Abstract: The S.H.I.E.L.D: A Multi-Phase Design Benchmark for Society-Centered AI
Safe Healthcare Intelligent Evaluation & Lifecycle Design
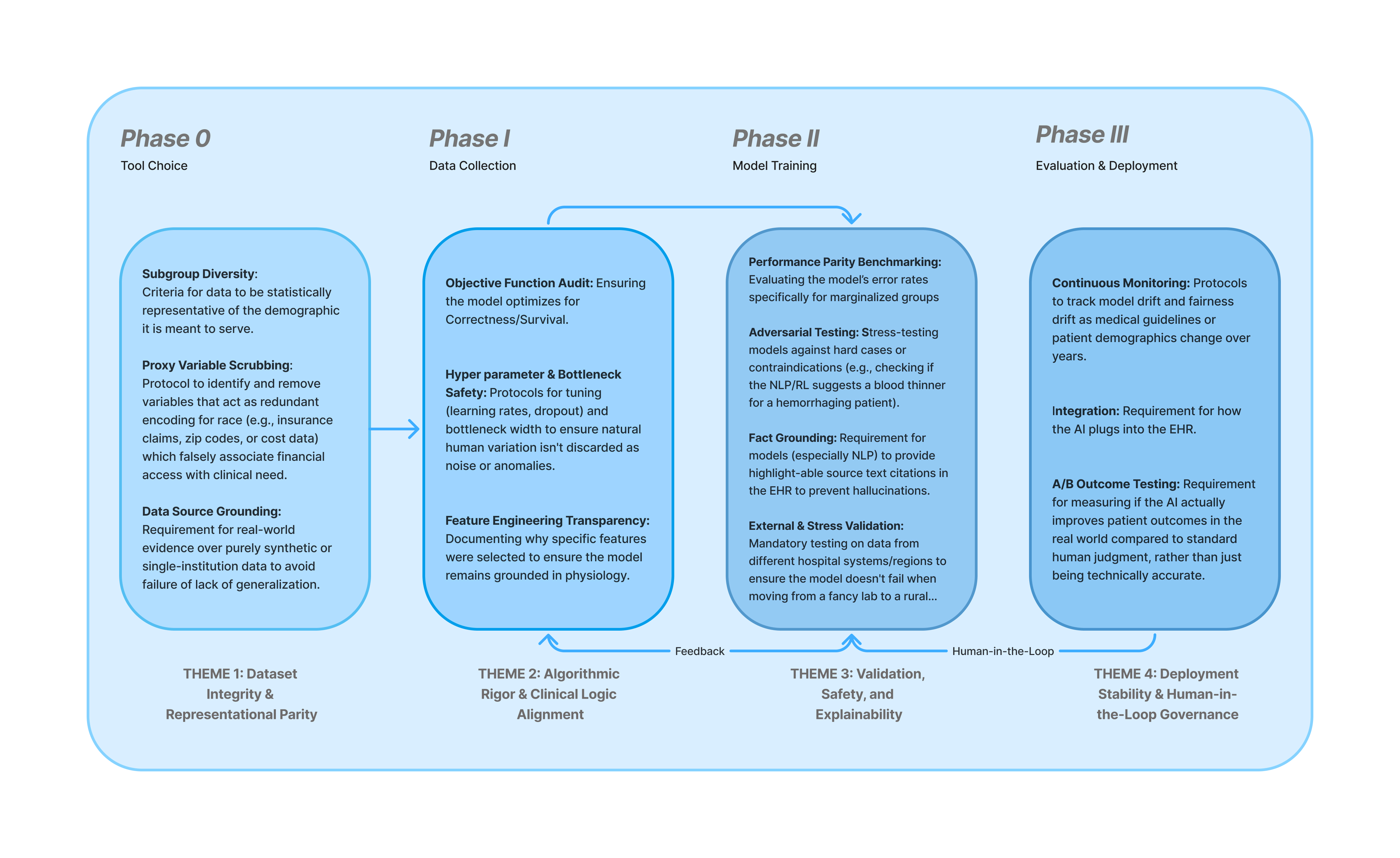
Current AI deployment often lacks the rigor applied to consumer goods, creating "black box" systems with unknown "ingredients" and toxic biases. Engineers lack a standardized risk map across the design cycle; when systems fail, they cannot pinpoint which stage-specific decisions caused the collapse. The S.H.I.E.L.D. framework solves this by providing a granular, milestone-based benchmark. While applicable to any high-stakes domain, we demonstrate its utility through Healthcare as the ultimate stress test for algorithmic safety, transforming fairness from an afterthought into a deliverable by design.
Societal Values & Impact: S.H.I.E.L.D. prioritizes equity and clinical safety. By auditing for negative legacy bias, it ensures AI systems do not perpetuate historical systemic inequalities, particularly where misaligned proxies lead to disparate treatment outcomes.
AI Systems & Use Cases: S.H.I.E.L.D. is tailored for Supervised (predictive diagnostics), Unsupervised (pattern discovery), and Reinforcement Learning (dynamic treatment optimization) models, making it universally applicable to high-stakes AI.
Evaluation Methodology & Metrics: S.H.I.E.L.D. structures evaluation into four phases: Tool Selection (matches AI learning modes to clinical use cases), Data Collection (diversity scores and label integrity audits), Model Training (shortcut detection via heatmaps ensuring causal feature learning), and Evaluation & Deployment (stratified auditing for calibration parity and external dataset stress tests).
Accountability & Public Trust: S.H.I.E.L.D. increases transparency by grounding models in clinical facts and requiring mandatory six-month audits to detect fairness drift, ensuring equitable care across patient demographics and fostering clinician and public trust.
Built With
- figma
- python

Log in or sign up for Devpost to join the conversation.