-
-
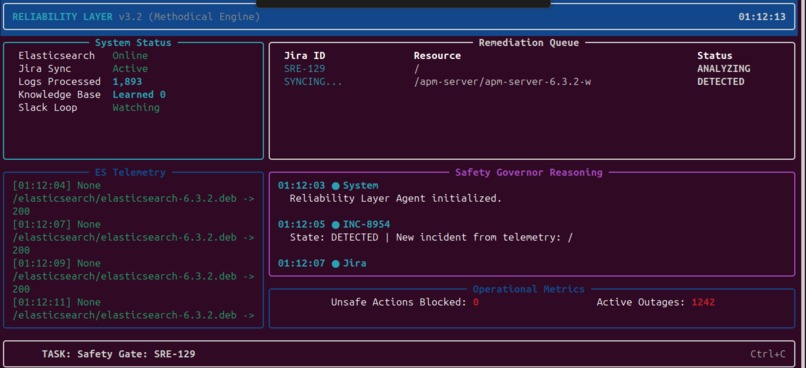
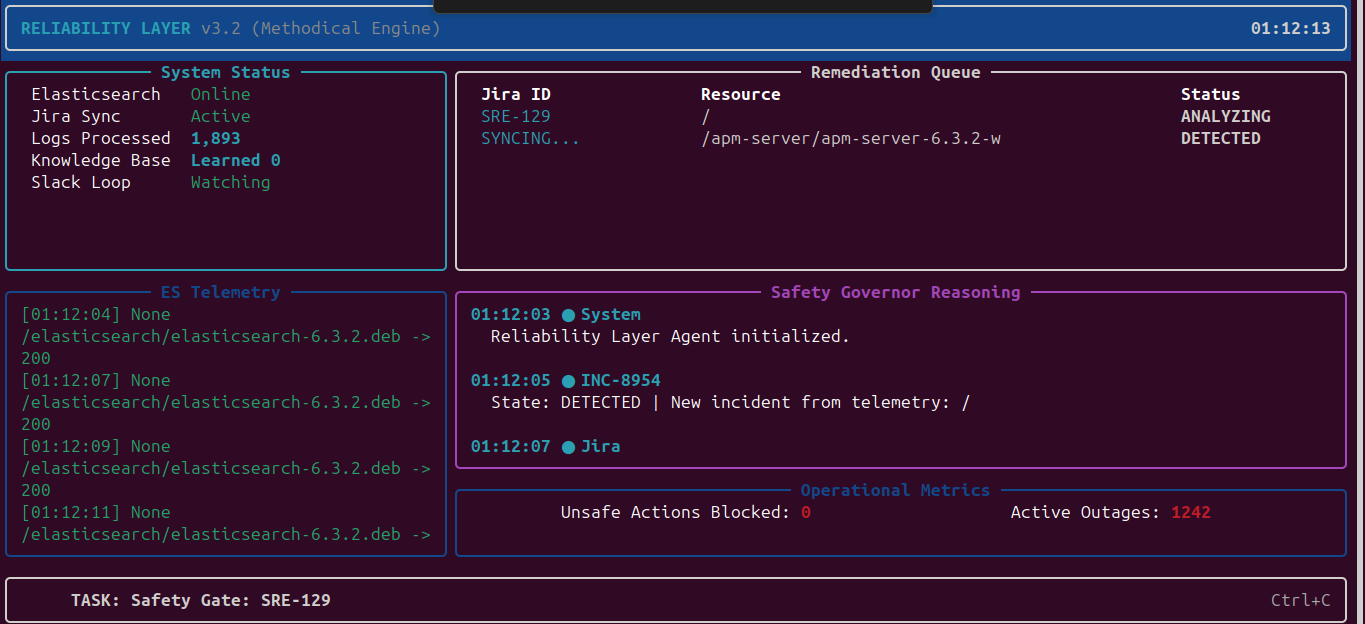
Safety Governor-TUI
Safety Governor: A Reliability Layer for Autonomous SRE Agents
Inspiration
While testing out and using various AI agents as part of my software development workflows, I realized that one of the most deterministic tasks in the software lifecycle (incident remediation and operational response) had seen the least trustworthy AI adoption. A further deep dive led me to identify silent failures which are difficult to track for vanilla LLMs. LLMs are decent at drafting code or summarizing logs. But when it comes to high-stakes operational decisions, they exhibit silent failure modes. They sound confident. They cite authority. They propose actions. But they often do so without grounding their claims in live evidence.
That realization led me to a deeper research arc around model reliability under stress. The perfect high-stakes use case emerged naturally: SRE incident remediation, where a hallucinated action can escalate a minor blip into a production outage.
The solution is not better prompting but architectural separation between reasoning and enforcement.
What It Does
Safety Governor is a reliability layer that wraps every AI-generated remediation plan in a deterministic:
$$ \textbf{Plan} \rightarrow \textbf{Stress} \rightarrow \textbf{Compress} \rightarrow \textbf{Gate} \rightarrow \textbf{Execute} $$
pipeline before any action reaches production.
The workflow is genuinely agentic. It retrieves its own evidence autonomously via MCP tools attached to an Elastic Agent Builder agent. But the final safety gate is enforced by Python, independent of the LLM.
The LLM cannot talk its way past the gate.
How I Built It
Stack
- Elastic Agent Builder (Elastic Cloud): the agentic runtime; handles tool planning, tool calling, and synthesis
- FastMCP 3.0.2: Python MCP server framework using
@mcp.tool()decorators with Streamable HTTP transport - Elasticsearch: stores runbooks, evidence, policies, live logs, incident records, workflow events
- Kibana: surfaces the agent, dashboards, and audit trail
- Slack: approval workflow with human in the loop; thread replies parsed for
APPROVE/FORCE_OVERRIDE - Jira: autonomous ticket lifecycle; ticket ID propagated through gate decision and Slack message
- Rich: terminal TUI for demo; 4 worker threads (logs, audit, agent reasoning, Slack)
I started by building the basic workflow entirely in Python and incrementally replaced different components with the Agent Builder agent, MCP server, and Jira and Slack integrations. This approach allowed the workflow to evolve naturally — each tool was introduced because it improved the system’s reliability, not simply to make the system appear agentic.
Deterministic Safety Gate
The gate is intentionally independent of the LLM.
Hard constraints include:
- Any policy conflict →
block_and_escalate - $n_{\text{contradictions}} \ge 2$ →
block_and_escalate - Insufficient evidence coverage →
block_and_escalate - Critical severity →
block_and_escalate(requiresFORCE_OVERRIDE)
Formally:
$$ G(p, s) = \begin{cases} \texttt{block_and_escalate}, & \text{if safety constraints violated} \ \texttt{execute}, & \text{otherwise} \end{cases} $$
This separation ensures:
- Auditability
- Deterministic behavior
- Model-independence
- Tamper resistance
The LLM influences reasoning, not enforcement.
Challenges I Ran Into
Designing Gate Thresholds
If thresholds are too strict, every incident escalates.
If too lenient, unsafe actions slip through.
Balancing safety and autonomy required multiple scenario simulations.
Preserving Gate Independence
It was tempting to let the LLM evaluate safety directly.
However, if the gate also ran inside the same LLM context, the trust boundary would collapse. Deterministic Python enforcement was necessary to preserve audit guarantees.
Accomplishments I'm Proud Of
- True multi-step agentic orchestration using Elastic Agent Builder and MCP tools
- A deterministic trust boundary between AI reasoning and production
- Live contradiction detection via Elasticsearch evidence queries
- Refusal logic: the system can deny
APPROVEfor critical incidents - Full forensic audit trail: every tool call, confidence shift, gate decision, and override is indexed
- Closed-loop runbook learning after successful resolution
- A live demo that shows both:
- Safe autonomous execution
- Hard-blocked incidents with enforced override
- Safe autonomous execution
What I Learned
Governance Is a Systems Problem
Trust does not come from better prompts.
It comes from:
- Evidence retrieval
- Contradiction measurement
- Deterministic enforcement
- Auditability
Determinism Matters in Production
If identical inputs can produce different enforcement outcomes due to temperature or model drift, the system cannot be trusted.
Separating reasoning from enforcement is essential.
Reliability Scores Should Calibrate, Not Dictate
CDCT, DDFT, and EECT adjust the sensitivity of the pipeline. They do not directly control the gate. This keeps enforcement legible and auditable.
What’s Next for Safety Governor
Closed-Loop Threshold Tuning
Human overrides should dynamically recalibrate gate thresholds over time.
Multi-Model Adversarial Planning
Planner and Verifier agents running on different LLM backends to increase robustness.
Anomaly-First Prevention
Integrate Elastic ML anomaly detection to shift from remediation to prevention.
Production-Grade MCP Hosting
Deploy MCP services as hardened microservices rather than development-mode exposure.
Policy-as-Code Integration
Allow enterprises to define custom enforcement logic declaratively.
Safety Governor does not attempt to make LLMs perfect.
It assumes they are fallible and builds a governed execution layer around them.
It executes only when its reasoning survives stress-testing.
Built With
- elasticsearch
- fastapi
- fastmcp
- jira
- kibana
- python
- rich
- slack

Log in or sign up for Devpost to join the conversation.