-
-
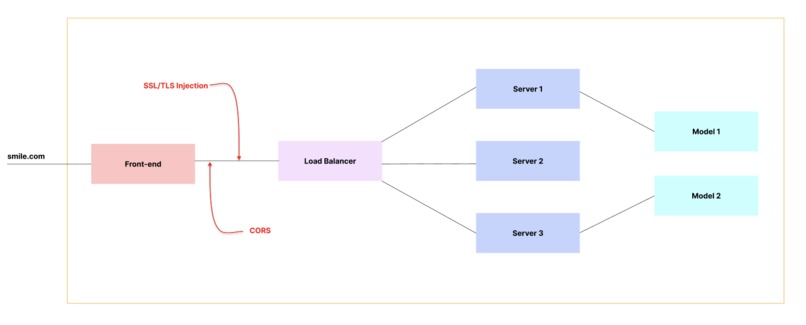
System Design (for the funsies)
Inspiration
Sometimes you're worn down from doing an assignment or reading a bad news, you tend to forget that life is full of happiness, and all you need is a little boost to keep going. That's exactly what Social Mood Intelligence and Life Saver Extension (S.M.I.L.E) is for. It's a chrome extension/website that detects when you are sad.
What it does
The chrome extension uses AI to detect the users' face and their emotions. It securely and constantly stream of video input from the users' cameras through the HTTPS protocol and WebRTC.
How we built it
To secure the communication with the back-end, we created a reverse proxy to load balance multiple concurrent request to three different servers in the backend (written in Go). From which, the video can be relayed to our machine learning model in Python to make predictions. Furthermore, we used docker compose to host a "hidden" network of backend, to expose only the necessary ports of the server for communication with the front end. And, we also added the TLS certificates to enable the https protocol.
In order to identify facial expressions of the user, we trained a Convolutional Neural Network using tensorflow in order to classify the subject's expressions into one of 7 universally-identified emotions: anger, disgust, fear, happy, neutral, sad, surprise. If the percent likelihood of sadness exceeds a certain threshold, then we can be reasonably confident that the subject is sad.
Since our emotion detection model works with still images, we needed a way to apply our emotion detection model to each frame of our video stream. In order to accomplish this, we used opencv to process the video stream and WebRTC to stream data from our frontend to our backend.
Challenges we ran into
Enabling for https for local development proved great difficulties. We had to search across the internet, before coming across mkcert package and the concepts of trust stores on local machine. Even then, making sure that they arrive at the appropriate place in the docker image was quite difficult.
Using WebRTC to connect the front-end to the proxy then to the backend before arriving at python model was quite difficult. We didn't manage to get it working but, it was a cool concept to know and learn about.
In order to train the model, we used the FER-2013 dataset (Kaggle). WE struggled for a long time with the architecture of the model, as we was having difficulty reaching testing accuracy over 60%. We tried to extend popular deep learning models such as ResNet50 and MobileNet using transference training, but we got even worse results, likely because we had no idea what we was doing. Eventually, by looking through the leaderboards for models based on facial recognition datasets, we was able to find a model that we could replicate.
Because we were using Python for video processing, we used the aiortc library to be able to establish a WebRTC connection to the Go backend. The biggest challenge we faced was deciphering how to actually use the libraries, as we had to essentially copy the provided examples and expand our brains enough to understand how to use it for our purposes.
Accomplishments that we're proud of
Very, very proud to be able to enable the https for local development. Also, being able to bring 3 different servers up with an additional proxy with only a single docker command is very satisfying. Learning how to network within docker (especially how it masked localhost) is also very worthwhile.
This was our first time training our own convolutional neural network, and we are very proud of how we were able to achieve testing accuracy of over 65% - still not perfect, but good enough for our use. In addition, we are very proud that we were able to get the majority of the core functionality working - it used a lot of technologies that were new to us, like computer vision and the aforementioned facial emotion recognition using neural networks.
What we learned
We learned how to route to different alias hostnames within docker network. Additionally, TLS and https protocol for local development (and the concepts in general) were challenging, but they provided a deeper understanding about the underlying work of networking. And, Docker is my new favorite development tool!!!!
We also learned a lot about neural networks and machine vision. While we could have used managed cloud solutions to perform the recognition for us or used a library/pretrained model, we wanted to get the hands-on experience of doing the whole process, and in the end we were able to achieve a respectable result.
What's next for S.M.I.L.E
Definitely the WebRTC connection. Learning how to stream realtime data to the backend will undoubtedly be fun and worthwhile.
While our model's accuracy of 65% is fairly good for our needs, there is still a lot of room to improve. One of the things we noticed is that most of the highest-performing models all used pytorch. Because we started out learning and using tensorflow, we weren't confident in switching over. If we want to leverage the best-performing models without having to read the papers to replicate them, we will likely need to switch over to pytorch.
The FER-2013 dataset also appears to be a somewhat limiting factor, as the sample size is fairly small - there are only ~30,000 images total, with the smallest category, disgust, having only about 600 images. If we are able to find more datasets with larger sample sizes, we will likely be able to train our model to be much more accurate.

Log in or sign up for Devpost to join the conversation.