-
-
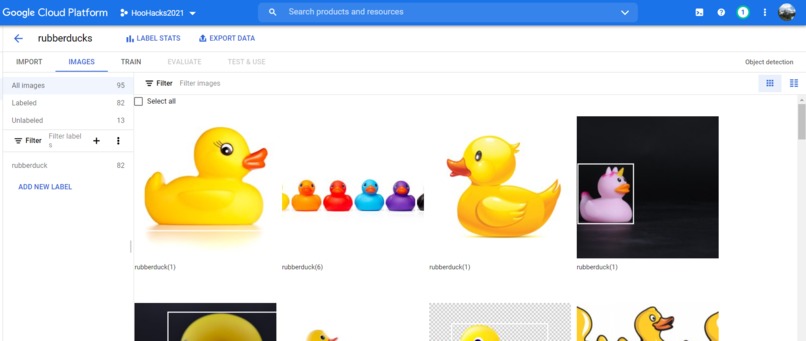
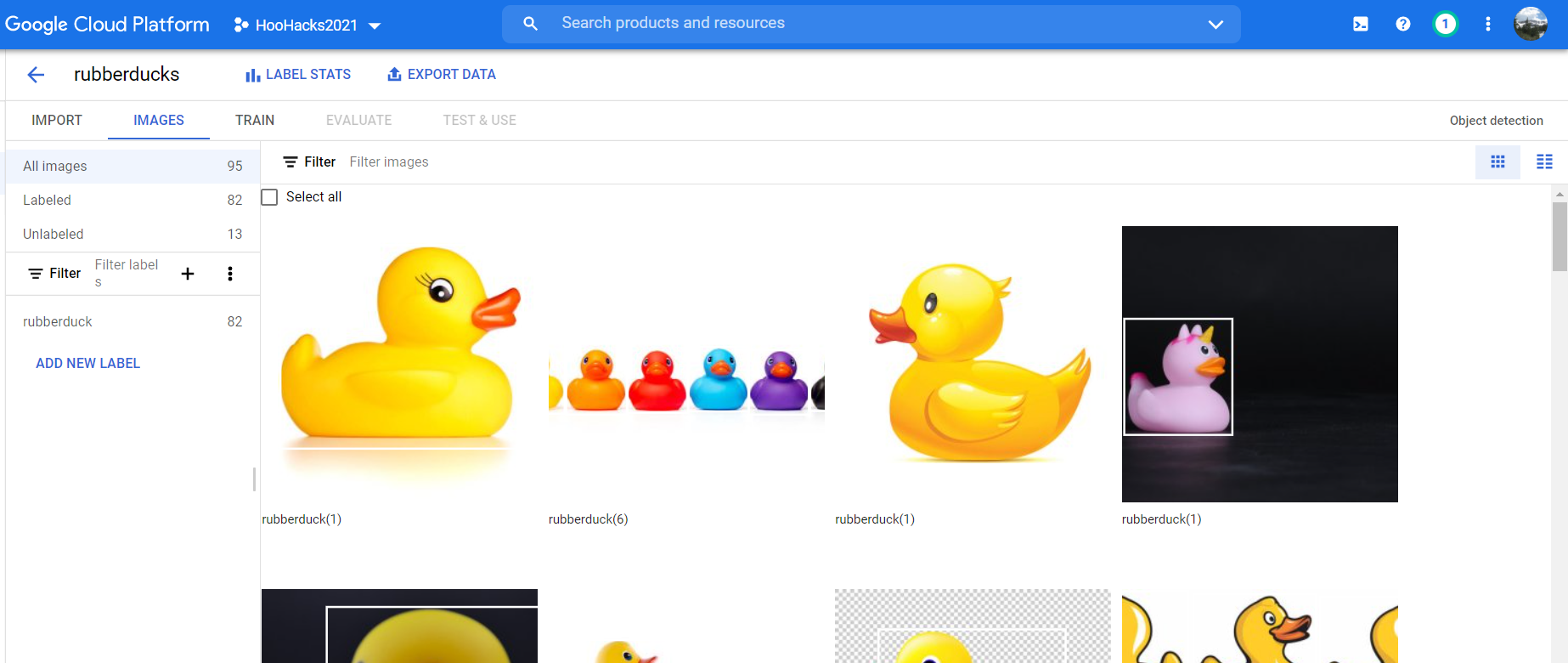
Google Cloud Vision
-
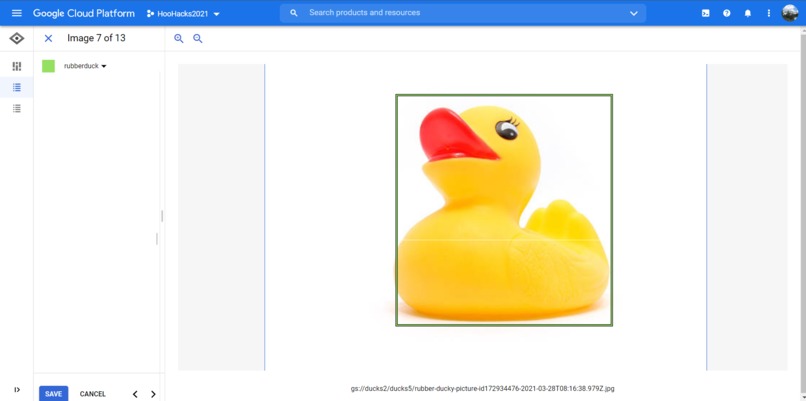
Classifying each rubber duck by hand
-
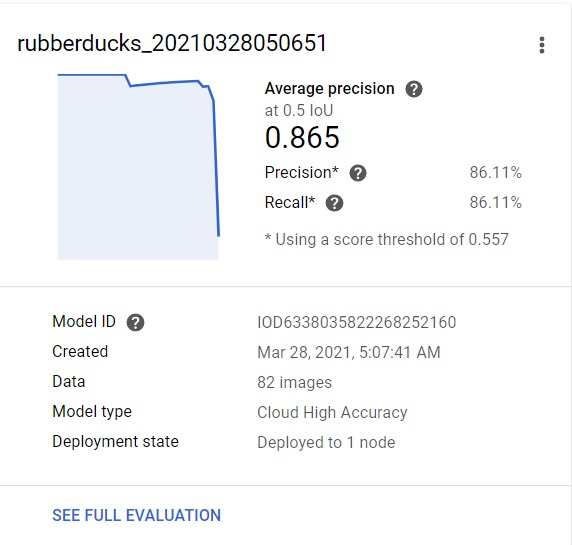
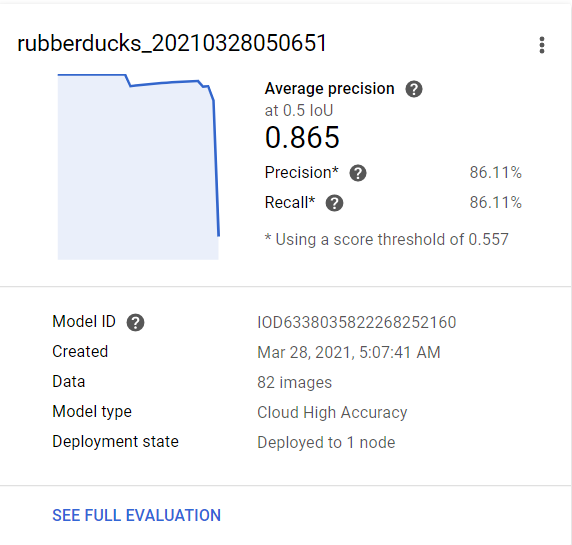
Training Results
-

Example Main Site Page
-

Example Duck Found Page
-

Example Duck Not Found Page
-
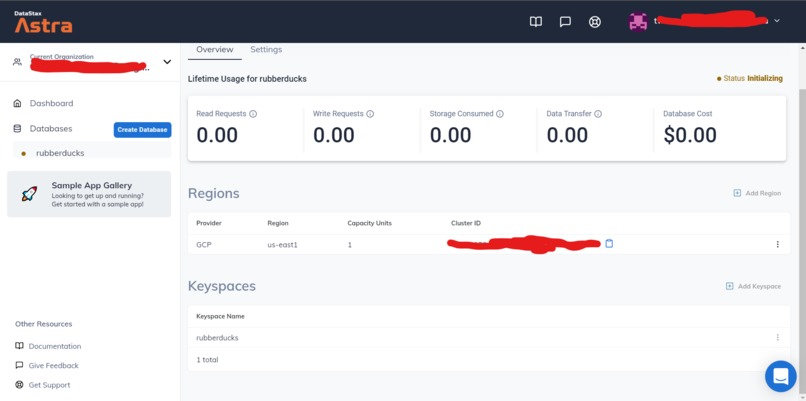
Setting up Astra
-
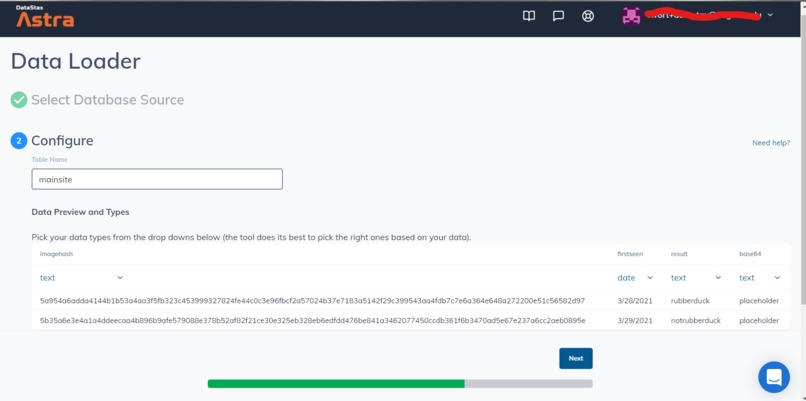
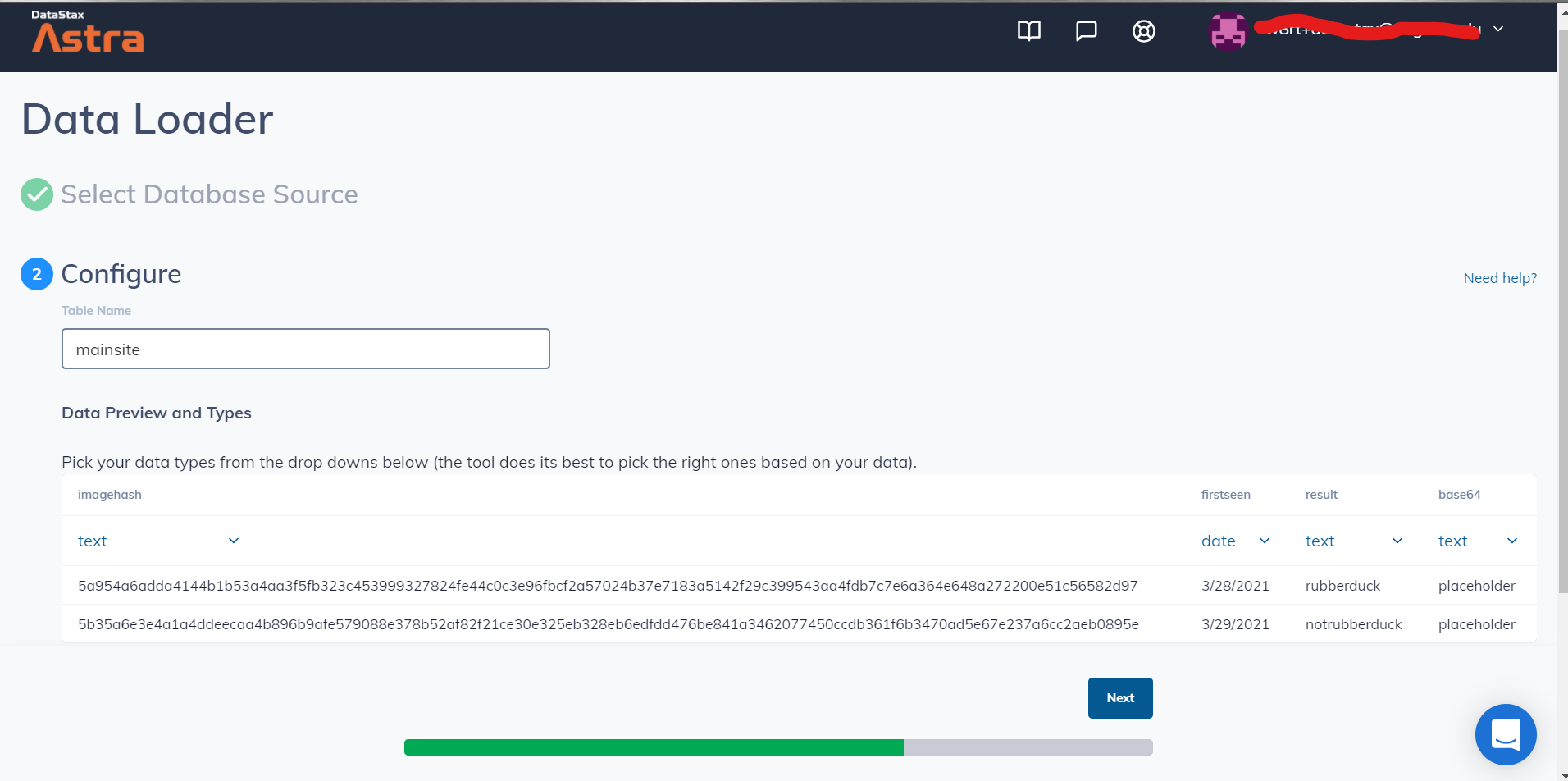
Importing sample data into Astra
-
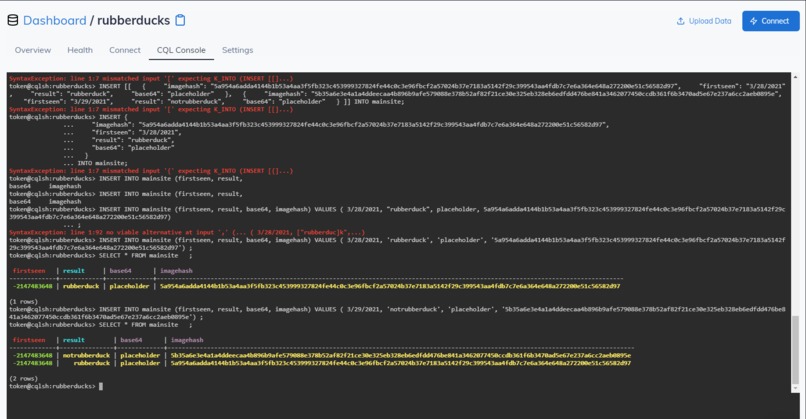
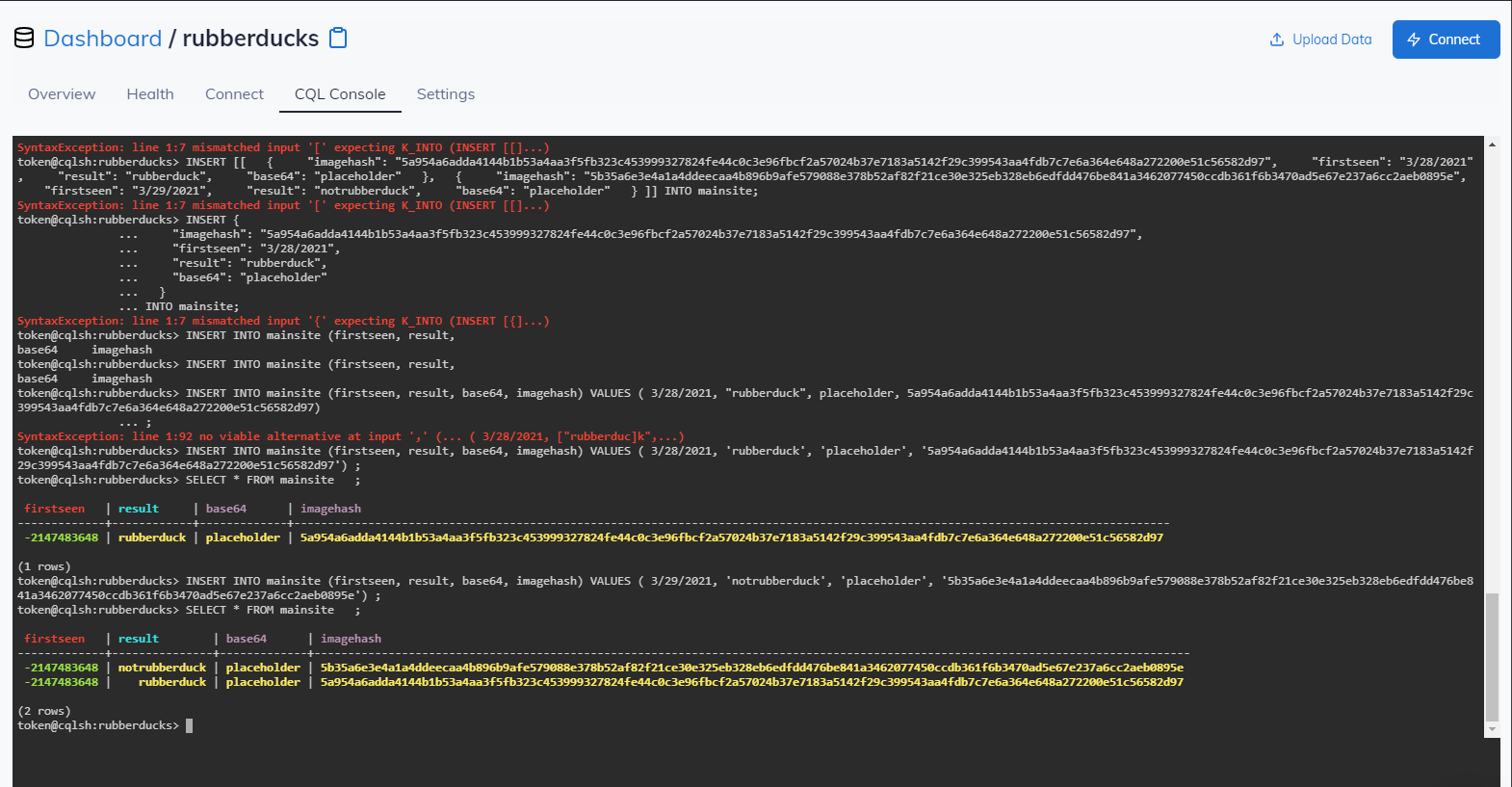
Data in Astra
-
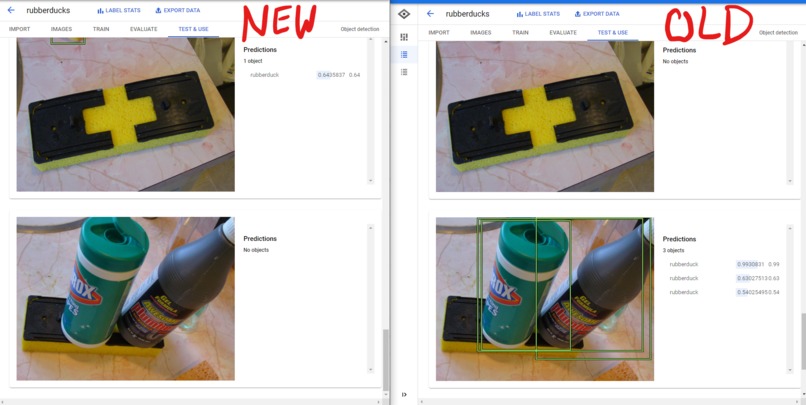
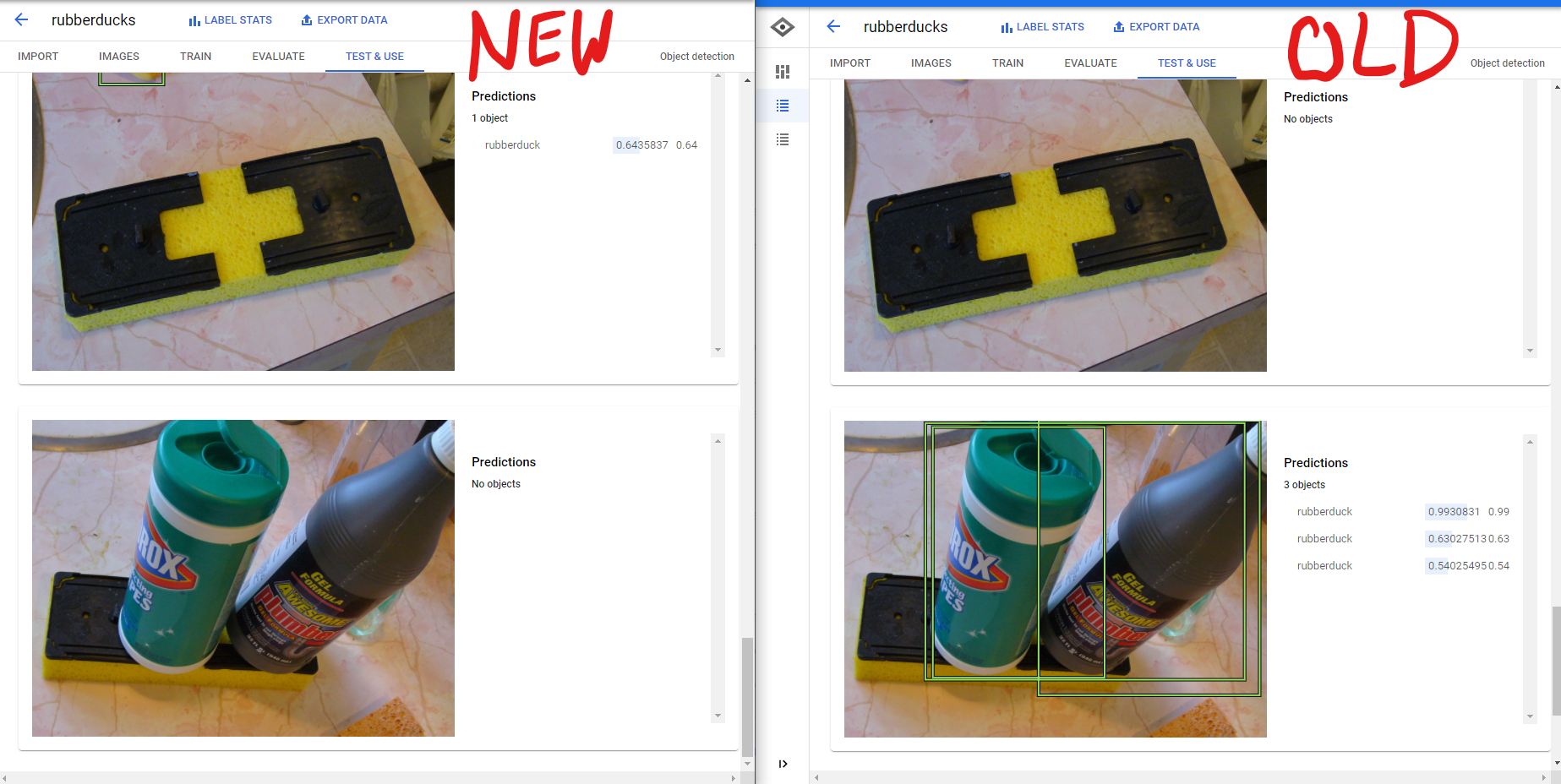
Improved: New vs Old
-
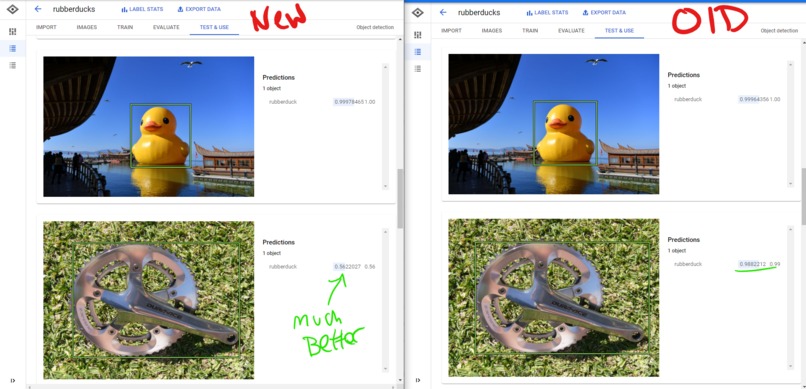
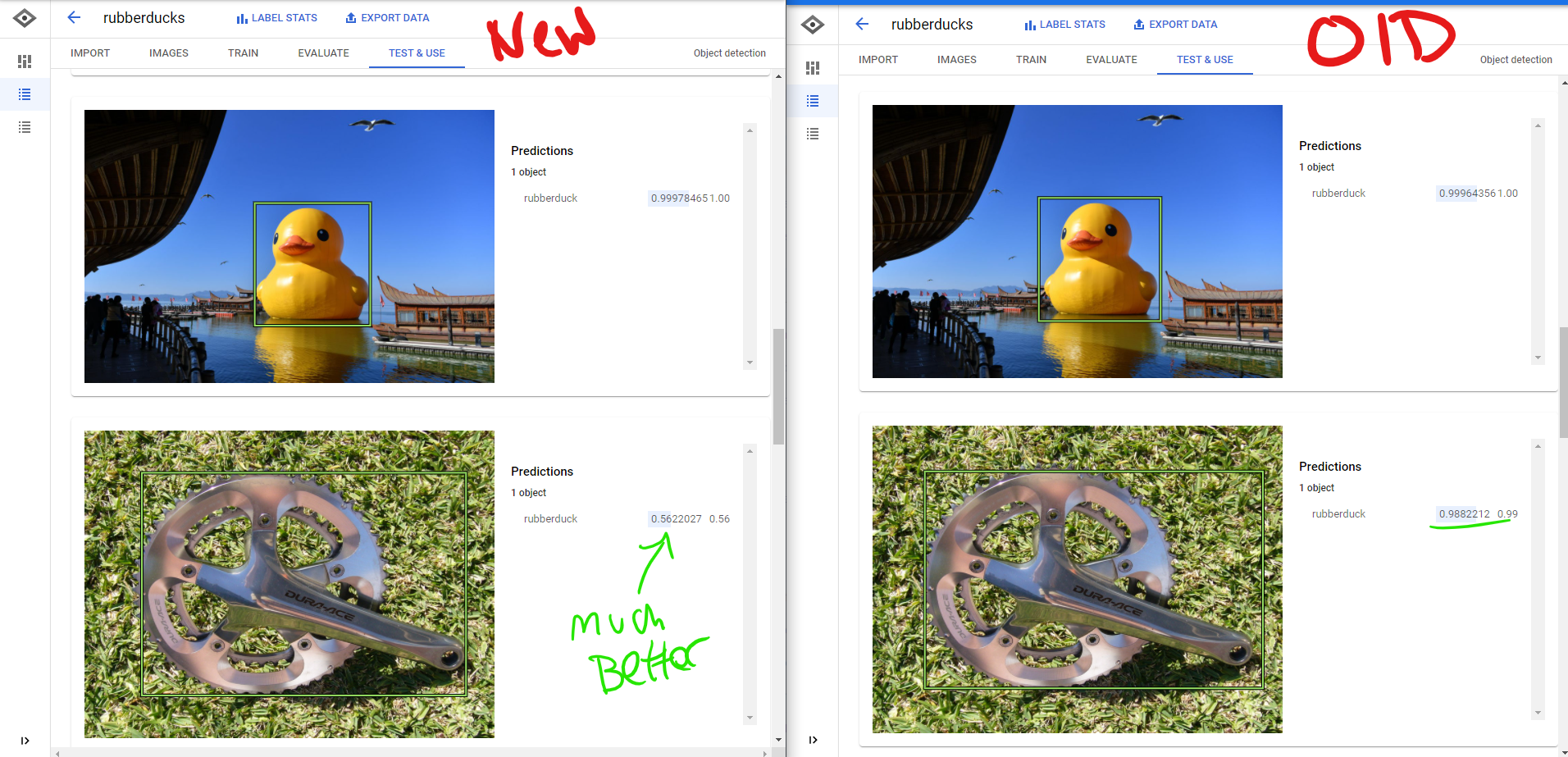
Improved: New vs Old




Inspiration
Inspired by a desire to distinguish between rubber ducks and not rubber ducks. Inspired in spirit by sHacks
What it does
Detects rubber ducks in images
How we built it
- Google Cloud Platform AutoML Vision
- Google Cloud Platform Storage Buckets
- Google Cloud Platform Compute (Ubuntu VM used for manipulating bucket contents)
- Google Cloud Platform Data Labeling (Attempted)
- Download All Images Chrome Extension (https://chrome.google.com/webstore/detail/download-all-images/ifipmflagepipjokmbdecpmjbibjnakm)
Challenges we ran into
I decided to spend my time working on a fun light hearted project. Other groups may have the high aspirations of changing the world; I just want to know if an image contains a rubber duck. While the end result doesn’t look particularly impressive, I encountered a number of roadblocks on my journey. Gathering the data was the first challenge. I looked through a large number of published datasets for images of rubber ducks before giving up on those and scraping my rubber duck images from AliExpress, Getty Images, iStock, and Pexels. Unfortunately I didn’t realize that I didn’t need images of counter examples so I spent time finding and gathering images from published datasets of not rubber ducks.
Once I had gathered my images, I then had to figure out how to get the data into google cloud and into a format that was usable. I made the mistake of uploading directly to a bucket, but then I wasn’t able to get the images from the bucket to work in the AutoML Vision service. I tried to upload to the Data Labeling hoping it would be a tool to help me label my data, but the tool was out of service. At this point I decided to re-upload the images directly into AutoML Vision service and I still had issues. I haven’t fully figured out what the issue is, but it seems that some of my images throw errors when I try and add them. I had to cherry pick images and hope they wouldn’t error on upload. I ended up with 95 training images and after even more time spent labeling the data I had over 200 bounding boxes for rubber ducks.
Training seemed to go well, it didn't take as long as initially quoted which was really nice. In the end, while the model was pretty good at detecting what was a rubber duck it was not very good at determining what was not a rubber duck. Based on the little bit of testing I did, it had a high false positive rate. I believe that this issue could be fixed by including more images of not rubber ducks.
Accomplishments that we're proud of
Really proud that I was able to find images and get them labeled. Proud that I can distinguish between rubber ducks and not.
While it wasn't necessary in the end, I was still proud of how I worked around challenges with manipulating data in the cloud storage bucket. Renaming, unzipping, and listing all the files in a CSV were all harder than expected
What we learned
Learned the basics of Google Cloud Vision
What's next for Rubber Duck or Not
While I had hoped to build a front end that that users could submit photos and get results, I unfortunately ran out of time. My hope was to set-up a web front end, use Astra as a cache for previously submitted photos, and call the model for new images. I would also like to further refine the detection and potentially try and detect different varieties of rubber ducks (colors, costumes, hats, etc.). In my final testing I found that while the model is good at detecting rubber ducks, it has a lot of false positives. Next time I would like to add more non-rubber duck images to the data set to try and see if that helps prevent some of these.
Sponsor Categories
Google Cloud
The project is heavily based on Google Cloud. I use it for storage and to train the model. The main analysis component is built using Google Cloud AutoML Vision. Additionally I used a VM from Google Cloud Compute when manipulating the dataset inside the bucket. While it is possible to have a model offline, this one still hosted in GCP.
Astra
Astra is an ideal fit for how the project could be expanded upon and how it could grow in the future. Astra would be a good platform to use to cache image results so the model doesn't have to be consulted every time. Hope would be to store the hash of the images, the result, the data on which the image was first submitted, and space permitting, the base64 version of the image. This would save power and time making things more efficient.
Photo Credits
Photo credits: Photo by Peng Louis from Pexels
Photo by Mahrael Boutros from Pexels
Photo by Armando Are from Pexels
Photo by Designecologist from Pexels
Photo by George Becker from Pexels
Photo by Andre Moura from Pexels
Photo by Ann H from Pexels
Photo by Anthony from Pexels
Getty Images
iStock Images
AliExpress
https://www.nationalgeographic.org/activity/follow-friendly-floatees/
https://www.safety1st.com/rubber-ducky-tempguard--ba066-s1-us-en.html
https://storage.googleapis.com/openimages/web/download.html
http://www.vision.caltech.edu/pmoreels/Datasets/Home_Objects_06/
http://www.vision.caltech.edu/Image_Datasets/Caltech256/
http://www.vision.caltech.edu/Image_Datasets/Caltech101/Caltech101.html
Built With
- astra
- google-cloud
- google-cloud-buckets
- google-cloud-compute
- google-cloud-vision





Log in or sign up for Devpost to join the conversation.