

Inspiration
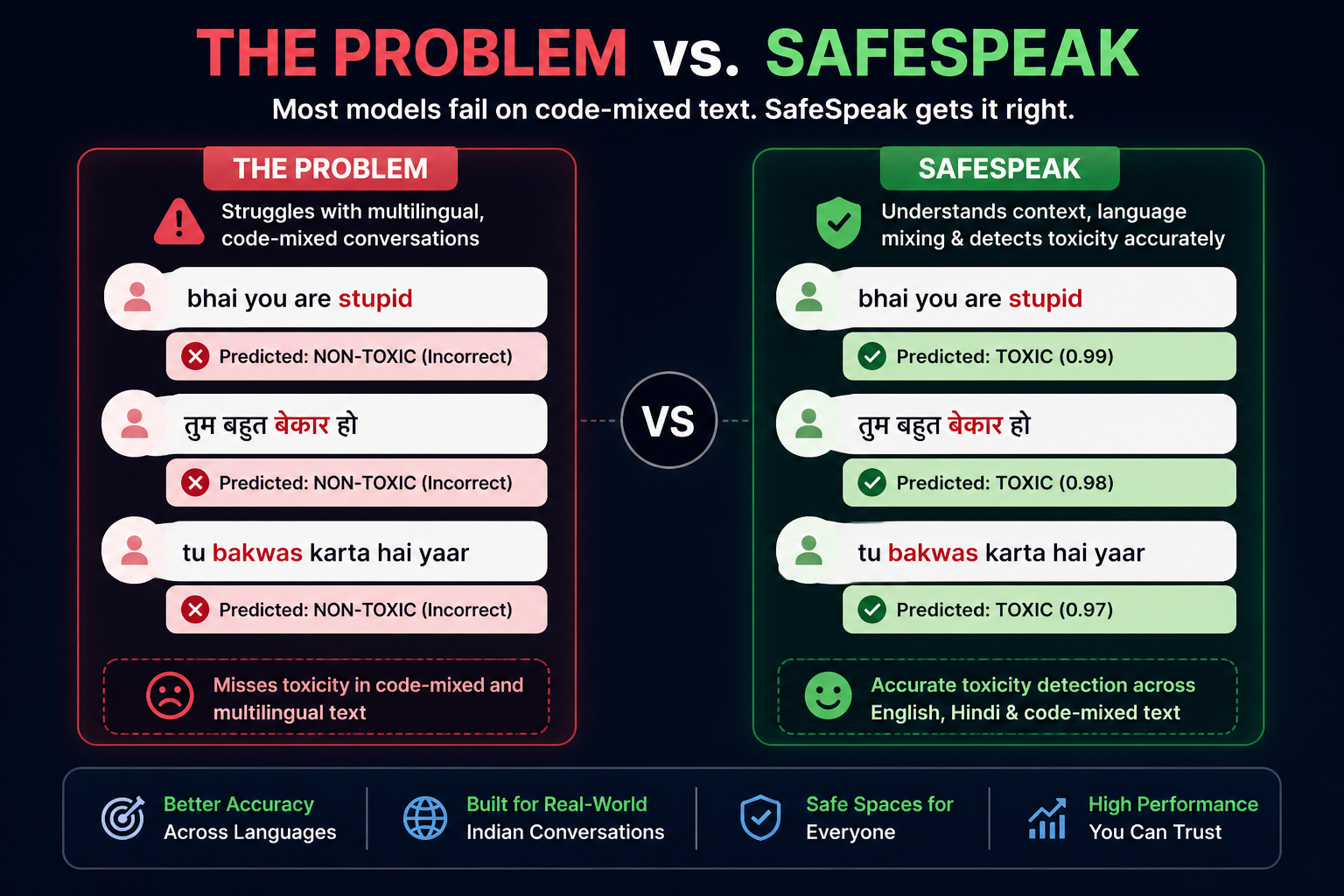
Most toxicity classifiers fail the moment someone writes "bhai tu bahut stupid hai" — a single sentence mixing Hindi and English the way millions of Indian users naturally communicate.
We tested multiple moderation tools on code-mixed data. Over 40% of these inputs were misclassified — not because the models were weak, but because they were not designed for multilingual, mixed-language text.
SafeSpeak was built to close this gap: a toxicity detector that works when language boundaries don’t exist.
What it does
SafeSpeak classifies user-generated comments as toxic or non-toxic across:
- English ("you are stupid")
- Hindi ("तुम बहुत बेकार हो")
- Code-mixed inputs blending both languages
It also handles borderline phrasing where toxicity is implied.
The system outputs:
- Binary label (0 = non-toxic, 1 = toxic)
- Confidence score for moderation decisions
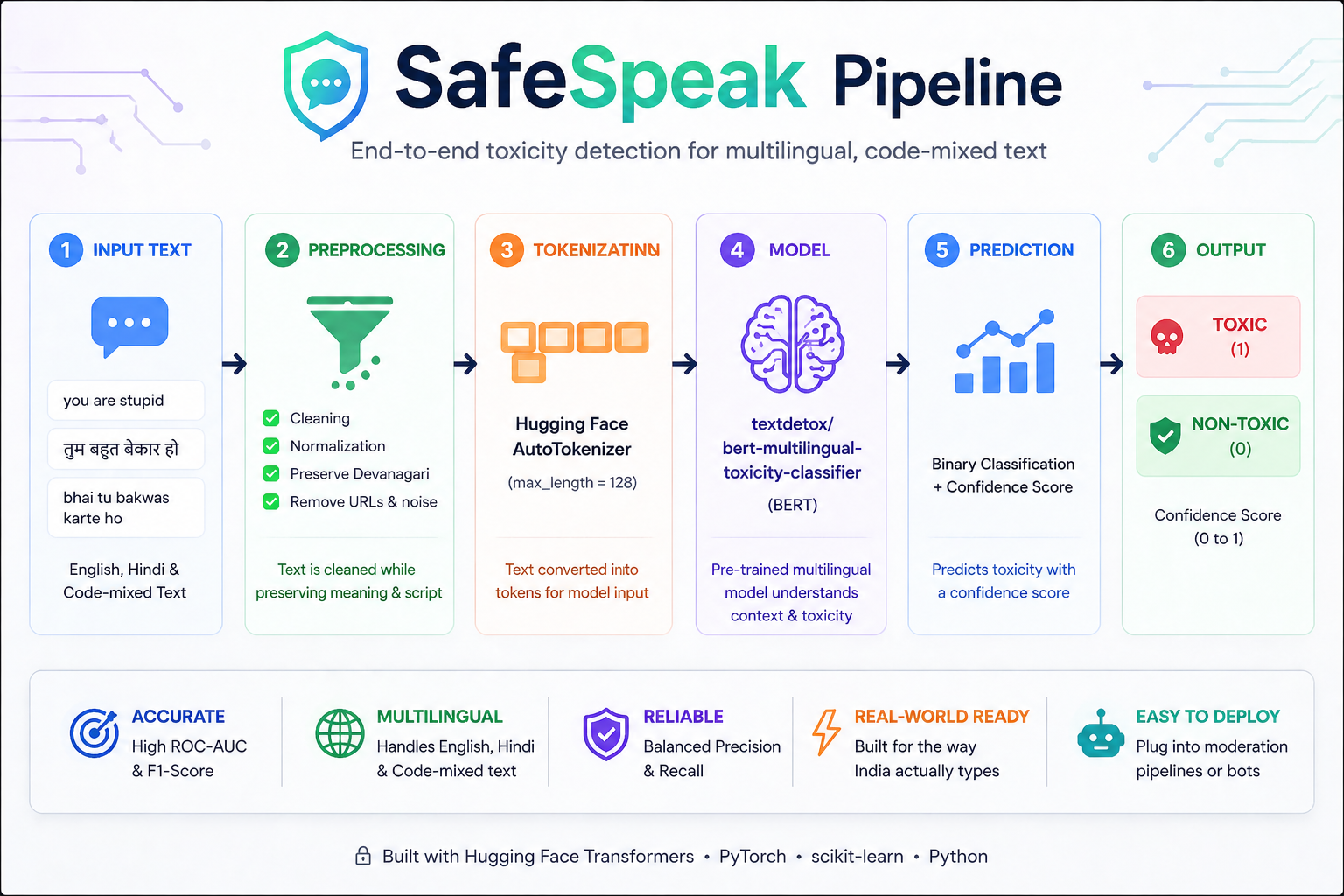
How we built it
Model: textdetox/bert-multilingual-toxicity-classifier — pretrained on multilingual toxicity corpora.
Pipeline:
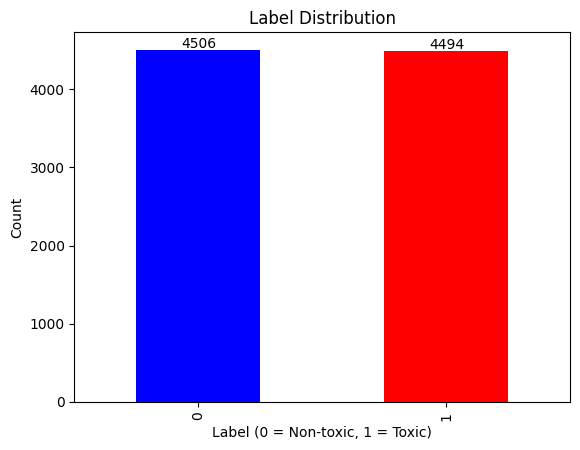
- Data cleaning (nulls, duplicates, preserving Devanagari text)
- Tokenization using Hugging Face tokenizer
- Stratified 80/20 train-validation split
- Zero-shot evaluation before training
- Fine-tuning (learning rate 2e-5, warmup_steps=270, weight decay=0.01)
- Evaluation using ROC-AUC and classification metrics
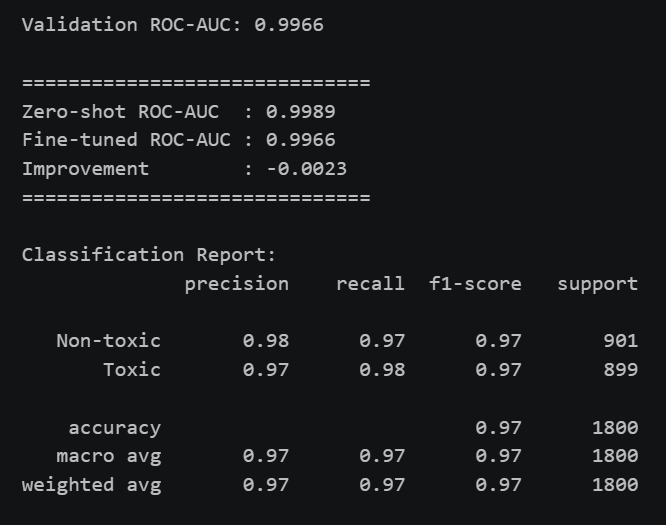
A key design choice was evaluating the model before fine-tuning to ensure transparent results.
Results
- ROC-AUC (fine-tuned): 0.9966
- ROC-AUC (zero-shot): 0.9989
- Accuracy: 97%
- Macro F1-score: 0.97
Balanced precision and recall ensure reliable moderation without excessive false positives.
Challenges we ran into
- Handling code-mixed Hindi + English text without breaking linguistic meaning
- Designing preprocessing that preserves Devanagari characters
- Debugging dependency conflicts in Colab (transformers version mismatch)
- Maintaining performance when starting from an already strong pretrained model
Accomplishments that we're proud of
- Built a pipeline that handles mixed-script (Latin + Devanagari) input
- Achieved ROC-AUC 0.9966 with 0.97 macro F1
- Verified results with reproducible outputs
- Implemented zero-shot vs fine-tuned comparison for transparent evaluation
What we learned
Starting from a domain-matched pretrained model changes what fine-tuning can realistically achieve — and reporting the baseline honestly is what makes the result credible
What's next for SafeSpeak
- Multi-label toxicity classification (threats, hate speech, harassment)
- Expand to models like XLM-R for broader language coverage
- Deploy as a Telegram/Discord moderation bot
- Build a real-time API for production use
Built With
- hugging-face-transformers
- matplotlib
- numpy
- pandas
- python
- pytorch
- scikit-learn


Log in or sign up for Devpost to join the conversation.