-
-
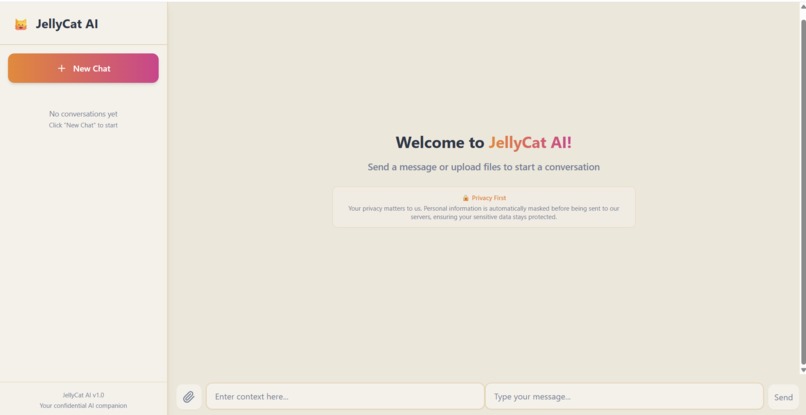
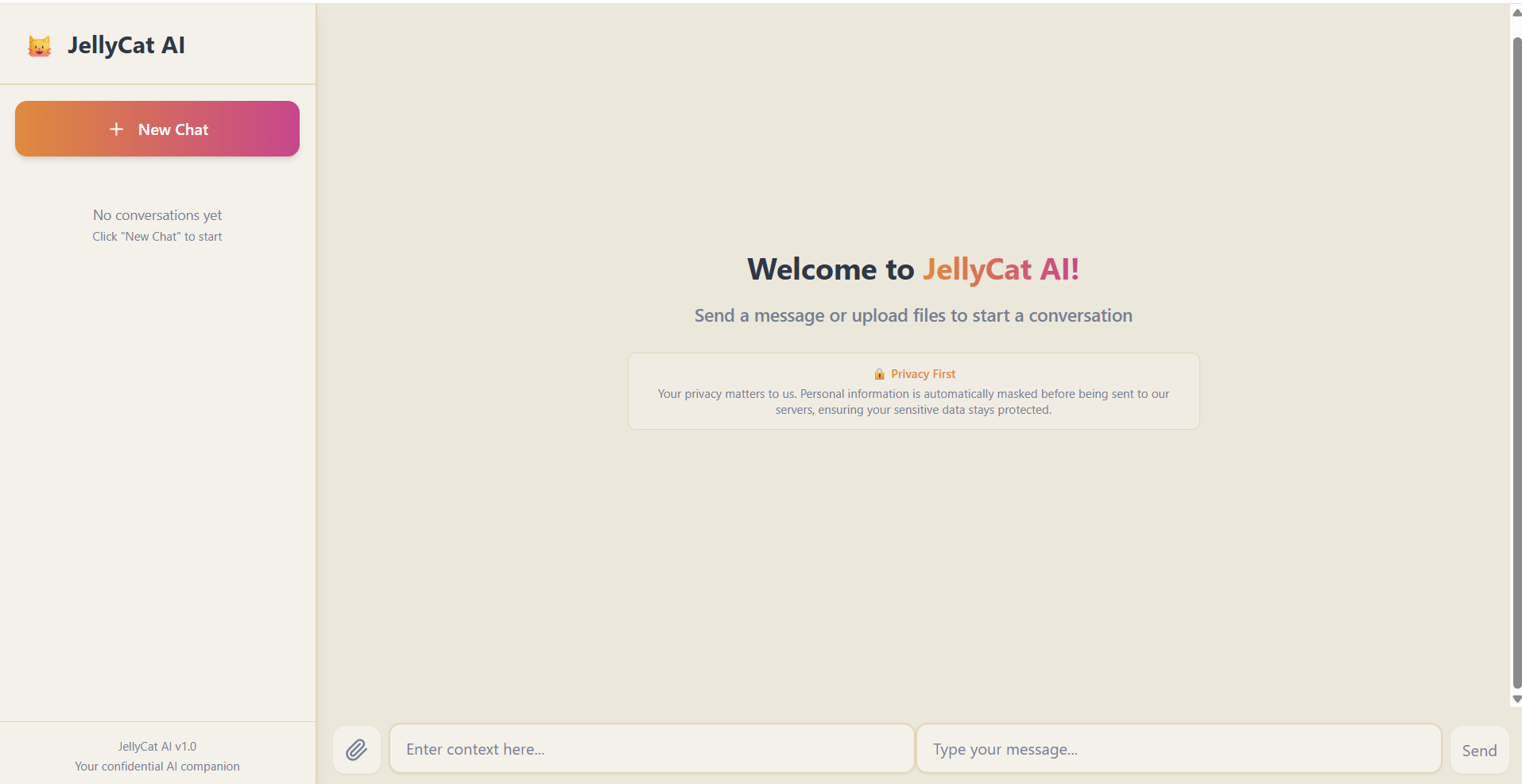
Landing page
-
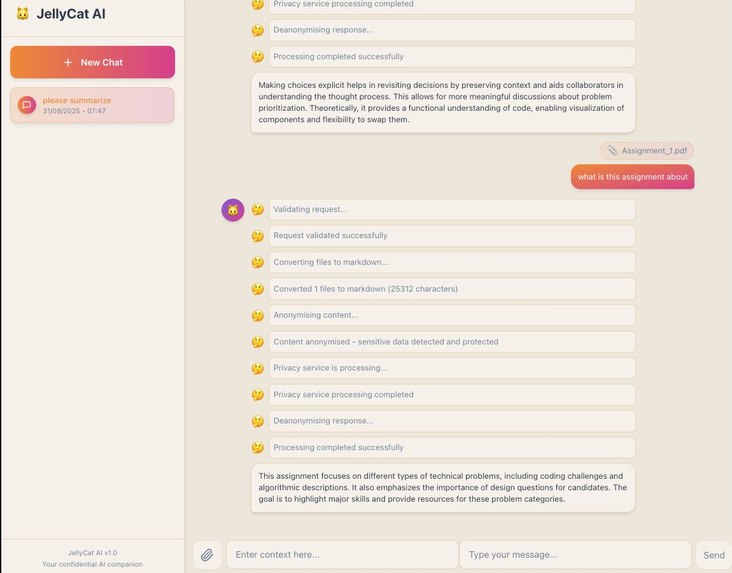
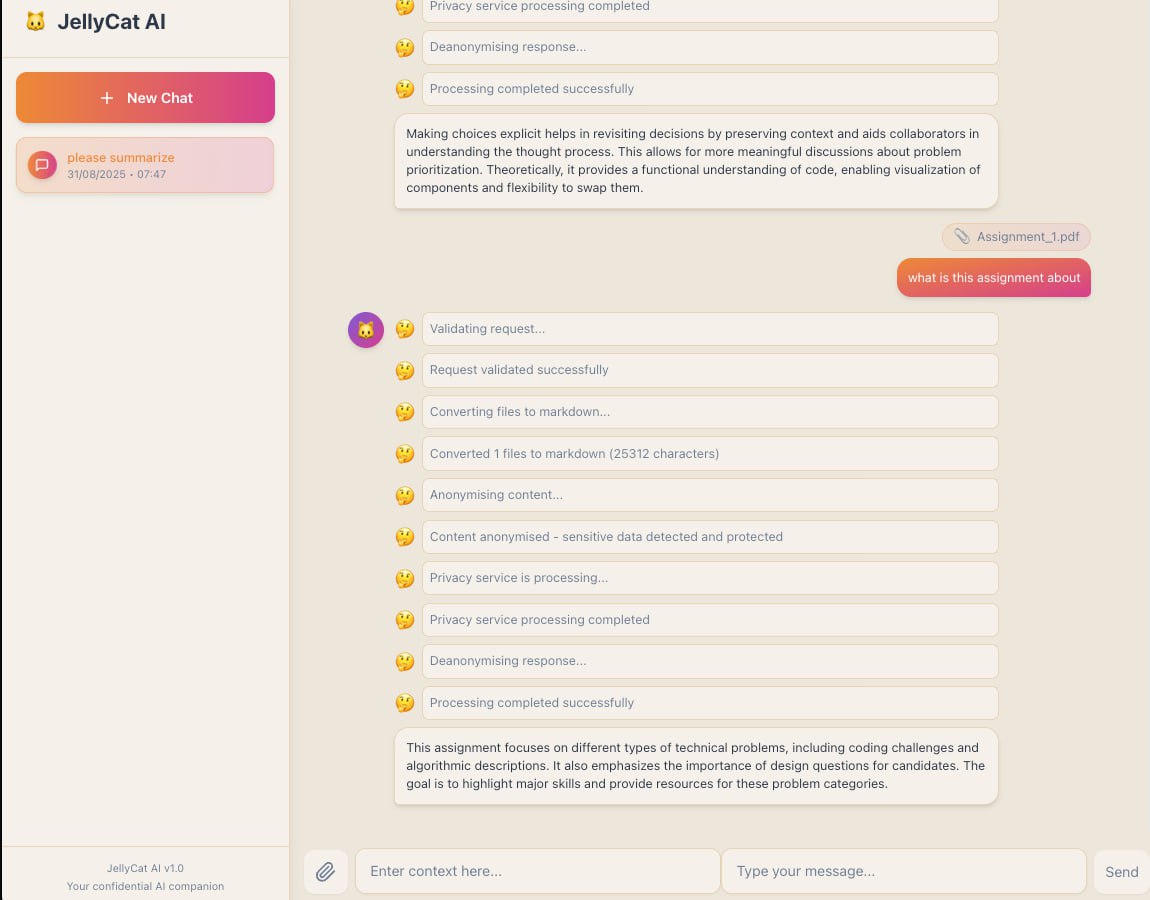
User chat
What Inspired JellyCats 🐱✨
We wanted to understand how more can be done to protect sensitive information about ourselves, which are sometimes taken very lightly. And since the worldwide adoption of GenAI is going to continue to increase, the importance for GenAI is going to increase as well. Hence, we wanted to challenge ourselves to come out with a feasible solution 💪🏻.
During the brainstorming and background research phase, we stumbled upon some interesting papers that enriched our understanding in privacy of GenAI and homomorphic encryption. Such as:
- “On Protecting the Data Privacy of Large Language Models (LLMs): A Survey” by Biwei Yan et al.
- “Encryption-Friendly LLM Architecture” DongWan Rho et al.
What We Learned! 🧠📚
- Good team work and project management. We had 2 members working on the privacy tools, RAG and LLM, and 3 members working on frontend and backend. There was a good split of work among us, and our tasks aligns with our expertise. Hence, the whole hackathon experience has been quite fun, and enriching.
- New technical skills: Each of us learnt some new technical skills as well. Those from ML background (Martin, SekYi) learnt some DevOps and software engineering skills. And those from Computer science (Terence, Joel, Wenhao) learnt some RAG and LLM skills.
- Privacy-Preserving AI is Possible: By combining tools like Microsoft Presidio for PII detection, homomorphic encryption for secure computation, and robust anonymization pipelines, we learned that privacy and AI can coexist. Also homomorphic encryption is a cryptographic method allowing computations on encrypted data without needing to decrypt it first. 🤯
- Deeper understanding of privacy leakage in LLMs:
Privacy leakage can occur in two ways:
- Passive privacy leakage
- Passive privacy leakage - Users themselves expose PII data to the LLM.
- Data leakage during model inference - LLM trained on sensitive data may be inferred.
- Active Privacy attacks
- Passive privacy leakage
Potential Solutions for Privacy-Preserving AI 🧠
After literature reviews and brainstorming, here is what is found out. In SafeGenAI, we have implemented the first solution.
- Anonymization and Pseudonymization: Anonymizing or pseudonymizing sensitive information, and aggregating data to reduce granularity. (Done in our Solution - SafeGen AI)
- Data Aggregation: Aggregate data at a higher level to reduce the risk of re-identification. For example, instead of storing individual inference query details, and aggregate queries by day or week.
- Deduplication: Remove duplicate entries from datasets to further protect user privacy.
Federated learning: Instead of sending raw data to a central server, only model updates are transmitted, keeping user data localized on their devices.
In LLM pre-training, federated learning eliminates the need for centralized data storage—training occurs on local devices, and only model parameters or updates are sent to a central server for aggregation. This drastically reduces data breach risks and addresses privacy concerns. (A hot topic in current research!)Differential Privacy: Apply mathematical techniques to ensure that the inclusion or exclusion of a single data point does not significantly affect the output, providing strong privacy guarantees.
How We Built It 🔧
- Backend: We used Python (Flask), with modular architecture, dependency injection, and state machines. Privacy features include PII detection/anonymization (Microsoft Presidio), homomorphic encryption (Pyfhel), and secure document processing. Redis is used for caching.
- Frontend: React (TypeScript, Vite) with real-time chat, file uploads, and streaming responses. Client-side validation ensures only safe files are uploaded. Infrastructure: Docker and Docker Compose orchestrate backend, frontend, and Redis.
- APIs: Integrated Google Gemini 2.5 Flash for LLM, LangChain for orchestration, and Microsoft Presidio for privacy.
What Makes SafeGenAI Unique ⭐️
SafeGenAI demonstrates that privacy-first AI is not only possible but practical. Our workflow ensures that sensitive data is anonymized and encrypted before any AI processing, and only de-anonymized at the very end—protecting users at every step. We really hope our project inspires others to prioritize privacy in AI innovation!✨
Challenges We Faced 😰
Throughout our development journey, we encountered several technical and conceptual challenges that shaped the direction of SafeGenAI.
Initially, we aimed to incorporate Lynx into our solution. However, due to time constraints and integration complexity, we decided to focus our efforts on perfecting the privacy-preserving RAG-LLM workflow.
Encryption Phase Hurdles
During the encryption phase, we faced multiple obstacles:
Approach 1:
We attempted to store encrypted data in a vector database, which only accepts strings. Our idea was to convert the encrypted ciphertext into bytes, and then into a string for storage. However, we discovered that converting bytes to a string and back is not lossless—the string representation of bytes cannot be reliably converted back to the original bytes, making decryption impossible. This forced us to rethink our storage strategy for encrypted data. Also, we cannot store Pytxt (Encrypted format) in the vector db because Homomorphic Encryption Is Not Designed for Semantic Search. Ie, they are not designed for high-dimensional vector similarity search.
Approach 2:
We wanted to secure the transfer of data from users’ edge devices to the cloud LLM by encrypting data on the edge and decrypting it in the cloud. Unfortunately, since we relied on publicly available cloud LLM APIs, there was no way to perform decryption within the LLM itself. This limitation highlighted the current gap in privacy features for commercial LLM services.
Approach 3:
Our literature review led us to the paper "Encryption-Friendly LLM Architecture", which explores enabling LLMs to operate directly on homomorphically encrypted data. While this approach is promising and could revolutionize secure AI inference, it remains an area of active research and is not yet practical for real-world deployment.











Log in or sign up for Devpost to join the conversation.