-
-

Logo
-
Tech Stack

Inspiration
Spot Robots are often purchased for specific uses that occur infrequently, e.g. search and rescue, highly radiated environment work, and other hazardous situations - resulting in low utilization of the spot robots. We believe these robots can add dynamic value by integrating the robot with state-of-the-art multi-modal generative AI models. These models can be leveraged, in combination with text-to-speech, to provide value on an everyday basis while also increasing opportunities for collaboration with workers in order to normalize the use of mobile robots. We envision the integration of spot with these large language models as a way to complement expertise - e.g. a specialist at a factory is paired with a spot robot with complementary, different duties and routines.
What it does
Safety Spot allows for a greater review of a work environment, allowing for more eyes to be present. When started, the Safety Spot program follows a given employee. As the employee walks around the environment, Spot follows along, capturing a 360-degree picture of the entire environment around it. Each picture taken is then sent to OpenAI’s GPT-4 multi-modal model, paired with a prompt, to produce a safety evaluation of the pictured scene. Information such as potential Safety concerns, OSHA violations, etc is then generated. If a safety concern is detected, Spot stops, and speaks the generated text, allowing the employee to fix the problem/violation or get help from a supervisor. Imagine immediately discovering problems without needing to be an expert. Safety Spot allows for greater Workplace safety with little overhead.
How we built it
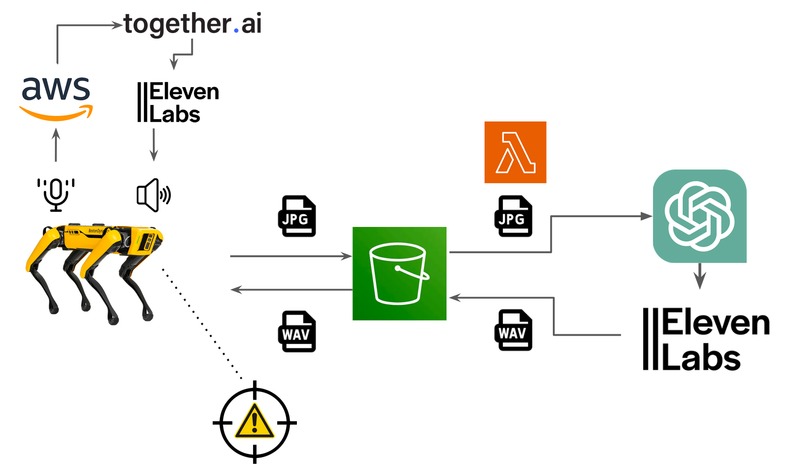
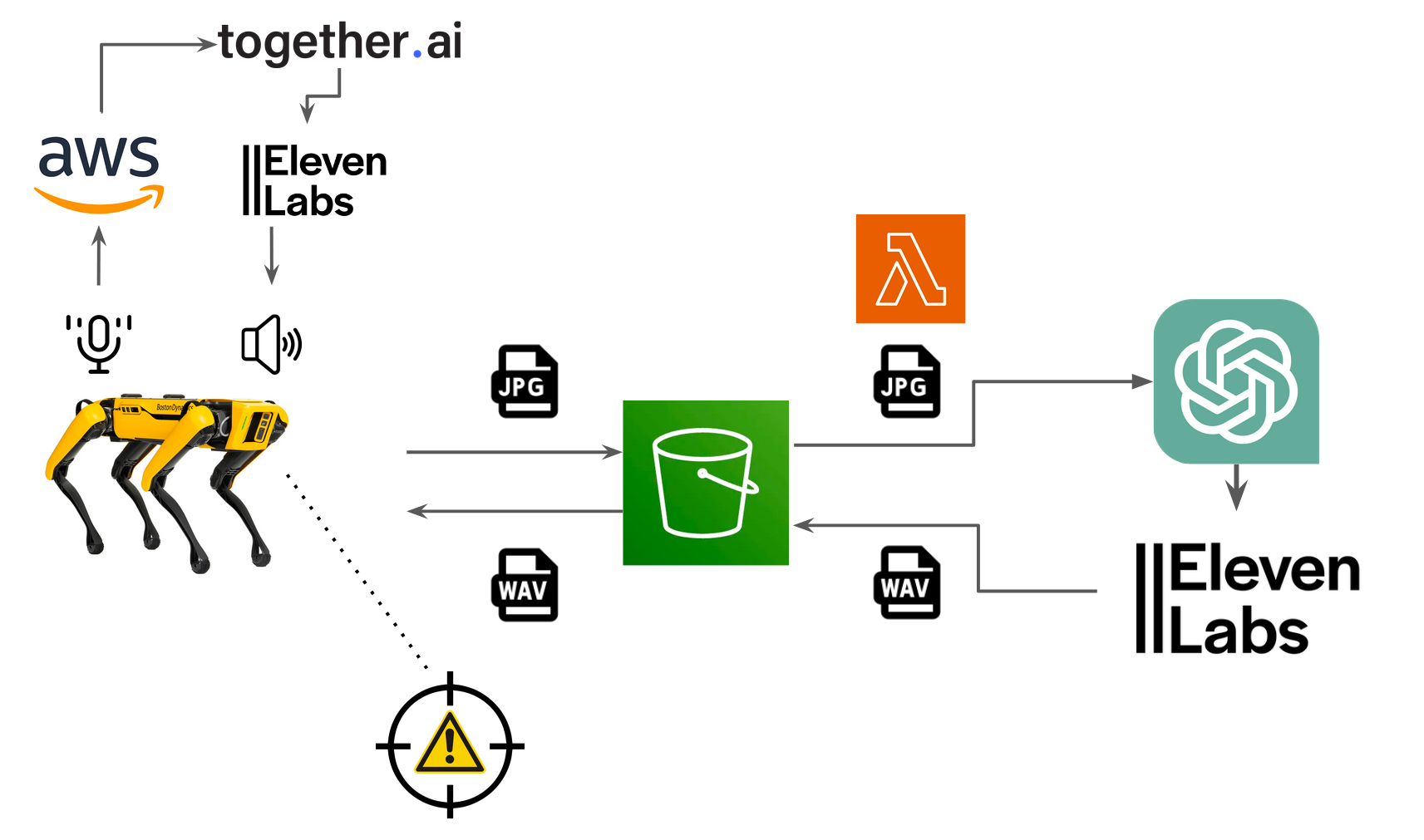
So how does Safety Spot work? You first employ Boston Dynamics’ Spot to follow any given person to traverse around its environment. Start the program and the Spot will detect the nearest fiducial image and follow the person. You are then all set to start traversing your environment and Spot will follow behind you at a distance of around 1 meter. As long as you have the fiducial, a spot will follow you, allowing for many different users. While moving, Spot captures two images of the environment with built-in cameras. Spot sends these images to an AWS bucket. Images are pulled from the buckets, paired with a prompt, and then fed into the OpenAI multi-modal to detect potential safety concerns. If there is a safety concern, the result of the generated text is converted into a .wav file. To generate a variety of regular responses, we use together.ai’s hosted large language model, llama-2-70b-chat, We use ElevenLab’s text-to-speech API to generate audio. The resulting .wav is converted to a Spot-compatible format and saved to the AWS bucket. The spot pulls the AWS bucket scanning if there is a new .wav file generated. Once a new .wav file is in the AWS bucket, the Spot robot fetches the .wav file, stops walking, and speaks about the recognized safety concern. The Spot then resumes following the user, allowing for more freedom in deciding what to do.
Challenges we ran into
The Spot we used came with additional sensors. However, when trying to access them and interface with them, countless missing dependencies were found. To even start development we had to debug the drivers and features. To download the drivers, we had to deal with the slow internet of the venue. We tried ethernet, attempted various wifis, and switched around the locations. We also had some various issues rebooting SPOT. There are additional sensors connected to the Spot core that we tried to interface with. In addition to the sensors provided by SPOT, we had additional hardware to use (mainly a Raizer Kiyo Bluetooth receiver, and Bluetooth speaker). Because the additional sensors weren’t tested beforehand, there was no guarantee that they would be compatible with the SPOT core. Even after debugging, we could not get the provided Razer Kiyo microphone to work.
Accomplishments that we're proud of
Although there were a myriad of problems we came across, the accumulation of smaller victories always pushed us to continue our project. The largest victory was debugging the sensors and drivers. Because the additional sensors weren’t tested beforehand, there was no guarantee that they would be compatible with the Spot core. Getting the speaker working with the new hardware gave us all the experience in debugging hardware. The usage of the Spot SDK was challenging, yet rewarding. Since Spot is capable of many features, learning the given movement commands and interacting with Spot required us to learn Spot events. Our next accomplishment was the interaction between Spot and the AWS buckets. Provided a challenge. Since we had to constantly upload to and from the AWS buckets, adjusting for bandwidth and response times served as a challenge.
What we learned
For the entire team, it was our first time interacting directly with hardware. The usage of Spot was a unique experience for all. Usage of the Spot-sdk and interfacing with sensors was a first for many. Live debugging with hardware allowed us to develop new skills and adapt quickly to unforeseen issues. Although not used in the final project, We also learned to interface with voice recognition. Our team was able to take audio commands and convert them into text, allowing for potential integration with the spot if we can get a different microphone. When it comes to debugging, the usage of resetting the machine can’t be understated. When debugging wifi, controllers, and drivers it is invaluable to have dedicated access to a simulator or the target device.
What's next for Safety Spot
We are interested in exploring what specialized knowledge will be most valuable for Safety Spot to leverage. Additionally, we can identify opportunities for multiple running Spots following multiple users, each outputting to the same set of AWS buckets. This allows for more eyes on your workplace, ensuring employee and workplace safety. Since we have the safety concern and the given picture, we can extend our system to send the data and pictures to a separate database, allowing for a third, professional eye to check the detected hazards. We believe that this backend can even be employed on Spot’s trademark ‘missions’ too, as it can passively send the images to the buckets while doing other tasks.
Built With
- amazon-web-services
- elevenlabs
- openai
- python
- speechrecognition
- spot-sdk
- together.ai



Log in or sign up for Devpost to join the conversation.