-
Homepage
Inspiration
Public speaking is one of the most universally feared skills - yet one of the most valuable. Most people never get honest feedback on how they actually sound. We've all sat through presentations littered with "um", "uh", "like, basically, you know", and most speakers have no idea they're doing it.
So we wanted to build a mirror. Not a coach that tells you what to say, but a tool that lets you hear yourself the way your audience does and then immediately hear what you could sound like with those rough edges removed.
So the big question that sparked Alto is this: "what if you could hear your own pitch, in your own voice, already polished?"
## What it does
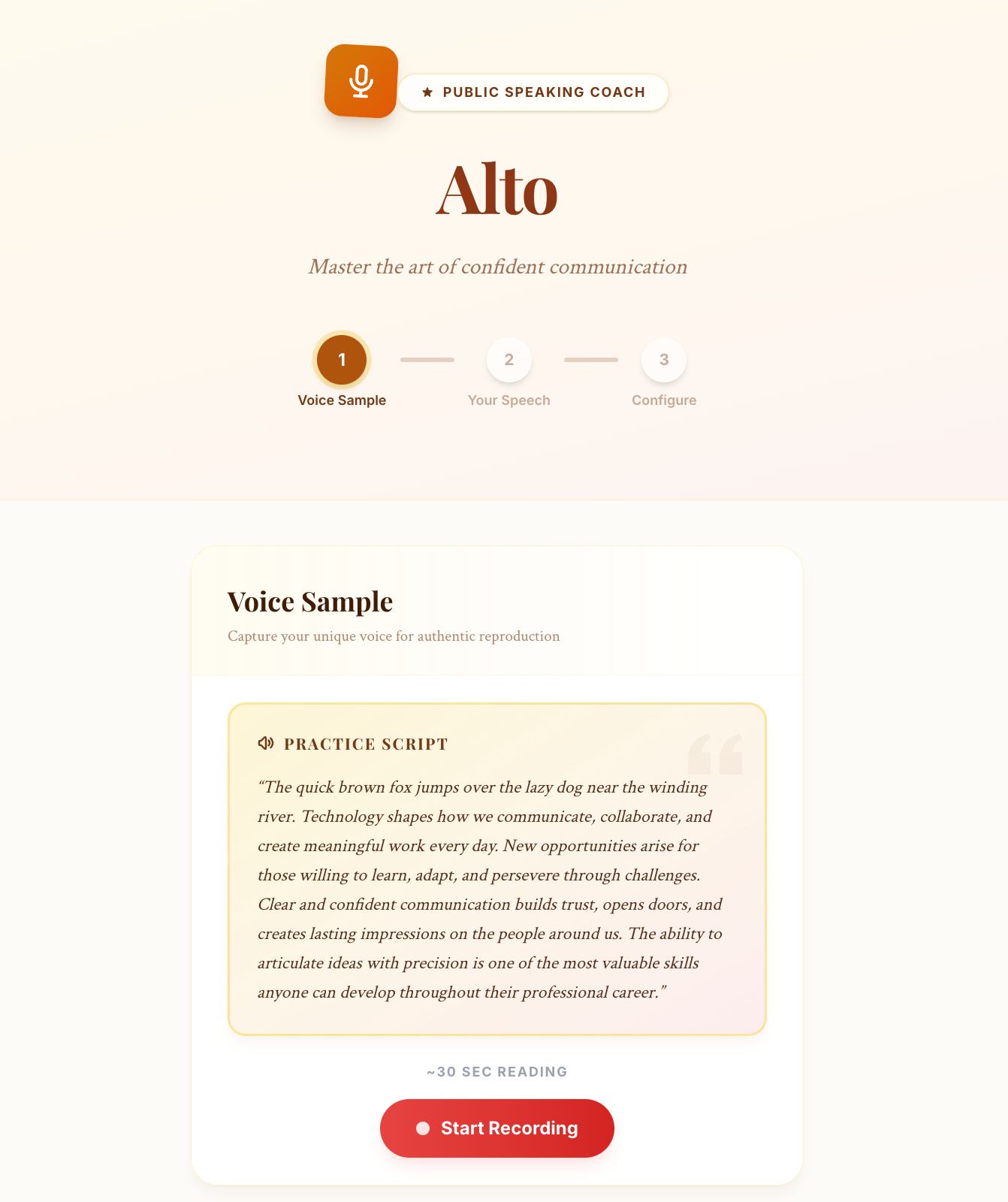
Alto is a real-time AI speech coach. You record a short voice sample and your speech, and Alto:
- Clones your voice using ElevenLabs Instant Voice Cloning
- Transcribes your speech via ElevenLabs Scribe (speech-to-text)
- Removes filler words such as "um, uh, like, you know, sort of, basically, literally" and cleans up phrasing using GPT-4o
- Plays it back in your own voice at a slightly measured pace, so the delivery sounds calm and confident
- Shows you the difference, with the original transcript with fillers highlighted in red alongside the cleaned version
- Reports key metrics: fillers removed, original WPM, words saved, and filler rate as a percentage of total words
You can edit the cleaned transcript inline and regenerate the audio instantly. Cloned voices are saved locally so you can reuse them across sessions and preview each one before selecting.
How we built it
Frontend: Next.js 16 (App Router), Tailwind CSS, deployed on Vercel. State is managed with a module-level store rather than a global library, which lets blob URLs survive client-side navigation without dying on page unload.
Backend: FastAPI (Python), running on a local server. Three core endpoints:
| Endpoint | Role |
|----------|------|
| POST /clone | Uploads audio to ElevenLabs, returns voice_id |
| POST /analyze | STT → GPT-4o clean → TTS pipeline |
| POST /tts | Regenerates audio from edited transcript |
AI pipeline: Raw Audio -> (ElevenLabs Scribe) > Raw Transcript -> (GPT-4o) > Cleaned Transcript -> (ElevenLabs TTS) > Cloned Audio
TTS speed is calculated dynamically to preserve the speaker's original WPM, then biased 20% slower for natural spacing.
Filler detection uses precompiled word-boundary regex patterns, sorted longest-first so multi-word fillers like "you know" match before their component words.
## Challenges we ran into
Blob URLs don't survive page navigation:
The original recording needs to play on the results page, but URL.createObjectURL() produces a URL that's garbage-collected when the page unloads. session
Storage can't hold binary data: We solved this with a module-level in-memory store that persists across Next.js client-side route changes.
WPM calculation breaks on redo:
When a user redoes an analysis with the same recording, the speech duration wasn't being restored, so original_wpm came back as 0. Fixed by persisting speech_duration alongside the result and rehydrating it on mount.
ElevenLabs API key scoping:
The voice cloning endpoint requires a specific create_instant_voice_clone permission that isn't enabled by default on all key tiers. This burned time during local testing.
Speed feels wrong at the wrong value: Finding a TTS speed that sounds confidently measured rather than robotic and slow took several iterations. Too fast and it sounds rushed; too slow and it sounds synthetic. We landed on a dynamic calculation biased to 0.65-0.78× depending on the speaker's natural pace.
## Accomplishments that we're proud of
End-to-end voice cloning in a single session. Alto can go from raw recording to polished playback in your own voice in under 30 seconds
Persistent voice library: saved voices with inline renaming and live preview so you're never guessing which clone to use
Dynamic speed matching: the cleaned audio doesn't just sound cleaner, it sounds like you speaking at a natural, confident pace
## What we learned
ElevenLabs' Scribe model is remarkably accurate even on casual, filler-heavy speech - it handles overlapping words and mid-sentence corrections gracefully! We also learnt that GPT-4o is aggressive about cleaning when prompted directly; the real work is in the system prompt tuning to preserve meaning while removing noise. Also, as this is the first hackathon for a lot of our members, we learnt that for a hackathon, a module-level singleton store beats any state management library when all you need is "survive a page change".
## What's next for Alto Real-time filler detection: we want to reach a point where Alto can do live audio analysis while you speak, with a subtle visual cue each time a filler word is detected
As this is a self-improvement tool, we want to add progress tracking over time: a personal dashboard showing filler rate, WPM, and confidence trends across sessions

Log in or sign up for Devpost to join the conversation.