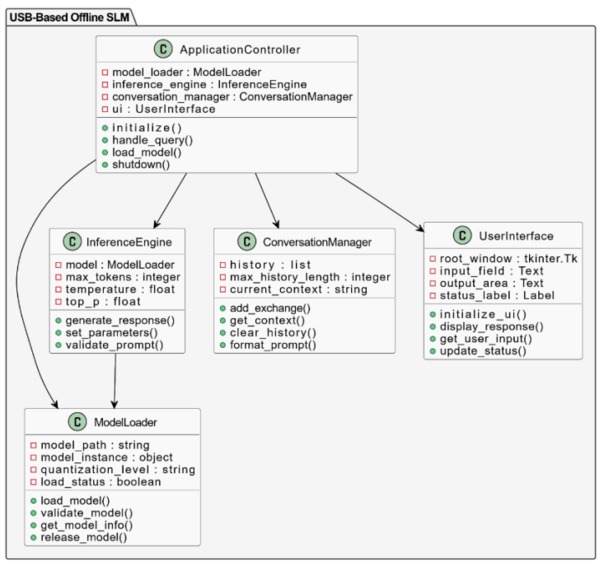
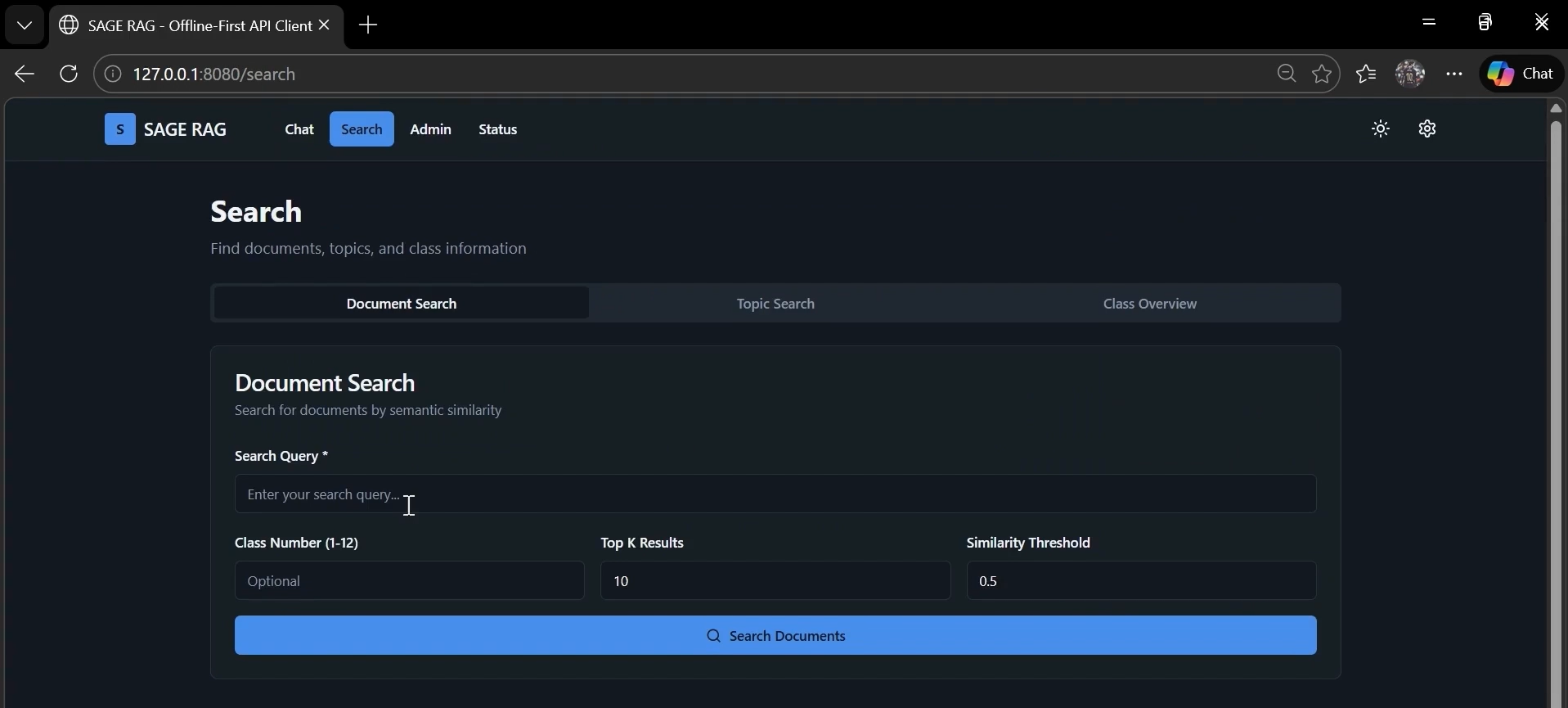
Class Diagram
-
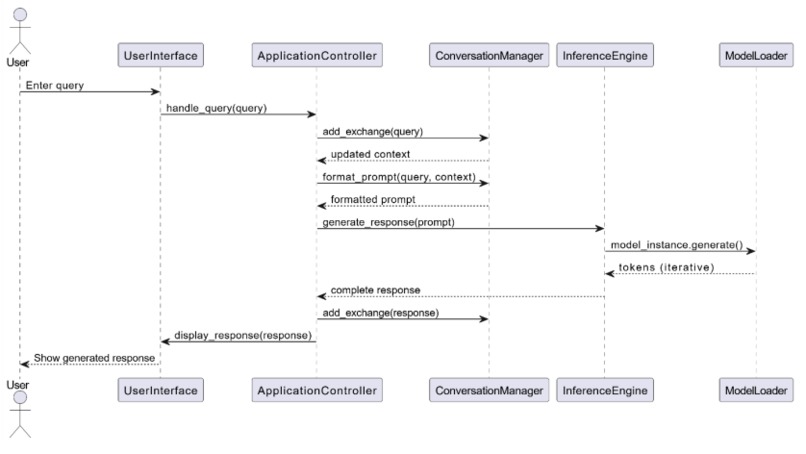
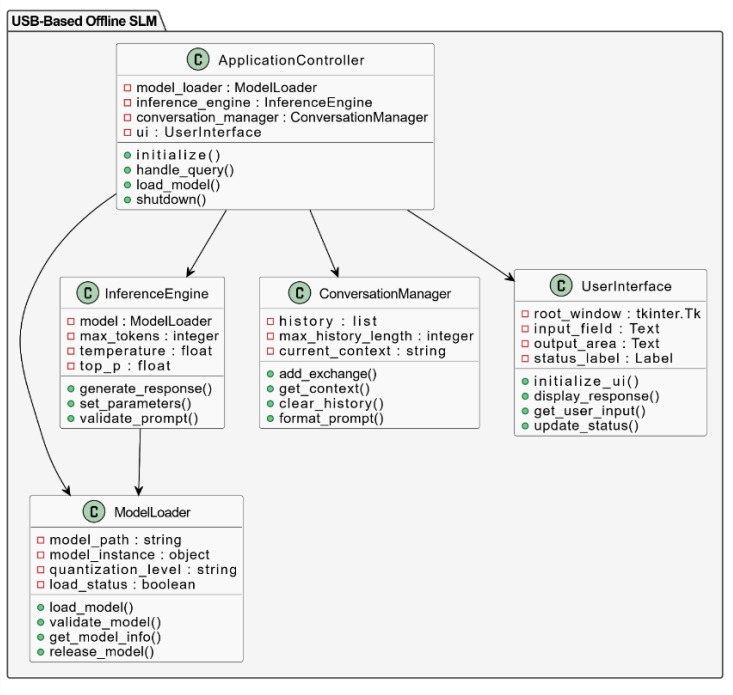
Sequence Diagram
-
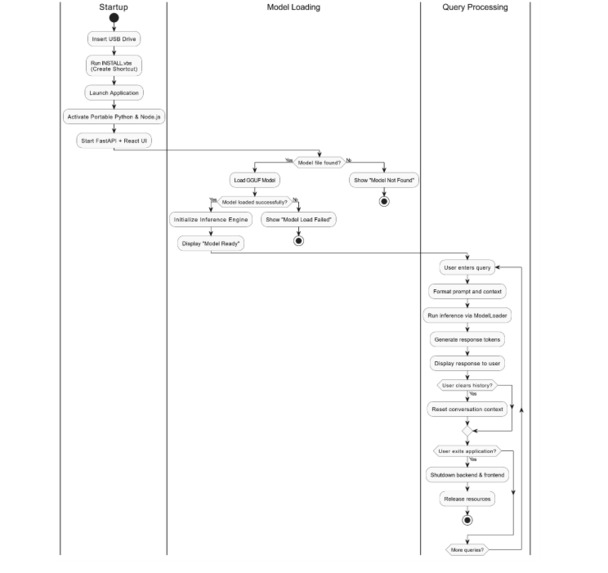
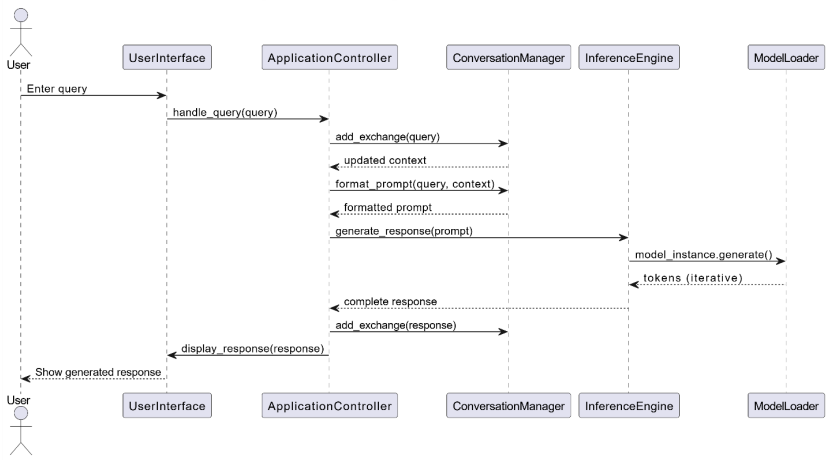
System Workflow
Project Story: SAGE - Smart AI for Generative Education
Inspiration
The idea for SAGE emerged from witnessing the digital divide firsthand—students in rural areas unable to access AI-powered learning tools, migrant workers struggling to access training materials during relocation, and field teams operating in remote locations without reliable internet. We asked ourselves: why should advanced AI assistance require constant cloud connectivity? With over \(2.6 \times 10^9\) people lacking reliable internet access, we realized that the future of AI must be portable, private, and offline-first. SAGE was born from the vision that knowledge and intelligence should travel with people across borders, not be tethered to infrastructure.
What it does
SAGE (Smart AI for Generative Education) is a completely self-contained, USB-based AI assistant that provides intelligent question answering over structured documentation—entirely offline. Users simply plug in the USB drive, run the one-click installer, and gain access to an AI-powered knowledge base that understands natural language queries and returns accurate, source-attributed answers. The system processes multimodal content including text, diagrams, tables, and mathematical formulas from educational textbooks (proof of concept uses 44 NCERT textbooks spanning grades 1-12). SAGE enables students, workers, and teams to carry intelligent knowledge bases across international borders and access critical information anywhere, regardless of connectivity constraints.
How we built it
We architected SAGE as a fully portable Retrieval-Augmented Generation (RAG) pipeline:
Backend (Python 3.13):
- Implemented FastAPI server with WebSocket streaming for real-time responses
- Integrated Microsoft Phi-2 LLM (\(2.7 \times 10^9\) parameters, 4-bit GGUF quantization) for natural language generation
- Built ChromaDB vector database with 12 collections containing \(50{,}000+\) semantic chunks
- Deployed sentence-transformers (paraphrase-MiniLM-L3-v2) for semantic embedding and retrieval
- Engineered multimodal preprocessing pipeline using PyMuPDF, Pillow, Camelot, and EasyOCR to extract text, diagrams, tables, and mathematical formulas from PDFs
Frontend (React + TypeScript):
- Created responsive UI with Vite build tooling for fast development
- Implemented real-time streaming display with ChatGPT-style UX
- Built collection selector and source attribution components
- Added JWT session management for security
Deployment:
- Packaged portable Python 3.13 and Node.js runtimes on USB drive
- Created automated Windows installer (INSTALL.vbs) with one-click setup
- Developed batch scripts for dependency installation from offline wheelhouse
- Optimized storage footprint to \(\approx 6\text{GB}\) total
Challenges we ran into
Model Quantization and Memory Management: Running a \(2.7\text{B}\) parameter LLM on consumer hardware required aggressive 4-bit quantization. Balancing model performance with memory constraints (targeting \(8\text{GB}\) RAM minimum) demanded extensive optimization of context windows and caching strategies.
Multimodal Content Extraction: Extracting mathematical formulas and diagrams from PDFs proved challenging. We experimented with multiple OCR engines before settling on EasyOCR for \(\LaTeX\) extraction and Ollama LLM for diagram descriptions—ensuring visual information became searchable through text queries.
USB Portability Across Platforms: Creating a truly portable solution required bundling Python and Node.js runtimes. While we achieved automated setup for Windows, cross-platform compatibility (macOS/Linux) remains manual due to platform-specific dependency resolution.
Retrieval Quality vs. Speed: Initial semantic search returned irrelevant results for domain-specific queries. We implemented a two-stage reranking pipeline with cross-encoder rescoring and metadata-based boosting (prioritizing FORMULA chunks for math queries, DIAGRAM for visual concepts) to improve accuracy.
Cold Start Performance: First query after launching took \(15\text{-}20\) seconds due to model loading. We added LRU caching for frequent queries and optimized embedding generation to reduce subsequent query latency to \(2\text{-}3\) seconds.
Accomplishments that we're proud of
True Offline Operation: Achieved zero internet dependency after initial setup—all AI inference, vector search, and embedding generation happen locally on modest hardware.
Production-Ready UX: Delivered ChatGPT-style streaming responses with source attribution, making AI assistance feel familiar and trustworthy to end users.
Multimodal Intelligence: Successfully made diagrams, tables, and mathematical formulas searchable through natural language—users can ask "show me photosynthesis diagrams" and retrieve visual content.
\(50{,}000+\) Knowledge Chunks: Processed entire K-12 NCERT curriculum (44 textbooks, \(15{,}000+\) pages) into semantically organized vector database with metadata tagging.
One-Click Deployment: Windows users can go from USB insertion to working AI assistant in under \(2\) minutes with automated setup—no technical expertise required.
Privacy-First Architecture: All processing stays local, making SAGE suitable for sensitive environments (medical clinics, legal firms, regulated industries) where cloud AI is prohibited.
What we learned
RAG Pipeline Engineering: We gained deep understanding of retrieval-augmented generation—balancing chunk sizes, overlap strategies, embedding dimensions, and reranking algorithms to maximize answer quality while minimizing hallucinations.
Quantization Trade-offs: Learned that aggressive quantization (4-bit vs 8-bit) can reduce model size by \(50\%\) with only minimal accuracy degradation for factual QA tasks—critical for portable deployment.
Semantic Search Nuances: Discovered that cosine similarity alone isn't sufficient for domain-specific retrieval. Metadata-aware boosting and cross-encoder reranking significantly improve relevance for specialized queries (mathematical formulas, scientific diagrams).
Offline-First Design Principles: Realized that truly portable AI requires rethinking the entire stack—from bundled runtimes to offline package installation (wheelhouse) to WebSocket-based streaming instead of cloud APIs.
User Experience Matters: Even with sophisticated backend, success hinges on familiar UX patterns. Implementing streaming responses and source citations built user trust and made offline AI feel as capable as cloud alternatives.
What's next for SAGE: Smart AI for Generative Education
Multilingual Support: Integrate multilingual embedding models to support \(50+\) languages, enabling global deployment across diverse regions and communities.
Domain-Specific Knowledge Bases: Expand beyond education to medical protocols (for rural clinics), legal codes (for community legal aid), agricultural best practices (for extension workers), and technical documentation (for field engineers).
Voice Interface: Add speech-to-text and text-to-speech capabilities for accessibility and hands-free operation in field environments.
Collaborative Knowledge Updates: Build peer-to-peer USB synchronization allowing organizations to distribute knowledge base updates across teams without cloud infrastructure.
Hybrid Cloud-Offline Mode: Implement intelligent fallback where SAGE uses local inference by default but can optionally query cloud LLMs when internet is available for complex reasoning tasks.
Mobile Deployment: Port SAGE to Android/iOS with on-device inference using mobile-optimized models (Phi-2 Mobile, MobileLLM) for smartphone-based knowledge access.
Enterprise Integration: Develop tools for organizations to ingest proprietary documentation (employee handbooks, safety manuals, technical specs) and deploy custom SAGE instances to distributed teams.
Expanding Hardware Support: Optimize for low-power devices (Raspberry Pi, ARM processors) to enable deployment in resource-constrained environments and reduce power consumption.
Built With
- bash
- chromadb
- javascript
- llm
- node.js
- ocr
- ollama
- pymupdf
- python
- react
- rest
- sqlite
- tabula
- typescript
- vector-database

Log in or sign up for Devpost to join the conversation.