-
-

Flowchart of the application
-

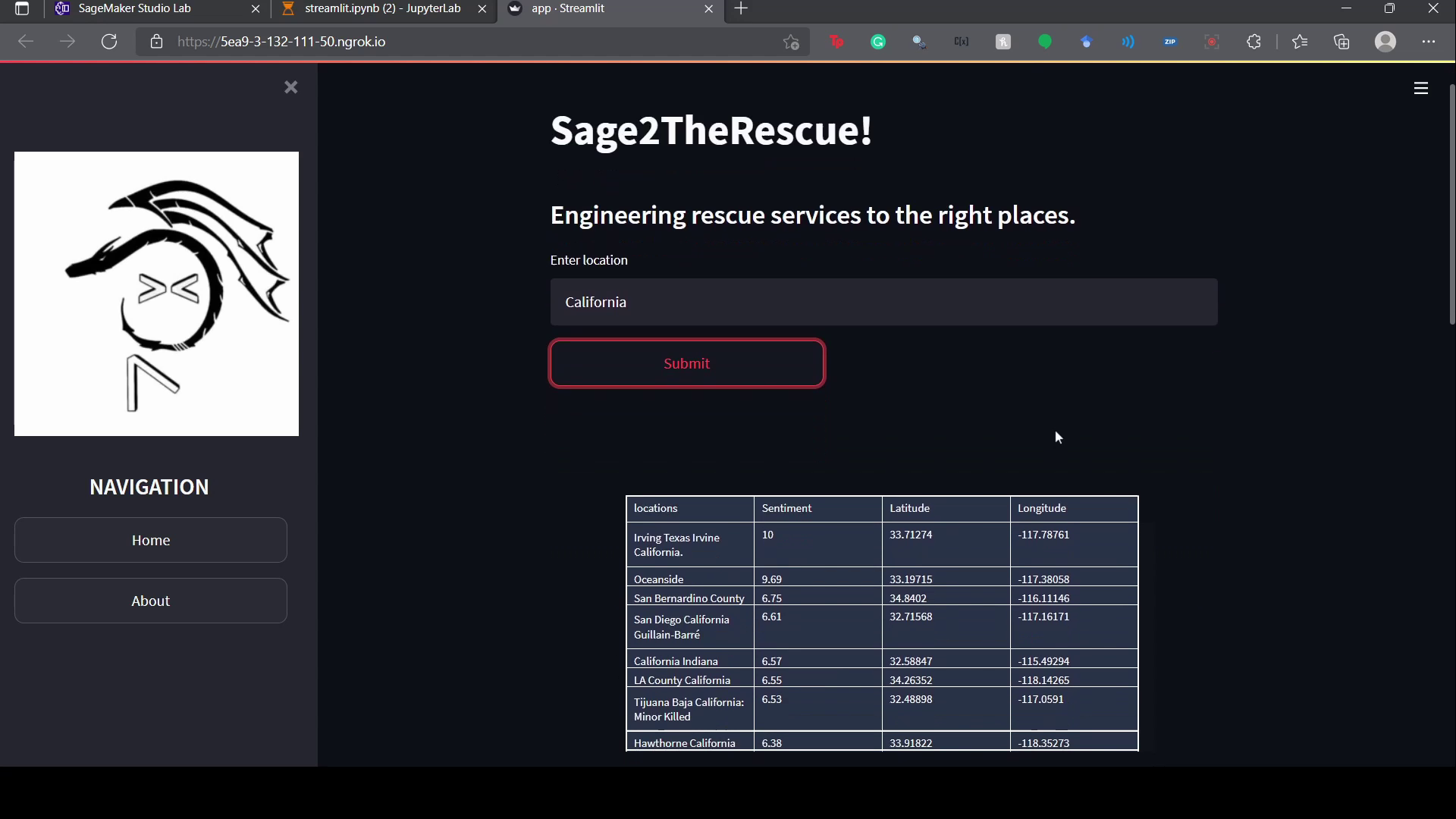
Scores Table of each location
-

Bar Graph of each of the locations
-

Map plotting all the locations
-

TechStack




Inspiration
During Cyclone Fani, which hit Odisha in 2019, a lot of places ran out of electricity, water, and other basic necessities. During this period, most of the rescue workers relied on data accumulated pre-disaster to guide rescue services, but this was far off from the on-ground reality where many places were in much worse of a situation than what was predicted. This is why we have developed this application to help guide rescue services in real-time using data from Twitter. Even during the cyclone, many parts of the city had mobile data running even though electricity and satellite television were not available. This is where our application comes into use; by accessing the data posted to Twitter, we help guide rescue services towards the areas that need it the most.
What it does
The application uses tweepy to retrieve tweets in real-time using keywords given by the user. At the time of a disaster, the city or state can be entered by the user into our application. Using the keyword received it retrieves all the tweets available, giving priority to the most recent tweets. These tweets we then run through a disaster prediction SVC model which was built using sagemaker. This model helps to eliminate tweets that are not disaster-related so that we only account for valid tweets. The newly generated set of tweets that contain only disaster-related tweets is now run through a sentiment analysis model to determine the negativity or positivity of a tweet. Using the sentiment analysis model we assign a float value score between -1 and 1 to each tweet. Now we use Spacy to extract the locations present in each of the tweets and add the score from the tweet to determine a total score for each location based on the sentiment of the tweets describing these places.
How we built it
- SVC model from sklearn to determine whether a tweet is disaster-related
- BERT model to determine sentiment behind each of the tweets
- AWS Sagemaker to train both the SVC and BERT models
- Spacy to extract the location keywords from the tweets
- Tweepy to extract the tweets
- Streamlit to deploy the app with a UI
- HERE API to obtain the coordinates of each of the locations
Challenges we ran into
- The biggest challenge we faced was to find the right datasets for each of the models. When looking for a dataset to check whether the tweet is disaster-related or not, most of the datasets were very biased, so we couldn't combine multiple datasets.
- Normalizing and scaling the scores in an appropriate fashion to adequately score the severity of disaster in each location
Accomplishments that we're proud of
- Obtaining map markers that are appropriately scaled and are a good representation of the actual scenario
- We made an original contribution to the HuggingFace Community. We employed our fine-tuned DistilBERT model
What we learned
- Classification of textual data from tweets between disaster or not using sklearn
- Distilled BERT transformer model for sentiment analysis
- Using Spacy NER to extract location data from the tweets, which helps us find the location of those in need
- Using HERE API integration for geocoding
- Using folium, a python library for maps to plot the map and find a graphical representation of those in need
What's next for Sage2TheRescue
- Implementation on a larger scale, taking older tweets into account as well
- Deploying on a host server accessible to all those who need it
- Making the disaster identification model more accurate using a larger dataset
Built With
- bert
- here-geocoder
- python
- pytorch
- sagemaker
- sklearn
- spacy
- streamlit







Log in or sign up for Devpost to join the conversation.