-
-

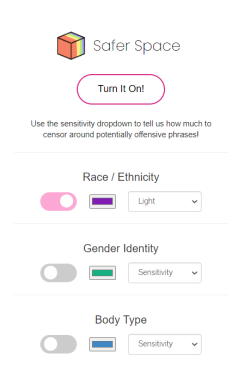
The popup for our extension.
-

Demonstration of the dropdown menu to choose sensitivity level in our extension.
-

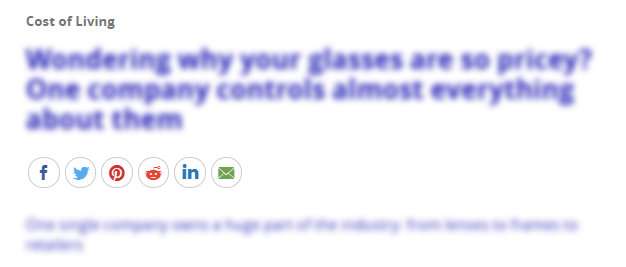
Demonstration of the blurring effect, which is especially effective on text with smaller font.
-

The Chrome view of our extension.


Inspiration
We noticed that many social media platforms have a “flagging” feature for content involving sensitive subjects; however, our team was curious as to why this feature was not applied to general internet browsing as there is generally much more sensitive content on websites and articles. As a result, we decided to create a Chrome extension that would achieve a similar task to social media’s “flagging”, where the extension would find certain “flagged” words on the user’s current webpage.
What it does
Safer Space is a Chrome extension that aims to censor words, phrases, or paragraphs that may be offensive or discriminatory against minority groups. The extension uses a Python natural language processing (NLP) module to find potentially offensive messages and blurs out the corresponding text on the web page to warn users about it.
How we built it
We created most of the Chrome extension using HTML, CSS, and JavaScript along with the Google Chrome Developers API. For determining which words were discriminatory, we used a “Hate Speech” (insert link) data set and the Python NLTK module to train a Natural Language Processing classifier. We then implemented it in our extension using JavaScript, jQuery and Flask.
Challenges we ran into
Since we couldn’t access data and variables across scripts, we needed to use chrome.storage.sync to save and retrieve data from the Chrome browser. We were extremely confused as to how to implement this into our code and spent hours stuck and debugging errors. Eventually, through lots of head-scratching, we were able to get the chrome.storage.sync to work.
Furthermore, the integration between the HTML section of our extension with the Python section was much more difficult than we thought. We had to use jQuery with Flask to use the machine learning functionality which could not be translated to JavaScript; however, none of our team members had been involved with Flask in any previous projects. Thus, we ran into numerous issues with localhost, servers, and proper information transfer and query handling, which we eventually managed to debug with perseverance and significant time investments.
Accomplishments that we're proud of
- We were able to combine our front-end and back-end together well (implementing a NLP module into our Chrome extension by using Flask) despite having very little experience with it
- We managed to set up global variables to communicate across different JavaScript files (this was a lot more difficult than we anticipated as this couldn’t be achieved by simply importing into the script)
What we learned
- How to cross reference scripts in our extension (as this had to be done in an unconventional manner)
- How the “popup”, “content”, and “background” JavaScript files are responsible for different functionalities in the extension
- How to select between and tune different machine learning algorithms, especially working with NLP where input is very difficult to translate into numerical values
- Implementing jQuery and Flask to allow our machine learning (NLP) algorithm to communicate with our JavaScript files
- How to set up a local hosted server and transfer information between JavaScript and Python
- How to use pickle to transfer trained ML models from one development environment to another
What's next for Safer Space
- UI and functionality improvements - it can always be better!
- Host Flask app on an external service so that the Chrome extension can be made available to the public
- Train more NLP classifiers for different types of discrimination
- Use more training datasets to improve the classifier and more accurately flag words
- Train our model on data from diverse sources and labeled by individuals with diverse backgrounds; this will help avoid bias through training data
- Implement a program by which users can contribute by indicating the extension’s accuracy at labeling words, thus providing more data and allowing the classifier to continually improve







Log in or sign up for Devpost to join the conversation.