-
-
Extension
-
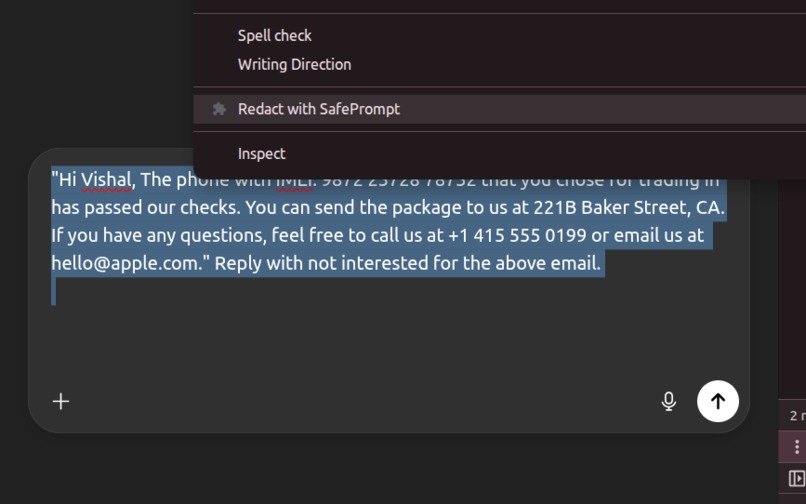
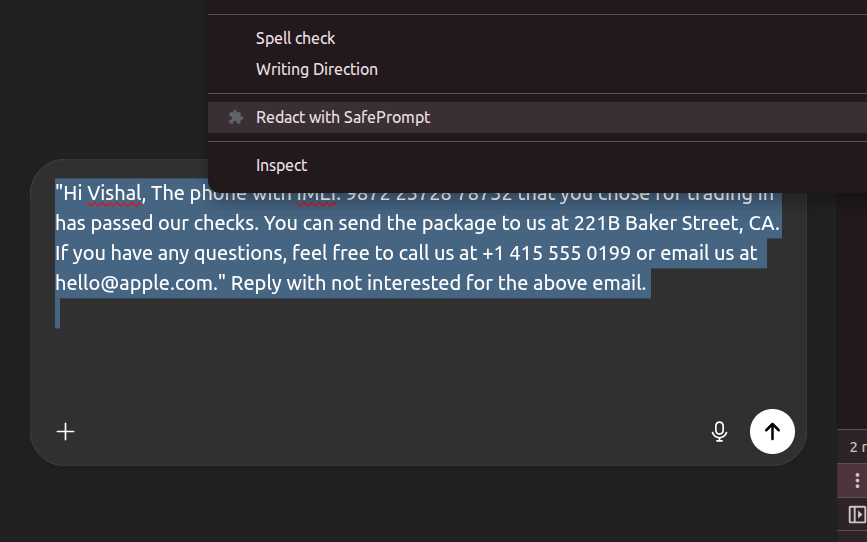
Option to Redact
-
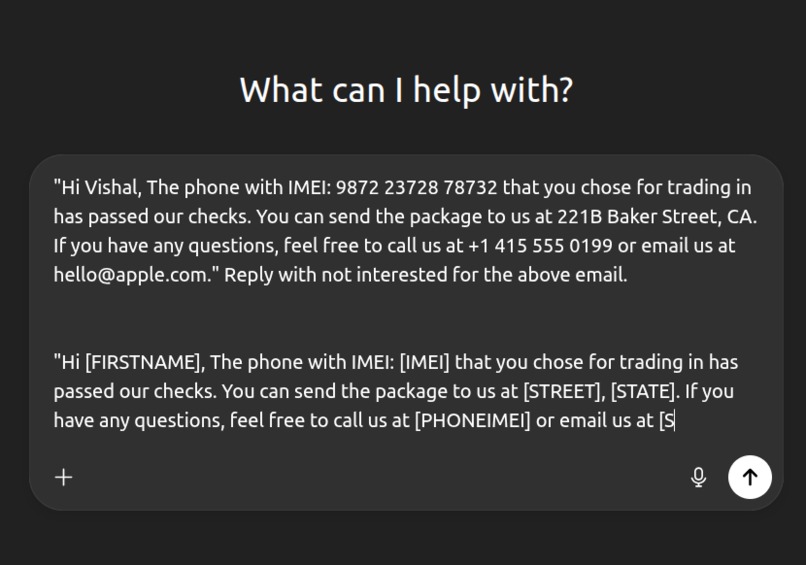
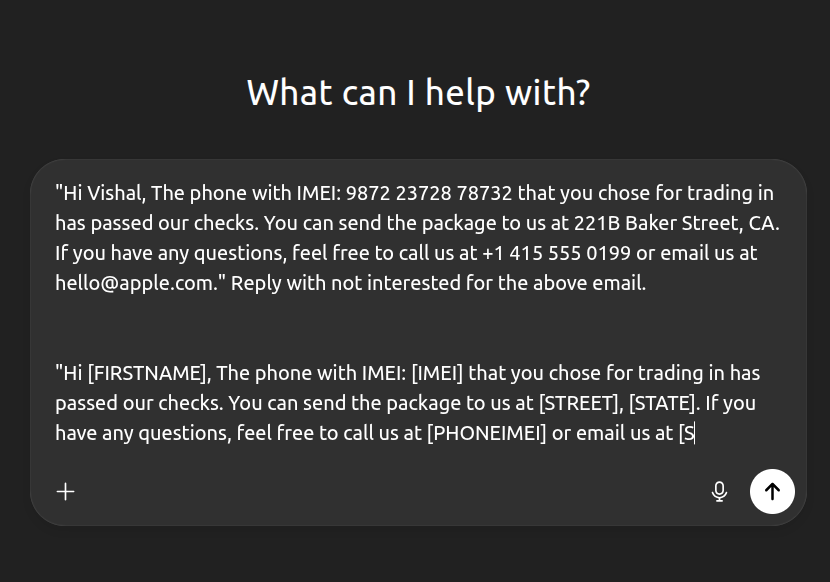
Output
Inspiration
Every product demo starts with a great prompt—and too often that prompt contains emails, phone numbers, license keys, or IDs that shouldn’t leave the browser. Regex-only filters miss edge cases; LLM-only filters can hallucinate or drift. We wanted something pragmatic and developer-friendly that keeps the text intact, masks only the sensitive values, and gives teams a simple, dependable contract they can build around.
What it does
Lumina (processdocuments) redacts sensitive values in any selected text and returns the same sentence with placeholders like [EMAIL], [PHONE], [SSN], etc., wrapped in a strict <safe>…</safe> block. A minimal Chrome extension adds a right-click action (“Redact with SafePrompt”) that replaces the selection in inputs/contentEditable fields or copies the safe text to the clipboard. Under the hood, a small FastAPI service runs locally, so your text never leaves your machine, and optional validator “seatbelts” (regex) enforce masking for common entities.
How we built it
We fine-tuned Llama 3.2 3B Instruct with LoRA/PEFT on the ai4privacy/pii-masking-200k dataset, training on our university’s Nautilus research platform and publishing adapters to Hugging Face: chinu-codes/safe-prompt-llama-3_2-3b-lora. The inference path is deliberately lightweight: a CPU-only FastAPI server loads the base model + adapters, applies a chat template, generates deterministically, trims to the first </safe>, and runs optional regex validators before returning the single <safe>…</safe> string. The Chrome MV3 extension calls this local endpoint and either replaces the selection inline or falls back to copying/opening a data tab with the result.
Challenges we ran into
Loading a 3B model on CPU is tight on memory; we hit OS kills and pipeline/device mismatches. We solved it by reducing sequence lengths, enabling low-memory loading, and fixing an accelerate + pipeline(device) conflict. Extension-side, some pages block script injection so we built resilient fallbacks (execCommand copy, data-URL tab) and a replace-in-page path for inputs and contentEditable regions. Finally, we balanced model output with deterministic validators to avoid rare leaks without over-masking.
Accomplishments that we’re proud of
We shipped an end-to-end experience that works entirely local on CPU with a clean developer contract: always one <safe>…</safe> block. The Chrome extension feels invisible—right-click, redact, done and the backend is a single file you can run with uvicorn. Publishing the adapters and custom handler to Hugging Face makes the model portable and future-proof for a managed endpoint if needed.
What we learned
Small, well-scoped contracts beat clever prompts: teaching the model to start the answer at <safe> and training with completion-only loss simplified everything. PEFT adapters are perfect for fast iteration on modest hardware, but CPU deployments need disciplined limits (seq length, max tokens, dtypes). And mixing LLM intelligence with tiny deterministic validators gives you the best of both worlds: quality plus guardrails.
What’s next for Lumina
Optional hosted inference using the included HF handler, on-device GGUF quant for ultra-low-RAM laptops, and a small popup UI with history and a “copy without tags” toggle. Integrate directly into document pipelines (batch redaction for PDFs, email threads, and chat transcripts) and add simple analytics so teams can measure residual leaks while keeping data entirely local.
Built With
- html
- javascript
- python
- tailwind

Log in or sign up for Devpost to join the conversation.