-
-
-
-
-
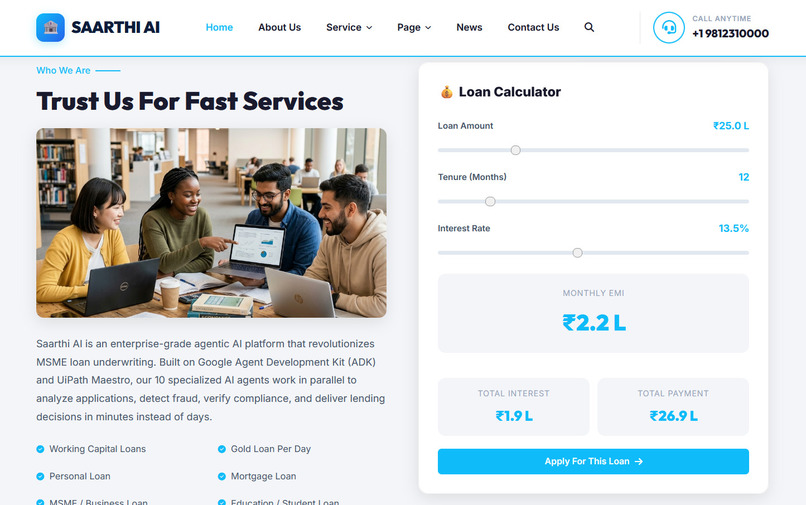
Home page
-
-
The Story of Saarthi AI: Reimagining MSME Loan Underwriting with Agentic AI
Inspiration
Micro, Small, and Medium Enterprises (MSMEs) form the bedrock of developing economies, contributing over 30% of the Gross Domestic Product (GDP). However, they face a massive credit gap. Traditional underwriting processes take days, sometimes weeks, to analyze a single loan application. For a business seeking a working capital loan, this delay can mean lost contracts or halted production.
The primary friction arises from fragmented and inconsistent financial data. Underwriters must cross-examine Goods and Services Tax (GST) returns, Income Tax Returns (ITR), bank statements, PAN cards, and Aadhaar cards. This manual validation is slow and prone to errors, and the cost of processing makes micro-loans financially unviable for many banks.
We set out to build Saarthi AI—inspired by the word Saarthi (meaning a companion or guide)—to revolutionize this process. Our goal was to create an intelligent system that reduces the underwriting cycle time from days to minutes while keeping humans in control.
How We Built It
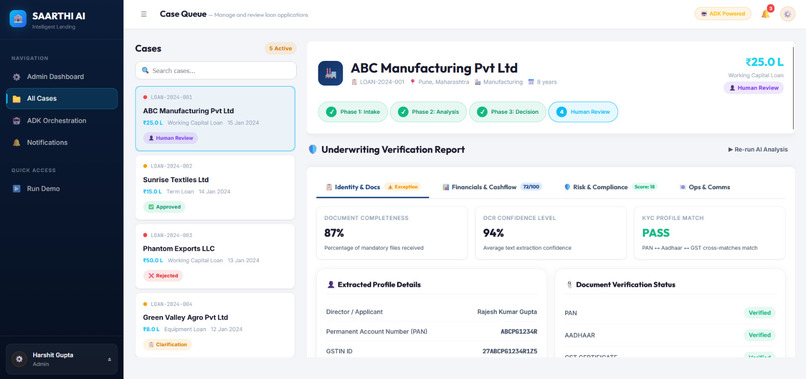
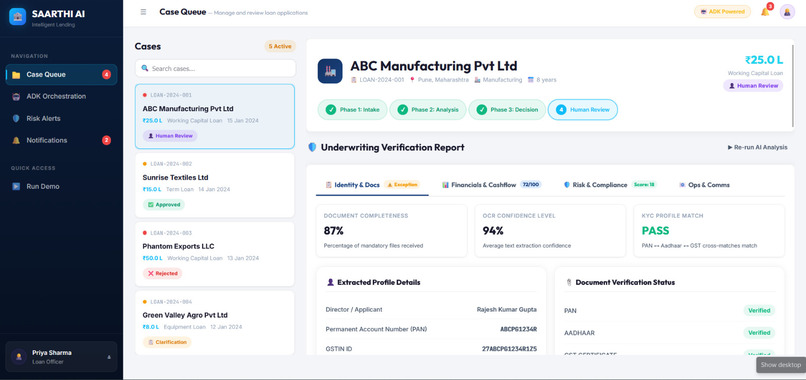
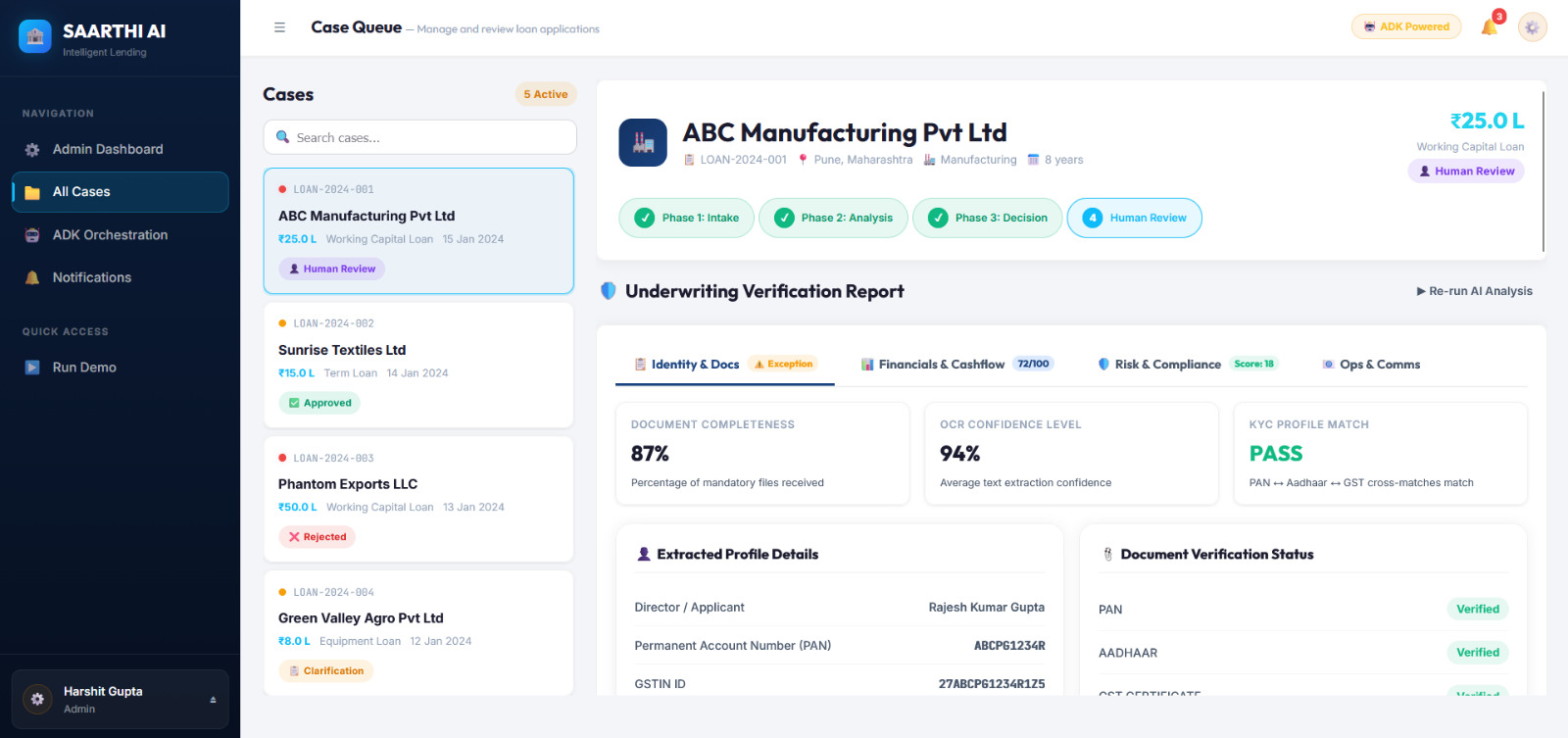
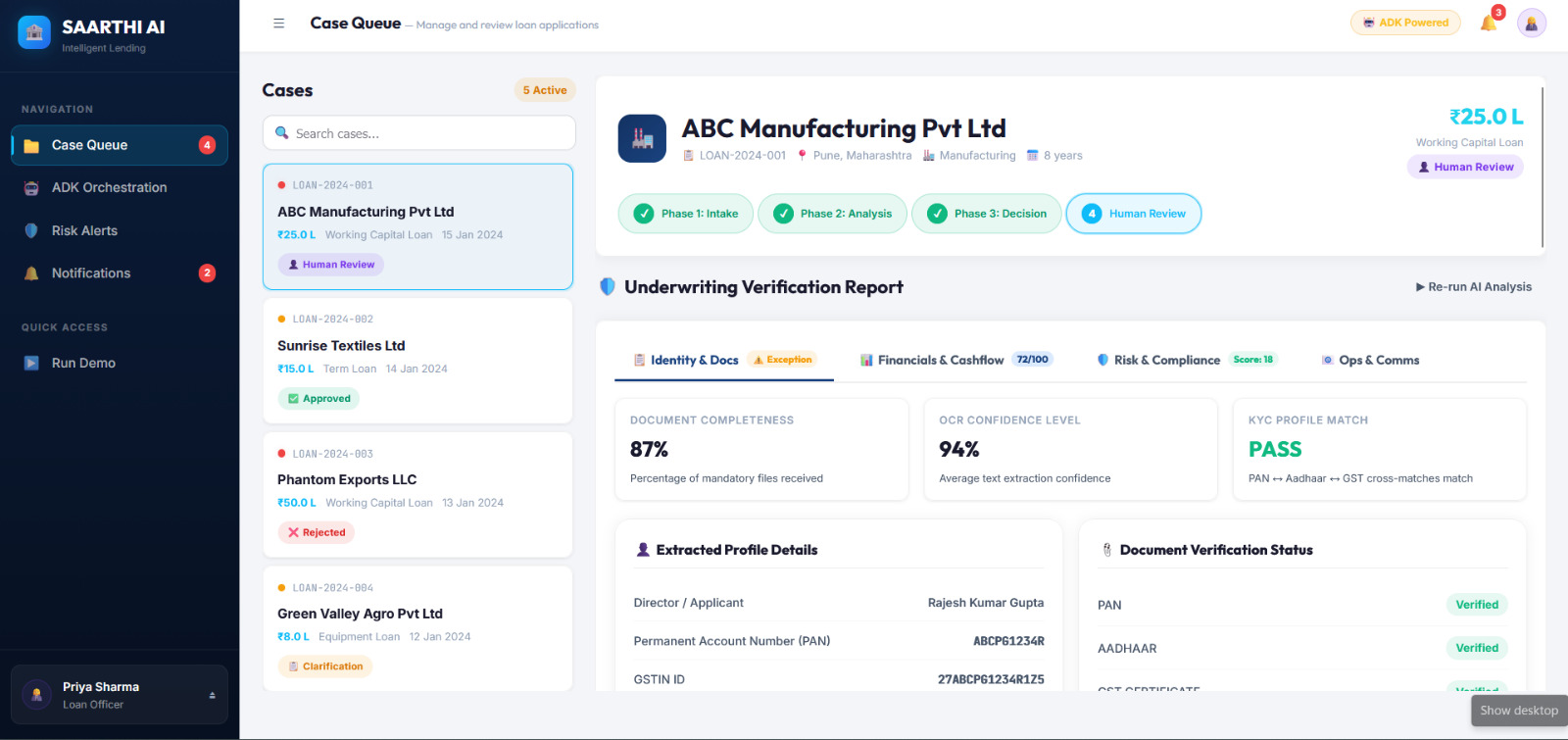
Saarthi AI is built as a multi-agent system where individual specialized agent containers run in parallel to analyze, verify, and score a loan application. The core orchestrator is simulated using the Google Agent Development Kit (ADK) structure, which divides underwriting into three distinct execution phases:
- Intake Phase: Handles document completeness checking and sanitization.
- Analysis Phase: Runs five agents in parallel (Document Intelligence, Financial Analysis, GST Verification, Bank Statement Analysis, and Fraud Detection) to conduct deep inspections.
- Decision & Compliance Phase: Runs sequential agents (Credit Recommendation, AML/KYC Compliance, Communication, and Summarization) to finalize the verdict.
The Mathematics of Credit Risk Underwriting
To render objective credit recommendations, we designed a multi-criteria decision analysis (MCDA) model. The system computes a composite Lending Score \( S_{lending} \) as a weighted sum of individual domain scores:
$$ S_{lending} = \sum_{i=1}^{n} w_i \cdot S_i $$
where the weights are constrained by:
$$ \sum_{i=1}^{n} w_i = 1.0 $$
For instance, in our standard risk model, the weights are distributed as:
- Financial Health (ITR & Balance Sheet) \( S_1 \) with \( w_1 = 0.30 \)
- Banking Reliability (Monthly Inflows & Balances) \( S_2 \) with \( w_2 = 0.25 \)
- GST Compliance (Filing history) \( S_3 \) with \( w_3 = 0.20 \)
- Fraud Inverse Score (100 - Fraud Risk) \( S_4 \) with \( w_4 = 0.15 \)
- Document Completeness \( S_5 \) with \( w_5 = 0.10 \)
Key Underwriting Ratios
The Financial Analyzer Agent calculates the Debt Service Coverage Ratio (\( \text{DSCR} \)) to determine the borrower's capacity to service the debt:
$$ \text{DSCR} = \frac{\text{Net Operating Income} + \text{Depreciation}}{\text{Interest} + \text{Principal Repayment}} $$
A applicant requires \( \text{DSCR} \ge 1.25 \) to qualify for standard pricing. If the conditions are met, the Credit Recommendation Agent calculates the Equated Monthly Installment (\( \text{EMI} \)) using:
$$ \text{EMI} = P \cdot r \cdot \frac{(1+r)^N}{(1+r)^N - 1} $$
where \( P \) is the principal loan amount, \( r \) is the monthly interest rate, and \( N \) is the tenure in months.
Challenges We Faced
1. Concurrency and Race Conditions
Running five LLM-based agent containers in parallel (e.g., GST and Bank Statement extraction) meant coordinating multiple async responses. In early iterations, slower agents delayed the pipeline, or race conditions occurred during the compilation of the central state. We addressed this by implementing a structured state machine in adk-engine.js using Promise synchronization.
2. Cross-Source Revenue Reconciliation
Fraudulent applications often submit doctored bank statements or inflated ITRs. The Fraud Detection Agent must run cross-source revenue reconciliation by checking GST-declared turnover against ITR-reported revenue and actual bank credit inflows. We implemented a variance calculation:
$$ \text{Variance } (V) = \frac{|R_{GST} - R_{ITR}|}{R_{ITR}} \cdot 100\% $$
If the variance \( V \) exceeds a threshold \( \theta = 10\% \), or if the annual credits in the bank statement deviate significantly from the GST filing:
$$ |R_{Bank} - R_{GST}| > 0.15 \cdot R_{GST} $$
the Fraud Detection Agent flags the application with a high-severity warning and automatically routes the application to the Risk Manager instead of permitting auto-approval.
3. Explaining Decisions
Underwriting decisions cannot be a black box; regulators require auditability. We solved this by forcing the final Case Summary Agent to generate natural language explanations mapped directly to the mathematical weights of the Lending Score.
What We Learned
- Agent Specialization Beats Generalism: A single LLM prompt trying to read bank statements, cross-verify GST, and flag fraud results in high failure rates. Splitting these duties among ten highly focused agents significantly increased precision and reduced hallucination rates.
- Human-in-the-Loop is Essential: AI should handle the tedious work (extracting, cross-checking, scoring), but humans must make the final call on edge cases. When \( S_{lending} < 750 \) or the loan amount is greater than ₹5,000,000, the system triggers a
human_reviewstatus. - User Experience Drives Adoption: Underwriters are more likely to trust AI if they can see what each agent is doing. Visualizing the execution logs and status of each agent container dynamically transforms a black box into a collaborative workflow.
Built With
- css3
- font-awesome
- google-fonts
- html5
- javascript
- single-page-application
- vanilla-js

Log in or sign up for Devpost to join the conversation.