Inspiration
Private credit markets have grown rapidly, but their risk infrastructure hasn’t kept pace. Most credit monitoring systems are still reactive they flag borrowers after clear deterioration or missed payments, when intervention options are already limited. This creates a structural inefficiency: credit teams spend time reviewing stable borrowers while truly risky exposures surface too late. The inspiration behind RWA — EWS Private Credit v2.1 was to invert this paradigm. Instead of waiting for defaults or late-stage distress signals, the goal was to detect weak signals early subtle shifts in payment consistency, increasing volatility in payment ratios, or rising sensitivity to macroeconomic factors like SOFR. Another key motivator was the fragmentation of data and tools in private credit. Analysts often rely on spreadsheets, static dashboards, and manual reviews. There was a clear opportunity to unify: Time-series behavioral analysis Cross-sectional anomaly detection Supervised risk prediction into a single, production-grade pipeline. Ultimately, the project was inspired by a simple but powerful question: “What if credit risk could be monitored like a real-time system, rather than a periodic report?”
What it does
RWA- EWS Private Credit v2.1 is an AI-driven early warning system that identifies borrowers at risk of default before traditional signals emerge. At a high level, it performs three core functions:
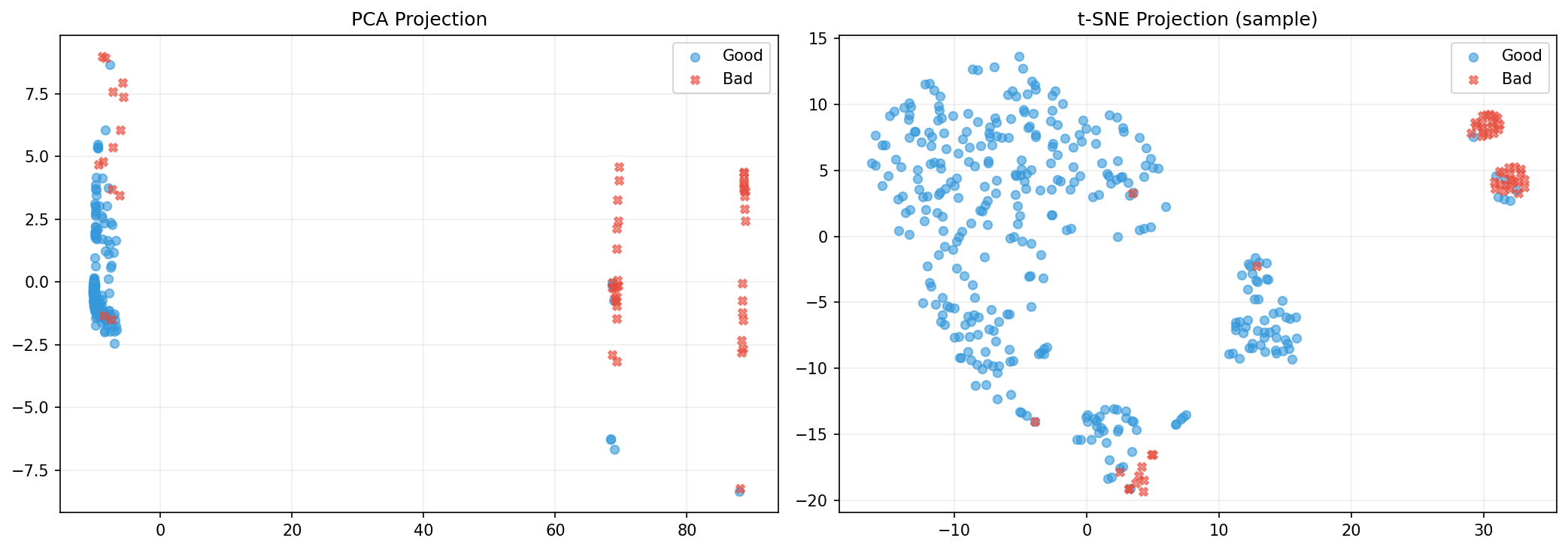
Detects anomalous borrower behavior Using Isolation Forest, the system identifies borrowers whose financial patterns deviate from the norm capturing structural irregularities that may indicate hidden stress.
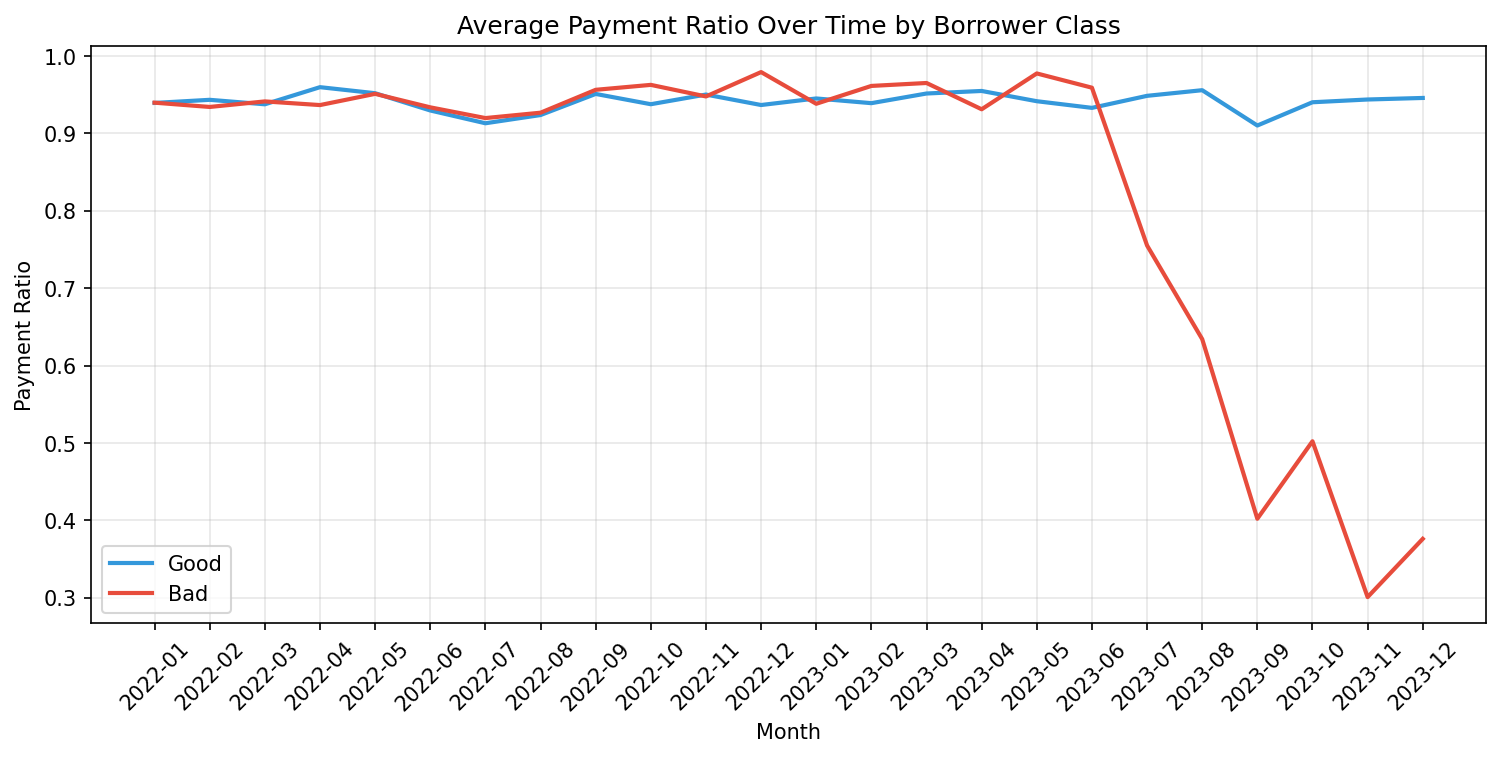
Learns temporal deterioration patterns A LSTM Autoencoder models sequences of borrower behavior (e.g., payment ratios over time). It flags borrowers whose recent trajectories diverge from learned “healthy” patterns, capturing gradual degradation that static models miss.
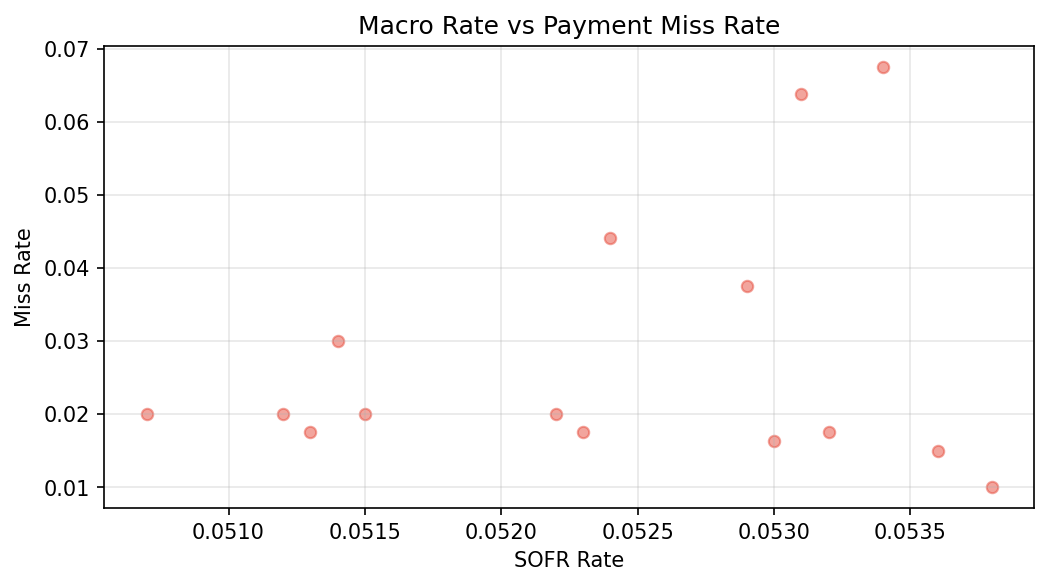
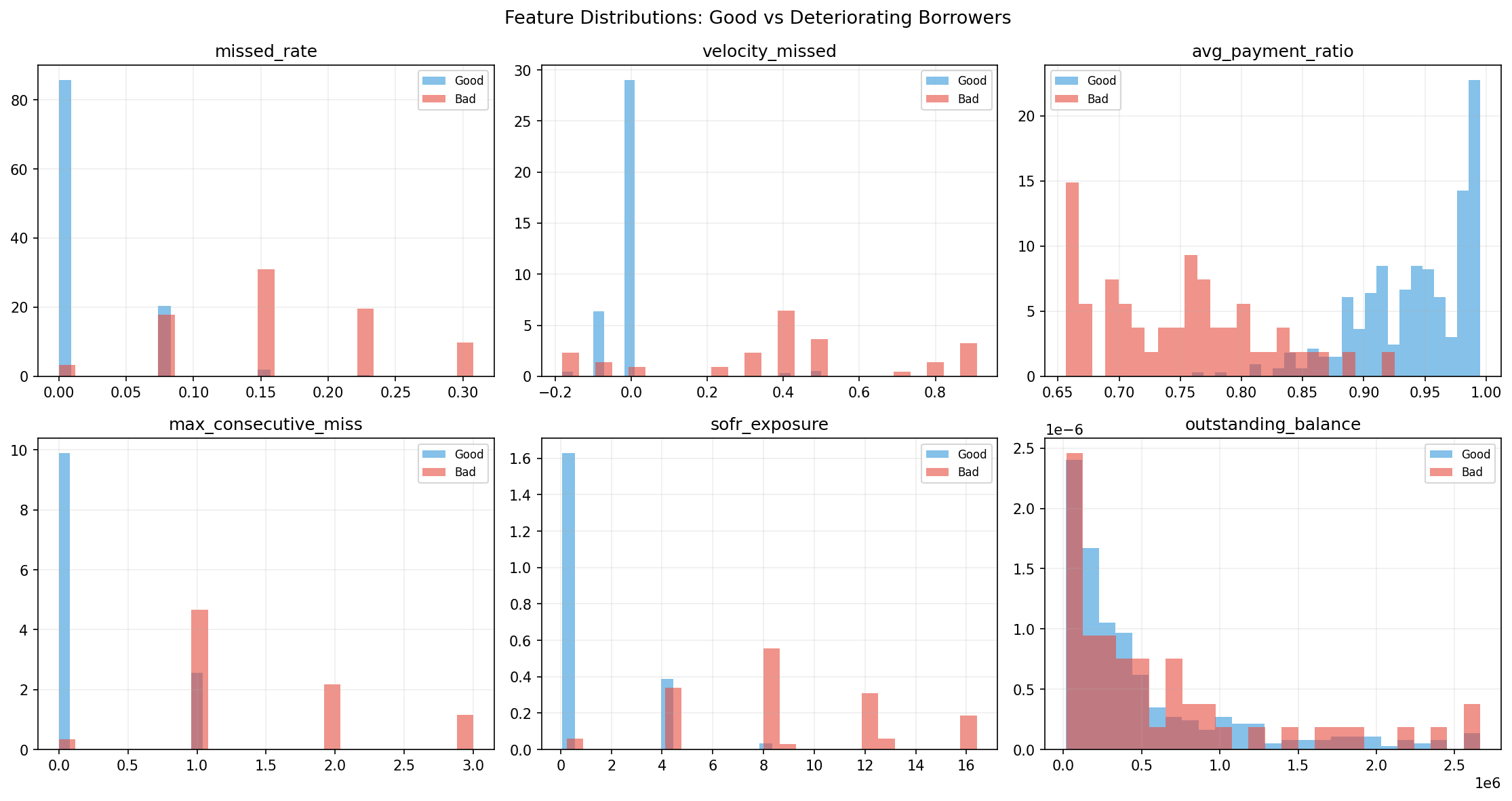
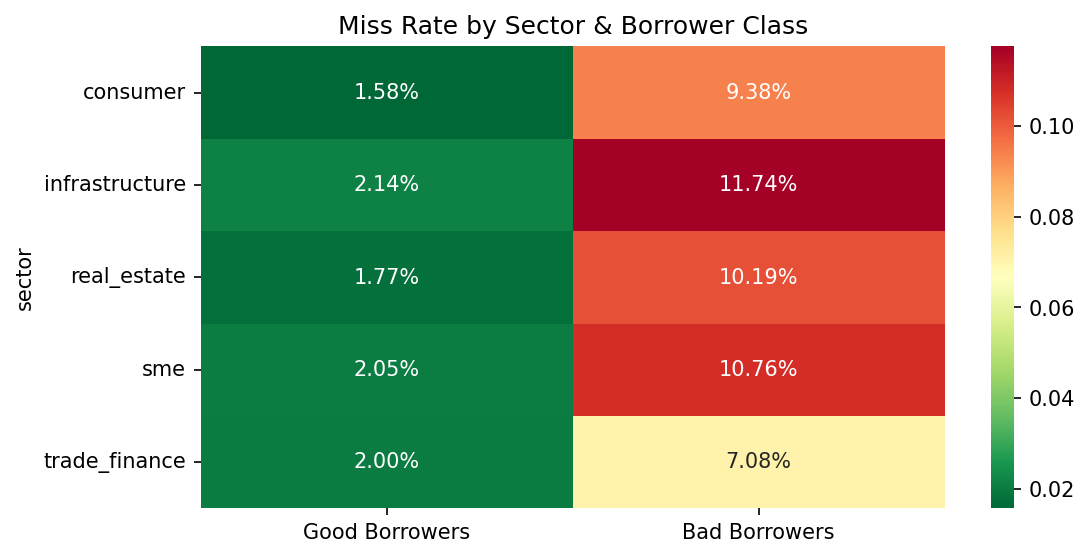
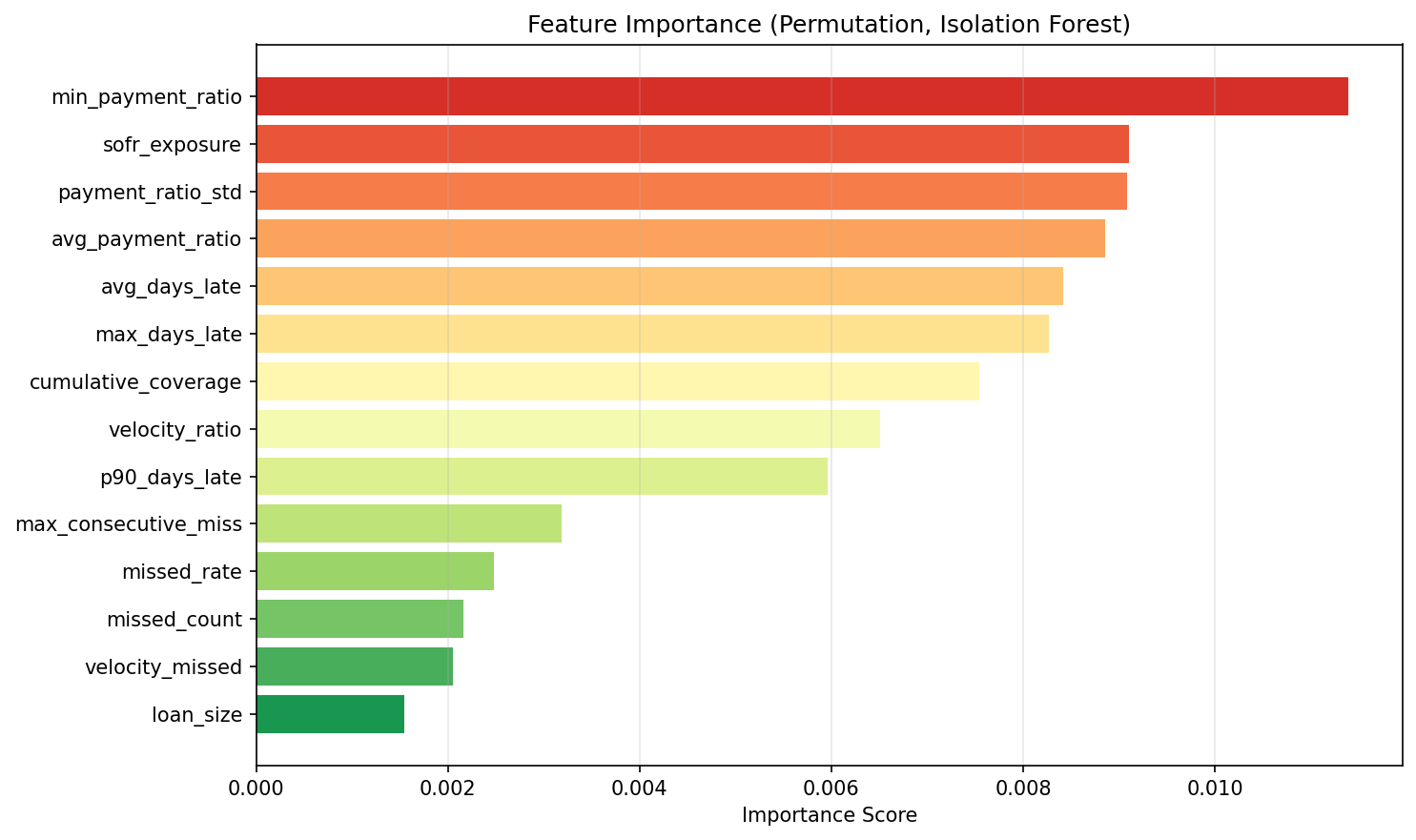
Predicts default probability A stacked ensemble (Random Forest, XGBoost, LightGBM) produces a robust probability-of-default score using engineered features such as: Missed and partial payment rates Days late and consecutive missed payments Payment ratio statistics (mean, variance, minimum) SOFR exposure and macro stress indicators Balance and leverage dynamics
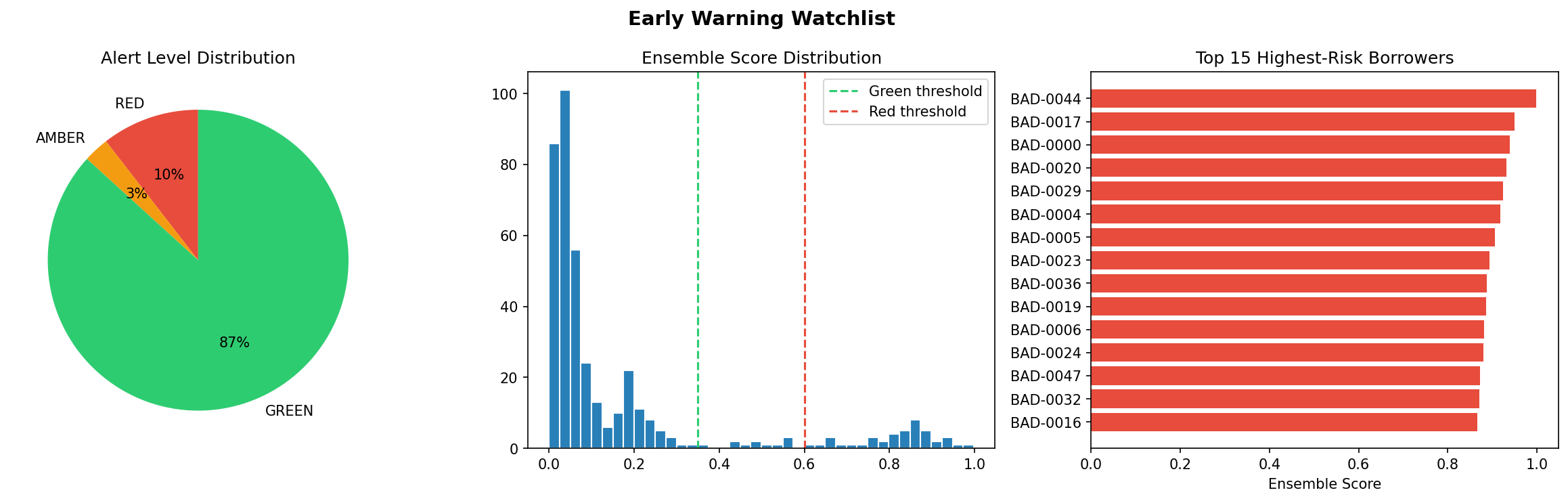
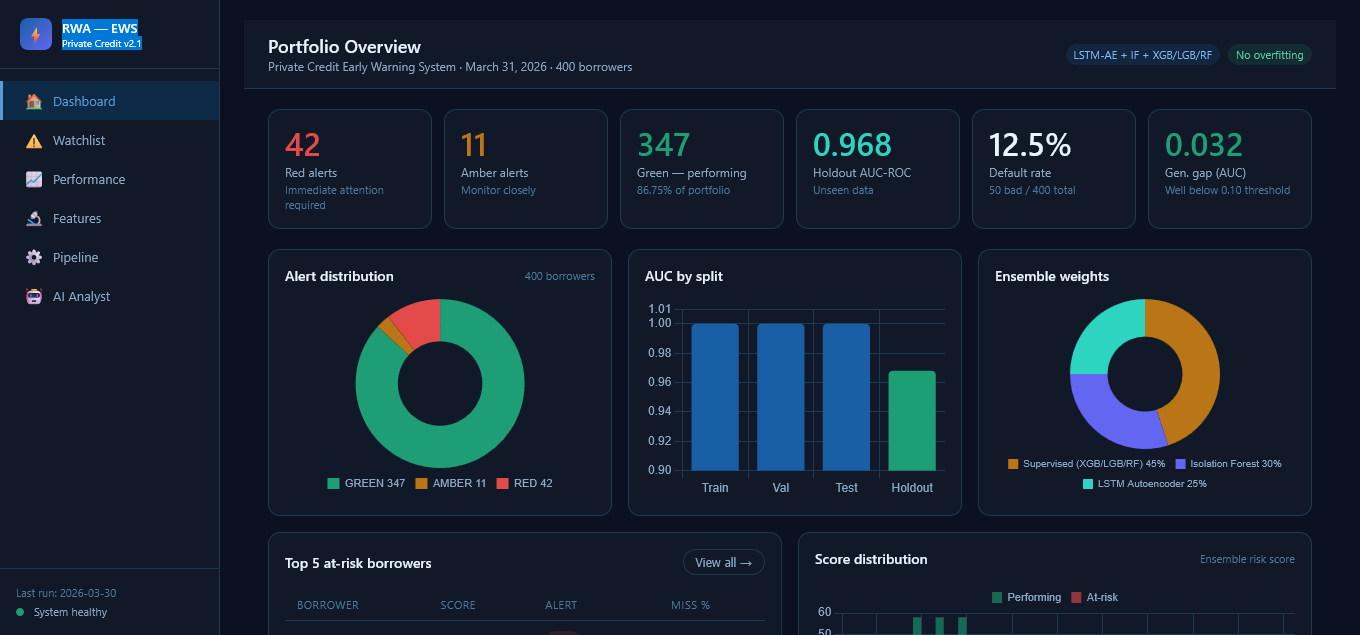
Output Layer The system translates model outputs into actionable intelligence: A ranked watchlist of borrowers Risk categorization: GREEN (stable), AMBER (watch), RED (high risk) Feature-driven explanations (via importance metrics / SHAP) AI-powered query interface for natural language exploration This bridges the gap between model output and decision-making, which is often where ML systems fail in practice.
How we built it
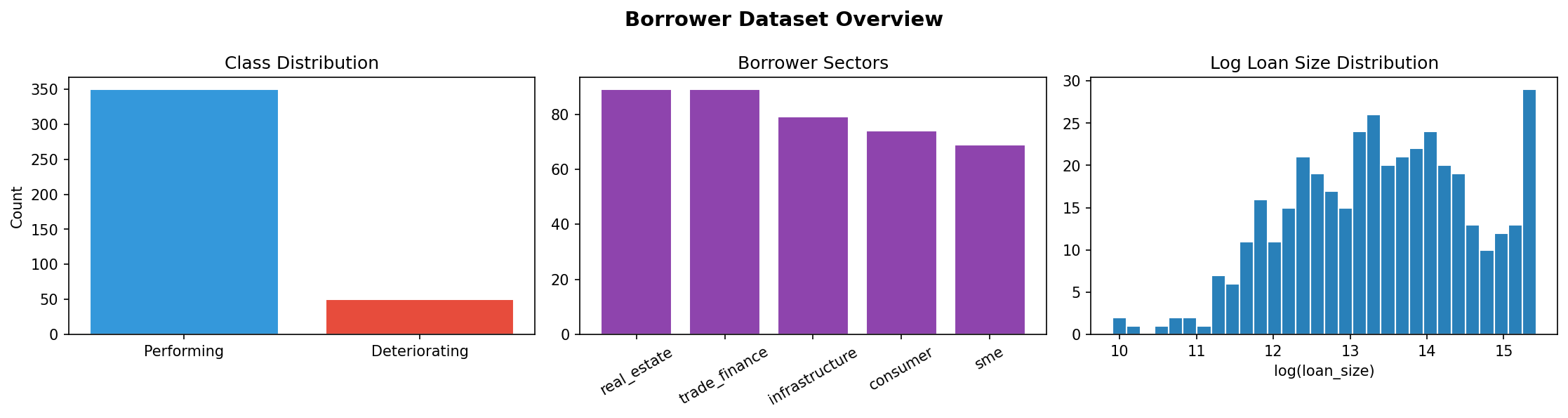
The system was engineered as a modular, end-to-end pipeline, emphasizing robustness, reproducibility, and real-world usability. Data Layer We integrated multiple open financial datasets: Macroeconomic indicators (e.g., SOFR, FRED data) Lending datasets (e.g., LendingClub-style borrower data) Payment behavior proxies (BIS statistics) To address real-world data fragility, we implemented: Automated ingestion scripts Fallback synthetic data generation, ensuring pipeline continuity even when external sources fail
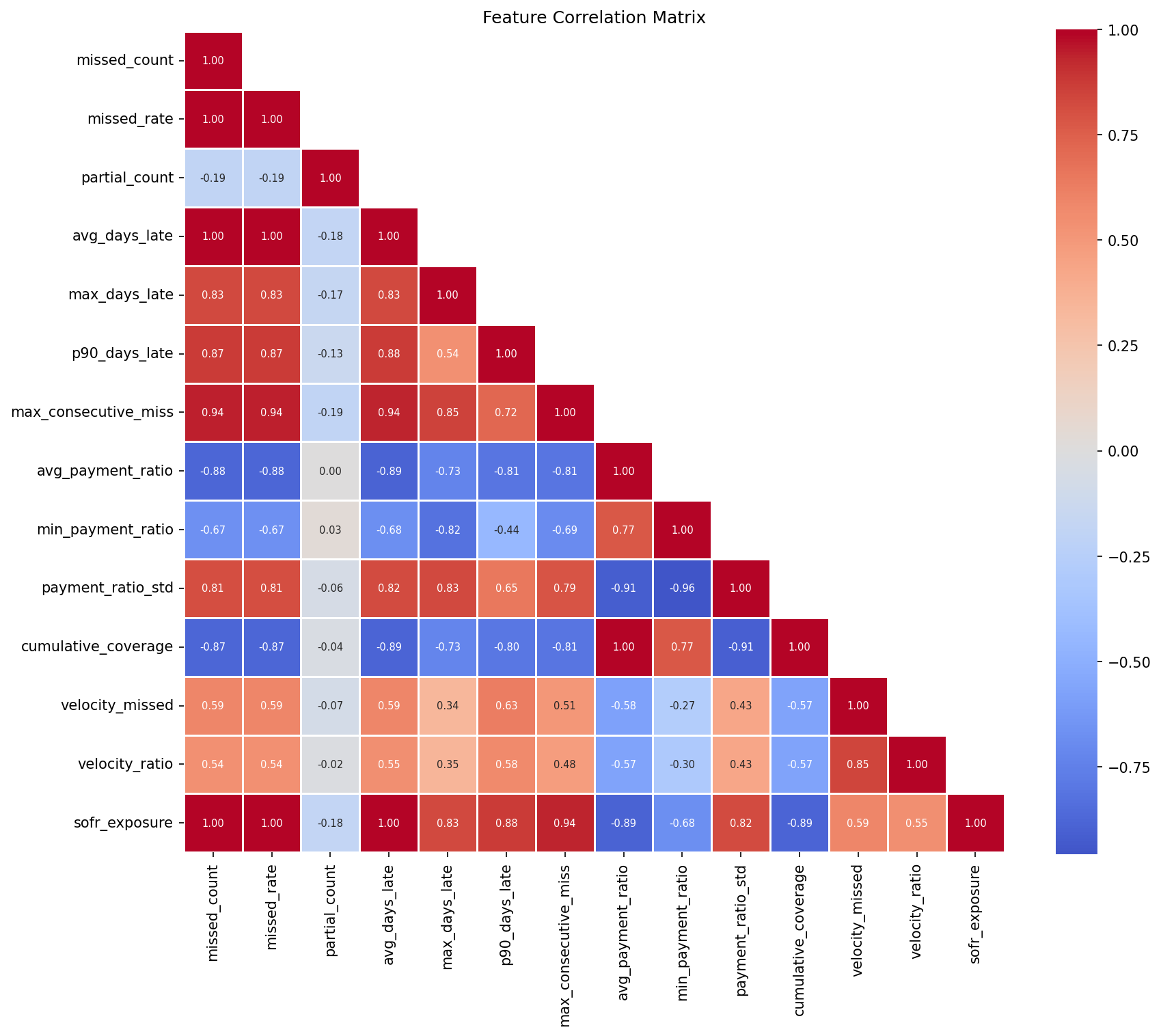
Feature Engineering We designed features specifically aligned with credit risk intuition: Behavioral: missed rate, partial payments, consecutive misses Temporal: rolling averages, volatility metrics, trend features Financial: outstanding balance, leverage ratio Macro-linked: SOFR exposure, macro stress rate Additionally, we constructed sequence windows (length = 12) for temporal modeling.
Modeling Architecture A three-layer hybrid system was used:
- Isolation Forest → unsupervised anomaly scoring
- LSTM Autoencoder → reconstruction error for sequence anomalies
- Supervised Ensemble → calibrated probability of default These outputs are combined into a final ensemble risk score, improving robustness across different failure modes.
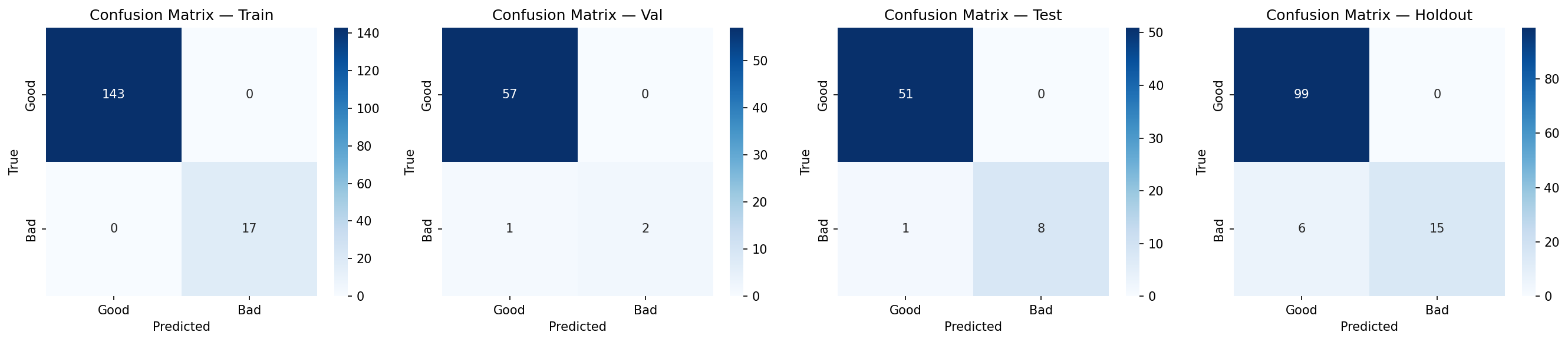
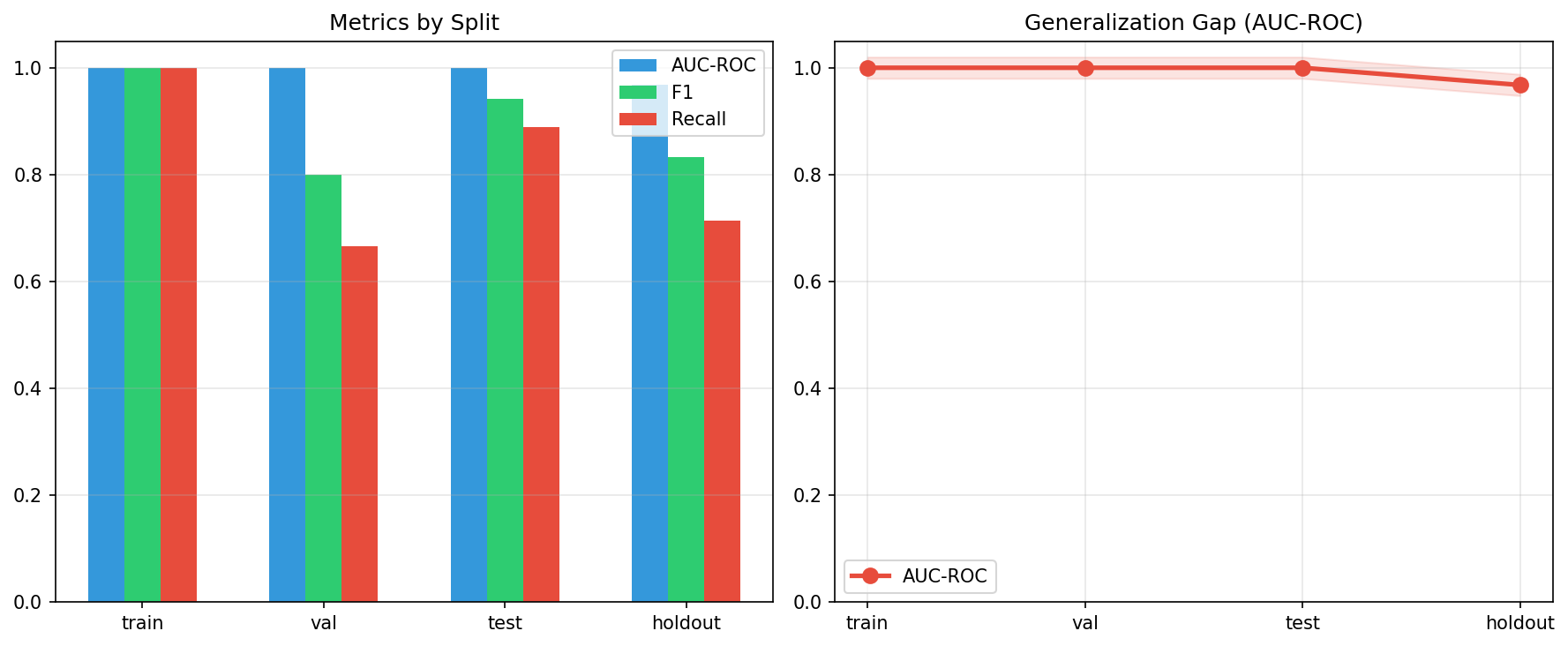
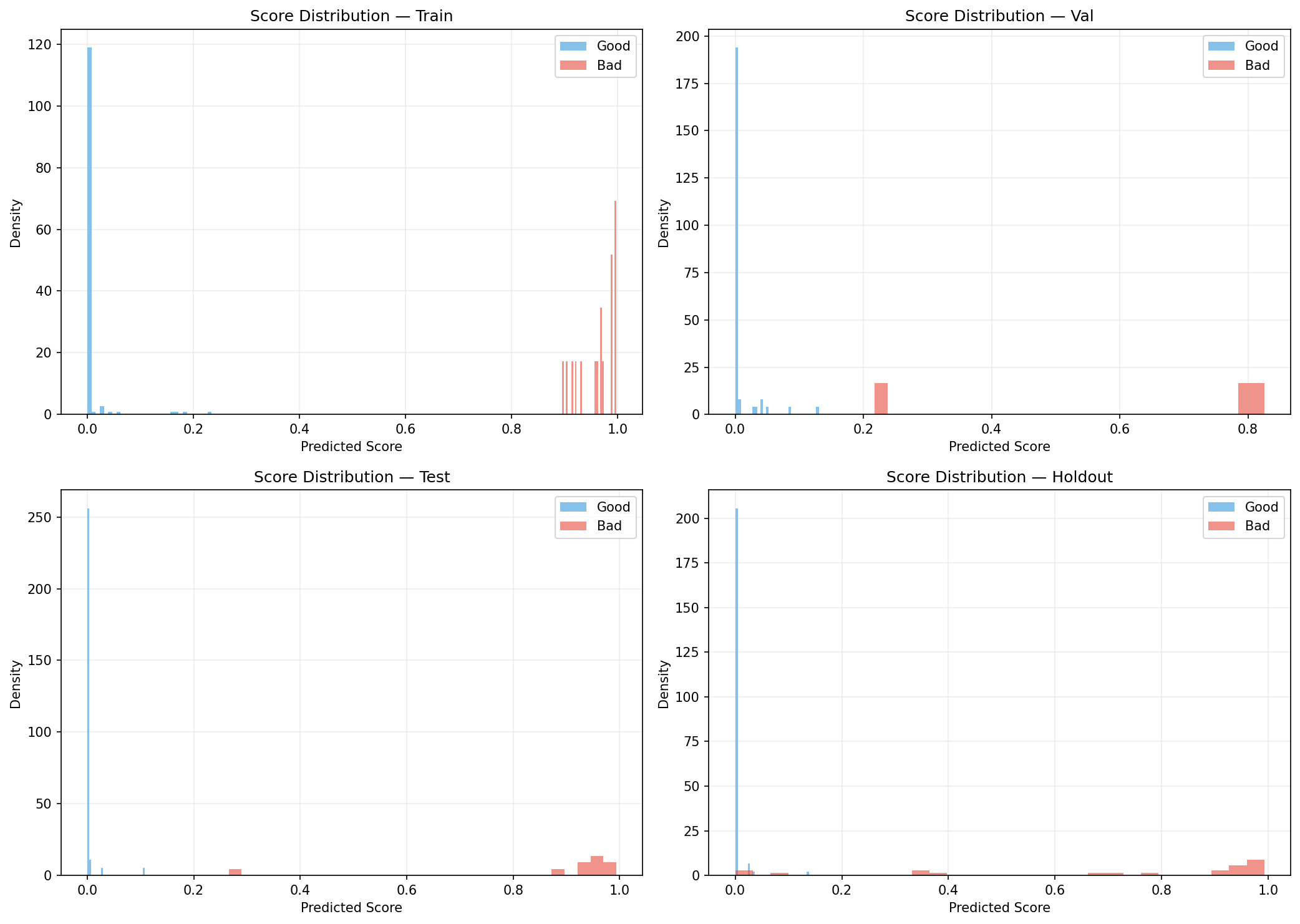
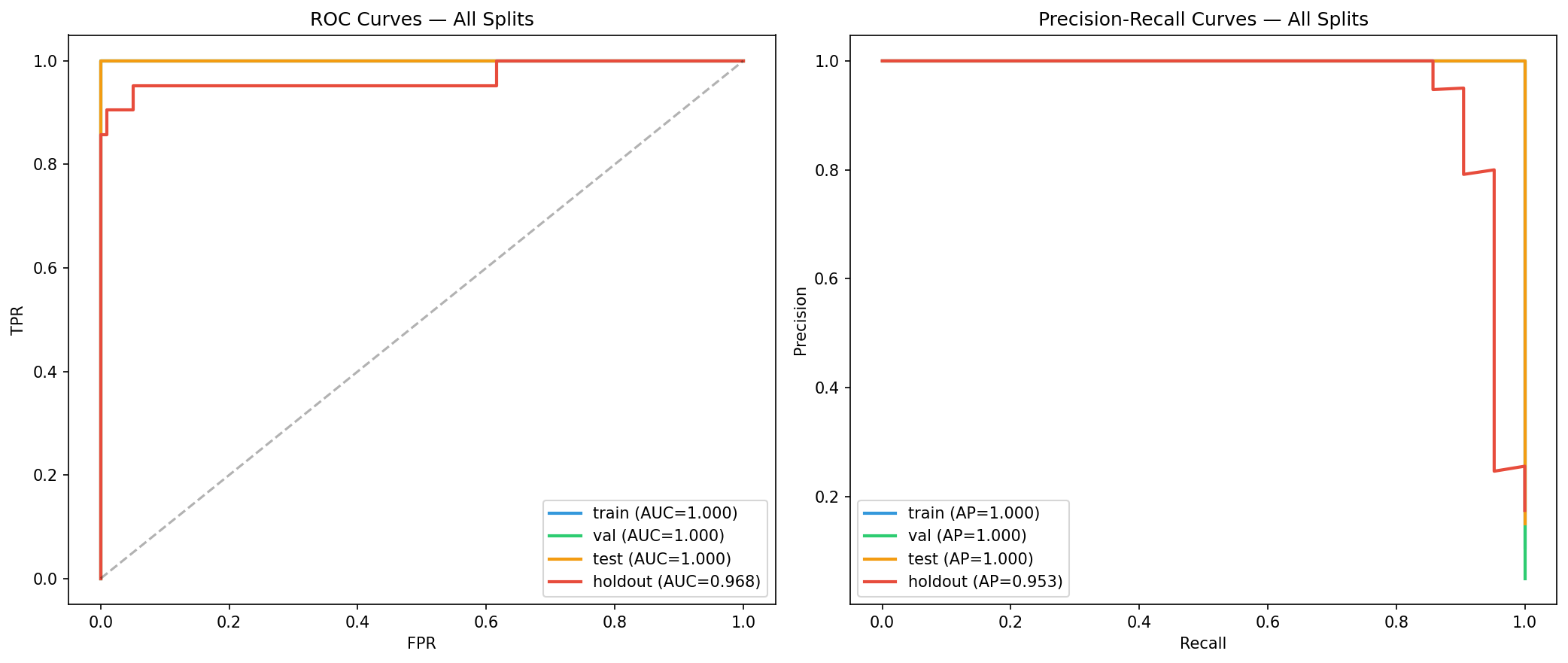
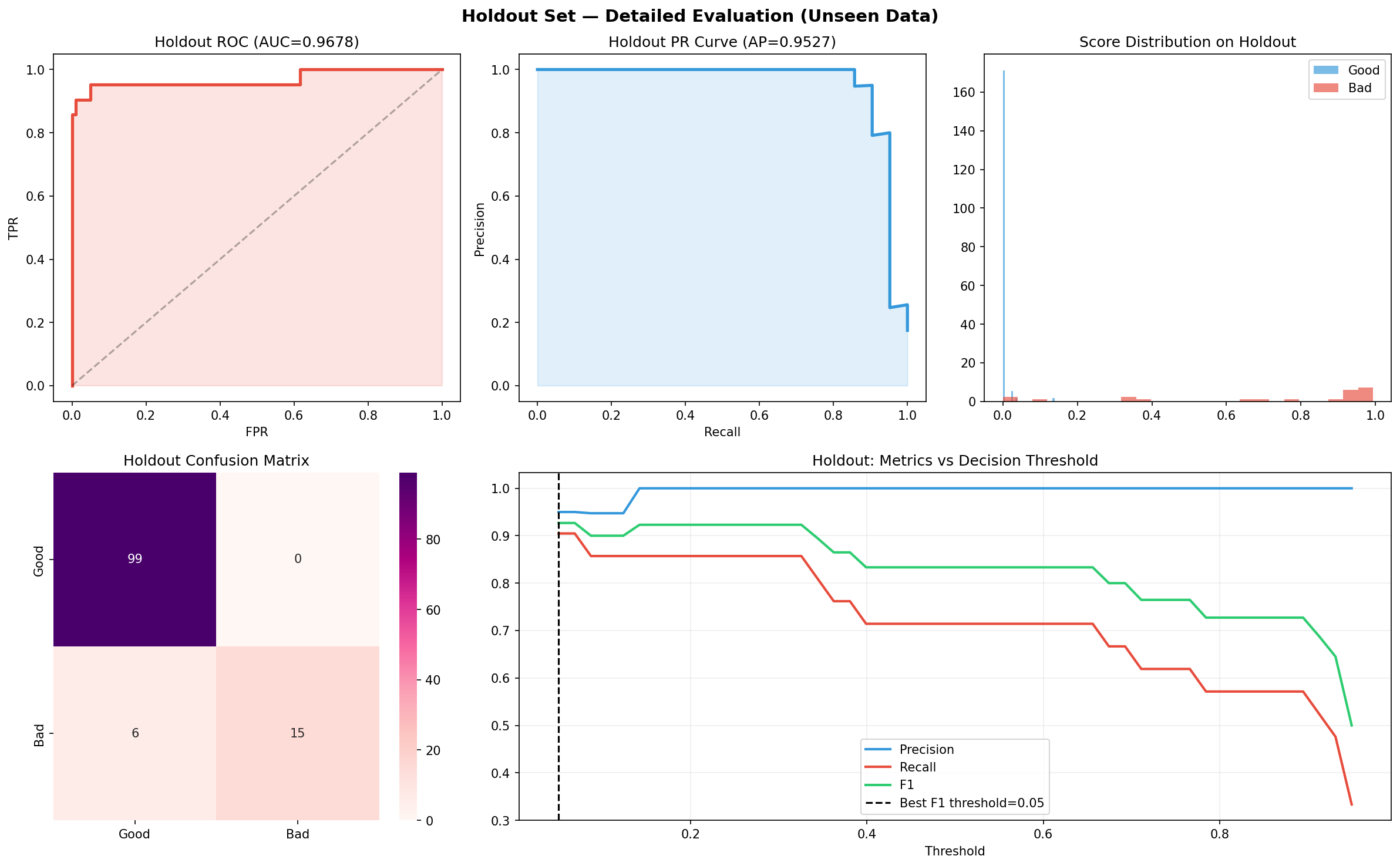
Validation Framework We enforced a strict four-way split: Train (40%) Validation (15%) Test (15%) Holdout (30%) This was paired with: Leakage detection checks Cross-metric evaluation (AUC, AP, F1) Overfitting diagnostics
Output & Interface The final layer includes: Automated report generation Visualization outputs (ROC curves, feature importance) Watchlist generation Agentic AI interface for querying results
Challenges we ran into
- Data reliability and ingestion failures External financial datasets are often inconsistent, incomplete, or structurally incompatible. This required building resilient ingestion pipelines and synthetic fallbacks.
- Feature leakage risk Time-series credit data is highly susceptible to leakage (e.g., using future information unintentionally). Designing a strict split strategy and leakage detection system was critical and non-trivial.
- Class imbalance Defaults are rare events. This created challenges in: Model training stability Metric selection (AUC vs F1 vs AP) Threshold calibration
- Combining heterogeneous models Blending outputs from: Unsupervised models (Isolation Forest) Sequence models (LSTM) Supervised ensembles required careful normalization and weighting to avoid dominance by any single component.
- Interpretability vs performance trade-off Highly accurate models can be opaque. Ensuring that outputs remained explainable for credit analysts required integrating feature importance and explainability tools.
Accomplishments that we're proud of
Strong generalization performance with high holdout AUC (~0.97), indicating real predictive power beyond training data A fully end-to-end pipeline—from raw data ingestion to actionable watchlists Successful integration of three distinct ML paradigms into a unified system A production-resilient design with fallback data generation and automated reporting Clear business-facing outputs, not just model scores An AI query interface, making the system accessible beyond technical users Most importantly, the system moves beyond theoretical modeling into something that could realistically be deployed in a credit risk workflow.
What we learned
- Hybrid models outperform single approaches No single model captures all risk dimensions. Combining anomaly detection, temporal learning, and supervised prediction yields more robust signals.
- Feature engineering is more important than model complexity Carefully designed features like payment ratio volatility or consecutive misses contributed more to performance than incremental model tuning.
- Validation design is critical Without strict holdout testing and leakage prevention, performance metrics can be misleading especially in financial datasets.
- Interpretability is non-negotiable In credit risk, predictions must be explainable. A “black box” model is far less useful, regardless of accuracy.
- Real-world robustness matters Handling missing data, ingestion failures, and edge cases is just as important as model performance.
What's next for RWA - EWS Private Credit v2.1
- Real-time data integration Move from batch processing to streaming data pipelines, enabling near real-time monitoring of borrower behavior.
- Enhanced macroeconomic modeling Incorporate richer macro scenarios (stress testing, forward curves) to improve sensitivity to systemic risk.
- Graph-based risk modeling Introduce network effects (e.g., borrower relationships, sector contagion) using graph ML techniques.
- Dynamic thresholding Replace static GREEN/AMBER/RED cutoffs with adaptive thresholds based on portfolio conditions.
- Explainability upgrades Deploy SHAP-based dashboards and borrower-level narratives for deeper transparency.
- Deployment & production API layer for integration with credit systems Dashboard UI for analysts Cloud deployment for scalability
- Continuous learning loop
Implement feedback-driven retraining, where analyst decisions refine model performance over time.
In its current form, v2.1 demonstrates that early warning in private credit is not only feasible but highly effective. The next phase is about turning this into a scalable, real-time decision system embedded directly into credit workflows.

Log in or sign up for Devpost to join the conversation.