-
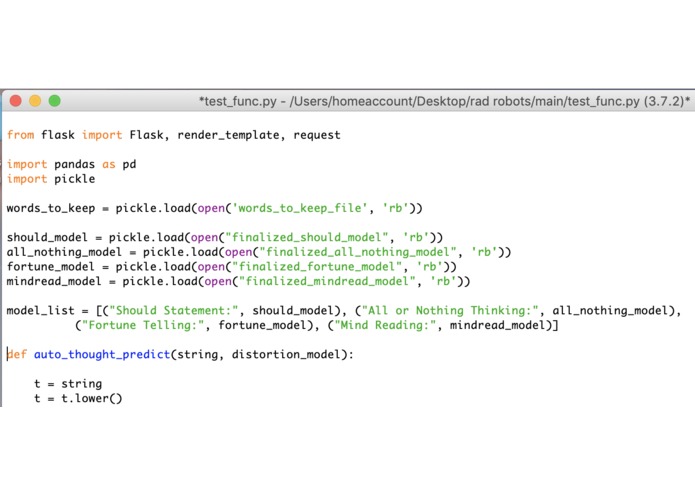
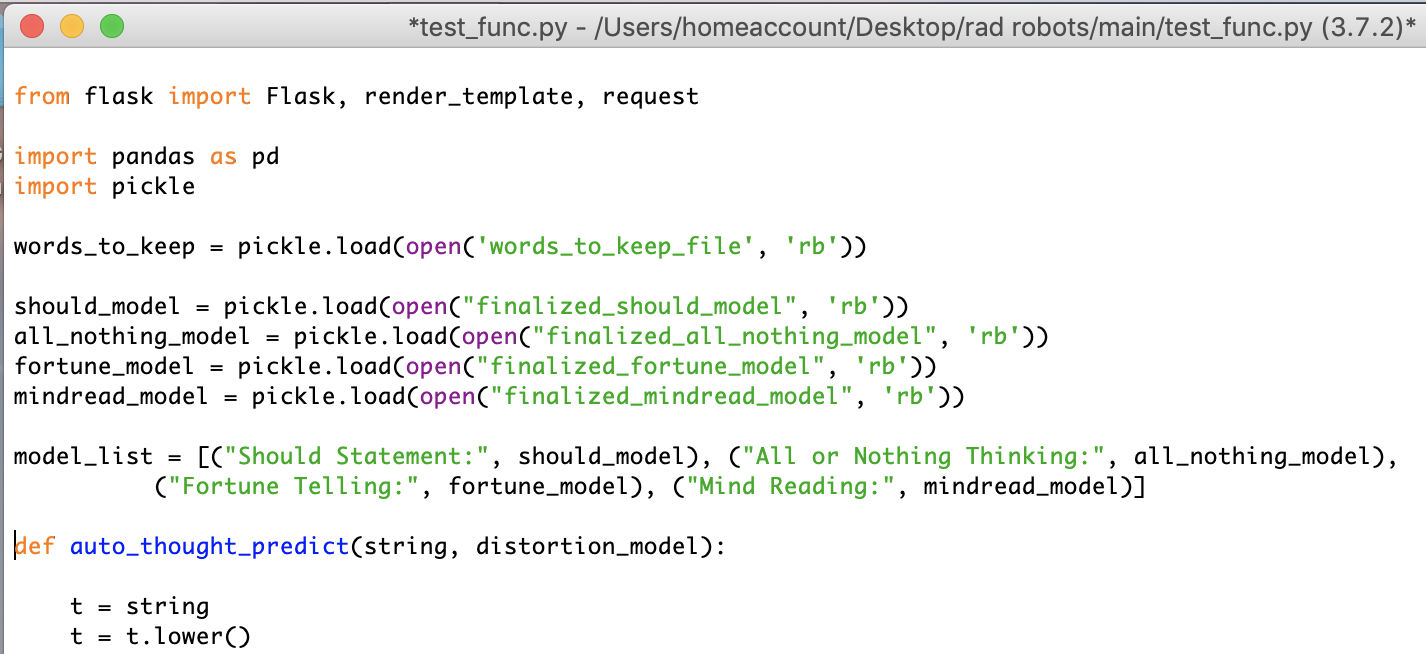
Header of the python code; runs four models to search for different cognitive distortions
-
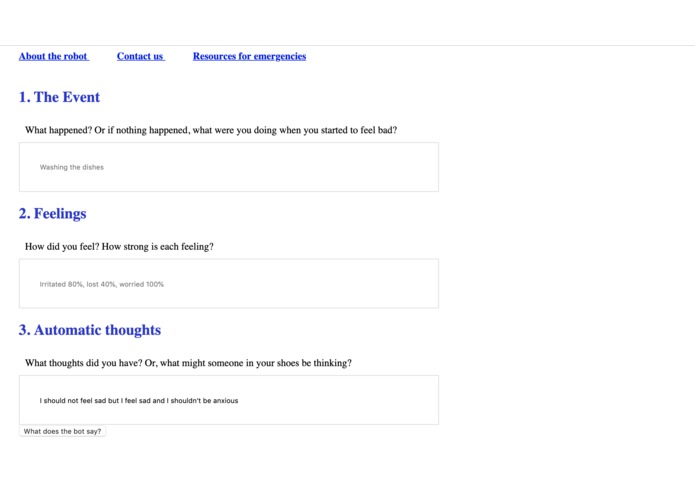
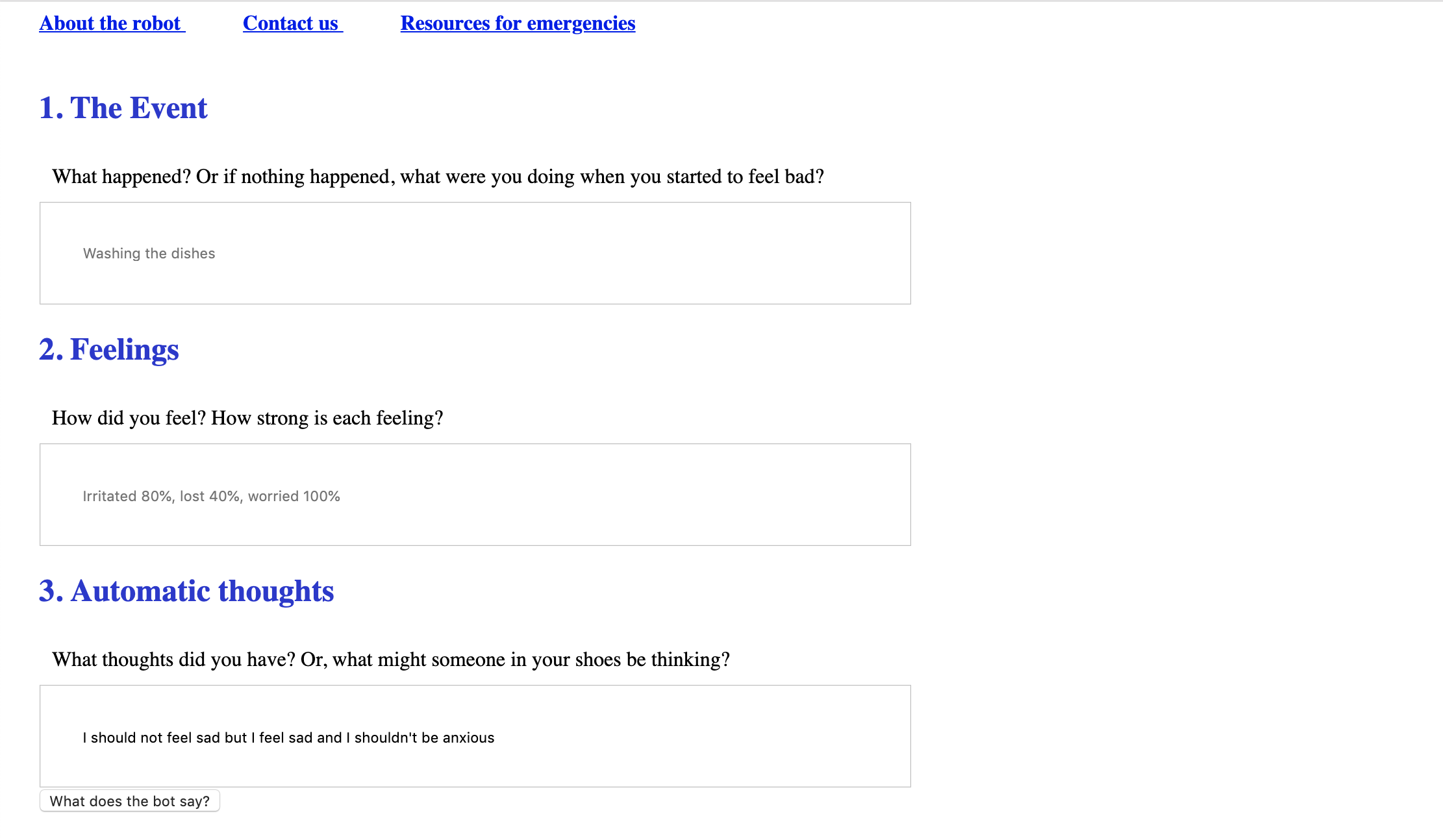
Submission page for automatic negative thoughts; site feeds models via Flask and returns probabilities of different distortions
-
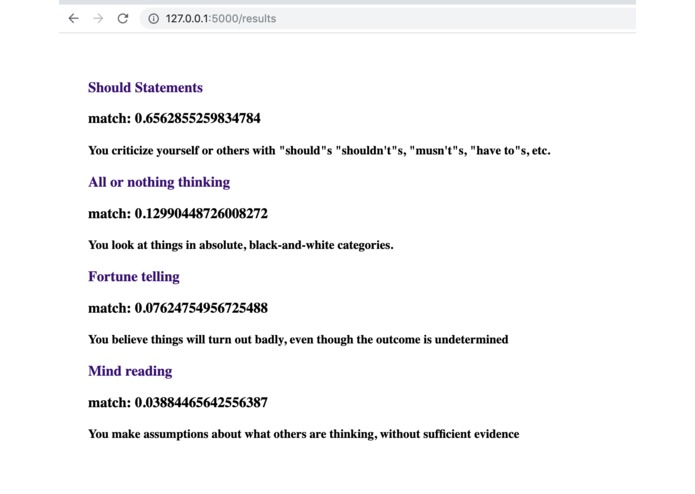
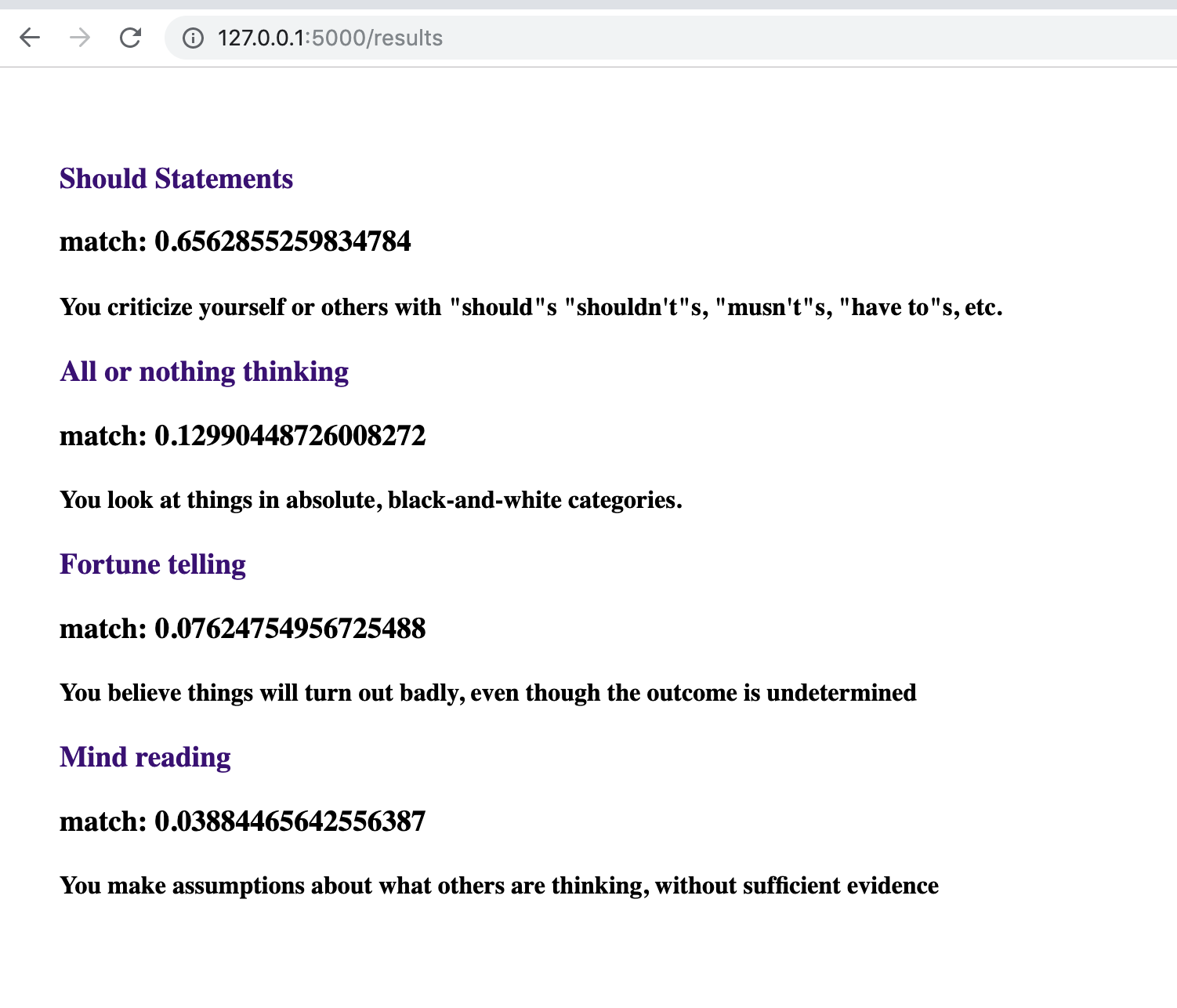
Output of models with raw probabilities of each distortion
-

Output of models with qualitative probabilities of each distortion

Inspiration
Cognitive behavioral therapy can be a highly effective treatment for depression, anxiety, and other disorders, but it requires the patient to learn skills such as how to identify distortions in their own thoughts. (And it can be particularly difficult to realize one's own biases.) We thought that natural language processing and machine learning might be able to identify these distortions, thereby helping the patient to "untwist" their thinking and to learn how to identify self-defeating thought patterns.
What it does
Our machine learning models use logistic regression to predict whether common cognitive distortions are present in the user's thoughts. We served the model to a web page, where it is integrated into a common cognitive behavioral therapy worksheet.
How we built it
We received examples of automatic thoughts from friends, and we also collected some examples from Reddit and a popular CBT handbook (the Feeling Good Handbook by Dr. David Burns.) Except for the examples from the book, which were already annotated, we manually annotated each example for the presence or absence of each distortion type. We reduced the feature space to relatively common words (occurring in at least four inputs) and then trained a separate model for each target.
Challenges we ran into
We had a very small set of annotated training examples, which may be one reason that our first approach, a naive Bayes classifier, did not work well.
Accomplishments that we're proud of
The machine learning works! Detecting these thought patterns automatically is possible, and with our pipeline, the tools necessary can be available to patients anywhere with an Internet connection.
What we learned
Steven made their first foray into machine learning and data handling in Python, and they learned to do natural language processing such as lemmatization. Kayley learned to serve a Python script in a web page with Flask, and she grew her rather new web development skills.
What's next for Sad Thoughts for Rad Robots
With a larger training set, we believe our model can achieve higher accuracy. With more data, we could also apply a deep learning approach, such as Recurrent Neural Networks (which could utilize words in sentences as a sequence rather than a "bag of words.") We would also like to extend our model to the eleven most common distortions (for the hackathon, we focused on just four). Also, actually using our fresh domain name: emotionsrunhigh.tech!
Built With
- html/css
- javascript
- python
- scikit-learn


Log in or sign up for Devpost to join the conversation.