-
-

Our Extra Cool Super Amazing Logo
-

Use of DataStax Astra
-

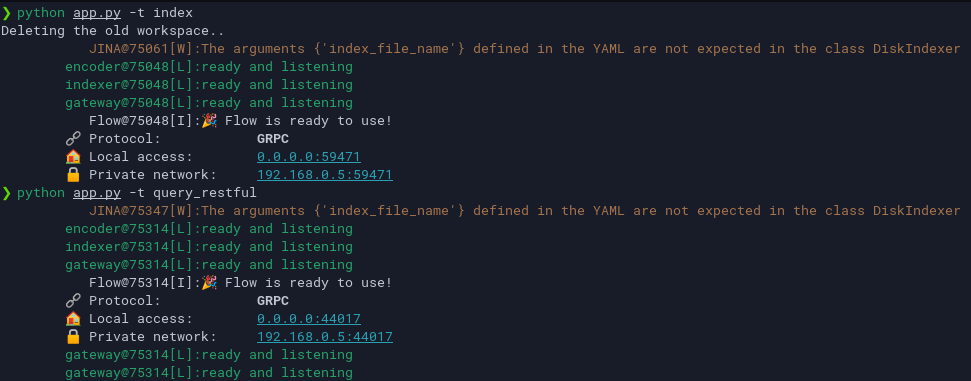
SUAVE CLI
-

Use of Jina
-

Web Application
-

Categories in Web Application
-

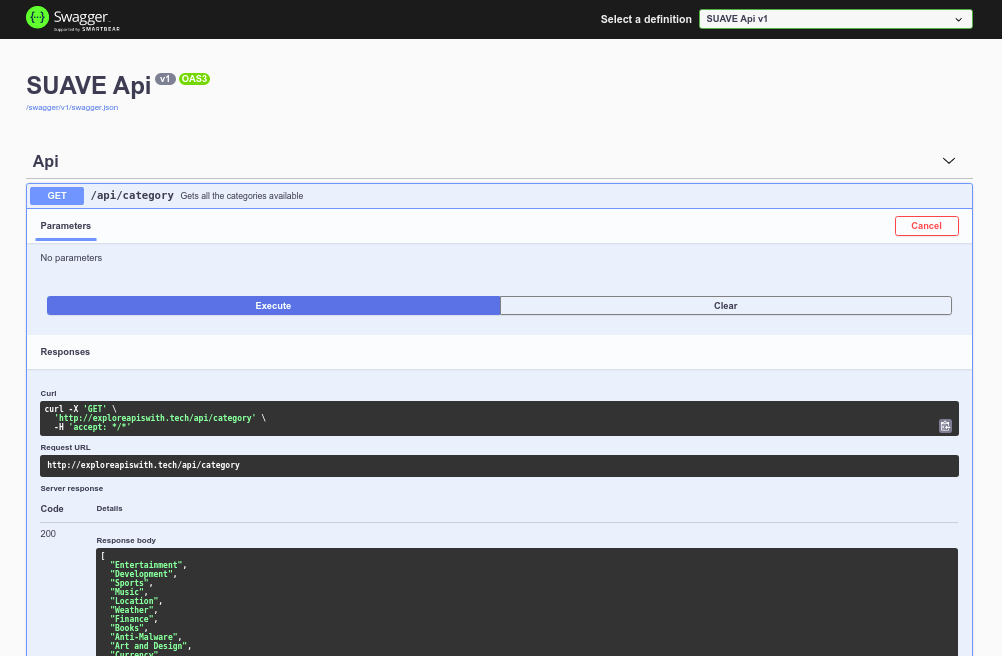
SUAVE API Docs





Inspiration 🅰🅿ℹ🤷♂️
I remember once during a hackathon, I thought that there would probably be an API for some task I wanted to achieve. That API did exist, but traversing through the sea of APIs that was there before me was not that difficult, but rather excruciating.
What made this worse was that because several APIs had paid to be promoted, they rose to the top for my search, even though there were better APIs out there for me.
Even worse (somehow!) was that my teammate had found an API for our purpose already, but because of poor communication and collaboration, and we ended up going down different rabbit holes.
The truth is, each of my teammates has had experiences like this, which we wanted to eliminate.
What it does 🔍🅰🅿ℹ👍🕸🤖
SUAVE, a backronym for Search and Use APIs Very Easily, does exactly what its name says.
It helps developers search and use APIs by using a web app, a Discord bot or a CLI! For the web app, CLI and Discord bot, users can get a list of categories of APIs in our Database, search for APIs in a certain category, and search for APIs by search terms or use cases. Lastly, users can also use the Jina AI-based search exclusive to the CLI interface to search for APIs.
This allows easy search and traversal of APIs, unbiased searches with no promoted APIs, and the Discord bot allows and enables hackathon teammates to collaboratively search on their own Discord server, which solves all our previous API problems!
How we built it 🏗🔧🔨⚙🧰
First, we used DataStax Astra’s Database service to store all of our APIs. It took a little bit of work to get working but we did manage to integrate it. It currently stores over 500 API entries (manually scraped with the aid of a Python script) and their titles, descriptions, links and categories.
Then, we used ASP.NET/C# to build an API for our project. This API had the endpoints for getting a list of categories, getting APIs from a certain category, and searching the database using some keywords. The API would query the database based on all of these factors.
Once we had the APIs, we built a Discord bot around it, a web app using it, and a CLI using it as well. However, we also integrated Jina AI-search functionality to find APIs into the CLI, as well.
Challenges we ran into 🏃♂️🏃♂️🏃♂️🏃♂️
- Building and Deploying an API for the first time
We’ve all used APIs before, but we thought to have numerous ways to access the database for getting the APIs, an API would be easiest. Thus, we decided to make an API for the first time ever and deploy it. We faced several problems while making and deploying it but after hours of debugging, we finally made it work.
- Implementing DataStax Astra’s Database and using CQL
We’d all used SQL to some extent before, but we had to learn an entirely new language for working with DataStax Astra: CQL. CQL was a bit difficult to work with, but we did manage to figure it out. Also, DataStax required an isolated environment for authentication so we had to use a docker container, which we had to host using spare Azure credits. Lastly, the authentication required a zip file, which is quite different from other methods that we've used, which made it much harder to manage secrets and sync them with the team. After all that, it finally worked!
- Implementing AI-Based Search with Jina
Jina was incredibly difficult for us to implement. However, we thought the search functionality would marry perfectly with SUAVE, but only one of us knew any AI to begin with, and we needed to look at a lot of previous implementations by other people, documentation and resources to get it to work. After a lot of trial and error, we finally implemented it, albeit only in the CLI (for now!)
- Getting a big list of APIs
If you search for a list of APIs online, you’ll definitely find some, but most are on GitHub READMEs which make them hard to scrape. Also, these lists often had some information we didn’t need for our project. Thus, we had to scrape these lists with a Python script to convert a text file to JSON. However, the descriptions in the list I was using weren’t clearly marked which meant that we had to manually mark the descriptions so the Python script would understand. This was extremely time-consuming, but 533 APIs is awesome for just a few hours!
- Caching
To stop our server from being overloaded and our Azure credits from being drained, we decided to implement caching on the API. While all of us knew what caching was, we still had to learn how to implement it in an API. After a few errors and some debugging sessions, we finally achieved what we wanted.
Accomplishments that we're proud of and what we learned 🏆🏅🧠
- Overcoming our challenges
Our project was a perfect example of Murphy’s Law, and everything that could go wrong did go wrong. Luckily, thanks to a team with all super duper cool people, we managed to overcome every challenge that was foolish enough to face us.
- SO MANY APIs (for 6 hours)!
Our API list is 533 entries, which is amazing for a 48 hour hackathon! It did also lead to some funny moments including an incredibly enormous 89KB JSON. 89 KILOBYTES!
- Learning EVERYTHING
From CQL to building and deploying APIs to working with DataStax Astra to working with Jina to caching, We’re immensely proud of how much we’ve learnt this weekend, which we are definitely going to use for future hacks!
What's next for S.U.A.V.E.
We’d love to add way more APIs in the future and having a proper database of thousands of APIs to give our consumers the best experience! Also, we would like to make more frontends/clients for the API to enable developers to search and use APIs anywhere they are.











Log in or sign up for Devpost to join the conversation.