-
-

Our Logo
-

Landing Page
-

Utility interface
-

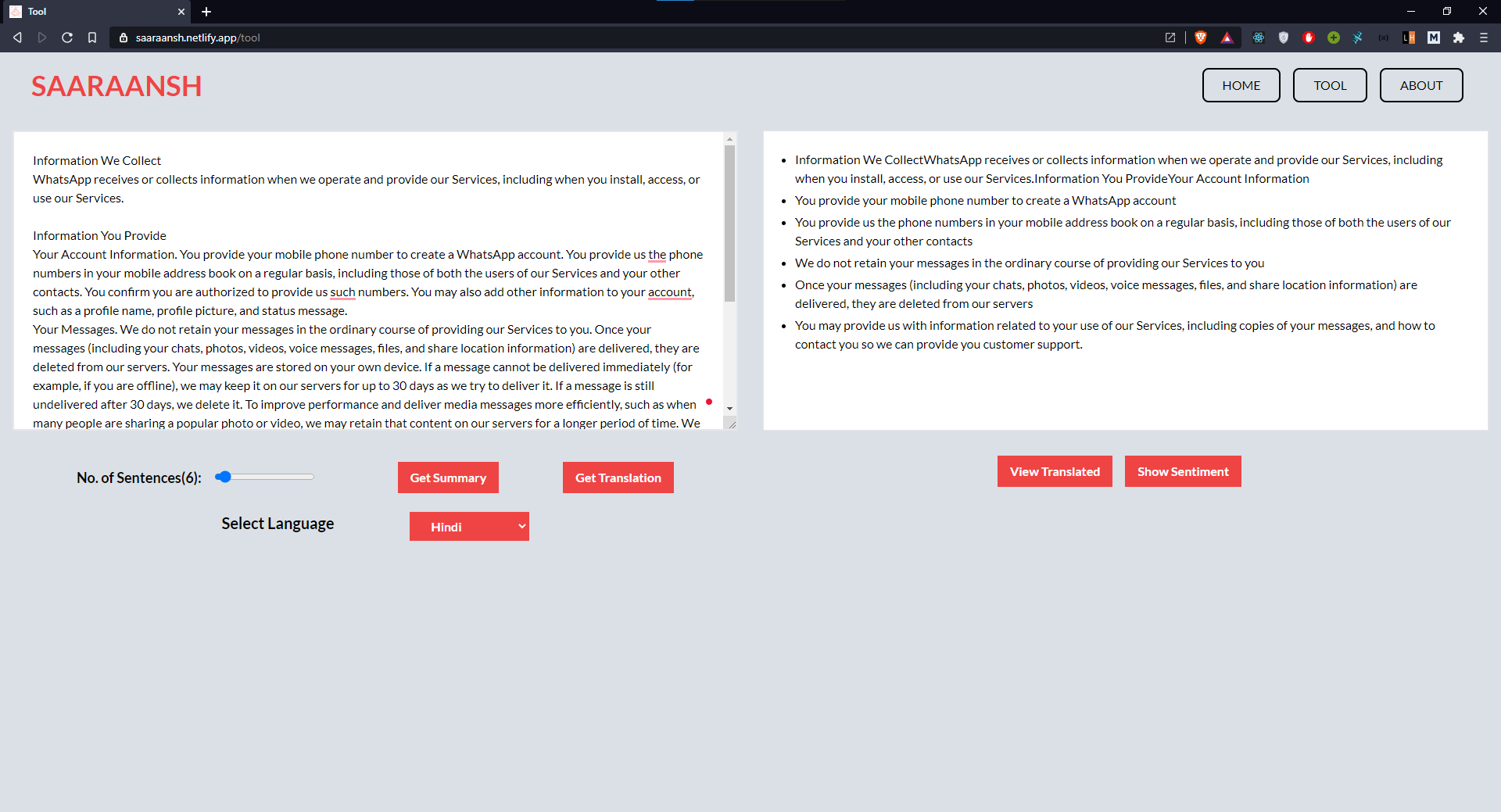
Text Summarization
-

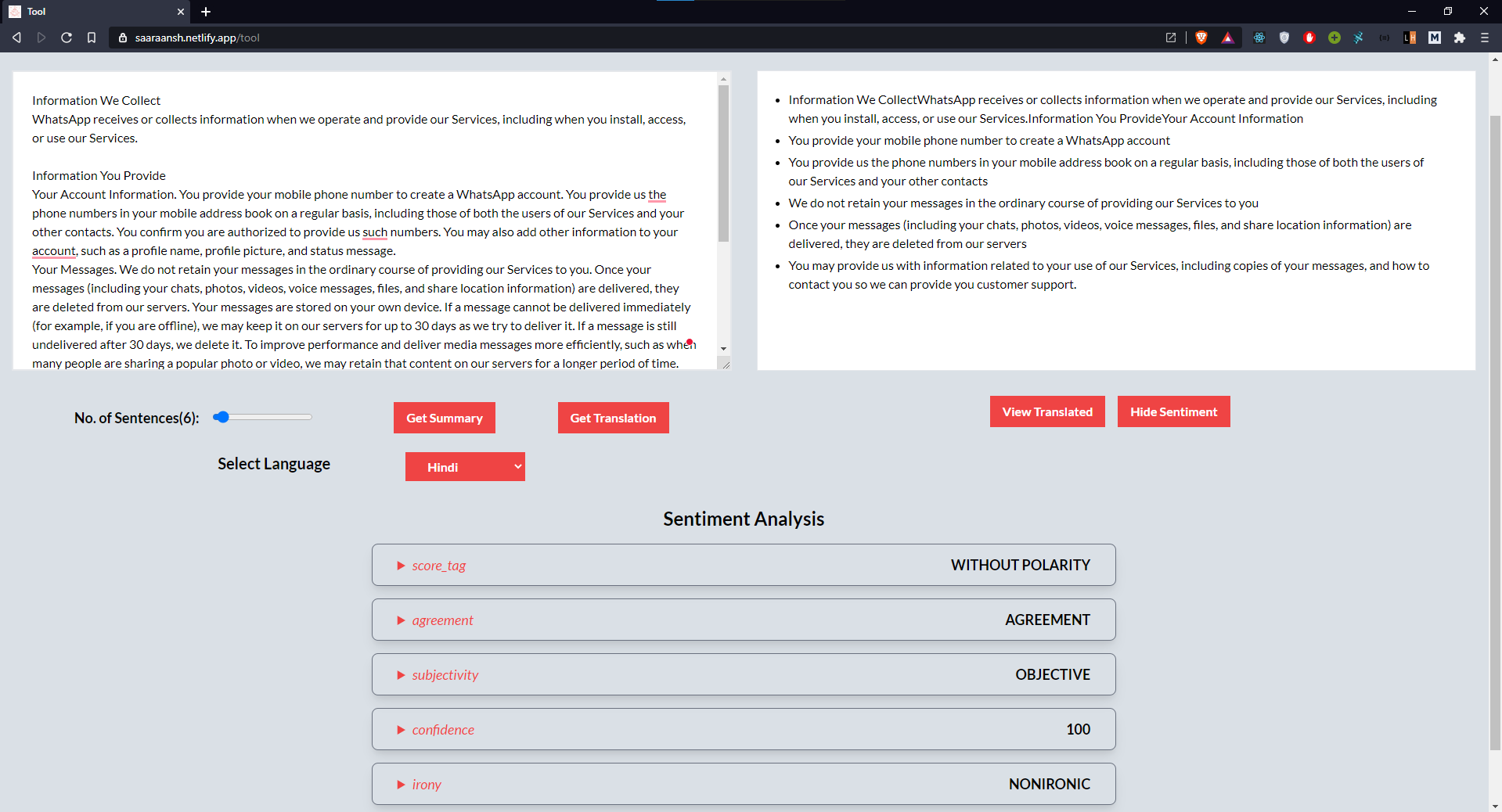
Sentiment Analysis
-

Text Language Translation




Inspiration ✨
Around the world, millions of adults are unable to read or write, and therefore fall prey to the extremely confusing jargon of lengthy legal documents. India has the highest adult illiteracy rate in the world. According to the latest report published by UNESCO, there are 287 million illiterate adults in India—37 percent of the illiterate population in the entire world. Farmers, manual laborers, and the people below the poverty line don't have access to education, therefore do not understand the legal terms and even can't understand the language of the document which are generally in English, and fall trap to financial debts in many cases. Therefore, we present to you Saaransh
What it does 🙌
We built an easy-to-use web app that summarizes the lengthy legal documents into easy-to-understand terms and then converts them to the local language of the individual so that he/she is completely aware of what they are signing for by simpy uploading/taking a picture of the document.
The app works like this: The users can submit the documents they want to understand and the app uses an API to process the document and gives the user back a simplified and summarised document in their regional language.
This supplies the user with a much easier-to-understand document with which they can understand the broader terms of the document and can make a decision whether they should go ahead with the agreements or not.
Features 👇
- Summarise the lengthy and confusing legal documents into concise easy-to-understand bullet points.
- Creating an OCR system to enable users to directly upload images of the document and get the summary.
- Convert the summary to regional Language.
- Create a sentiment analysis of the document to detect any unfair or fraudulent terms.
- Create a mobile-friendly application for the same
How we built it 💡
- The website UI/UX will be designed using Figma and then developed with Next.js, The React Framework, and Tailwind CSS for UI, Tensorflow.js, Python, and GCP API to translate the summary to the regional language.
- We’ll use the open-source framework of Hugging Face to create the document summarizer using Natural Language Processing.
- We used OCR Tesseract.js to implement the text recognition feature.
- We will implement the Web App using cutting-edge web technologies like NextJs as React framework, nextAuth for handling auth, and Tailwind CSS for rapid prototyping.
Novelty 🥇
There is no existing software to create accurate summarization text with translation features. Adapting from the different research papers on legal document summarization, we are adding 2 novel features on translating the summary to regional languages and text to voice conversion for better understanding.
Future Aspects ✔
➡ Improving the NLP Model to create the summary more precisely.
➡ Create a mobile application for the same.
➡ Adding more regional languages and adding text-to-speech for the summarized text.
Help File 💻
- Clone the repository to your local directory
https://github.com/0x-45/saaraanshNode.js required in runtime
npm iStart the live-server
npm run devVoilla the site is up and running on your PC.
Ctrl + C to stop the live-server!!
Tech Stack ⚙
- NEXTjs
- Tailwind CSS
- React-Hook-Forms
- SWR
- Hugging Face
- LibreTranslate API
- OCR Tesseract.js
- Web Browser API
- Google API
- Python
- Tensorflow.js
- Deployed on Vercel
Try it out 👇🏽
- 👤 Github
- 🕸 The Website
The team
Built With
- ai-applied-sentiment-analysis
- language-translation
- libretranslate
- natural-language-processing
- next.js
- ocr
- tensorflow.js
- tesseract

Log in or sign up for Devpost to join the conversation.